-
-
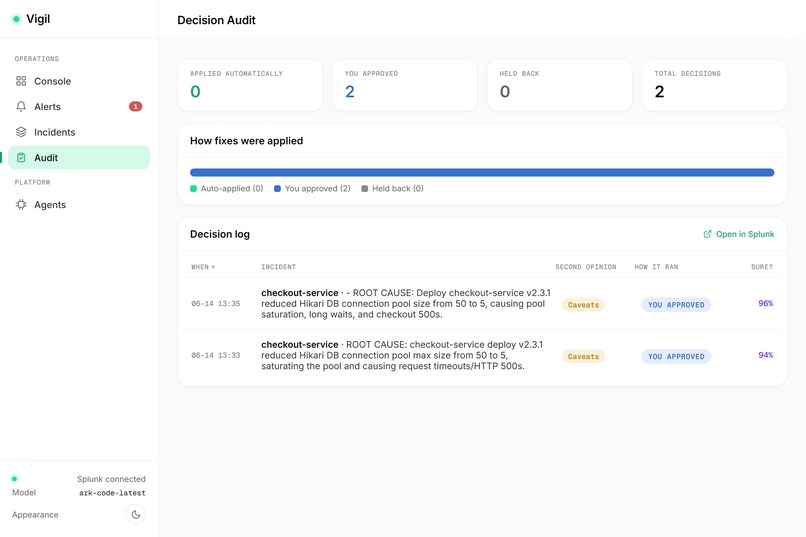
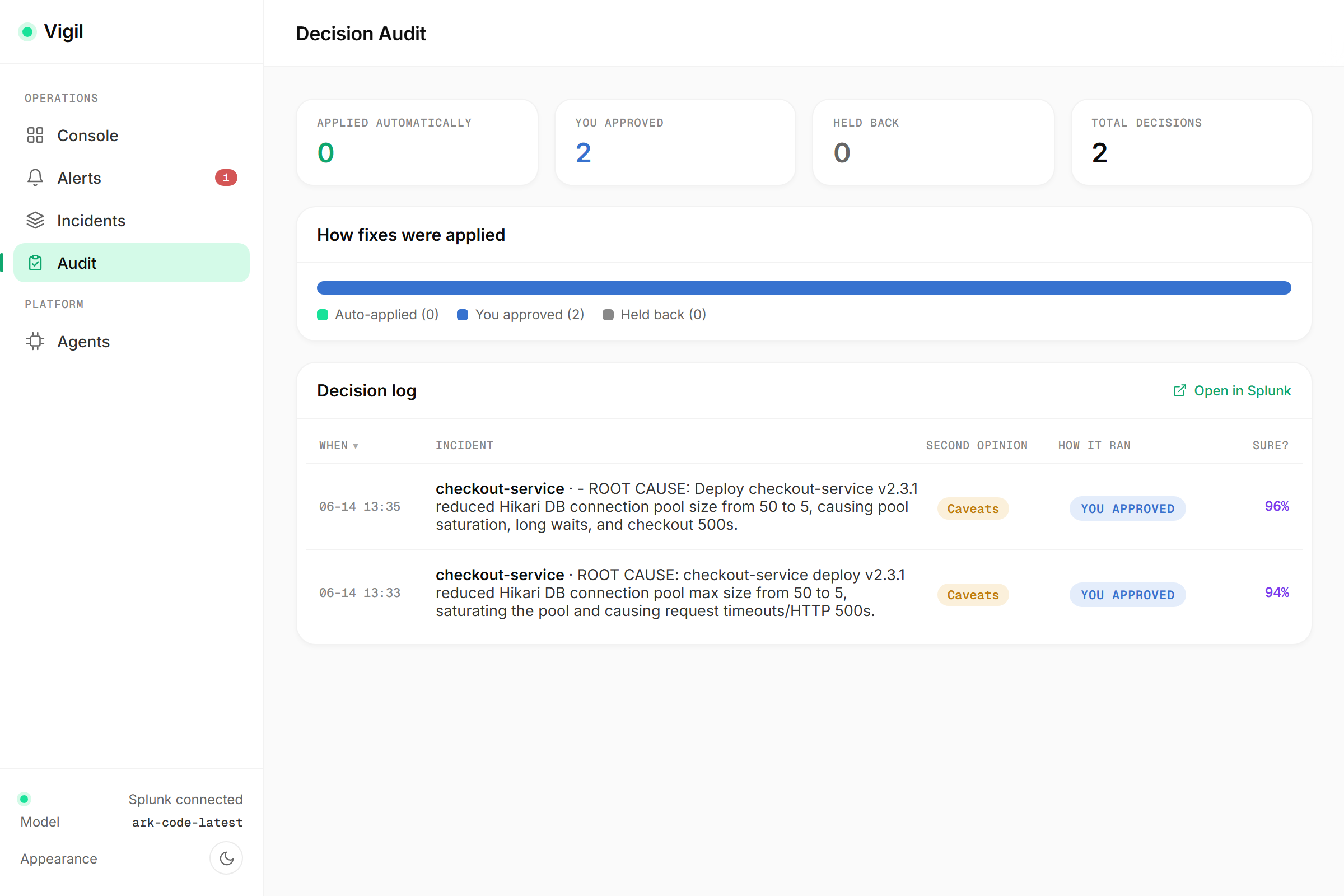
03_audit.png: Decision audit view for AI verdict tracking.
-
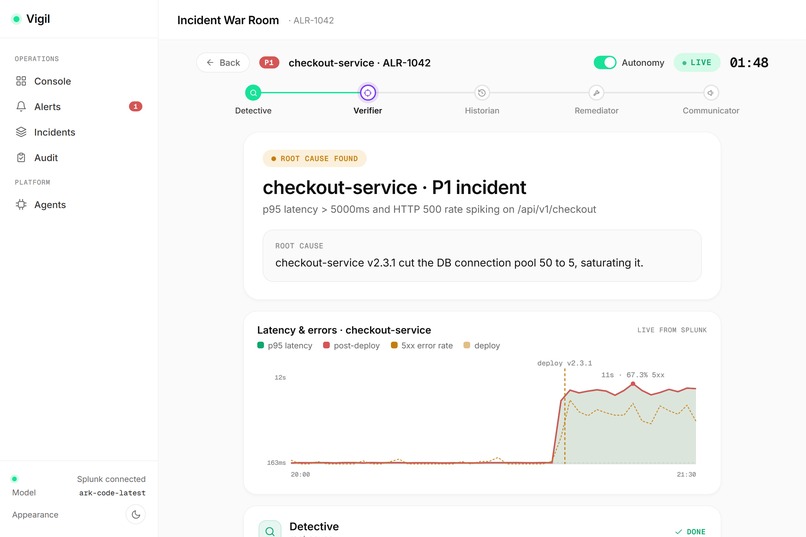
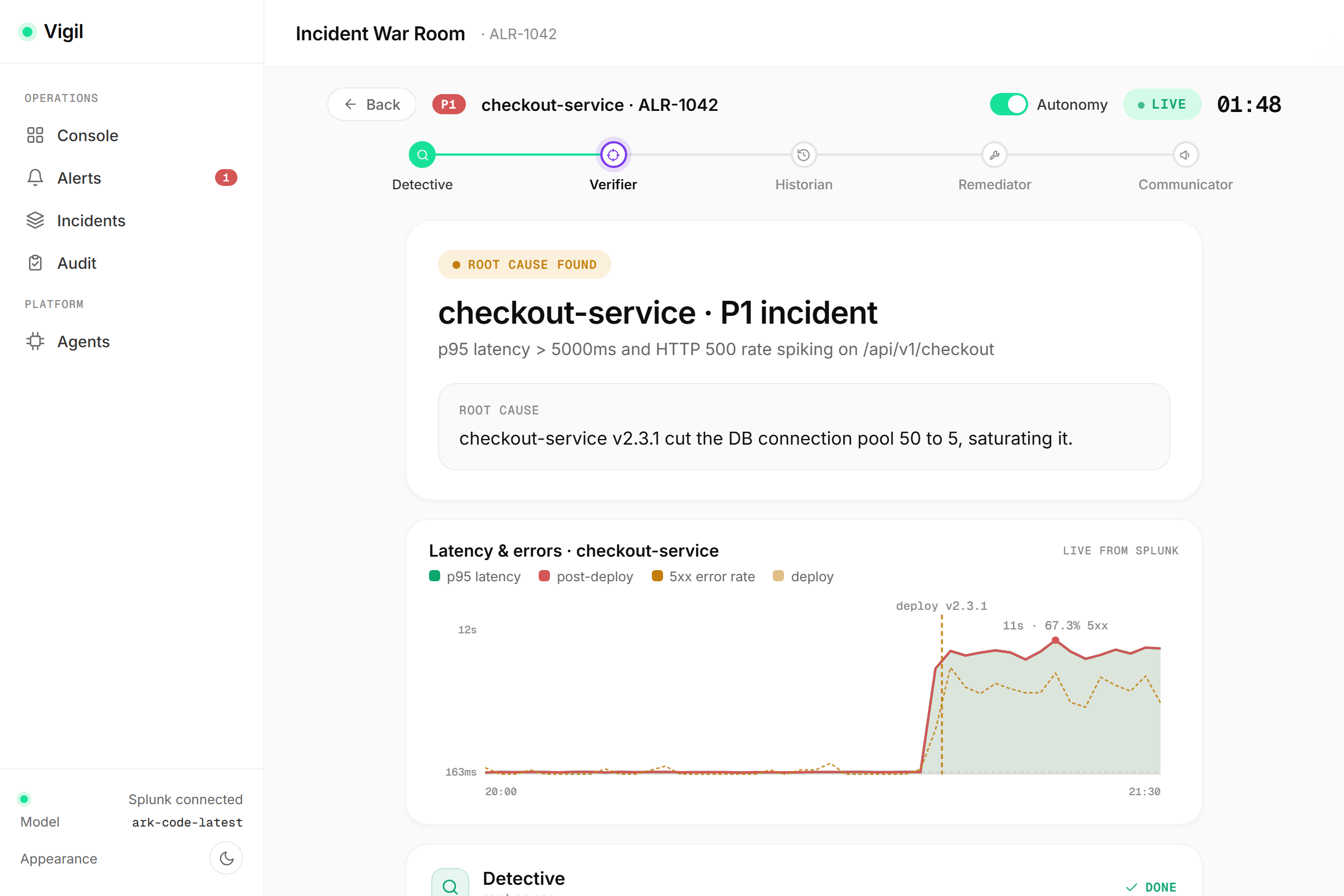
02_warroom.png: AI-powered incident war room for root-cause analysis.
-
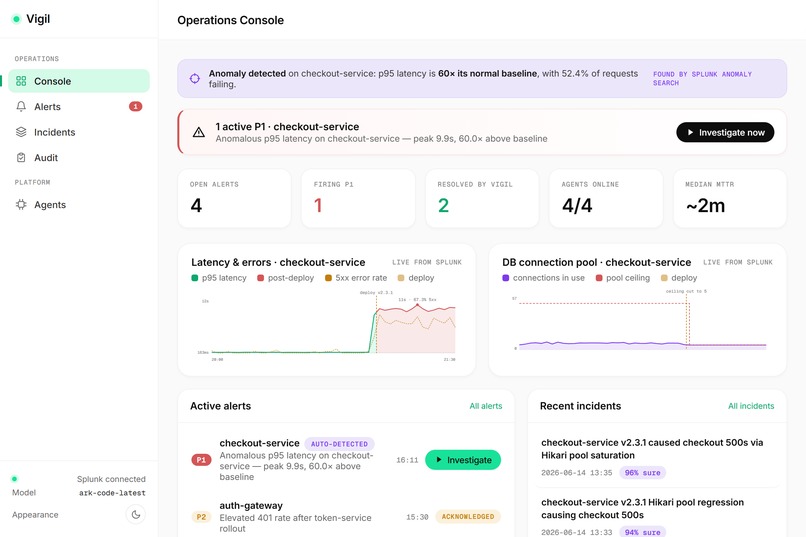
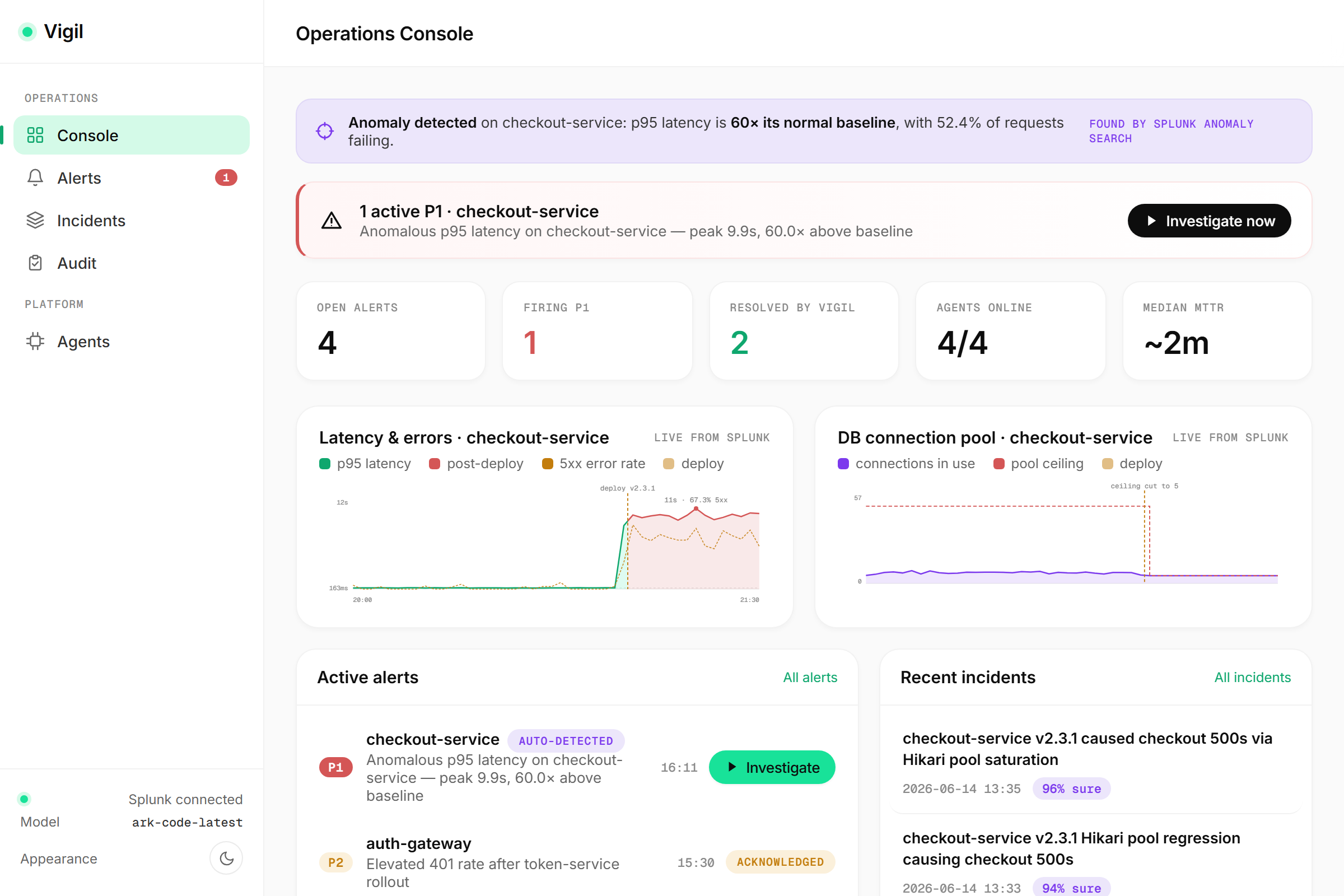
01_console.png: Vigil operations console with real-time incident monitoring.
-
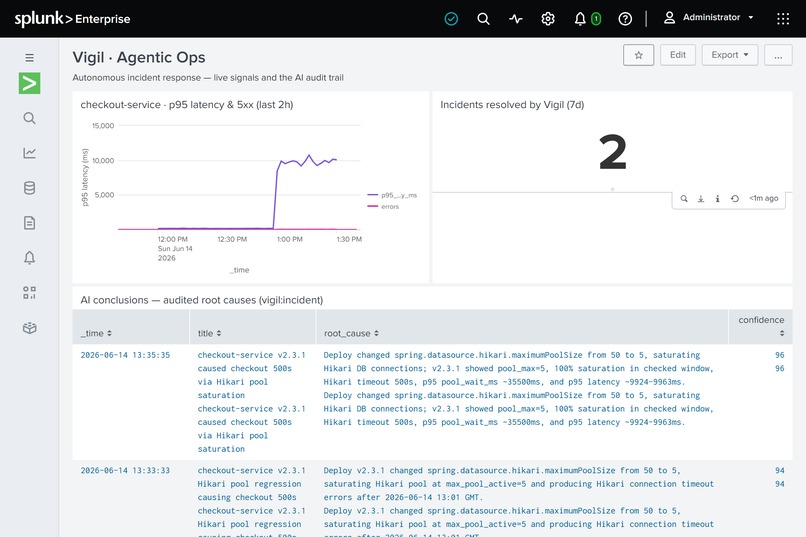
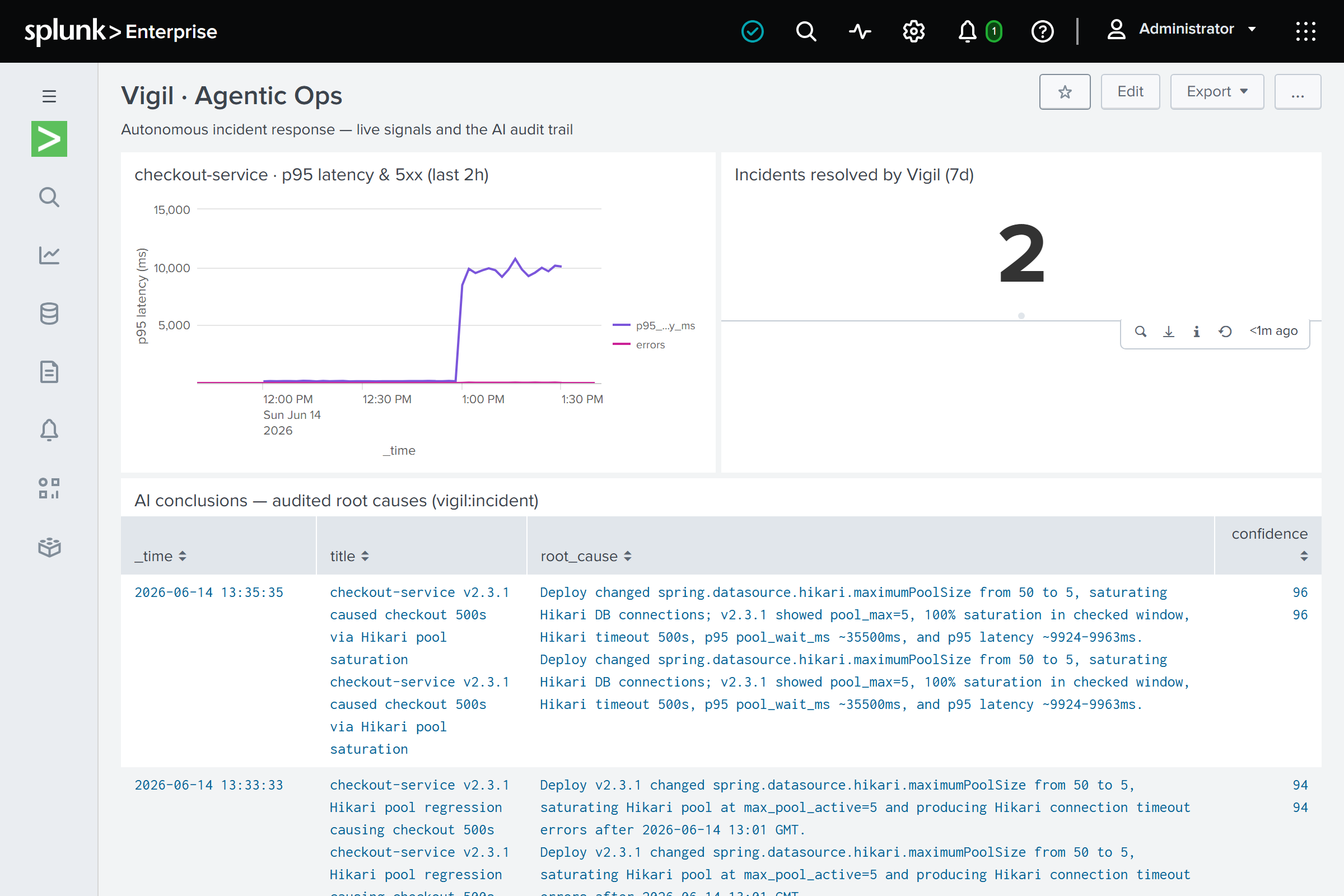
04_splunk_dashboard.png: Native Splunk dashboard for Agentic Ops monitoring.
Inspiration
On-call is the same painful loop every time: an alert fires, a tired human pages in, opens Splunk, and spends 30–45 minutes pivoting between logs, metrics, and the deploy history to answer one question — what changed? The data to solve almost every incident is already in Splunk. The bottleneck is a human stitching it together under pressure. We wanted to see how far an agentic system could take that loop — not a chatbot that summarizes dashboards, but a team that actually investigates, reasons over live data, and is trusted to act.
What it does
Vigil is a full agentic-ops console backed by a team of five specialized agents:
- Detective — runs multi-step SPL searches to find when the incident started and what changed right before it.
- Verifier — an adversarial skeptic that re-checks the root cause with its own independent queries and reports a calibrated confidence.
- Historian — surfaces the deploy behind it and a safe rollback target.
- Remediator — proposes a concrete, reviewable fix with a confidence score.
- Communicator — writes the incident record and saves it back to Splunk.
The end-to-end loop:
- Autonomous detection. Vigil runs a Splunk statistical anomaly search (a trailing z-score over p95 latency) and raises the incident itself — no human-configured alert.
- Diagnosis. The agents query live Splunk through the Splunk MCP Server; every claim is grounded in rows they actually retrieved.
- Adversarial verification. The Verifier tries to disprove the root cause; its calibrated confidence — not a self-report — drives what happens next.
- Responsible autonomy. If verified confidence clears a configurable threshold, Vigil applies the fix automatically with a human veto window; below it, approval is always manual. Every decision (auto vs. human) is recorded.
- Auditability. Conclusions and decisions are written back into Splunk
(
vigil:incident,vigil:action) and surfaced on a native Splunk dashboard — you can search what the AI decided and why.
The console includes an operations dashboard with live Splunk charts (latency/errors and DB connection-pool saturation, each drillable straight into Splunk search), an alert inbox, a live "war room" that streams each agent's reasoning, an incident history, a decision-audit view, and an agents page where you can tune the automation. On our demo incident, Vigil takes MTTR from ~45 minutes to ~2–3.
How we built it
- Agents & orchestration — a five-agent team in Python. Each agent runs its own
ReAct-style tool-use loop against an OpenAI-compatible chat-completions API
(Volcengine Ark,
ark-code-latest, with tool calling). Every reasoning step streams to the UI. - Splunk MCP Server — a FastMCP server exposing Splunk to the agents over the Model
Context Protocol with token-based (JWT) auth. Tools:
splunk_search,splunk_list_indexes,splunk_server_info,splunk_write_event. A synchronous bridge lets the agent loop discover and call these tools dynamically. - Data plane — Splunk Enterprise 10.4. Ingestion via HEC; agents read through the REST
API; the team writes its audit trail back via
receivers/simple. Anomaly detection, signals, and incident/decision history are all real SPL. - Console — FastAPI + WebSocket backend and a dependency-light single-page app (vanilla JS, Inter + Geist Mono, a Mintlify-inspired design system, light/dark themes, responsive). Charts are hand-rendered SVG so the whole thing stays self-contained.
- Splunk-native — a script pushes a dashboard and saved searches (including the anomaly search) into Splunk so Vigil lives inside the platform.
- One command —
docker compose up(orscripts/bootstrap.pyagainst an existing Splunk) provisions indexes, HEC, a token, demo data, and the dashboard.
Challenges we ran into
- Making autonomy trustworthy. A single agent's self-reported confidence isn't enough to let software act on production. Adding an adversarial Verifier whose calibrated confidence gates execution was the change that made autonomy defensible.
- Keeping agents honest. It's easy for an LLM to produce a plausible-but-wrong root cause. Forcing every claim through real SPL via MCP — and having a second agent re-derive it — kept conclusions grounded.
- Statistical anomaly detection that reads cleanly. A flat baseline makes z-scores explode; we report an intuitive "× above baseline" magnitude instead while still flagging on the z-score.
- Bridging sync agents to an async MCP client without blocking the reasoning loop.
Accomplishments we're proud of
- A genuinely closed loop: detect → diagnose → verify → fix → audit, all on live Splunk.
- Deep MCP usage — ~30 live searches per incident, zero hardcoded data.
- Responsible autonomy with an independent verification gate and a complete audit trail back in Splunk.
- A console that feels like a real product, not a demo — and a one-command setup so anyone can run it.
What we learned
- Grounding + adversarial verification matter more than raw model capability for trust.
- MCP is a clean seam for giving agents safe, typed access to a data platform.
- The most persuasive thing an agent can do is show you the smoking gun in your own data — hence the live, drillable Splunk charts.
Built With
- docker
- fastapi
- fastmcp
- hec
- javascript
- model-context-protocol
- python
- rest-api
- spl
- splunk
- splunk-mcp-server
- svg
- volcengine-ark
- websockets


Log in or sign up for Devpost to join the conversation.