-
-

Little Island is a park in NYC that opened in Summer 2021, OSM updates allow us to keep tabs on new developments
-
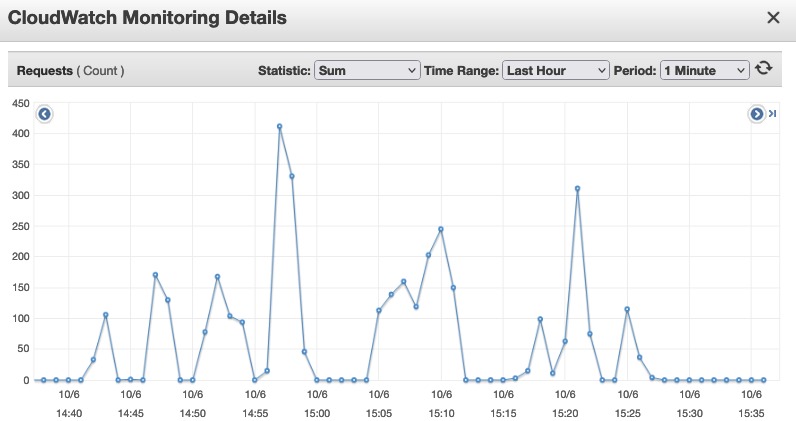
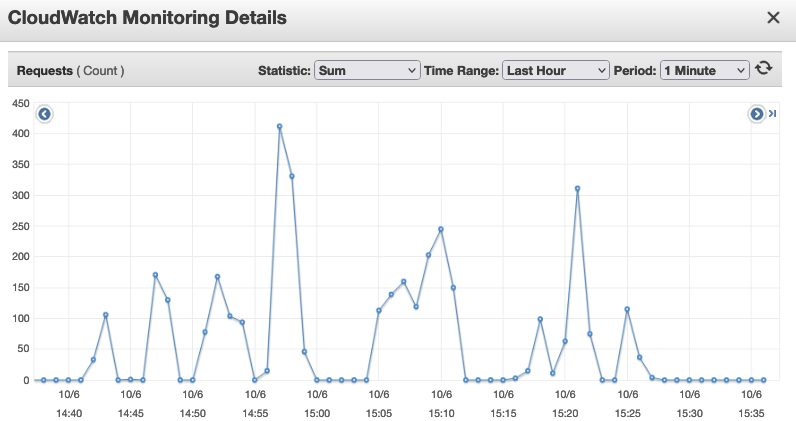
Sample ALB data, just a few users panning the map requires serving thousands of tile requests (which Go handles wonderfully!)
-
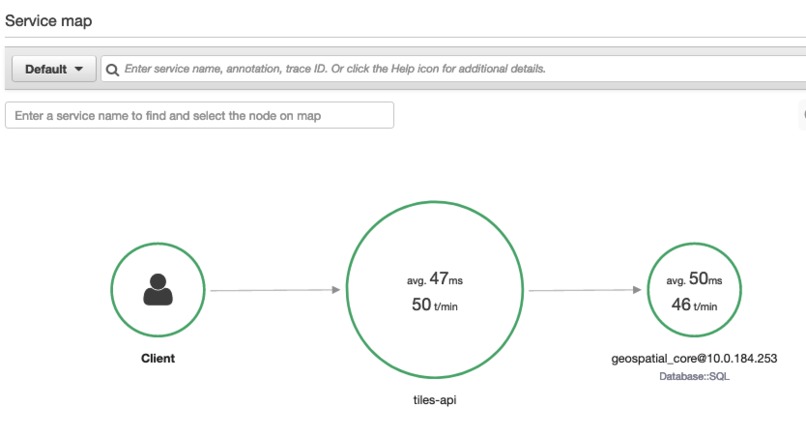
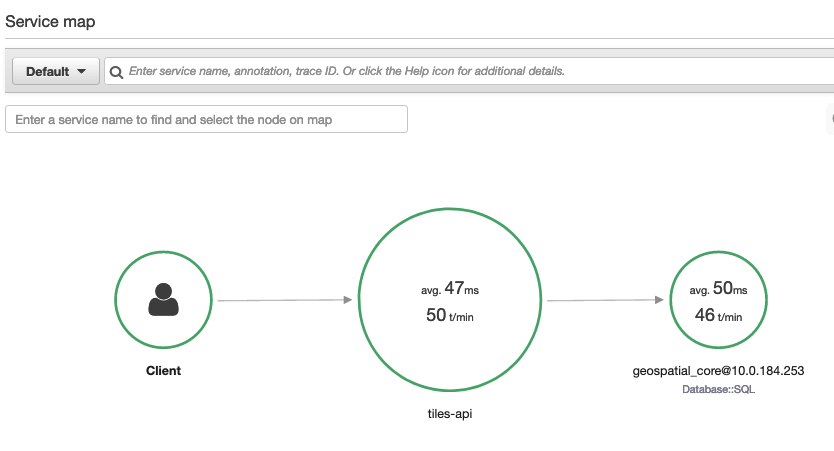
Sample X-Ray traces from demo usage. Point layer only.
-
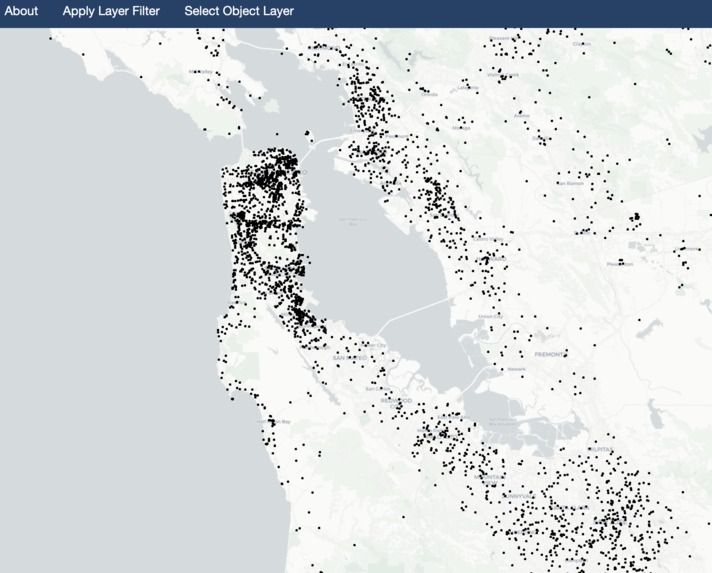
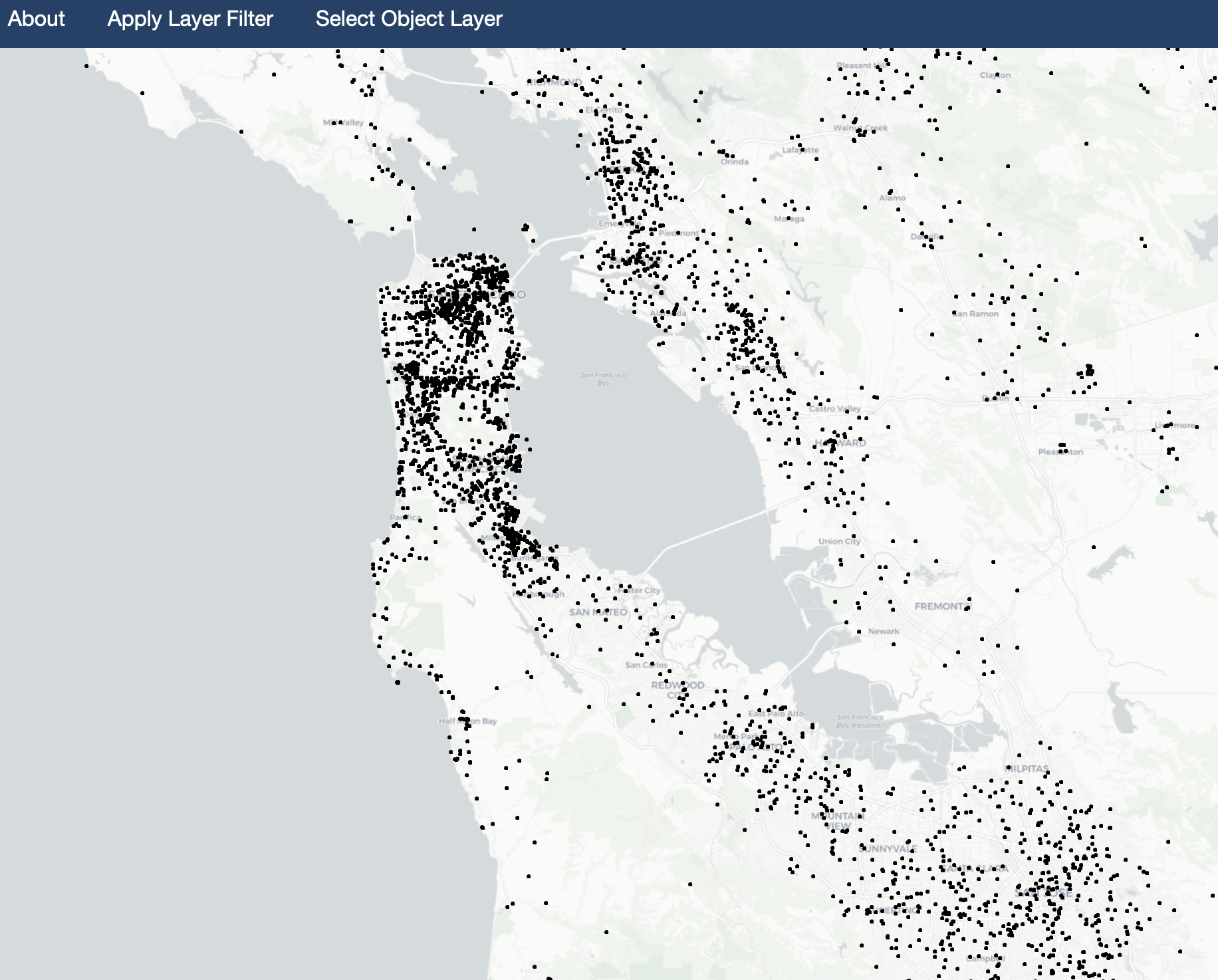
Sample Point Layer - Oakland, CA
-
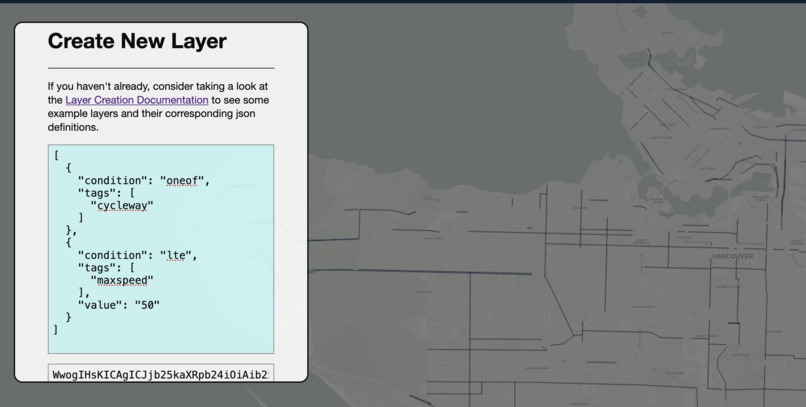
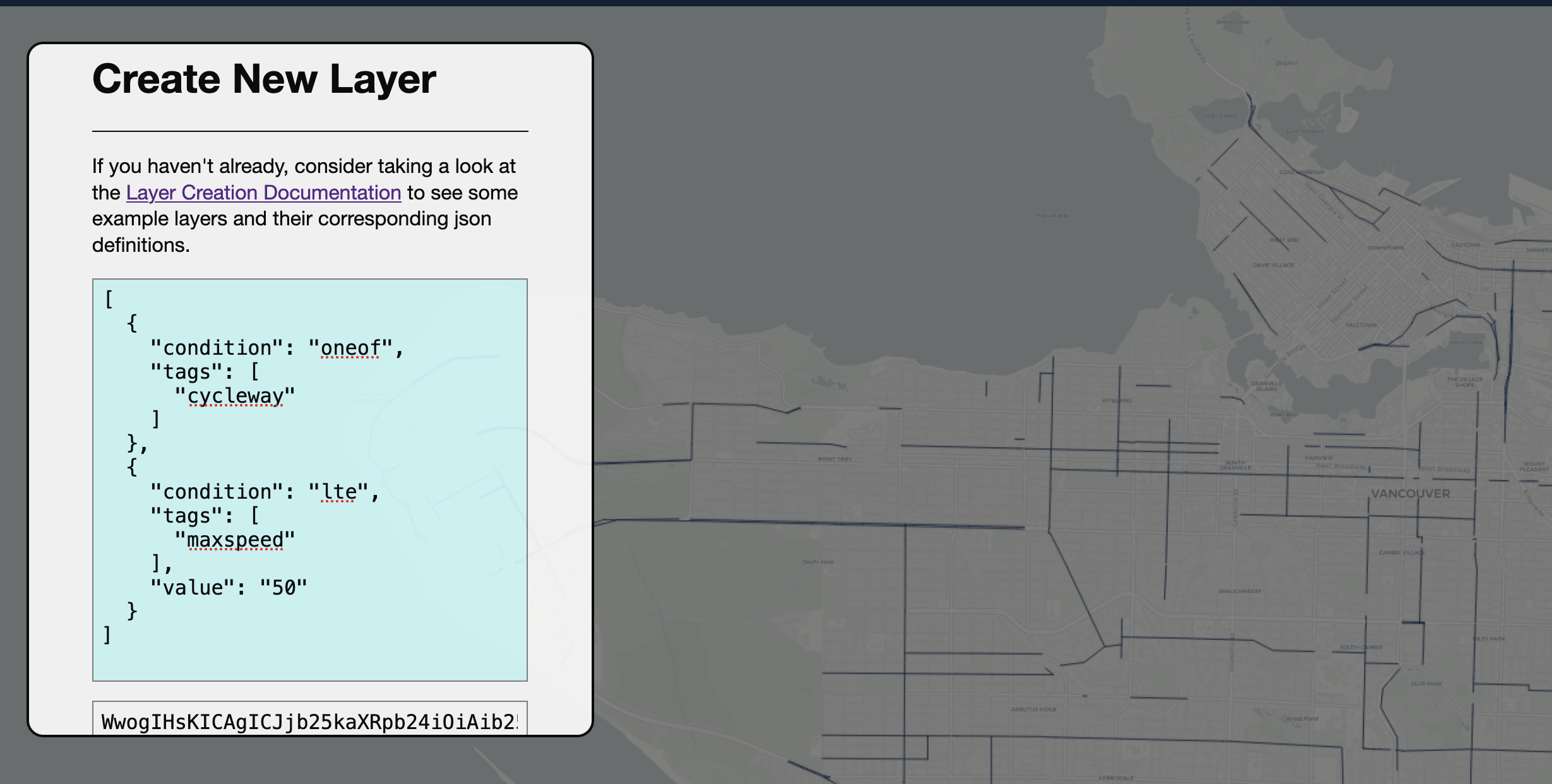
Vancouver Protected bike routes w. low speed limit

Inspiration
I work as a data engineer, often working with geospatial data. I've noticed that developers, analysts, PMs, etc. often want to be able to visualize subsets of spatial data, but struggle because there is no way to "peek" at a subset of a large source without specialized knowledge of a GIS software or spatial SQL.
A simple request like "I'd like to see all the grocery stores in Belgium" can involve asking an analyst/engineer to materialize a custom dataset and then recreate it several times over as the definition of a "grocery store" is refined.
Not only is this process inefficient from an operational perspective, but given a large enough dataset, preparing the cuts of data can take quite a while or put a heavy load on a DB. The solution to this problem is a service that allows for adhoc analysis of geospatial data in small increments. To do that, I'd need a geospatial DB, an API that can interact with that data and return map tiles for a user to review, and the appropriate hardware for both services.
Before undertaking any serious API development, I tested some queries on PostGIS on ARM and X86. The results are here and encouraged me to commit to this project because I saw the clear performance benefit from the ARM instance's overall better memory performance. Also see this excellent article from Percona.
What it does
The project's backend services allow users to query through hundreds of GB of OpenStreetMap (OSM) data and request/build custom vector layers from this data (e.g. "All roads with a bike lane AND speed limit over 50 kmh").
The webpage offers a convenient graphic interface to explore and visualize custom layers. A user guide is available here as well. NOTE: The webpage has been tested for compatibility with Mozilla Firefox >=v92.0, Chrome v94, and Safari >13.1.x, other browsers may not display w/ live map interaction properly
The advantages of dynamic tiles are twofold.
Dynamic tiles can receive frequent changes without a batch tile re-generation job - If a spatial dataset changes frequently, static tiles can't incorporate those changes without running a large batch job. If those diffs are minutely or hourly, it becomes near impossible. Tiles uses OSM as sample data, and receives and incorporates those changes into the database every few hours.
Dynamic tiles allow users to visualize arbitrary subsets of data - Dynamic tileservers are great for quick analysis. Because tiles are requested only when needed, a query like "All roads with 2 lanes and a speed limit over 40 mph" (or something otherwise impractical, like "All nodes with the tag "amenity" equal to "circus"") can be generated on the fly for only the user's area of interest. As long as our database is properly provisioned, tiles will be rendered in the users browser in as little as 10ms for cached tiles and ~100ms for new tiles.
Compared to static tiles, dynamic tiles require less disk space and offer more possibilities for analysis, but demand better disk, memory, and consistent CPU performance; a perfect set of requirements for Graviton instances!
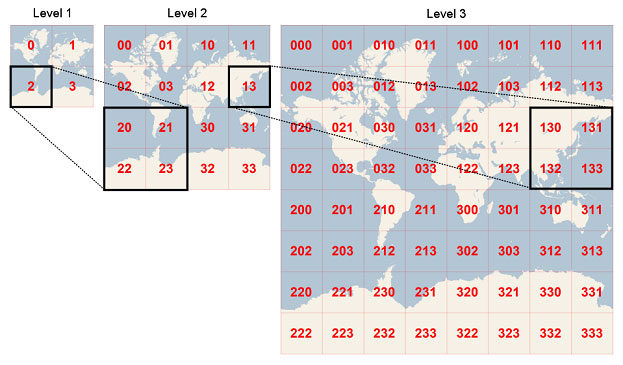
Note: static and dynamic tilesservers fetch data using a hierarchical reference model, where each tile contains smaller sub-tiles down to the point where tiles have negligible width and height. Dynamic tileservers can save an order of magnitude on storage because data is stored once (in the db) rather than at multiple zoom levels across several files on disk. see image below.
Map layers are shareable via link, Example - NYC MTA bus B68 stops with Shelter Data for easier communication between parties.
How we built it
A dynamic tileserver works just like any other API. There's a backend API that returns the result of query against a database. In this case, the API is receiving the coordinates of a tile, pulling all shapes in that area, sending the response to the DB, and then packaging that response as protobuf. The webpage's client library understands this protobuf as a map tile and can render at the correct portion of the screen.
OpenStreetMap is an open source database of geospatial data (think Wikipedia for spatial objects). I've pulled the extracts from North & South America into a PostgreSQL database running on an m6g.large instance to help test the viability of my idea. This data was accessed from Geofabrik, a mirror of OSM.
The build process from compressed extract to PostgreSQL is very memory intensive, so to speed the initial load I used a spot r6gd.2xlarge and dumped the DB over to my main, permanent instance after the build was complete.
My API and sidecar containers were deployed with ECS onto Graviton backed instances as well. Because the DB does a lot of the service's heavy lifting, the most important infra decisions were DB related; but I also wanted to ensure that the tile-caching service (redis) that I stood up was on a Graviton instance and able to take advantage of Graviton's fast memory.
The full architecture of the project is available here, some of the key points include:
- Route53/Cloudfront for distribution of the website
- ECS for orchestrating task containers
- EC2 Spot (
c6g.large) for launching the tileserver and related tasks - EC2 (
m6g.large) for hosting the main PostGIS DB - EC2 Spot (
m6g.2xlarge) for one time load of OSM data (~16hrs) - AWS X-Ray for analysis of performance
Challenges we ran into
The build process for the raw OSM file was challenging. Given that the memory requirements to load the data and serve the data were so different (32GB+ vs 4GB), I elected to use a temporary builder instance to get the best build performance for the price. Even with good hardware, this task took 4+ hours + the time to transfer data to storage the serving instance can access.
EC2 storage pricing. Regrettably, there's just no way to get around attaching >1TB of fast storage to an instance without paying quite a bit. I would have loved to host the entire world, but for cost reasons, I adjusted the scope of my project to just North/South America. This allowed me to shrink the volume to 600GB, and hopefully can still demonstrate that this service can perform on large datasets.
Polygon performance. Each layer, point, line, road, and polygon has some baseline assumptions for each tile (e.g. how to truncate shapes across tiles, what zoom level to begin rendering, which objects to load first, etc.) For point, (and to a lesser extent, road and line) these assumptions were easy to guess, but on the hardware I'm using, it was rather difficult to find good baseline assumptions for polygons to load smoothly. Might be worth a bump to an
m6g.xlarge?Concurrent db reads. Because tileservers make dozens of requests at a time, queries can get blocked by lack of access to a connection. On a production system I'd need a way to ensure many users can query tiles simultaneously, this could involve a cluster of read replicas, but for now it's just the one PostgreSQL instance using a connection pool. One way to handle this is bumping shared buffers and memory, but this hasn't been tested enough to implement here.
Rendering in browser. Depending on the browser used, request ordering/rendering behaves variably. Requests to the baselayer (a 3rd party static tileserver, Carto Free Basemaps) take precedence over my requests which leads to a less than ideal user experience.
Accomplishments that we're proud of
I wanted to make a webpage that respected users' data constraints (e.g. a webpage that automatically loads 30MB of content can be quite annoying). Map tiles can be large, but the addition of Nginx allowed me to compress the data that gets sent over to the user by a factor of 2-3x.
I wanted to make sure that even though I was querying hundreds of GB (or TB), performance was still adequate. I was very pleased to get XRay integrated with the core API so I could trace requests systematically, analyze when we get cache hits, and what was causing slow tiles.
What we learned
ECS networking - I've only ever worked with ECS and Fargate before, going to a different network model was a bit challenging, but I'm glad I spent the time to learn about EC2 on ECS.
Benchmarking database performance - I wanted to make sure that I always had observability on the DB and other services. In doing so, I learned a lot about X-Ray and Cloudwatch Agent, both services I'd never used before.
What's next for Tileserver
- Tiles is still a ways away from being a proper "product". In the next month or so, the most likely outcome is that I'll tidy up the Terraform code used to load and update OSM and release that as a module. Loading the OSM data has been a challenge for engineers for at least a decade, it would be nice to abstract the infrastructure required for this job down to a
terraform apply.
Post Submission Considerations
Last week AWS released ARM lambdas, this was pretty interesting for me and I was hoping to integrate a lambda into the app's architecture for the OSM updater component. Unfortunately, large DB updates like this can run for longer than the lambda timeout. In retrospect, this use case is probably best suited for Fargate tasks or scheduled ECS tasks. Instead, I ended up reserving a permanent ECS task for this job. Not the best design, but adequate given I was short on time.
Given more time, I'd likely re-architect some of the choices I made around my ECS Cluster tasks in general. I had originally planned on a single node, and the addition of a second API created more complexity than it's worth. Including the following:
AWS ALB has no mechanism to ensure that a request for a tile "z/x/y/" goes to the same member of the target group. Because each target has it's own cache, this can lead to different versions of the same tile being cached (although rare, worth evaluating), or more likely, unnecessary cache misses.
Redis doesn't need to be tightly bound to the API. In fact, this choice forces me to reserve much more memory than needed for each task instance. In retrospect, a standalone Redis task would have performed quite well. The bright side, however, is that linking within tasks is easier than linking between tasks with CloudMap.
The XRay agent can (should) be its own task. See note above, by having multiple instances the networking is easier, but the task is still bloated.
The API isn't the bottleneck! A second API instance adds minimal benefit unless we can get responses from the DB faster. I might try to crank up the DB's shared buffers and max connections to see the effect on response time before considering into the (significant) cost of a replica.
Built With
- amazon-web-services
- ec2
- golang
- openstreetmap
- osm2pgsql
- redis
- terraform



Log in or sign up for Devpost to join the conversation.