-
Web Scraping Tool
-
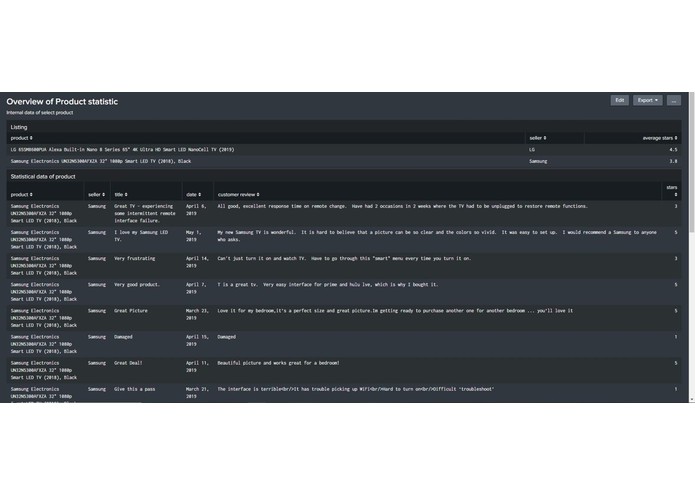
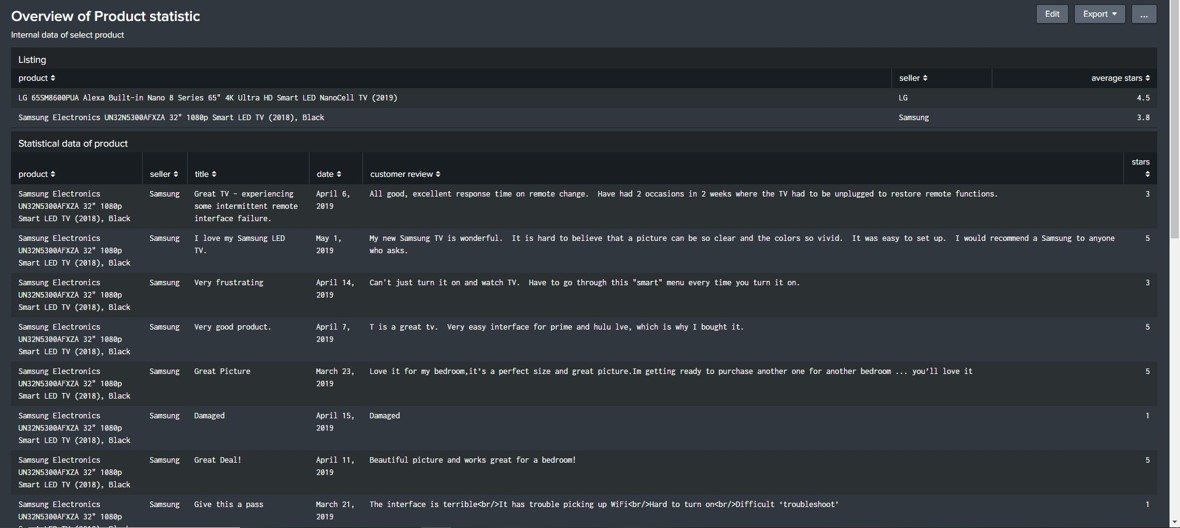
Products Overview Dashboard
-
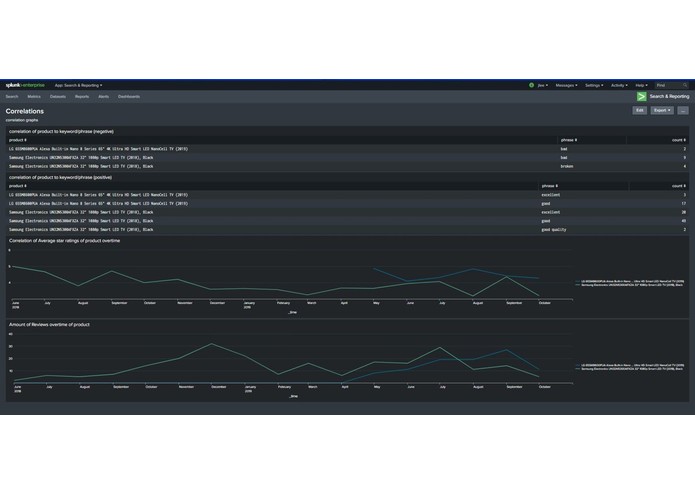
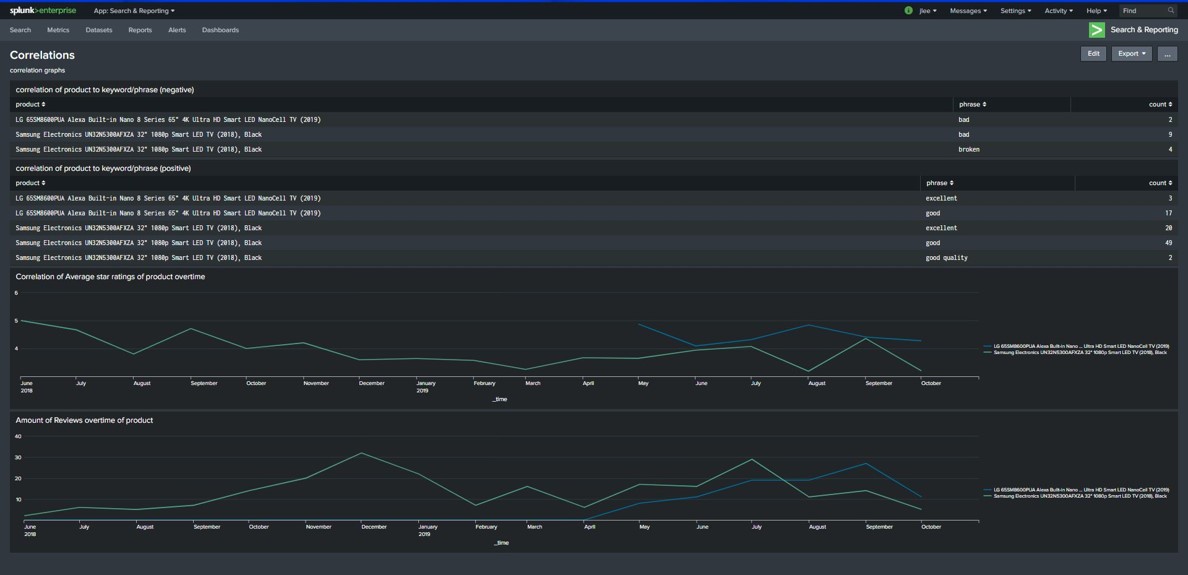
Correlations Splunk Dashboard

Inspiration
Through our work and education we have experience in handling large amounts of machine generated data. One group member has experience using a machine data processing tool called Splunk which we ended up using in this project. We saw this as an opportunity to apply our programming and data wrangling knowledge to something which was new to us, which was user experience analysis.
What it does
The solution that we built provides a way to scrape Amazon pages for large amounts of customer review data and hands the user relevant UX data that can be searched and correlated in various manners. Although the demo only currently scrapes data from Amazon, other sources can be easily added on by adding new aggregator modules.
How we built it
We built the project in 2 parts:
- The data collection tool was written in python and is currently able to scrape customer review data from Amazon. The scraper takes the URL of a product listing and is able to bring back thousands of customer reviews which are forwarded to the Splunk server.
- The Splunk dashboards were then written in Splunk search language to create understandable and relevant user experience overviews based on the collected data. In addition to the dashboard overviews, data can be searched at any time to investigate further information about how customers feel.
Challenges we ran into
As it turns out, Amazon does not appreciate it when you scrape thousands of user reviews from their site as it involves many HTTP requests which adds load to their servers. As a result, Amazon started blocking our requests to their site from our script. We overcame this however, by randomizing the User-Agent portion of our HTTP request headers. This allowed our script to masquerade as different web browsers on different host systems, making our requests seem like legitimate requests coming from different sources.
Accomplishments that we're proud of
First we are proud of the fact that we were able to produce a working demo in such a short amount of time. Other than that we are proud of how fast we are able to scrape user reviews given the fact that we don't have access to an enterprise API. Using our technique we were still able to scrape ~40 reviews per second. We are also extremely proud of how we were able to present the data in Splunk with simple, but informative charts and graphs that would be useful in analyzing UX data.
What we learned
We learned loads about the ins and outs of HTTP requests and how sites like Amazon attempt to prevent bots from doing scrapes. We also got tons of practice writing regular expressions :). Most of all though, we learned about how to think about what is important to people who analyze UX data, which is not something we had thought of before. None of the group members specialize in UI or UX so this was the biggest learning opportunity for us.
What's next for The Complete Experience
We would like to expand into using more sources such as YouTube to collect UX data. We would also like to leverage professional, enterprise level APIs to gather our data rather than using clunky web scraping techniques.

Log in or sign up for Devpost to join the conversation.