-
-
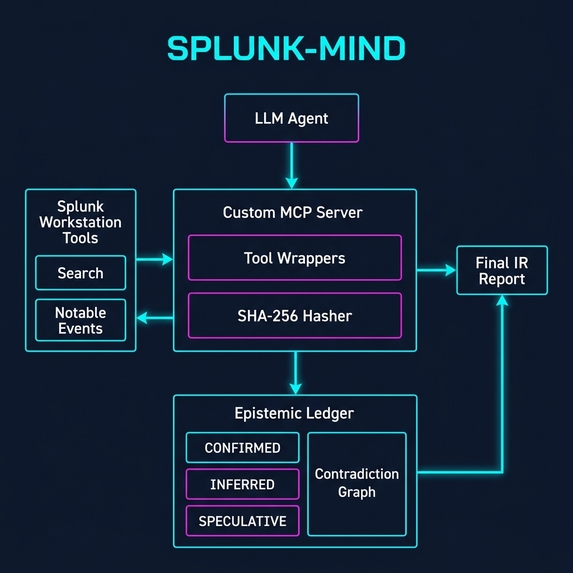
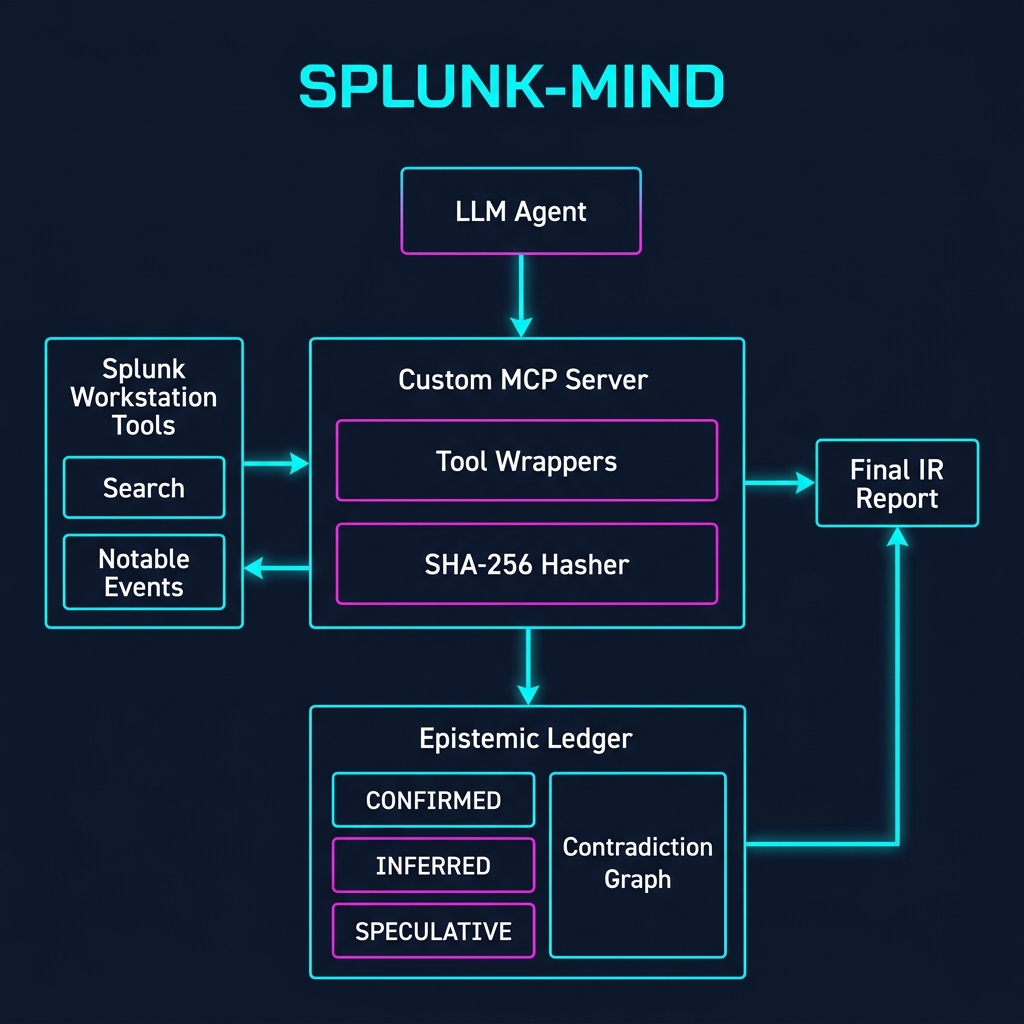
Architecture Diagram
Inspiration
SPLUNK-MIND solves Splunk Enterprise's core failure mode when integrating with LLMs: hallucinations that propagate undetected into incident response reports. When a standard agent receives raw tool output or runs SPL queries, it has no structured way to distinguish what it observed from what it inferred from what it confabulated. These three categories collapse into the same narrative voice and appear in the final report with identical confidence. We set out to fix this fundamentally at the architecture level.
What it does
SPLUNK-MIND makes observation, inference, and speculation architecturally separate through three innovations:
Typed MCP Server with Pre-Parsed Tool Output: Splunk searches and lookups are wrapped as typed, read-only MCP functions. The LLM never sees raw, overwhelming log output — only structured JSON summaries. Epistemic Ledger: Every finding must be submitted with a mandatory confidence tier (CONFIRMED, INFERRED, or SPECULATIVE). The report writer reads exclusively from the ledger. The agent cannot write untagged claims to the report. Contradiction Detection Graph: When two tool results produce conflicting claims (e.g., a Splunk search contradicts a notable event), the ContradictionGraph detects the conflict and hard-blocks the agent until it resolves the discrepancy. Finally, a Cryptographic Evidence Chain hashes every tool call's raw output. Any finding in the final report can be traced cryptographically to its exact source query.
How we built it
We built a custom Model Context Protocol (MCP) Server using Python 3.11 and FastMCP. We use Pydantic for data contracts and an SQLite WAL database for the Epistemic Ledger to ensure multi-writer safety. The system uses local Ollama (qwen2.5-coder:7b) for bounded JSON decisions.
We integrated directly with the Splunk REST API (localhost:8089) to execute live SPL queries and pull real-time telemetry, translating the results into our secure evidence chain. The interactive web dashboard was built using pure HTML/CSS to visualize the contradiction graph and hash verification in real-time.
Challenges we ran into
Handling the massive output from Splunk searches without blowing out the LLM's context window was a major hurdle. We had to design tight SPL query limits and robust JSON parsers for the MCP server.
Another challenge was contradiction rule design: determining when two findings actually conflict vs. when they are just measuring different timestamps required deep domain expertise to encode. Finally, we had to heavily engineer the system prompts to ensure the LLM complied with the strict ledger_add_finding() protocol instead of just writing prose.
What we learned
The hallucination problem in Splunk Enterprise is not a prompt problem, it's a data structure problem. Give the LLM a schema—enforced architecturally, not through prompting—and hallucinations can't propagate. Furthermore, contradiction detection is far more valuable than simple retry loops. Real self-correction means detecting why tools disagree and adjudicating the conflict.
What's next for SPLUNK-MIND
Multi-agent extension: Decomposing into specialized Endpoint, Network, and Memory agents that all write to the shared Epistemic Ledger. Wider SIEM integration: Expanding the MCP tools to correlate data across multiple SIEM platforms simultaneously. Community tool library: Allowing the DFIR community to add new SPLUNK tool wrappers following the same ToolResult contract.

Log in or sign up for Devpost to join the conversation.