-
-
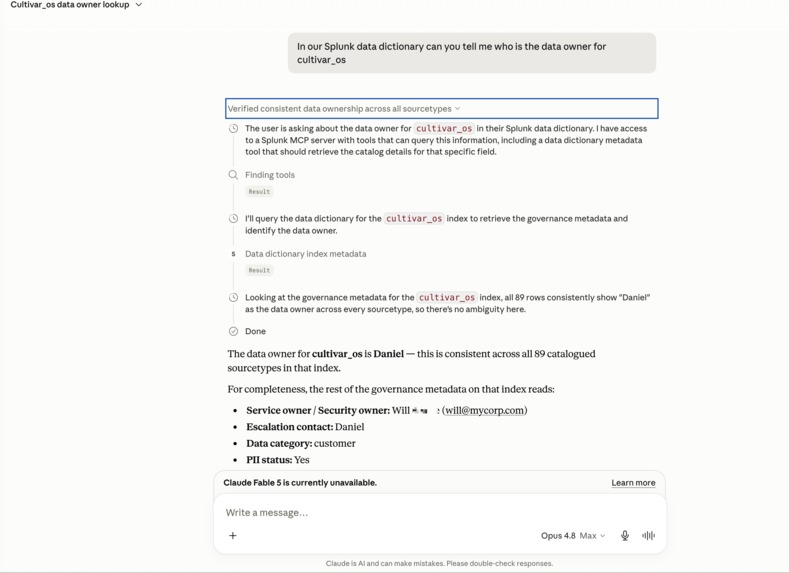
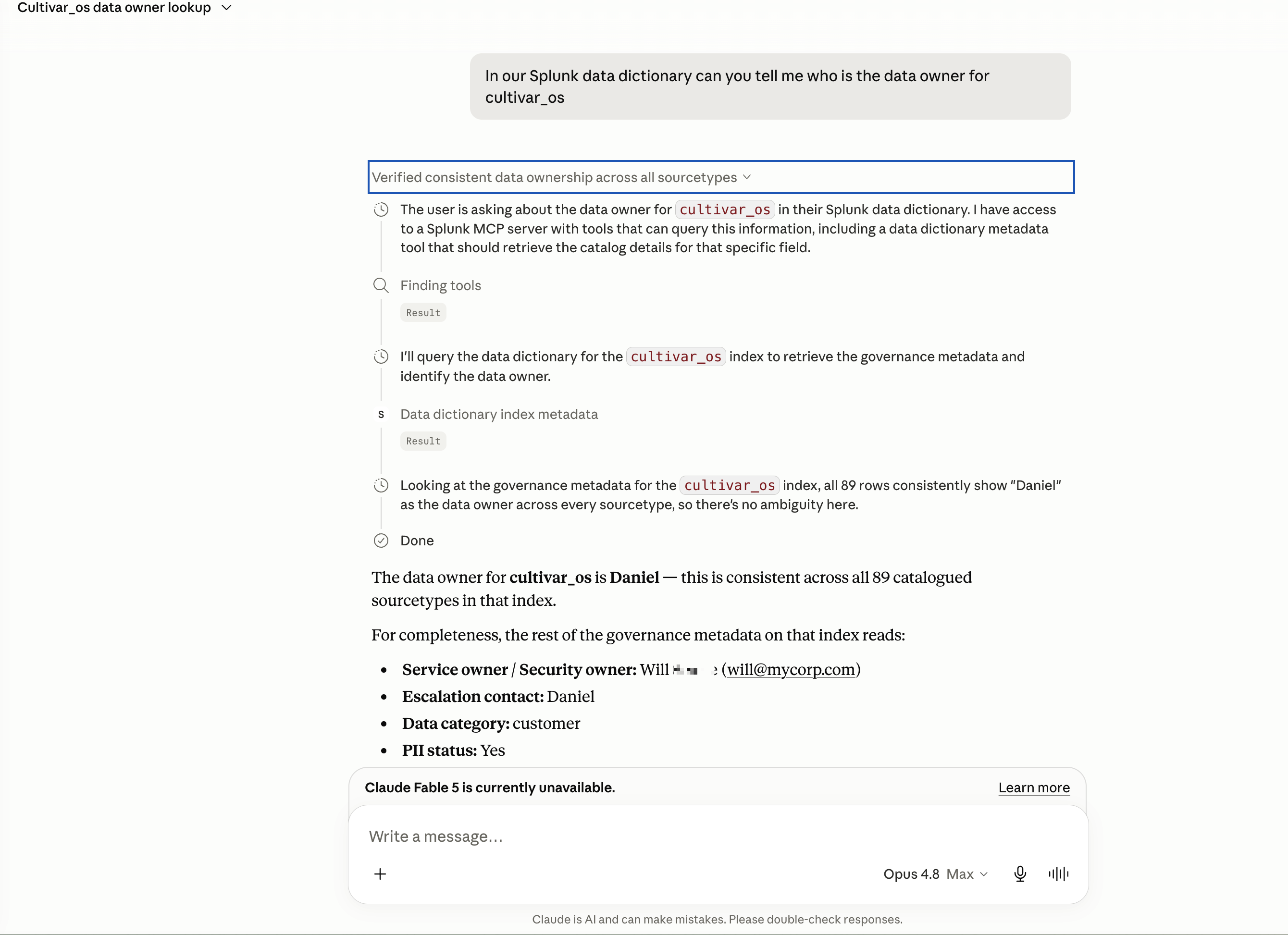
Claude Chat - Simple retrieval of index metadata for managing index access, security and operations.
-
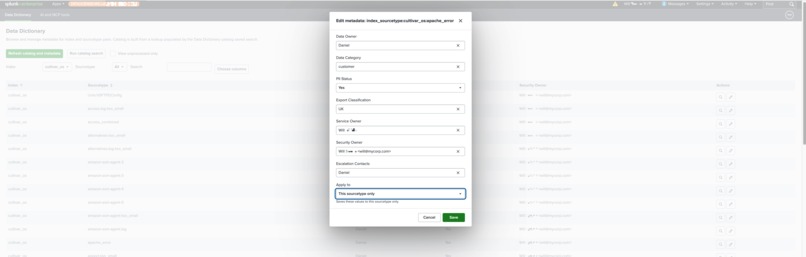
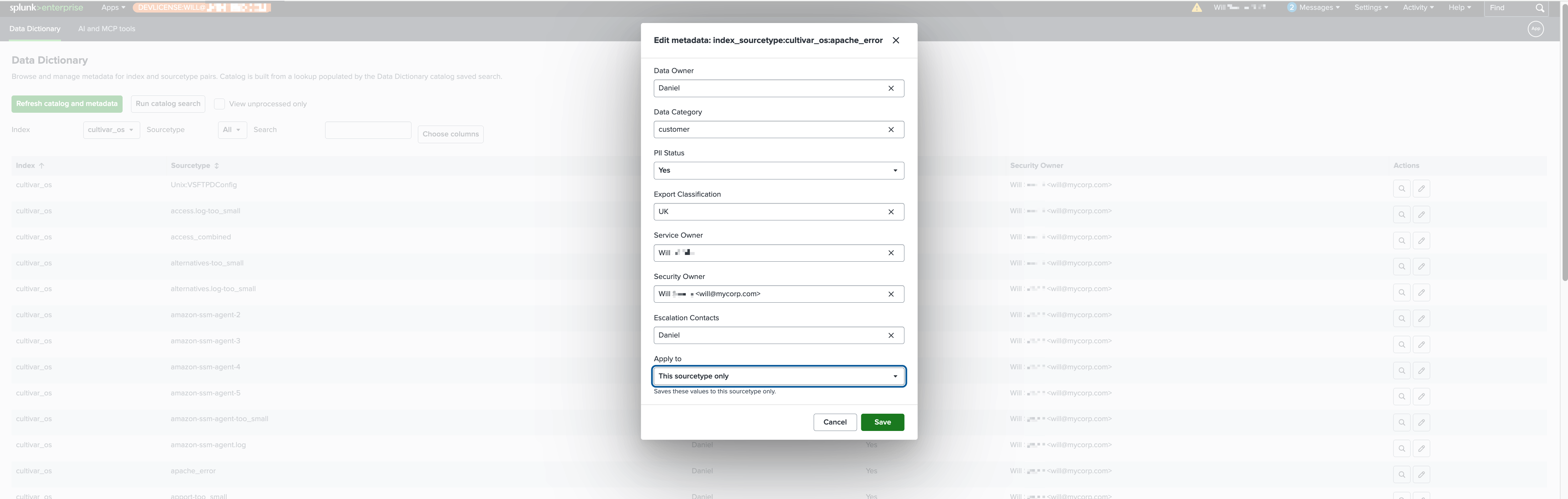
Splunk UI - Edit/View metadata easily to allow the data to be queried using the MCP Tools from external services.
Inspiration
In any large or enterprise Splunk estate, the questions hardest to answer are typically around what data we actually hold, who owns this data, does it contain PII, how is it classified, whose sign-off do I need before granting access, this could live in spreadsheets, wikis and people's heads. At the same time, AI assistants are arriving in everyone's day-to-day tools, yet they can't answer governance questions responsibly without a trustworthy, structured source behind them. I wanted to make Splunk itself that source of truth, and to put the answers in front of the many colleagues who don't live in Splunk Web all day, and offer a simple way for existing Splunk users to find the answers they need too.
What it does
It catalogues every index and sourcetype in the estate and attaches structured governance metadata to each - Data Owner, Security Owner, Service Owner, Escalation Contacts, PII Status, Data Category and Export Classification. Administrators curate it through an familiar Splunk ReactUI based interface inside Splunk Web (set values at row, index or sourcetype level with sensible inheritance, value-suggesting dropdowns, a Yes/No PII control, and an "Apply to index" bulk action). Crucially, it exposes that catalogue as three read-only Splunk MCP tools, so any MCP client can ask, "whose sign-off do I need for the firewall indexes?" and get an accurate, grounded answer with no SPL and no Splunk login.
How I built it
A native Splunk app built with Splunk's official UCC framework, Webpack and @splunk/react-ui. The catalogue is a CSV lookup populated by a saved search; governance metadata is held in the KV Store and surfaced to SPL via a kvstore lookup, merged row -> index -> sourcetype. The MCP tools are defined in a signature JSON that the Splunk MCP Server auto-imports into its mcp_tools collection; each tool executes as pure SPL (inputlookup + lookup). Delivery is to professional-services standards: CI reuses the shared livehybrid/deploy-splunk-app-action pipeline (wrapping Splunk's official AppInspect CLI and cloud-API actions), with a live-Splunk-in-Docker Playwright integration job and tag-driven GitHub Releases.
Challenges we ran into
- Tool selection is a real problem: agents simply wouldn't call the tools while their descriptions were mechanism-focused. We had to rewrite them in governance/ownership language ("who owns…", "whose sign-off…") before agents reliably chose the right one.
- Registration is automatic, but we faced issues developing as there didnt seem to be an automatic re-registration on change. - we learned to re-invoke its batch-replace registration to push updates live.
- Standing up a real Splunk in CI needed the right licence-acceptance variables and generous first-boot timeouts.
- There are currently no APIs to start Splunk Cloud Developer Edition (SCDE) stacks so this needed hand-cranking.
Accomplishments that we're proud of
- A genuinely agent-ready governance layer: a non-Splunk user can get an accurate ownership/sign-off answer inside Claude (or LLM of users choice), grounded in live Splunk metadata, without touching SPL.
- Engineering rigour: AppInspect-clean (0 errors, 0 failures) via Splunk's official actions in a reusable pipeline, end-to-end tested against a real Splunk in CI, third-party licences attributed, and releases auto-published from a tag.
- Safe by design: read-only tools, RBAC-respecting, sandbox-safe.
What we learned
- MCP tool descriptions are a UX surface - they're how an agent discovers capability, so they must speak the user's language, not the implementation's.
- Pure SPL is the safe, portable way to expose Splunk data as MCP tools, with REST integrations planned on the roadmap to make changes to metadata using MCP tools too.
- An assistant is only as trustworthy as the catalogue behind it: governance metadata turns a guess into an answer.
- Reusing Splunk's official pipelines (UCC, AppInspect) buys credibility and saves real time.
What's next for Splunk MCP based Data Dictionary
- Write-back over MCP - propose and update governance metadata through a consented tool, so curation can happen in the flow of conversation.
- Splunkbase release and Splunk Cloud validation.
- Richer governance - retention/freshness, data lineage, CIM mapping, and owner-directory integration.
- A coverage view that flags un-owned or likely-PII data and proactively prompts for classification.
- Hardening: a Splunk version test matrix, seeded-catalog integration coverage, and clear the AppInspect future-deprecation notice.

Log in or sign up for Devpost to join the conversation.