-
-
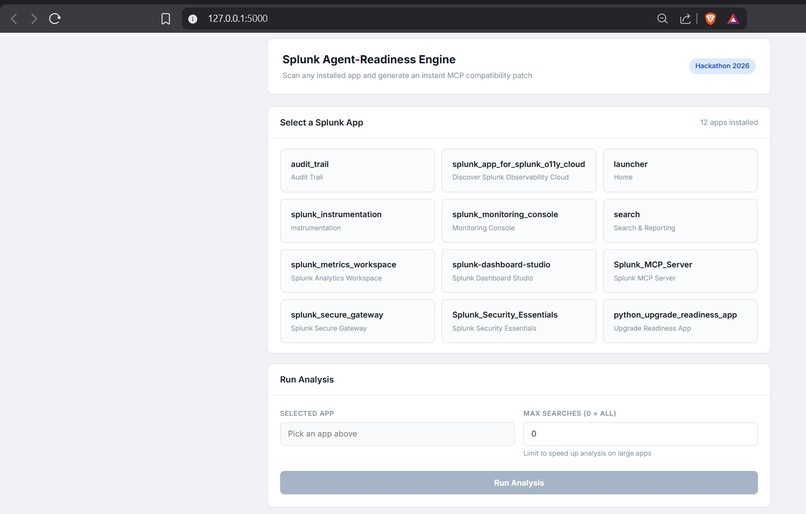
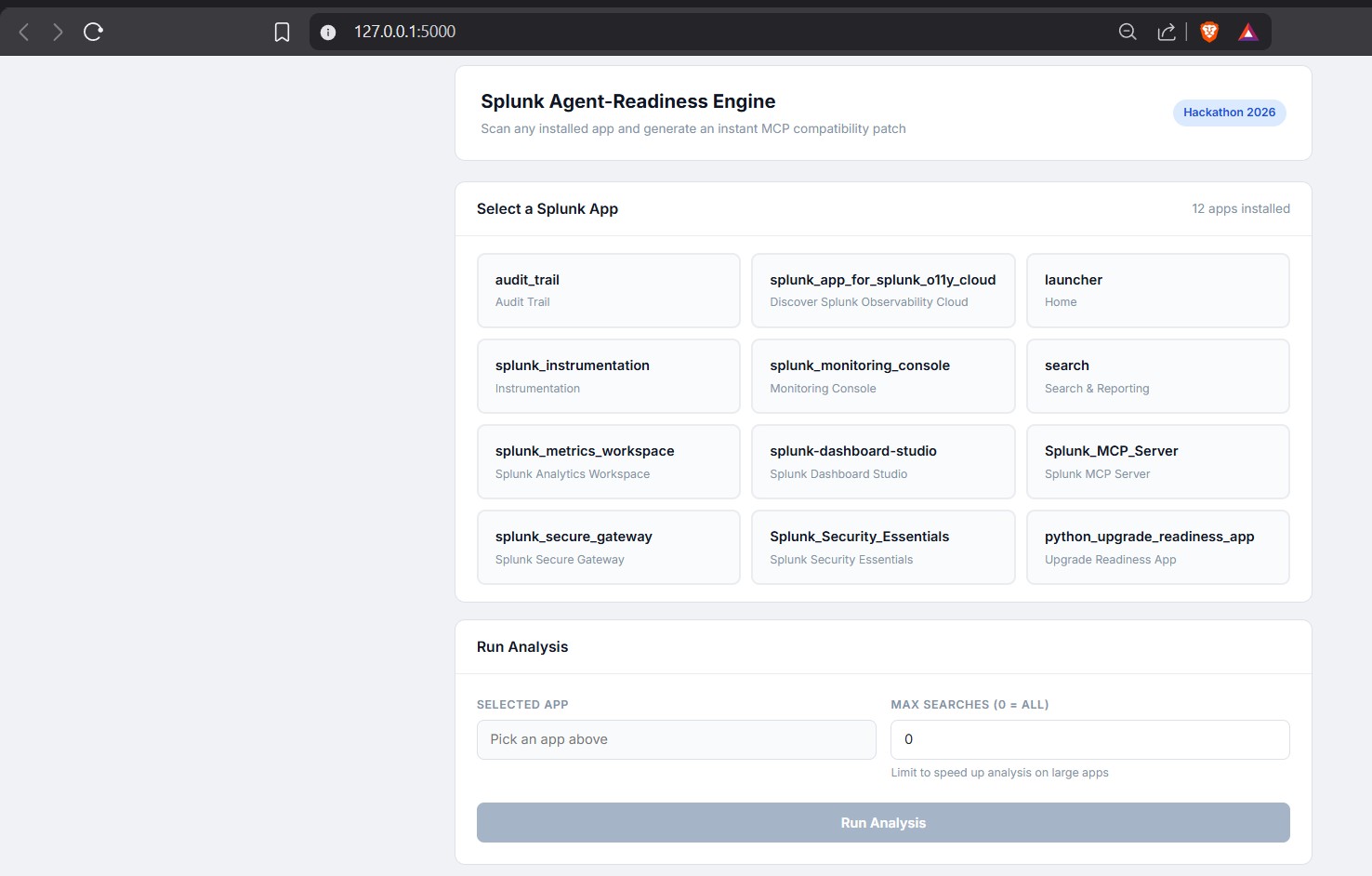
the application automatically detects all installed apps in your splunk enterprise ,we can select the app to generate semantic description
-
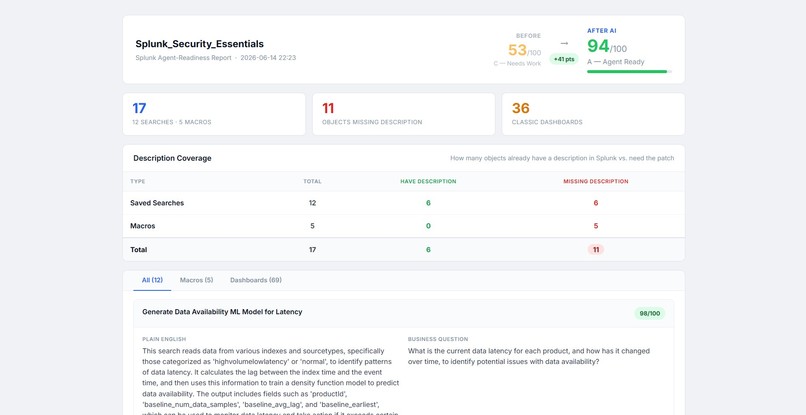
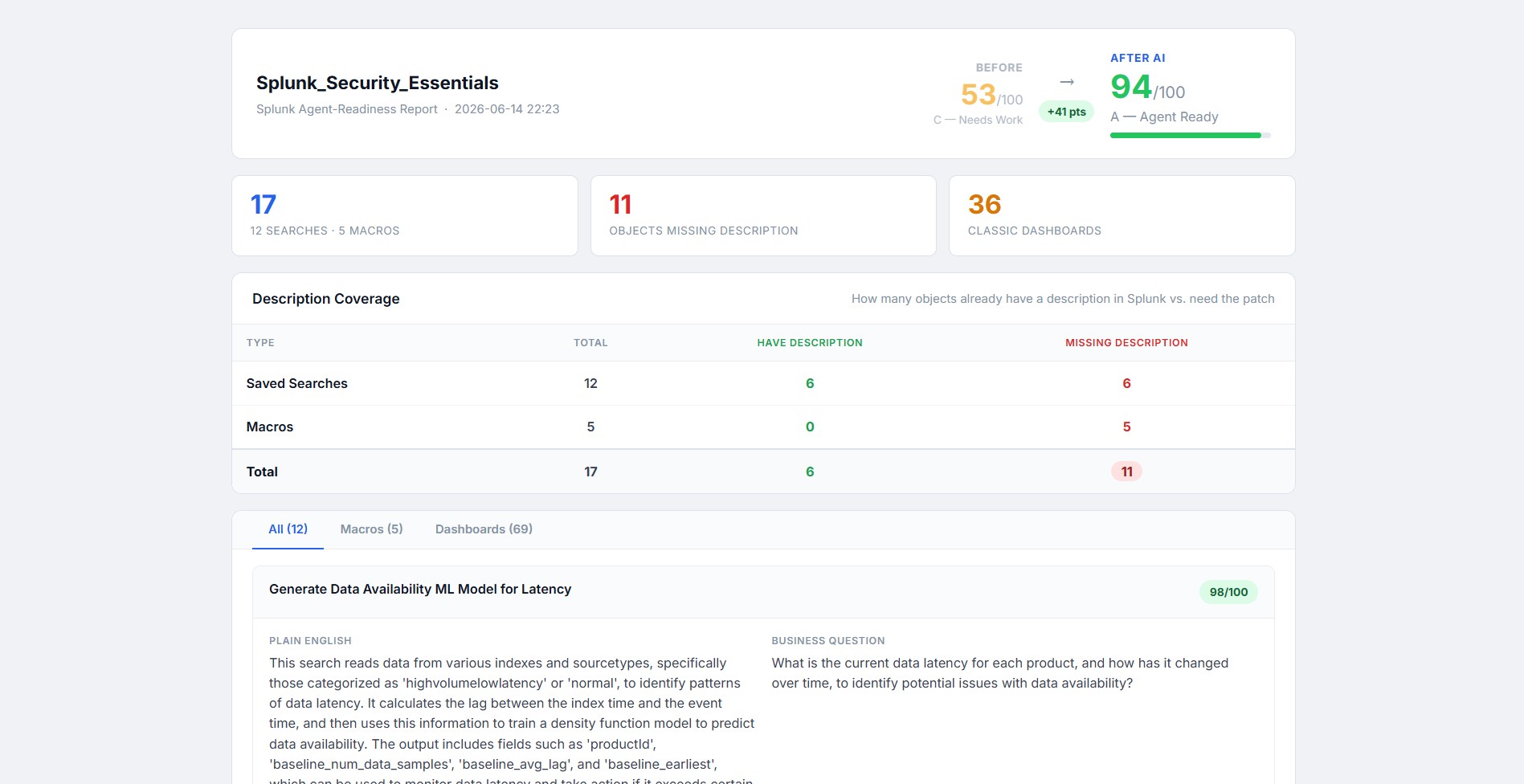
finds the no of saved searches,macros,dashboards present in the app and classifies them based on if they have semantic description or not
-
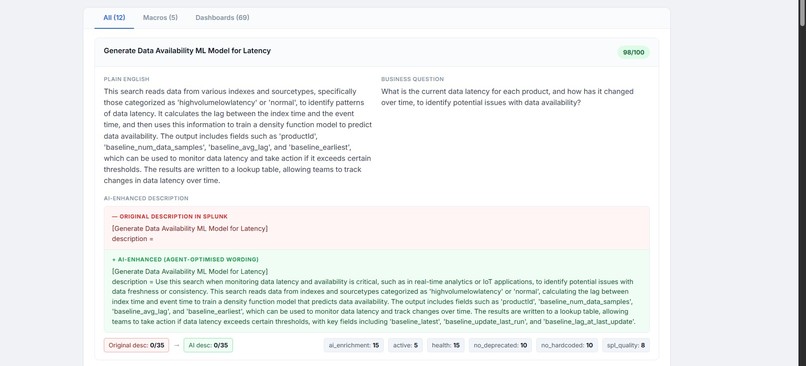
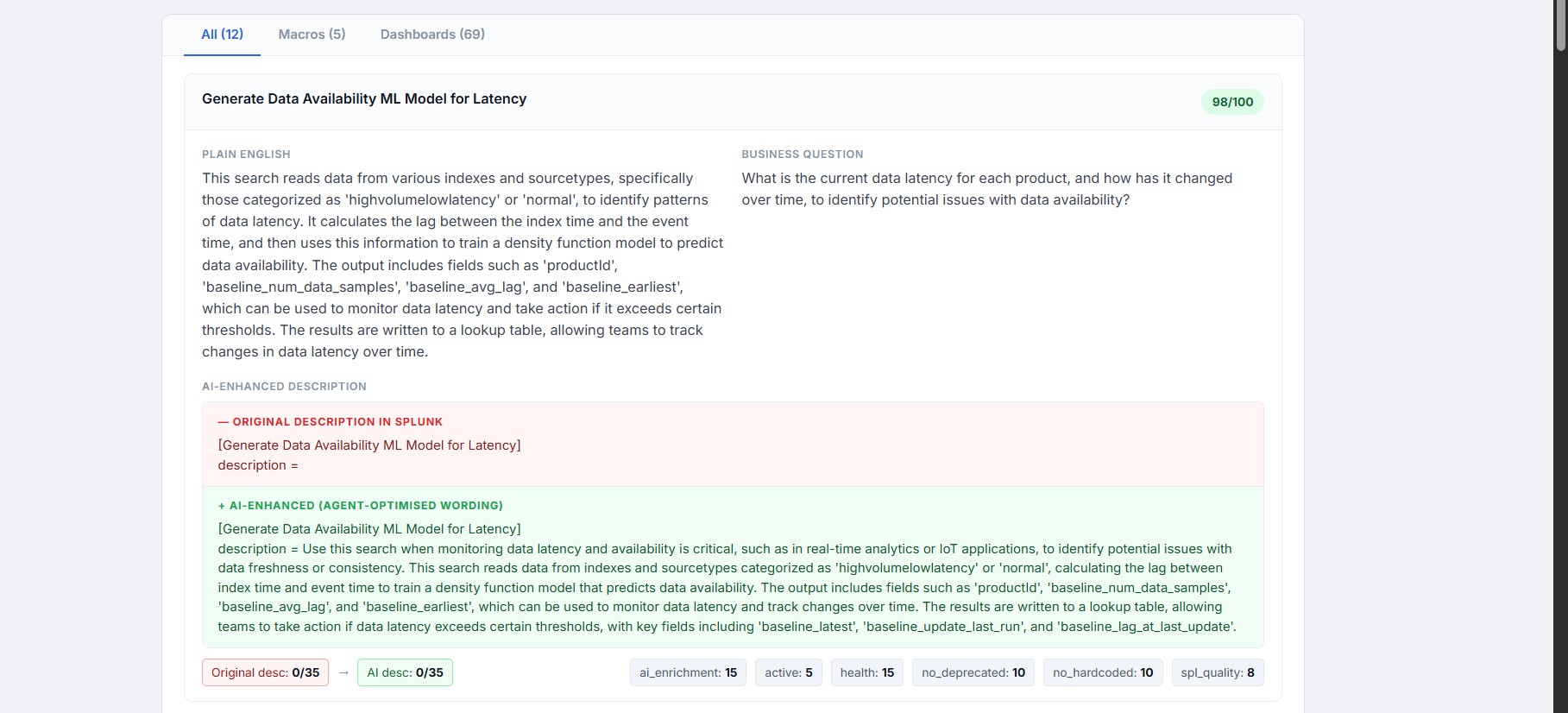
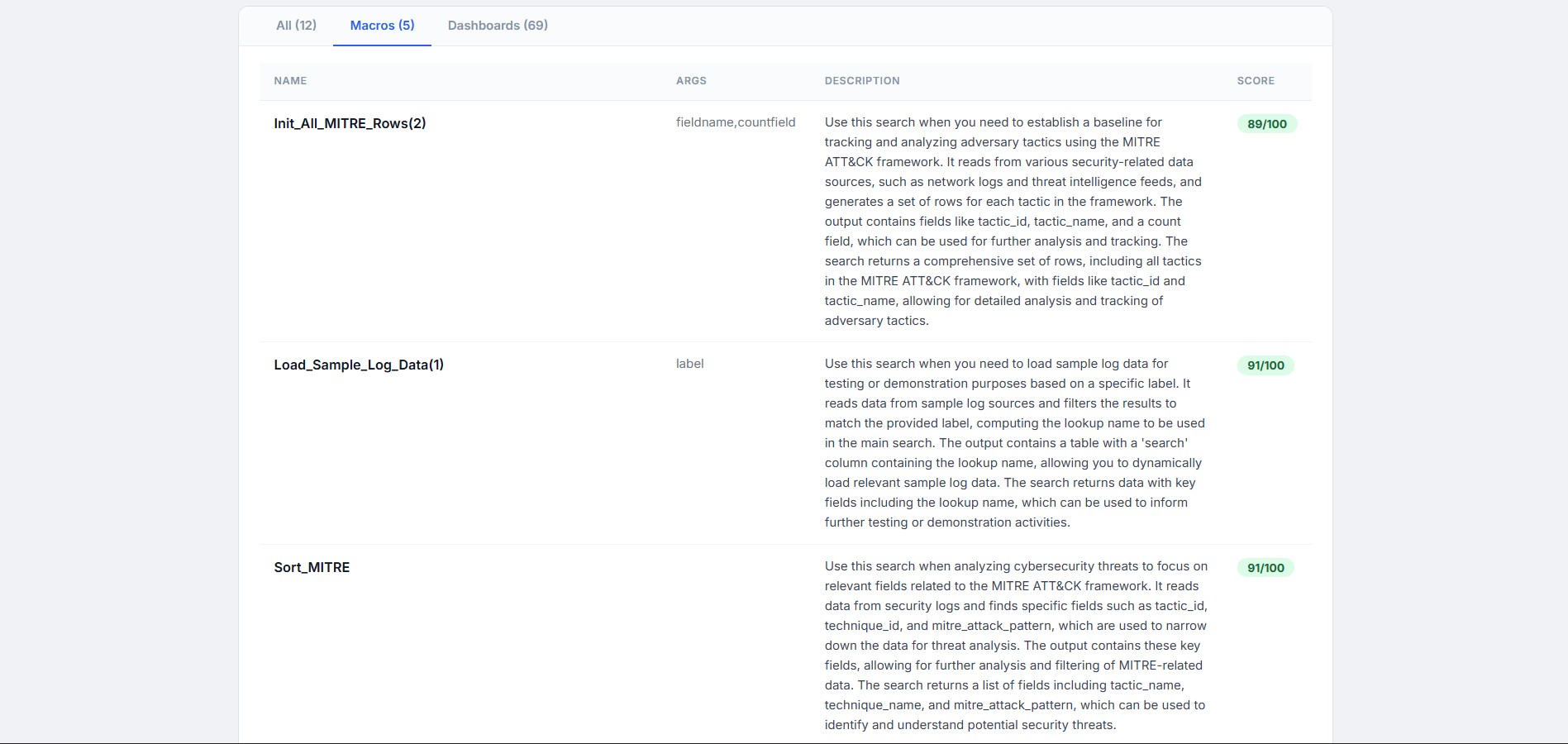
generates a description of what each saved search does,semantic description which will be used by the mcp server
-
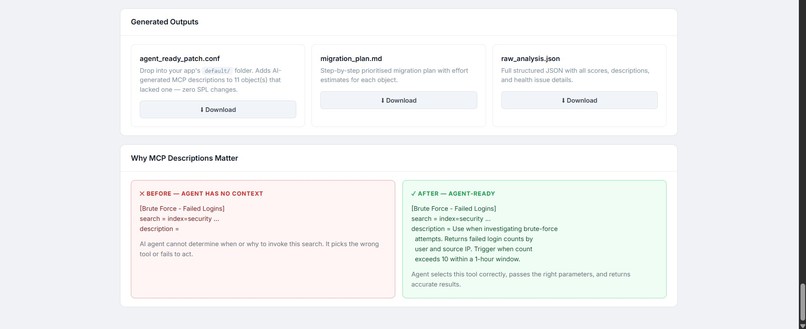
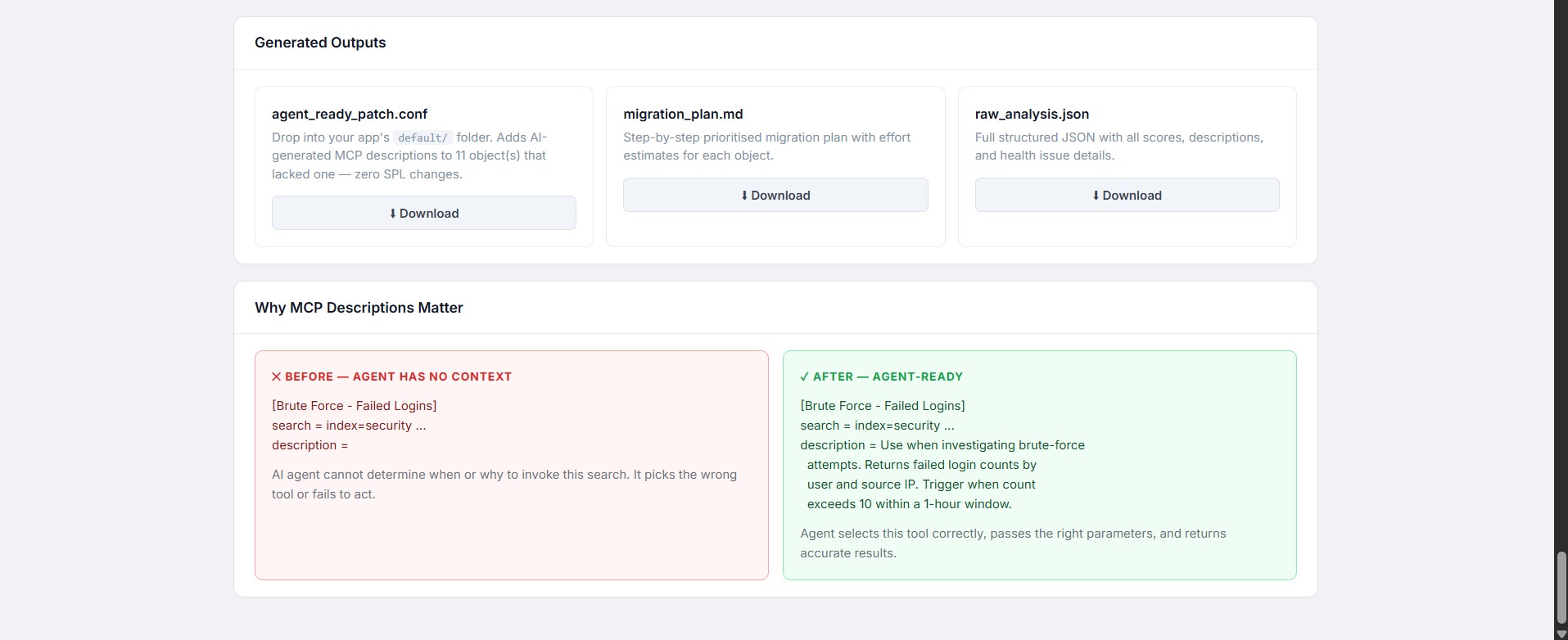
produces a .conf file containing the semantic description for every saved search tool paste this file in the local\ directory
-
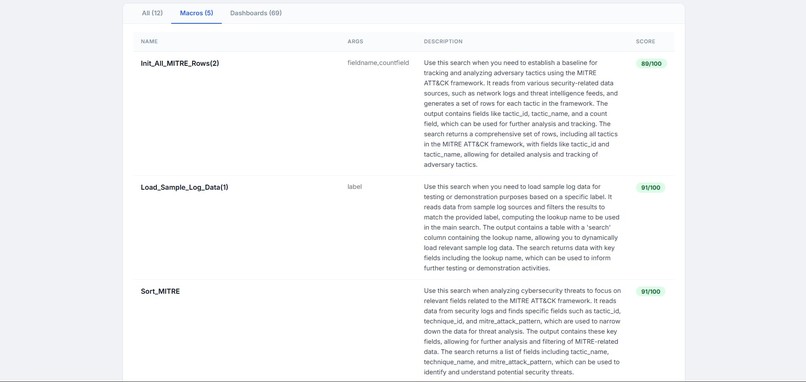
generates description and input arguments for all the macros
-
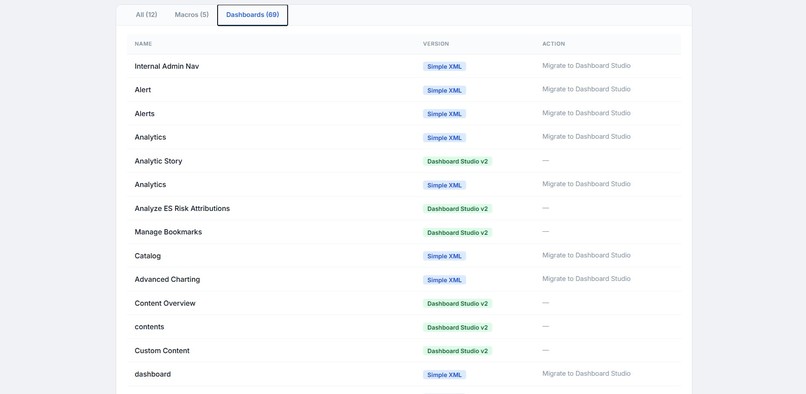
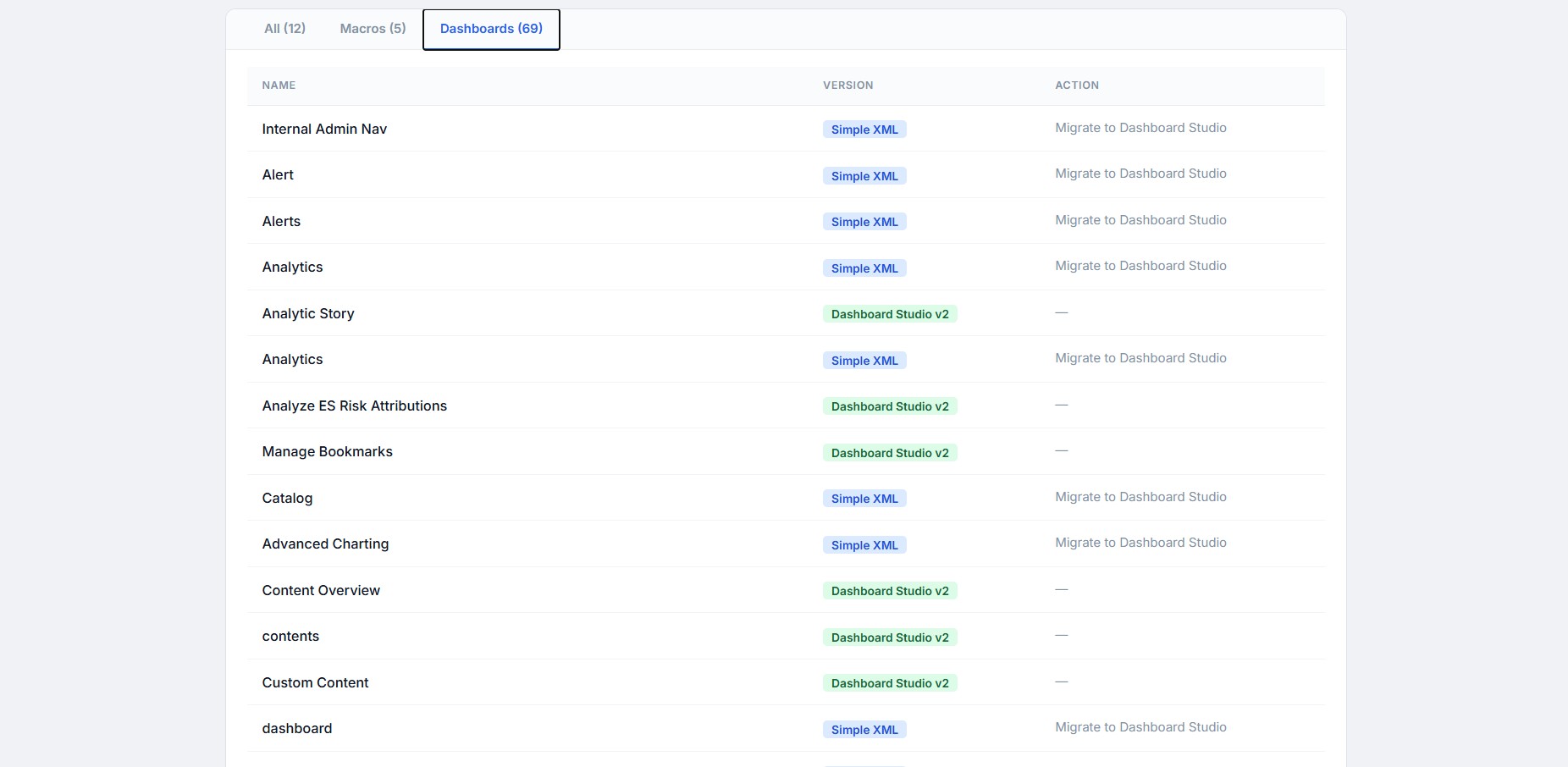
identifies deprecated dashboards which needs to be migrated to dashboard studio
-
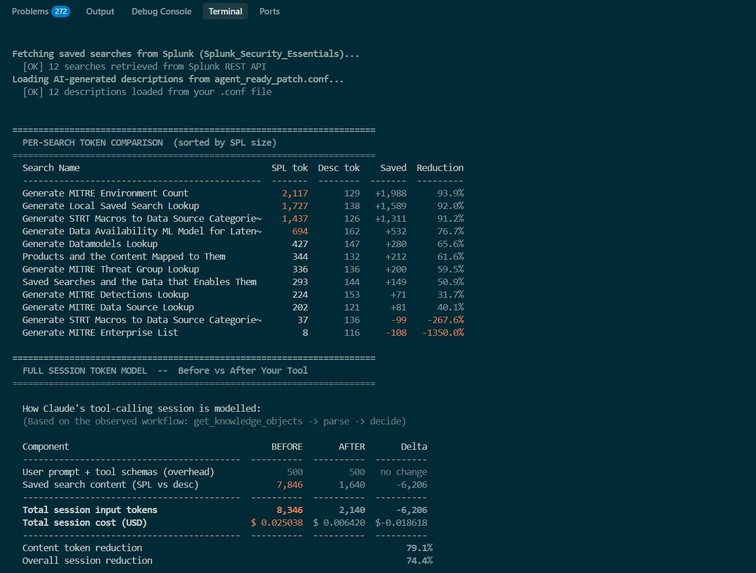
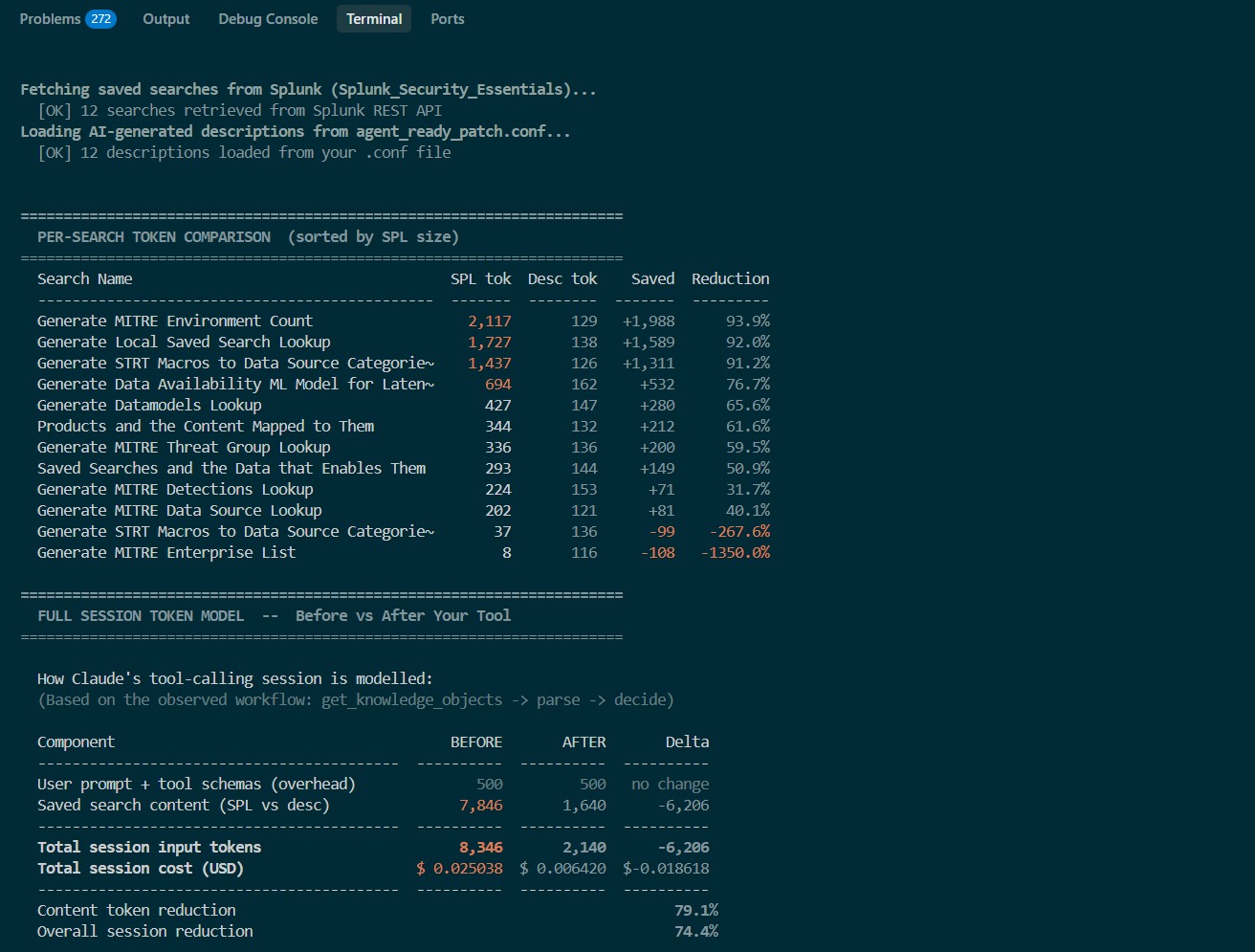
token usage before and after using our tool
Inspiration
When Splunk announced their new Model Context Protocol (MCP) Server, it was a game-changer. It meant AI assistants like Claude could finally talk directly to Splunk to help security and operations teams investigate issues.
But there was a massive blind spot: AI agents need plain English descriptions to understand which tool to use. We realized that out of the 1,700+ apps on Splunkbase, most of them are filled with complex, raw code (SPL) and no human-readable context. As a result, when you connect an AI to Splunk today,It has to read hundreds of lines of code just to guess what to do—which is slow and expensive We wanted to build a bridge to fix this instantly.
What it does
The Splunk Agent-Readiness Engine makes any legacy Splunk app instantly visible and understandable to modern AI agents.Instead of forcing developers to manually rewrite documentation for thousands of searches, our engine automates the entire process
It deep-scans a Splunk environment, checks the health of the existing searches, and uses AI to reverse-engineer the complex code. It then automatically generates clear, semantic (plain English) descriptions for every single tool.
Finally, it packages these descriptions into a simple configuration file that you can drop right back into Splunk. Instantly, your AI agents know exactly what your tools do and when to use them.
How we built it
We built the core engine using Python to deeply integrate with Splunk's ecosystem. It connects directly to Splunk using their REST API to pull down live data and code.
For the "brain" of the operation, we integrated the Groq API running the Llama 3.3 model.We also built a web interface using Flask that shows users the available splunk apps in their splunk enterprise so they can select for which app they need to generate semantic descriptions
Challenges we ran into
One of the biggest challenges was making sure our engine didn't get confused by massive, poorly written legacy code. Some Splunk searches are hundreds of lines long and contain deprecated commands or formatting errors. We had to build a robust "Health Checker" module that acts as a filter, cleaning up and auditing the code before we even send it to the AI for translation.
Accomplishments that we're proud of
We are proud of the live Token Counter we built to prove our tool's value.Our counter runs against live Splunk data and proves that by using our generated plain-English descriptions instead of raw code, we reduce the AI's processing load (token consumption) by over 74% per session
What we learned
We learned that the biggest bottleneck to Enterprise AI adoption isn't the AI models themselvesit's the messy, legacy data structures they are forced to interact with. AI is incredibly smart, but if you feed it raw, undocumented code, it will stumble. We learned how critical "semantic context" (human readable intent) is for AI routing
What's next for splunk agent readiness engine
Right now, our tool is a one-time scanner. The next step is to turn it into an automated, continuous pipeline. We want to integrate it directly into the CI/CD deployment process, so anytime a Splunk developer writes a new search or updates a dashboard, our engine automatically checks its health, scores its "AI Readiness," and generates the proper descriptions before it even goes live. We want to ensure that as the Splunk ecosystem grows, it stays 100% visible to the AI agents of the future.

Log in or sign up for Devpost to join the conversation.