-
-
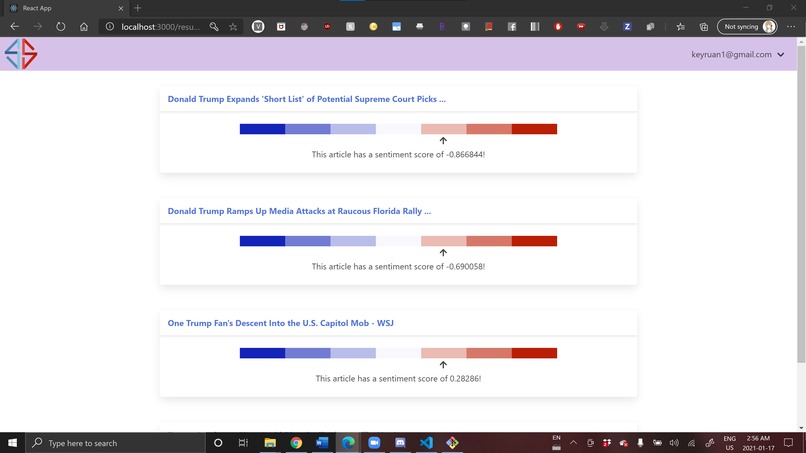
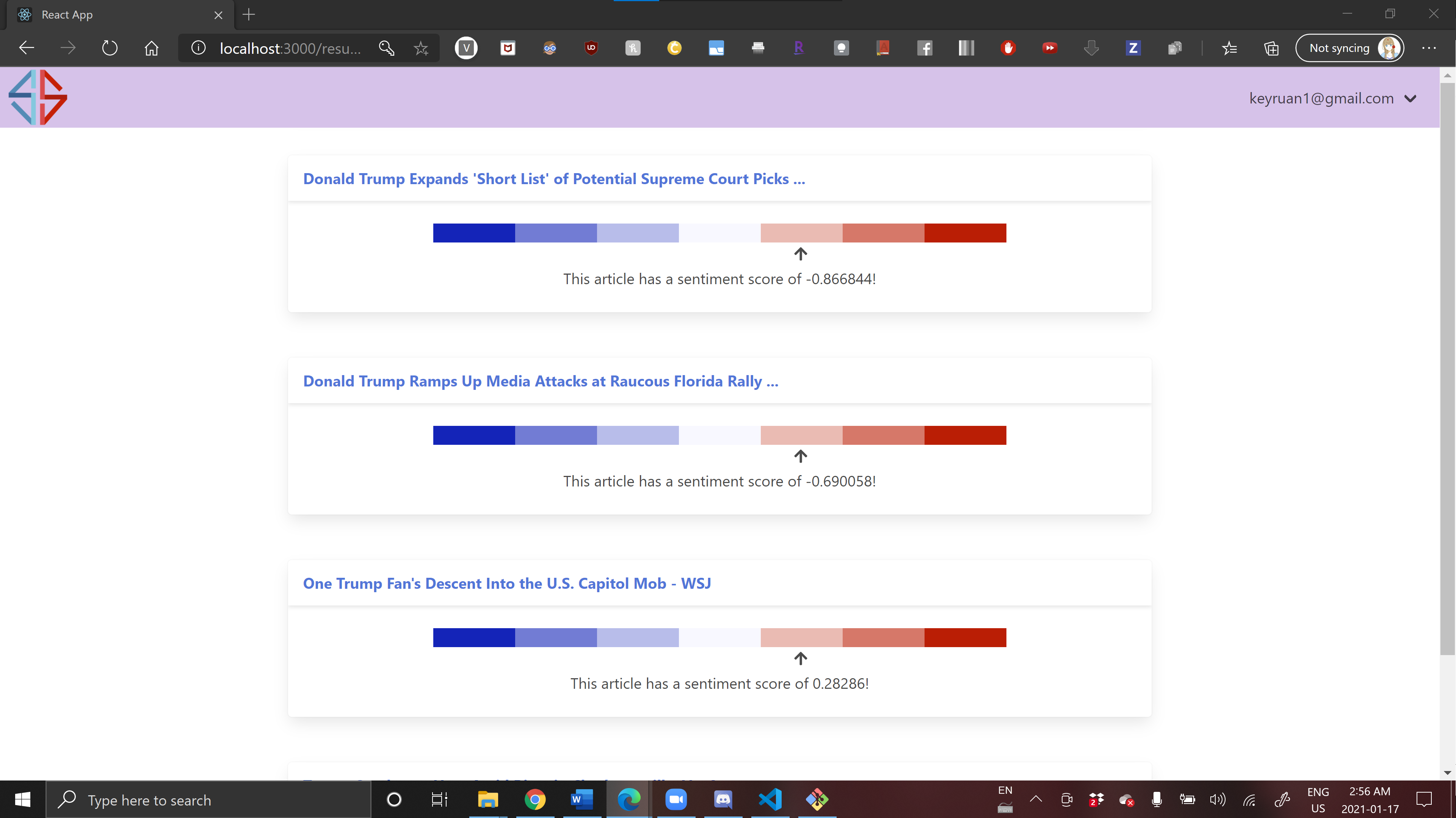
Web app -- results are given. The given article was a left-leaning article, so the suggested articles are right-leaning.
-
Web app -- this is a view of the log in page for users.
-
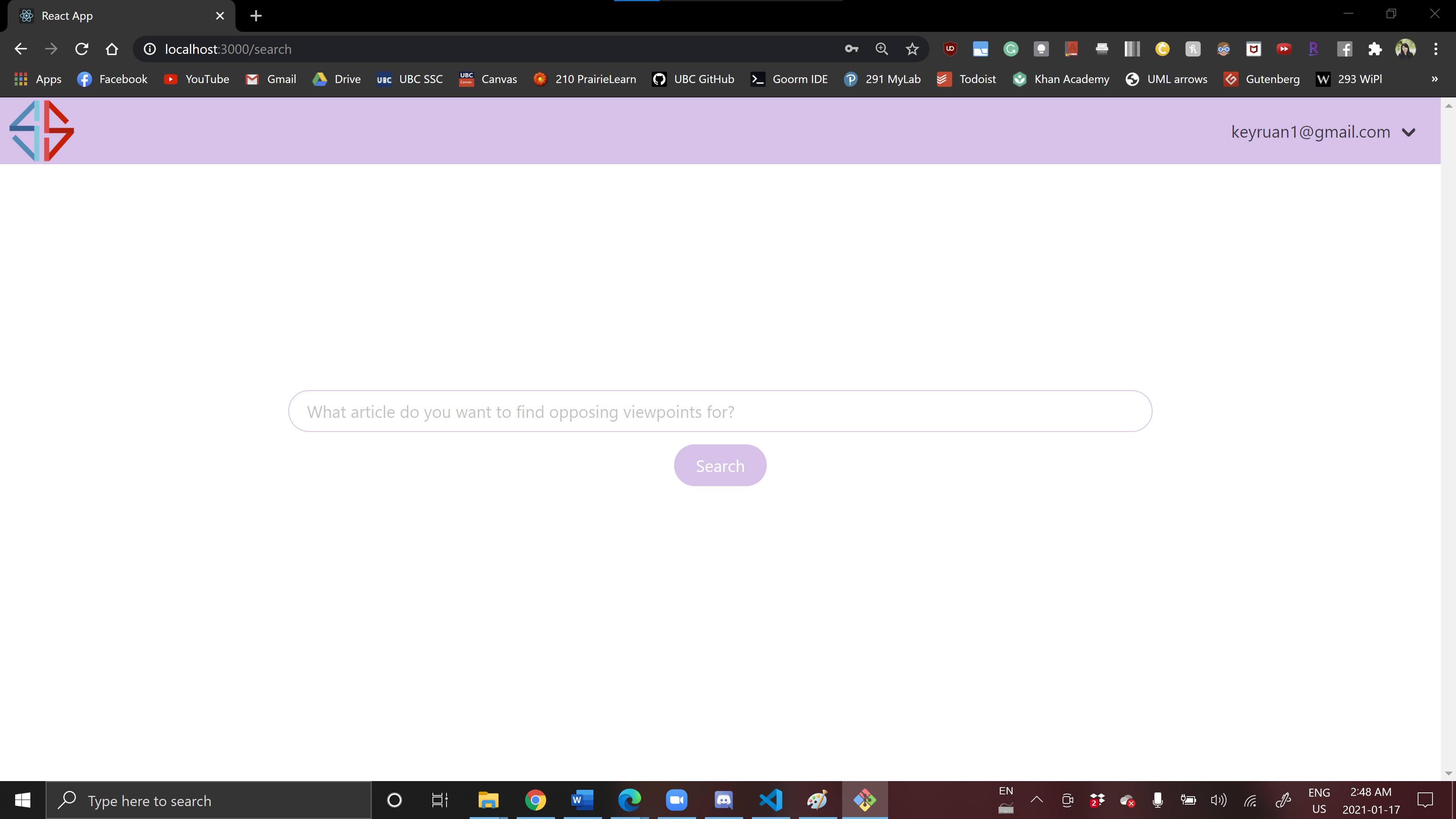
Web app -- users paste an article url into the search bar and click Search :)
-
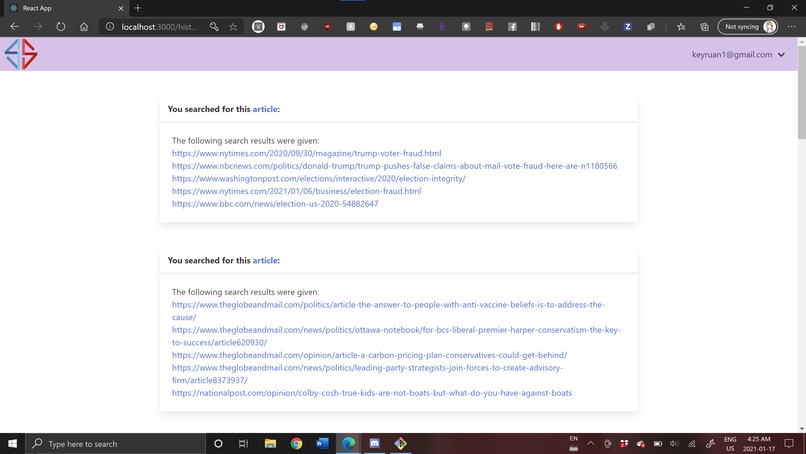
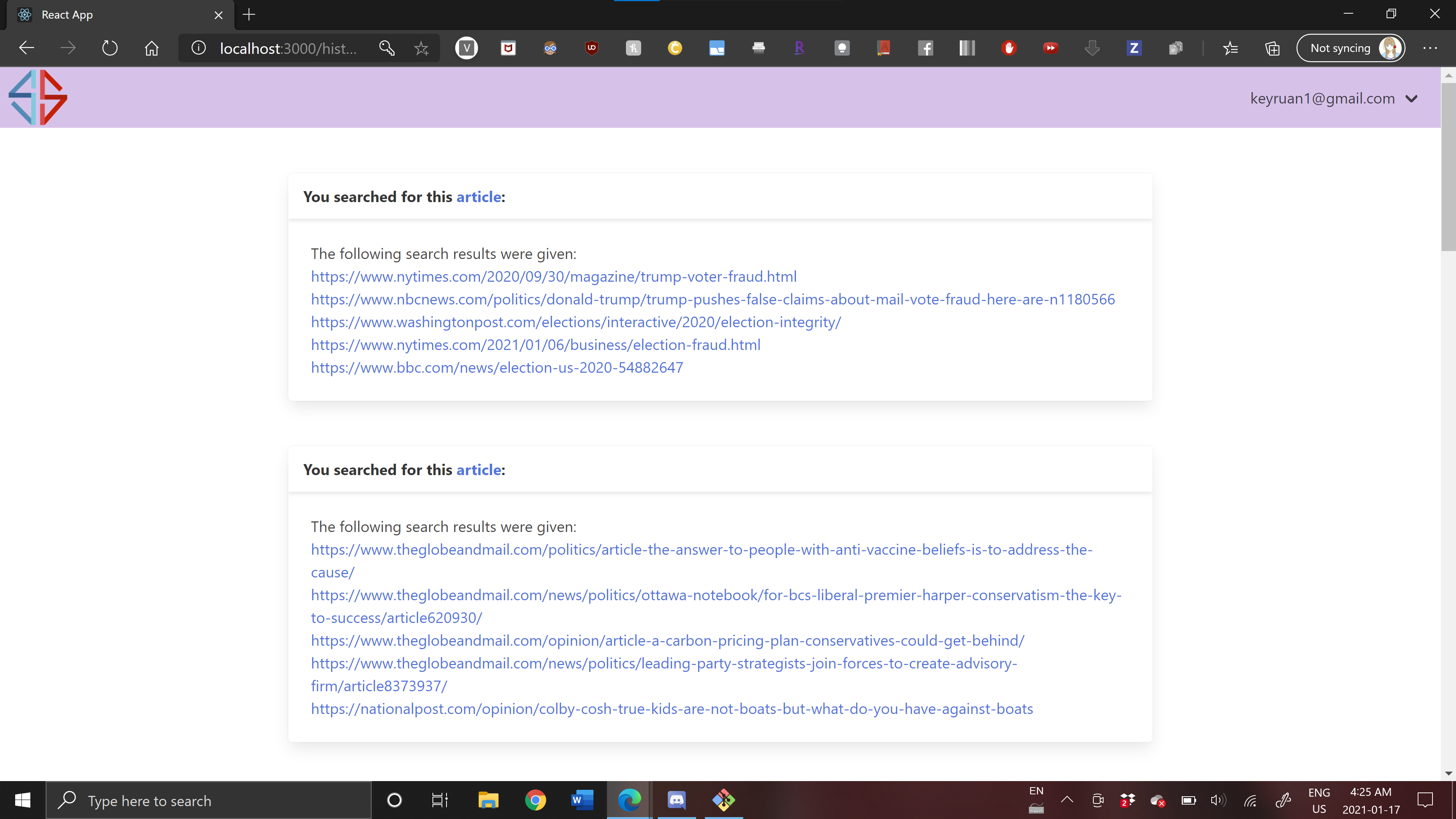
Web app -- users that are logged in can see their search history with the articles suggested.
-
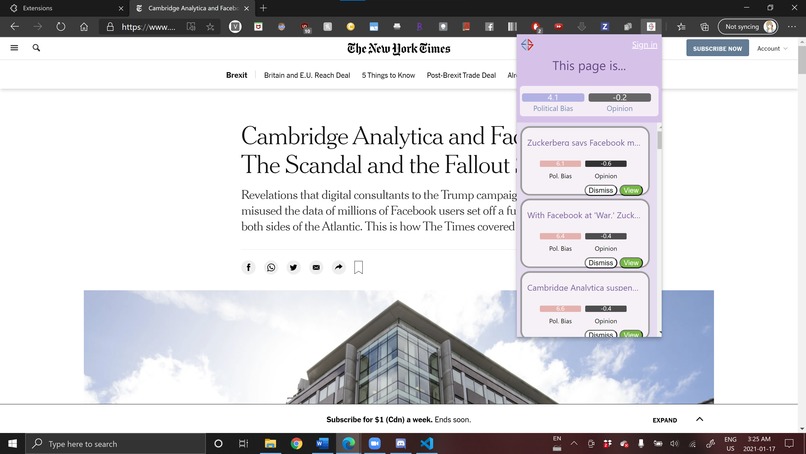
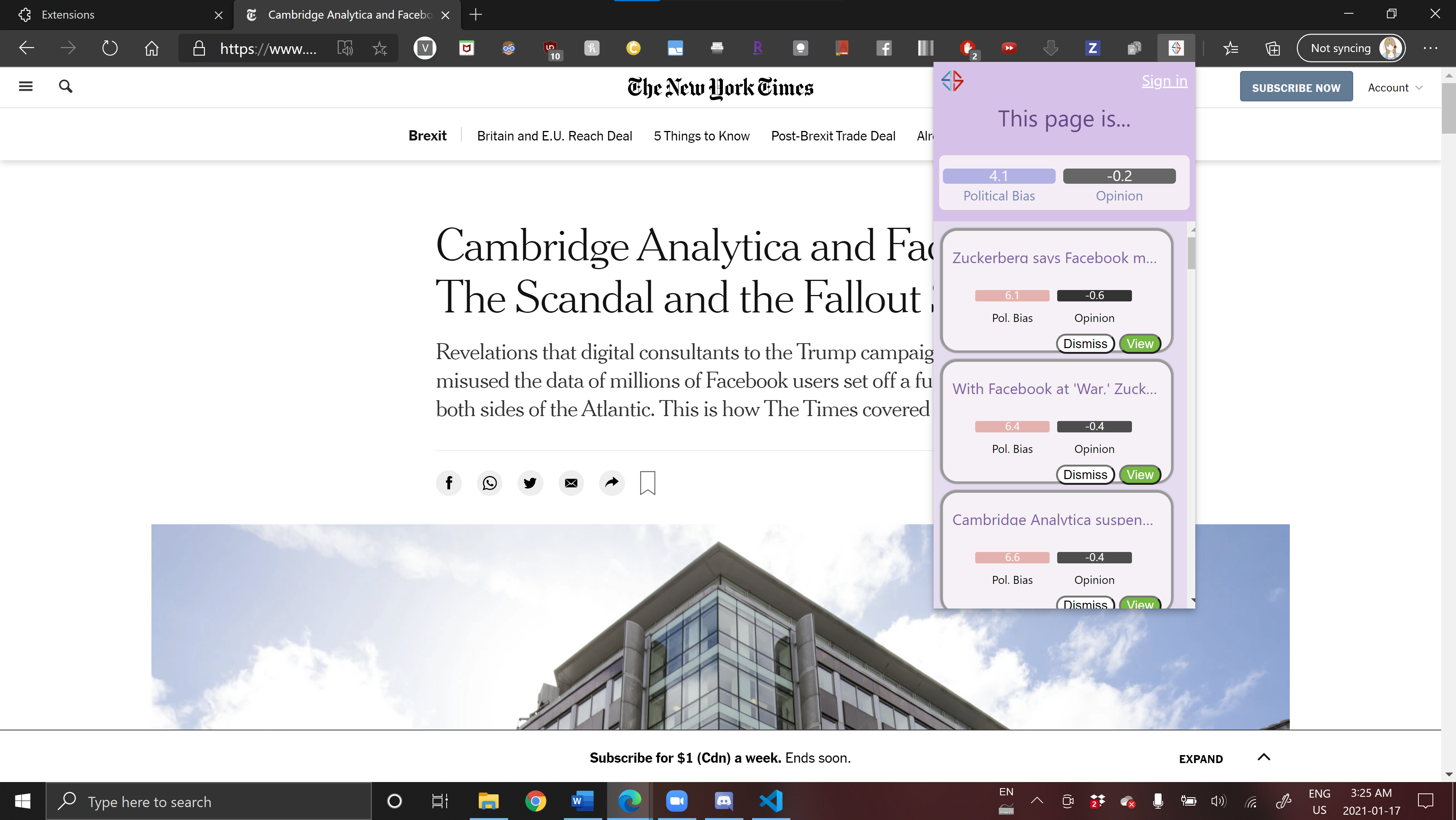
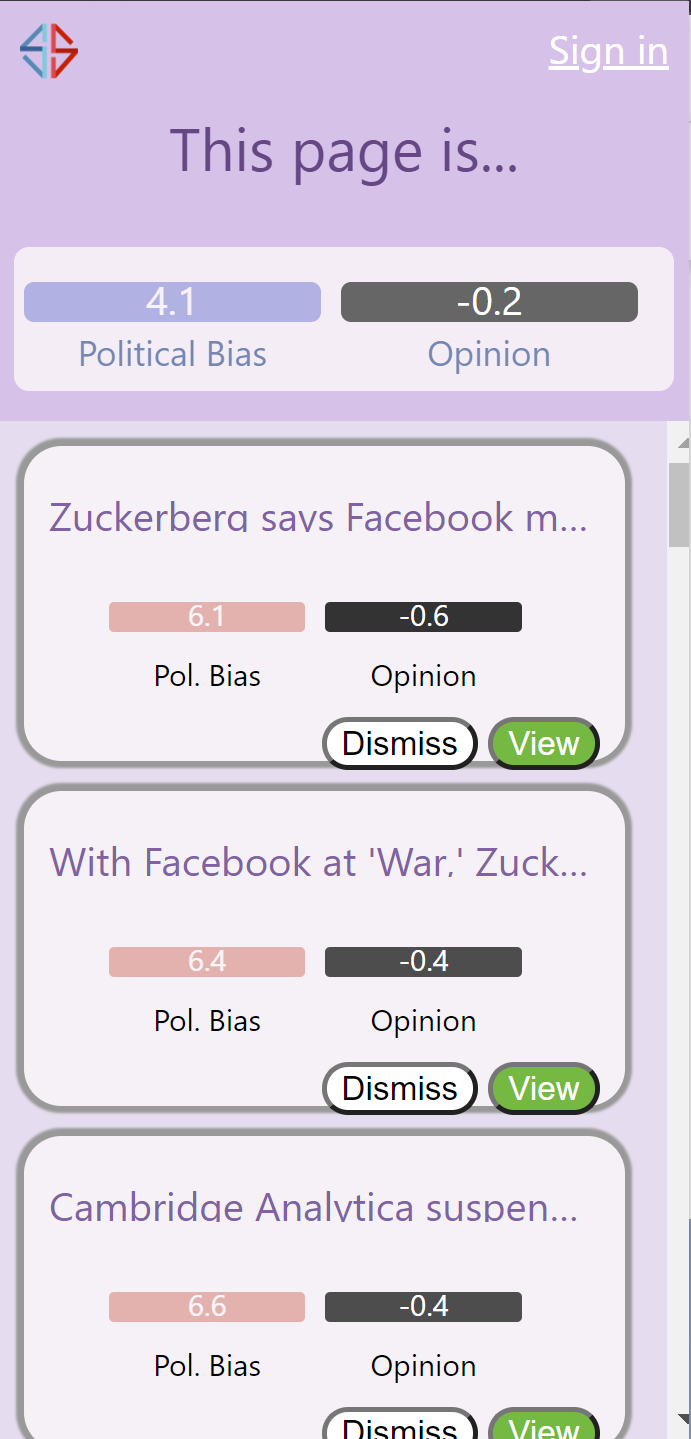
Chrome extension -- using a different article, you can see that the chrome extension reads the web page. NYT leans left.
-
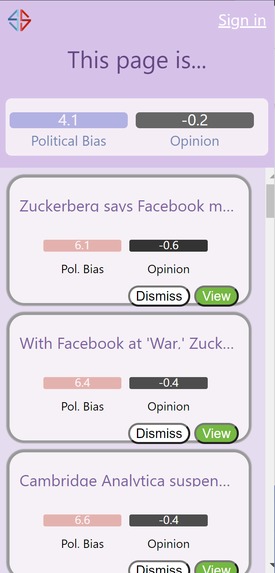
Chrome extension -- close up view. NYT is a left leaning publisher, so the suggested articles are right-leaning.
-

S are symbolic of a window -- representing openness and courage to change. Red and Blue are symbolic of the classic political party colours.

Inspiration
Political campaigns have become increasingly wagered on social media involvement. The Facebook-Cambridge Analytica data scandal is a foremost example of this. In Facebook’s largest data leak ever, where the private data of tens of millions of users was compromised, the psychological profiles of American voters were sold to political campaigns to unconstitutionally meddle with the 2016 Presidential Election.
More recently, Netflix’s 2020 docudrama The Social Dilemma explored how social media is fundamentally designed to nurture addiction to the platform and manipulate politics. It revealed how the algorithms behind our favourite social media networks are designed to nurture addiction and manipulate politics, by feeding users with click-bait-worthy articles, instead of legitimate posts, leading to a furious echo chamber.
Given the already extremely dichotomized political divide in the United States, we were inspired to build something that would address the echo chamber that social media users are thrust into. An echo chamber refers to when beliefs are reinforced by communication and repetition within a closed system, and insulated from rebuttal. Let’s break out of the echo chamber by educating ourselves across the Spectrum.
What it does
Spectrum is designed to broaden a user’s political awareness across the political spectrum. It’s easy to fall into an echo chamber, where we only read articles from a political viewpoint with which we feel most comfortable. It is uncommon for the average reader to actively look for news and reports that will challenge their perception or beliefs. We designed Spectrum with a two-pronged approach: it's both a web application and a chrome extension. Spectrum analyzes news websites automatically and provides the reader with an article, or several, discussing the same subject with a contrasting (political) viewpoint. We used IBM Watson’s natural language processing to understand the key components of the article and the article's viewpoint towards the topic; we then created a programmable search engine with Google Cloud API to obtain articles suggestions from various media sources.
How we built it
The front-end had two components (hahaha? Get it?... We're really tired it's been a long night): The Chrome extension was built with JavaScript, jQuery, HTML and CSS. The web application was built with JavaScript, along with React.js, SASS and the Bulma CSS framework.
Finally, the backend was built with Python, Django, IBM Watson API, Google Cloud API and CockroachDB.
Regarding the categorization for media sites, we stuck with existing methodology used to categorize news publishers into a respective position on the political spectrum. We obtained our classification from Ad Fontes Media, Media Bias Fact Check, and AllSides which evaluated news publishers and media companies on their political leaning and reliability. We settled on these three so that we could evaluate credibility cross rating-platform, and also because we found that they all had a rigid methodology.
Challenges we ran into
Frontend: Much of the challenge came from building the Chrome extension. No-one in the group had ever created a Chrome extension before, so it was a new challenge for everyone involved.
Backend: There were a few major challenges: first, was the integration of all of the various APIs and databases. None of us had worked with the IBM Watson API, the Google Custom Search API, nor CockroachDB prior to the beginning of the hackathon. We had to pore over documentation, ask mentors for help regarding special functionalities, and overall just spend a lot of time figuring out how to put all of the APIs together to form a coherent algorithm for our application. We found out about the google search operators, which allowed us to construct precise and robust queries. We decided to go with Django because it allows us to run python scripts for API calls, interface with CockroachDB, and create our own RESTful API for scalability.
The second challenge was figuring out how to recommend relevant articles that suitably contrasted a given article. The challenge could (as usual) be approached with machine learning models, some training time, and a lot of training data -- we spent a lot of time doing research on how we could assess political bias and emotion/opinion bias through machine learning models (here are some of our top picks if you’re interested! https://arxiv.org/pdf/1803.02710.pdf, https://cs224d.stanford.edu/reports/MisraBasak.pdf). However, that approach was not very feasible given the time and data available to us. In the end, we leveraged IBM Watson API to extract keywords from articles which we strung together to construct the main topic of the article. We also used the sentiment analysis capability to better understand the viewpoint of the article. Finally, we incorporated our NLP based analysis with existing research on news' media to produce the best suggestions.
Another challenge we had was to overcome the Cross-Origin Request Header mechanism of the browser. Since we are not hosting our server at the same origin as our web app, the browser restricted us from making API calls. We had to look for a Django solution and alter how we send our response headers to get around the restrictions. It's quite a neat computer security feature.
Finally, one of our biggest backend challenges was working with Django and creating our APIs. None of us had ever used it, and it involved a steeper learning curve than we expected.
Accomplishments that we’re proud of
We’re really proud of the fact that we were able to actually get two separate projects -- both the chrome extension and the web application -- working. I would kill for this type of productivity and efficiency during the school year.... We’re really happy with how everything turned out, especially since most of us working on the front end of things weren’t familiar with JavaScript, CSS, and HTML. Our backend developers had also never used Django, or Python on the backend before, ever. It's also great that we were able to set up our own APIs for user authentication and article recommendation. This opens up our project to future expansion very easily. When CockroachDB went down, we also learned to set up local PostgreSQL databases to push through! We learned so much!!
We’re also really proud of the fact that it works, and that it’s something everyone could benefit from, especially social science students. One of our team members, Alice, is a political science dual degree student, and she’s spent hours poring over media sides ranging from Jacobin to Breitbart to better understand how news is presented across the political spectrum. Alice: This probably would have been a lifesaver if I had it when I was writing my 4,000+ word term papers…
What we learned
We learned how lovely it was to get a decent amount of sleep during a hackathon, and are very grateful for the fact that Hack the North was 36 hours!
In all seriousness, in terms of the scope of our project, we learned about how to build a Chrome extension. On the front-end, we learned a lot more about JavaScript, HTML, and CSS. On the back-end, we learned how to use Django. Of course, we also learned how to use our APIs: both the IBM Watson API and the Google Programmable Search Engine API.
Outside of technical development, we also learned a lot more about political biases across the spectrum, and how we, as media consumers, are exposed to a lot of bias subconsciously. At a hackathon, it might not be our foremost goal to learn about social issues, but it’s still important to understand that, and how, we can be influenced by our media consumption.
What's next for Spectrum
We would love to deploy a more polished version of our extension and web application. Part of the reason we decided on having a web app component was because we wanted to deploy our project during the hackathon. Unfortunately, because of the database being down for some time, we weren’t able to get this done. Definitely something we’d like to do in the future! Some things that we would add and change are:
- Of course, deployed web application and chrome extension so that people can check their bias!
- Refined design of the application: we would make sure that our UI is updated and pretty!
- Integration with Single Sign-On (SSO) or through an existing account: like logging in with a Facebook or Google account, which would be perfect for the Chrome extension.
- Trained machine learning models for dynamicity: We spent a while reading up on the research behind training machine learning models to detect political bias and emotion/opinion bias, and in the future, we would love to make Spectrum more comprehensive with trained models.
- Analytics and statistics: We intended to create a statistical overview page so that users would be able to see their statistics on the political backgrounds of articles that they’ve read, to see where they land on the Spectrum. We’d love to incorporate this in the future.
- Extension that works on social media websites/newsfeeds: similarly to social media newsfeed blocker extensions, we’d love to be able to overlay our extension over social media news feeds, so political fact checking can be more explicitly seen.
Built With
- adobe-illustrator
- cockroachdb
- css
- django
- google-cloud-programmable-search-engine
- html
- ibm-watson
- javascript
- python
- react










Log in or sign up for Devpost to join the conversation.