-
-

screen to add a new device
-
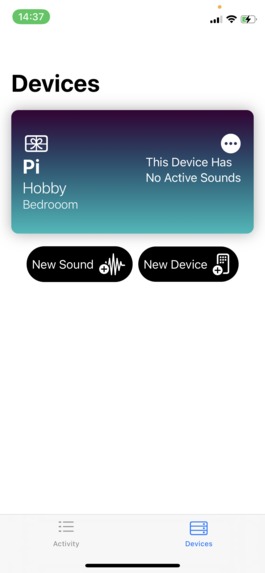
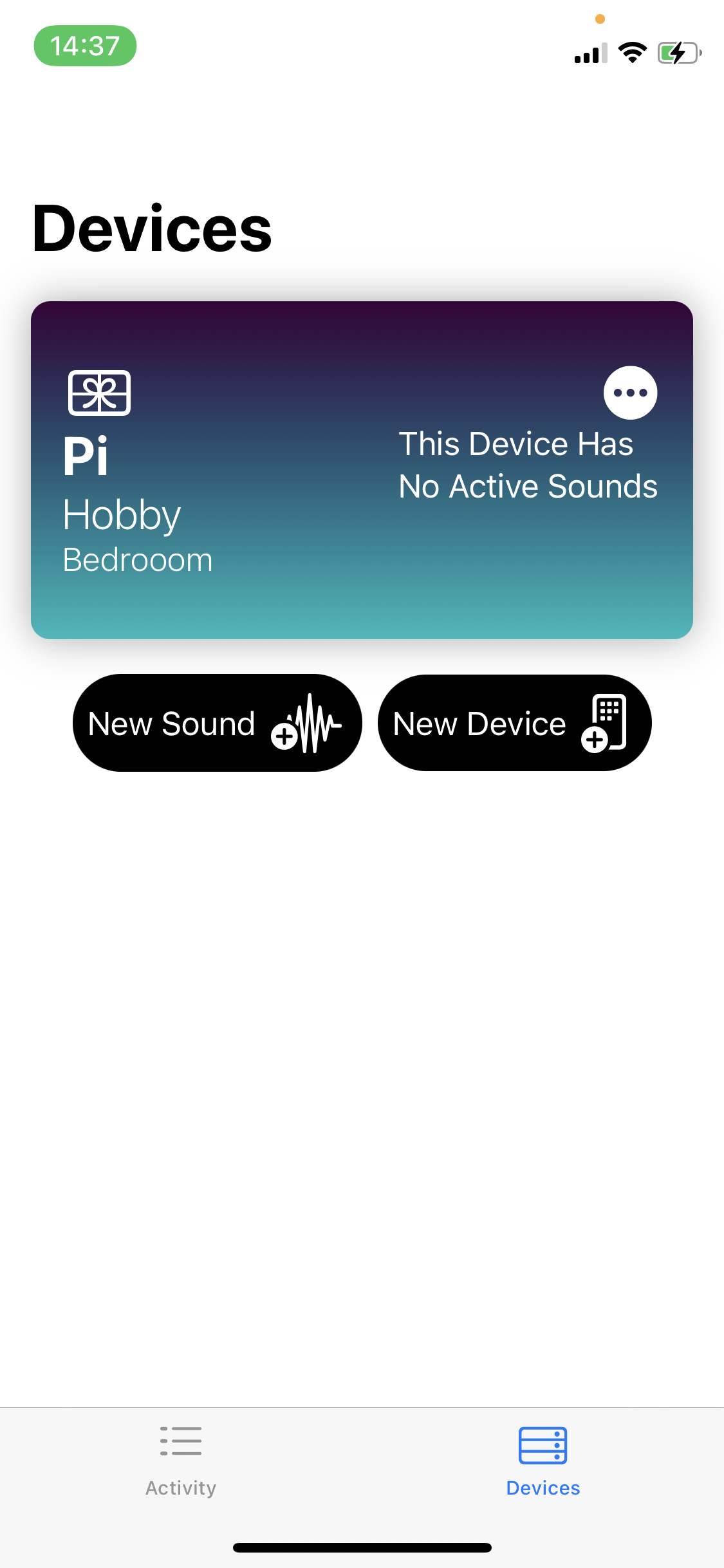
the devices page to see the devices you have connected
-
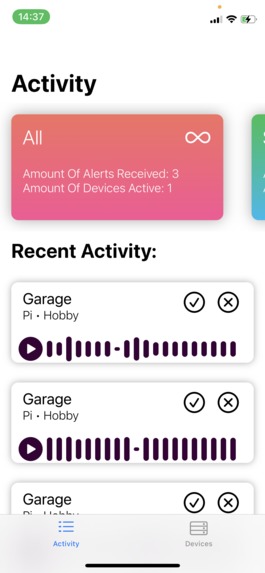
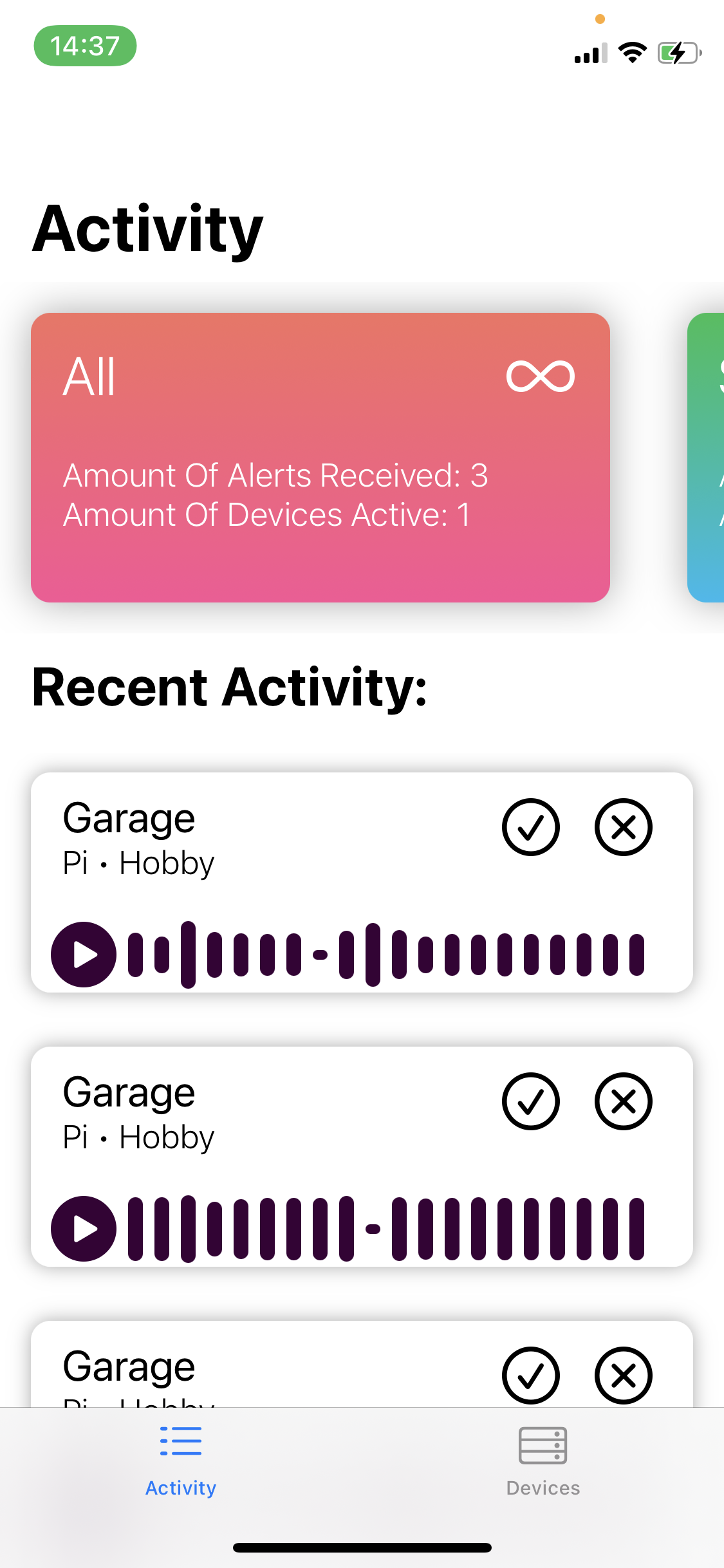
screen to look at recent activity and some more information at the top
Inspiration
When our families considered making our homes into smart homes we looked at all our options and were quickly turned away by the sheer number of different, specialized, devices that would be needed. The cost alone was discouraging, but the compatibility would have been another mess altogether.
What if there was one device that could sense almost anything in our environment, from a garage door opening, to glass breaking? What about a baby’s cry as they wake, or someone knocking on the door? Right now, you would need a separate sensor for each task, but what if there was just one that just worked? This is why we built SoundFish, one sensor to rule them all.
What it does
Our app can be used to train a “smart microphone” to recognize any noise, it then sends a notification whenever that sound is heard by the mic. A person can view all recent activity on their device. We recommend at least eight samples to train a new sound, but more always helps.
How we built it
The vast majority of our frontend is made with SwiftUI, Apple’s latest UI framework. We did have to use UIKit for certain portions since some features aren’t supported in SwiftUI as of iOS 14. To manage data on the frontend and call the backend we used Combine and URLSession. Most pages on the app use the REST API while the process of recording a new sound is done in real time through websockets.
The server uses Python and Fast-api (Flask-like web framework) for all the network endpoints. The neural network is a convolutional network that categorizes the sounds it hears. It is trained using transfer-learning where the head of the network can be changed, but the base of the network is frozen. This greatly reduces the number of samples needed to train a new sound.
Challenges we ran into
We ran into many challenges while working on this project. We’ve only been to two hackathons before but we wanted to do something much more ambitious this time. We really threw ourselves into the deep end.
- None of us are graphics designers and the most we’ve ever really done in the visual arts is the required high school class. Making the UI look half-way decent took a lot more time than we expected.
- Making the UI update properly when stuff changed on the backend caused a lot of debate and technical issues over how we would do it. One approach we considered was a websocket connection that the server would use to tell the client to update. In the end, we decided to use REST API calls and leave the websocket part only for the recording.
- Defining how the app would be structured was very challenging since we’ve never worked on a project this large. We wouldn’t have enough time to waste where one person would wait on the other to finish some code. By making sure we weren’t editing the same files, we didn’t have any merge conflicts and GitHub really helped out.
- Although we used a pre-trained convolutional audio model, we didn’t have much data. We also needed to make the user experiences the best we could manage.
- We love using SwiftUI, but it has its...issues. At two points in time, our code broke the Swift compiler and we had to walk back some changes to our code and try another way (we never figured out what happened).
What we learned
This Hackathon taught some very important lessons, from things specific to our project, to things that we need to take away and use in other projects.
By far, the most important thing we learned was the value of planning. We were eager to start the project after we came up with the idea, but we refrained from doing so by spending some time making a UI flow for the app (it wasn’t fancy but it was something). With such an ambitious project, we discovered that taking the risk of starting early and realizing we had architectured the app incorrectly nets greater work requirements than otherwise would be necessary.
Even still, our biggest problem was networking, although we planned out the API. When we planned it out, we thought we wouldn’t have to worry about the networking until the end. Vivek would handle the backend and follow the specification. Preston would handle communication with the Raspberry Pi. Saaketh and I would handle the frontend and follow the specification. It became so much harder when we had to change our API specification midway due to issues happening on the backend. Websockets were not cooperating, the database properties weren’t correct and had to be changed. Next time, we’re not going to test all the networking at the very end. We’re going to make sure we have certain “checkpoints” and check our networking at each step so we can catch some of these issues earlier on, before they become larger and more difficult to resolve.
Outside of general software engineering practices we learned, we also learned a lot of technical skills in the areas we worked on. Saaketh learned more about UI design and structuring the app. I (Arpan) learned how to create and use WebSockets in iOS using URLSessionWebSocketTask, AVFoundation to play audio, and GeometryReader(a special SwiftUI view) to make more complex UI’s (that wave-form viewer mostly). Vivek learned how to use transfer learning to reduce the amount of training data that would be needed, websockets in Python to communicate between the app and server and smart microphone (Raspberry Pi). Preston also learned how to use websockets to communicate with the Raspberry Pi.
What's next for SoundFish
Next we would like to put our API to good use and expand the scope of SoundFish by allowing integration with HomeKit, Alexa routines, GoogleHome, custom dashboards and more. Right now SoundFish is able to semi-accurately inform a user of when an action occurs, but we’d like to give users the power to automate the response to the notification.
We would also like to make a store of pre-trained noises that a user can add to their device. We made a UI mockup, but we were unable to get it working in the backend due to time constraints. This would serve to make it even easier to get SoundFish up and running. It would be great for detecting sounds you wouldn’t like to demo. I don’t want to break eight windows to train the microphone to detect my windows shattering.
TLDR
It's very annoying and difficult to set up special sensors for every task or purpose, so we used few-shot with transfer-learning to create a way for users to train a model to identify any custom noises with around 8 samples. In order to make this system easy to use, we made an iOS app using SwiftUI. We also developed a scalable API that opens the door for future integration with more devices, and the ability to program responses to the notifications of events. With SoundFish, you can easily train a device to identify any noise and get notified when that sound is detected. SoundFish is one sensor to rule them all, reducing cost and complexity for a variety of use cases.
Built With
- avfoundation
- fastapi
- librosa
- python
- restapi
- swift
- swiftui
- tensorflow
- uikit
- websockets

Log in or sign up for Devpost to join the conversation.