SignalSmith AI
Cut the noise. Keep the signal. Prove it first.
Inspiration
Every Splunk team hits the same wall:
Reduce telemetry cost — without killing visibility, breaking detections, or losing operational trust.
Health checks, verbose debug events, repetitive success responses, duplicate metrics, low-value infra logs — these quietly eat a massive chunk of your ingest budget. But one overly aggressive filter can suppress the exact event that would have caught a payment outage, a credential-stuffing campaign, a Kubernetes failure, or an SLO breach.
Right now, teams make these calls using spreadsheets, intuition, and gut feel. The result: either they eat the cost, or they avoid optimization entirely because the risk feels too high.
We built SignalSmith AI to replace guesswork with evidence.
SignalSmith is an agentic telemetry optimization platform that identifies low-value data, proposes safe reduction policies, tests them against real Splunk detections in an isolated shadow environment, automatically revises unsafe proposals, and only produces deployable OpenTelemetry Collector config after a human explicitly approves.
The Splunk Agentic Ops Hackathon pushed us to build something more than another observability dashboard. We built a system connected to the official Splunk MCP Server that can reason over operational context, execute validation workflows, show its evidence, and keep humans in control of every production decision.
What It Does
SignalSmith answers one high-stakes question:
What telemetry can we safely reduce without breaking the searches, alerts, and detections we depend on?
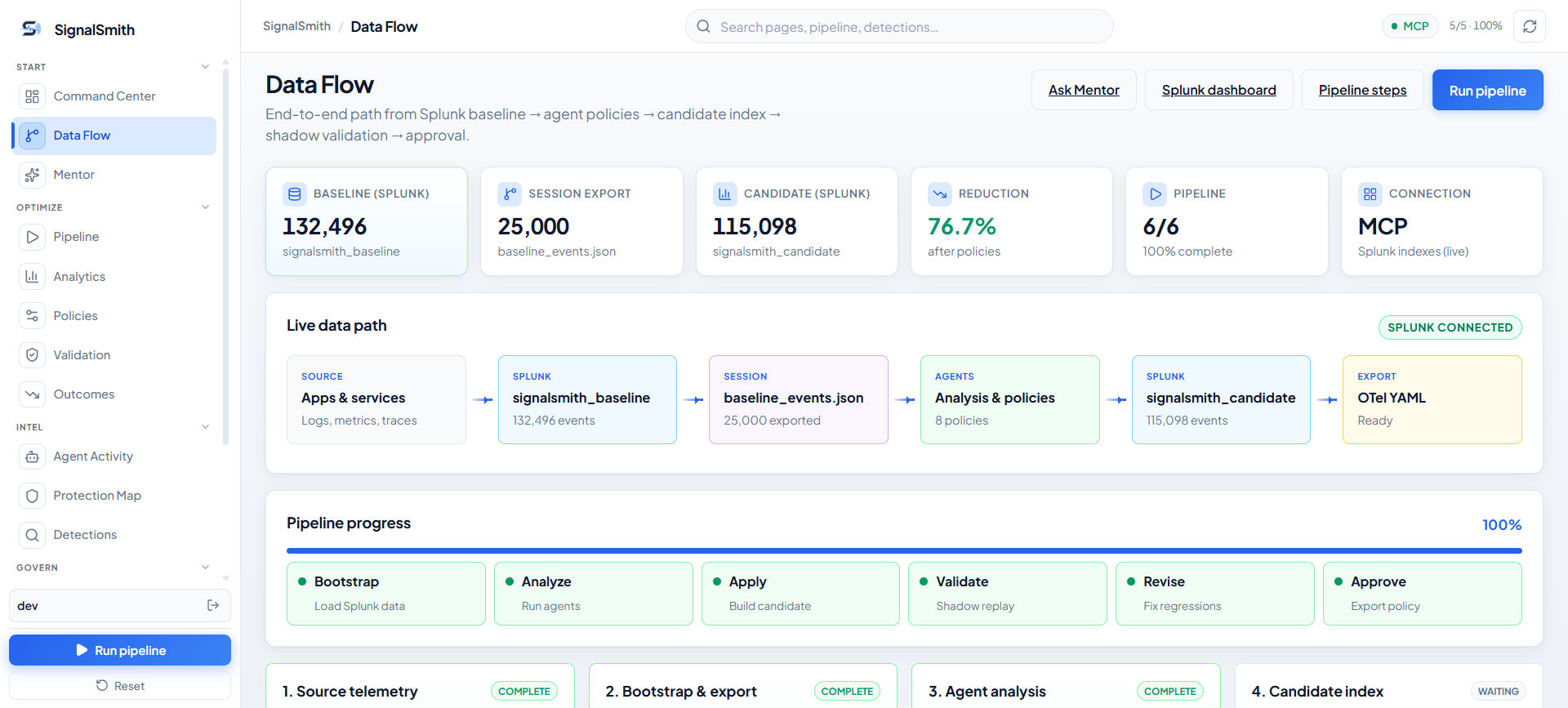
The full workflow:
- Discover — Maps indexes, sourcetypes, fields, saved searches, and detection dependencies.
- Profile — Identifies repetitive, redundant, or low-value telemetry patterns.
- Protect — Builds an explicit map of events and fields that must stay untouched.
- Propose — Generates explainable filtering and sampling policies with expected savings.
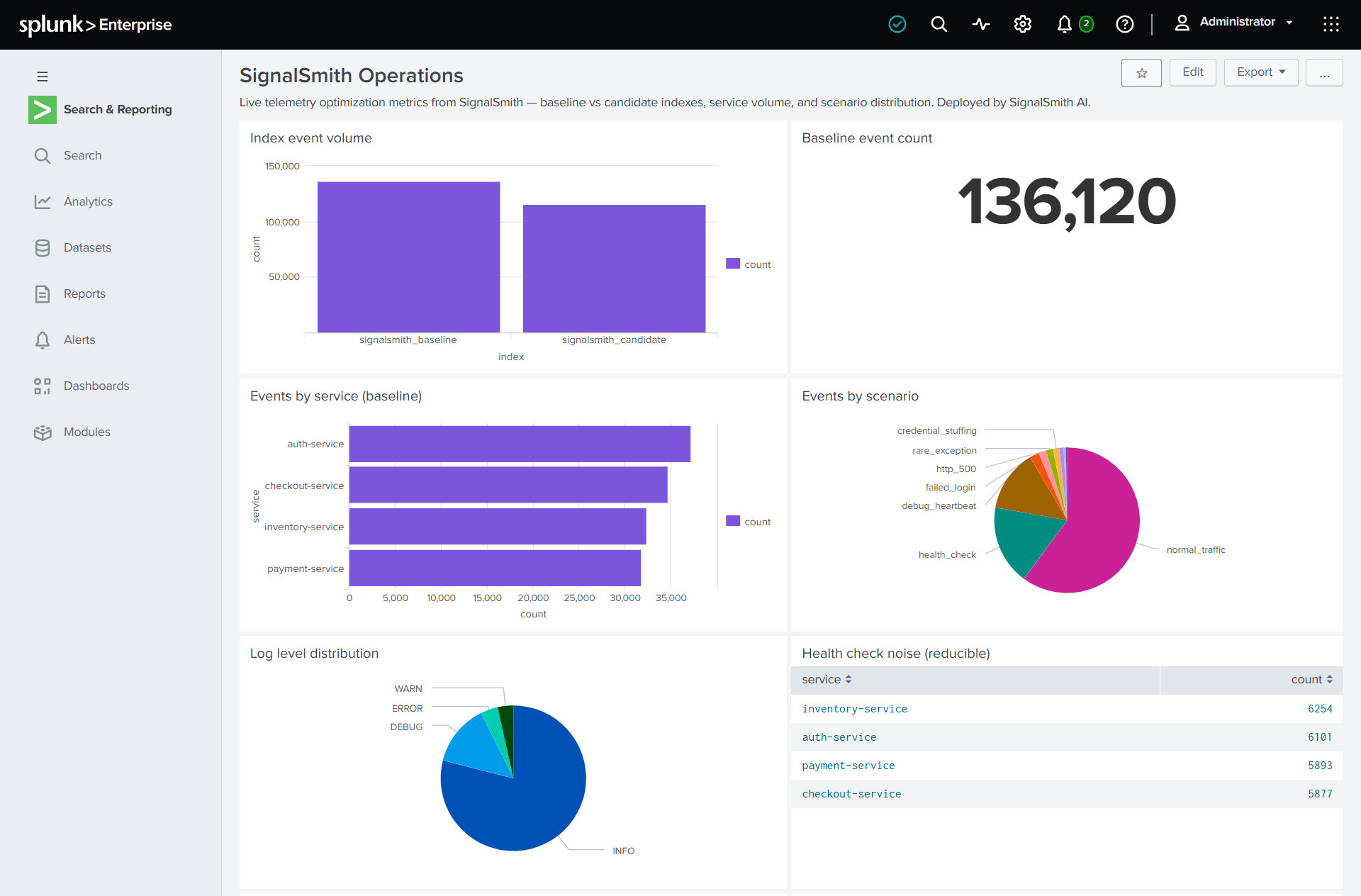
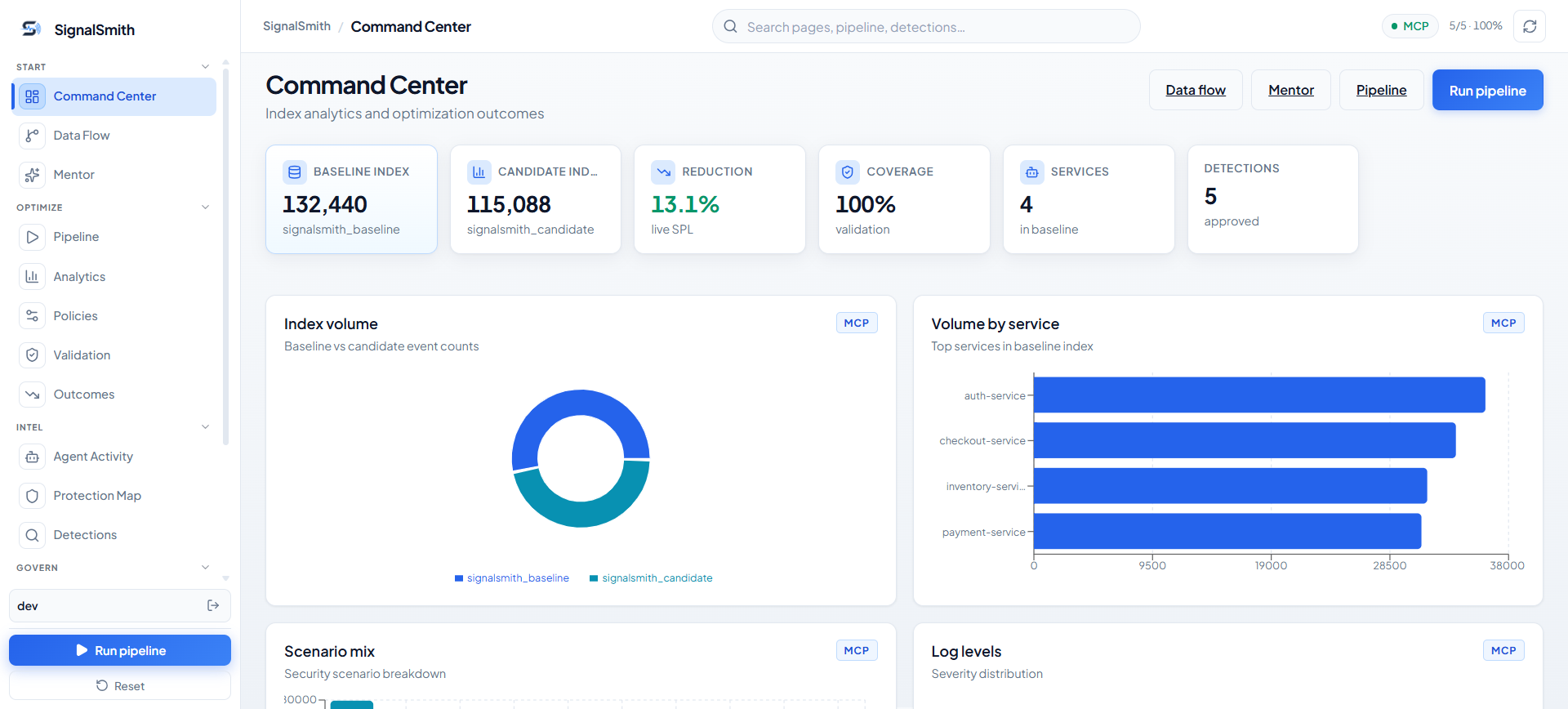
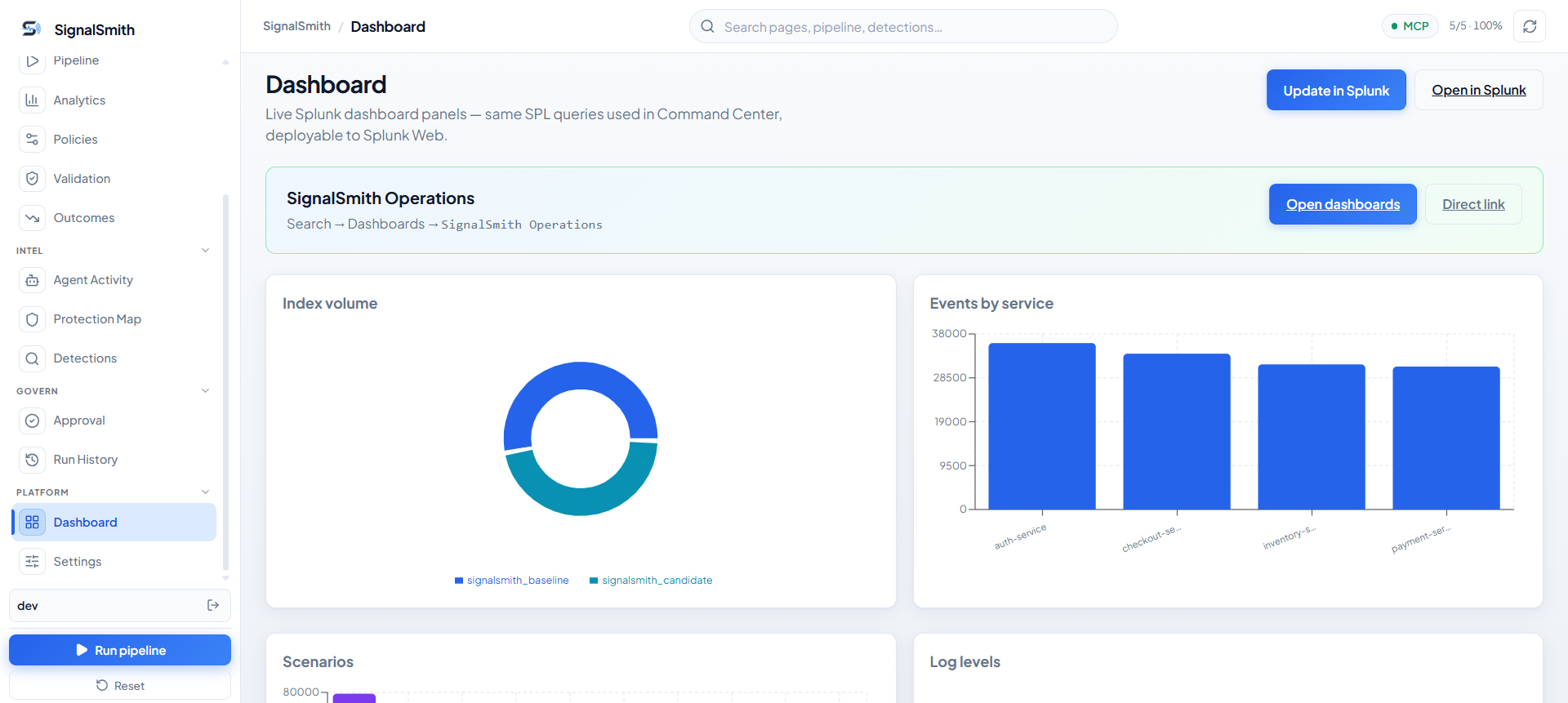
- Shadow — Routes filtered events into a candidate index; baseline stays clean.
- Validate — Replays protected SPL searches against both datasets and compares results.
- Measure — Calculates ingest reduction and detection coverage per search.
- Revise — Automatically patches policies when validation reveals regression.
- Review — Presents the full evidence package for human approval.
- Export — Outputs deployable OTel Collector config + rollback config after approval.
SignalSmith never modifies the production index in place. Everything is tested through a baseline-vs-candidate shadow workflow before you see a single recommendation.
What We Learned
AI for observability only earns trust when it can prove its recommendations.
"Looks reasonable" is not enough. Operators need evidence they can inspect, reproduce, and challenge.
That means showing:
- Estimated and measured byte reduction
- Which event patterns are being removed or sampled
- Which fields and detections are protected
- Baseline and candidate hit counts for every saved search
- The exact reason a validation passed or failed
- Policy changes made during automatic revision
- A complete audit trail before export
Key insight: Cost reduction and detection safety can't be collapsed into a single global score. A policy can preserve total event volume while silently damaging one critical security rule. SignalSmith evaluates each protected search individually and blocks approval if any required search drops below its safety threshold.
For each protected search, SignalSmith checks:
$$\text{Safety Ratio} = \frac{\text{Candidate Search Hits}}{\text{Baseline Search Hits}} \geq \tau$$
A proposal is only eligible for approval when this ratio meets the configured threshold for every required search, and all mandatory fields remain available.
Second key insight: Agentic assistance has to be grounded in the operator's actual session. SignalSmith Mentor isn't generic SPL advice — it understands your current indexes, telemetry profile, live proposals, validation results, failed searches, and approval state. It explains why a rule failed, what revision changed, and which evidence still needs review.
How We Built It
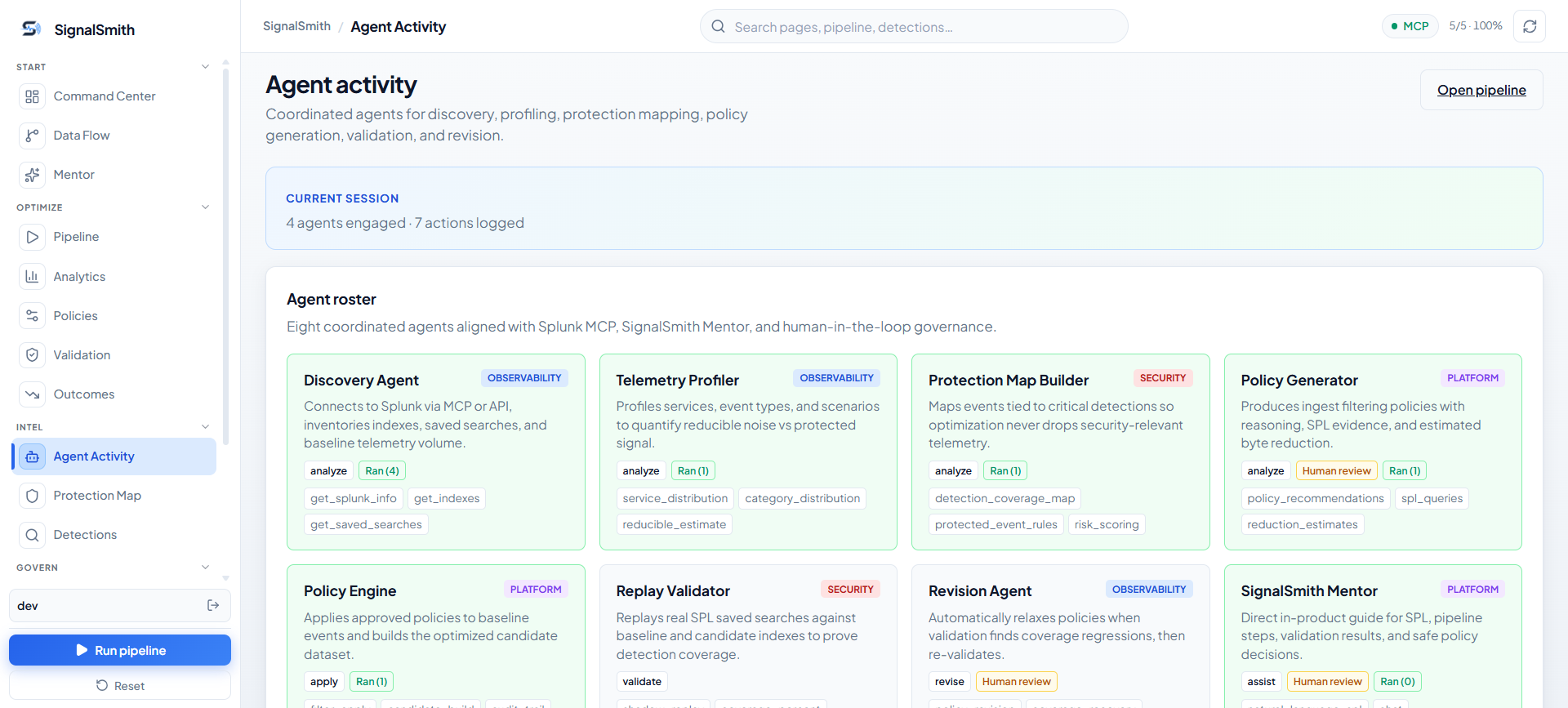
SignalSmith runs as an evidence-driven, 8-agent pipeline.
Agent 1 — Discovery
Maps the active Splunk environment: indexes, sourcetypes, field distributions, saved searches, alerts, configured detections. Its output is the operating context for every downstream agent.
Agent 2 — Telemetry Profiler
Analyzes volume and structure to surface optimization opportunities:
- Repetitive health checks and high-frequency 200 responses
- Verbose debug events and near-duplicate records
- High-cardinality fields and redundant metadata
- Events with low operational or detection value
The profiler separates likely noise from potentially valuable signals — it doesn't treat every high-volume source as disposable.
Agent 3 — Protection Map Builder
Builds an explicit dependency map: which telemetry does each saved search, alert, and detection actually need? The map records protected sourcetypes, required fields, critical event signatures, and user-defined rules. This gives the policy generator hard limits it cannot violate.
Agent 4 — Policy Generator
Produces candidate policies using:
- Deterministic event dropping
- Conditional filtering
- Probabilistic sampling
- Field removal and duplicate suppression
- Source-specific routing
- Exception rules for protected signals
Every proposal explains what will change, why it's safe, expected savings, and which protections were applied.
Agent 5 — Policy Engine
Compiles proposals into executable rules and applies them only to the candidate data path. Baseline telemetry stays untouched. The candidate index makes policy behavior testable without touching production visibility.
Agent 6 — Replay Validator
Uses the Splunk MCP integration to run protected SPL searches against both datasets. For each saved search, it compares result counts, matched event patterns, required-field availability, time-window behavior, and configured thresholds. Results surface as evidence — not a pass/fail black box.
Agent 7 — Revision Agent
When a proposal causes unacceptable regression, the system doesn't scrap everything. The Revision Agent finds which specific filter or field transformation caused the loss, introduces the smallest required exception, and reruns validation.
The loop: Propose → Shadow → Validate → Explain → Revise → Revalidate
It runs until the policy satisfies all safety requirements or is flagged as unsuitable for approval.
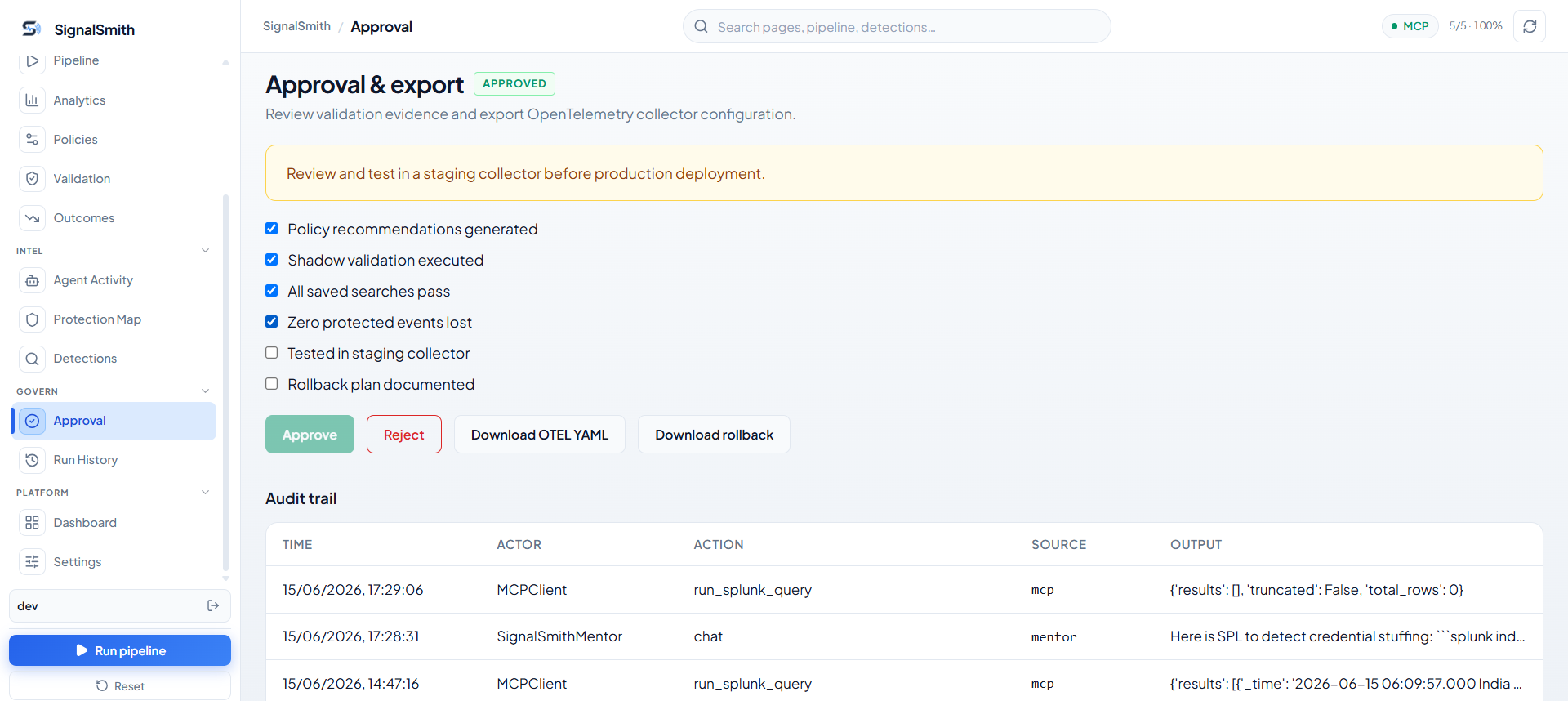
Agent 8 — Human Approval & Export
SignalSmith deliberately does not auto-deploy. The final approval view shows:
- Projected ingest reduction
- Validation coverage
- Baseline vs. candidate comparisons
- Unresolved warnings
- Policy revision history
- Final compiled rules
After human approval, SignalSmith generates:
- Deployable OpenTelemetry Collector config
- Rollback config
- Policy metadata and validation evidence
- Full audit record of the decision
Splunk Integration
SignalSmith uses the official Splunk MCP Server as its primary integration layer. Through MCP, agents discover Splunk context, execute SPL searches, inspect validation results, and reason over real operational evidence through a consistent interface.
The platform also supports controlled fallback modes when MCP or a live Splunk instance is temporarily unavailable — clearly labelled by evidence provenance (live MCP, direct Splunk, or offline replay).
SignalSmith never presents simulated results as live validation.
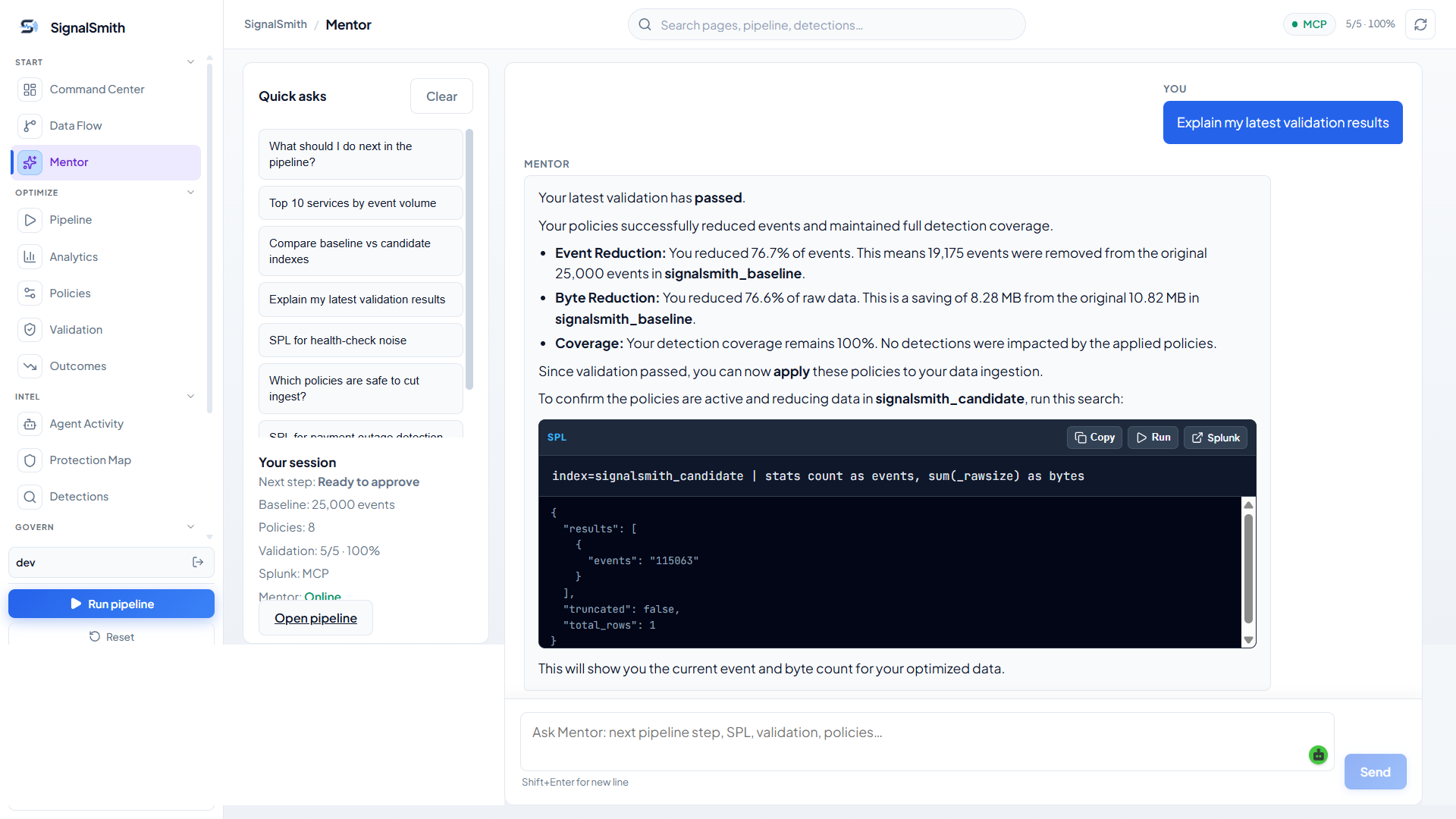
SignalSmith Mentor
Mentor is the operator-facing AI assistant embedded throughout the workflow. It's grounded in the current session — not a generic chatbot bolted on the side.
Ask it things like:
- Why was this sourcetype classified as noisy?
- Which saved searches depend on this field?
- Why did this proposal fail validation?
- What changed during automatic revision?
- Which policy gives the best reduction with the lowest risk?
- What evidence is still missing before approval?
- How would this policy affect my security detections or SLO alerts?
Mentor is designed to help operators understand the system's reasoning — not replace their judgment.
Challenges We Faced
Validating real SPL behavior — Saved searches can contain complex SPL, long time ranges, joins, lookups, macros, and environment-specific assumptions. Running reliable baseline-vs-candidate comparisons meant handling query latency, partial results, empty windows, and execution failures without fabricating certainty.
Keeping production data safe — SignalSmith must never experiment on the live index. We had to make baseline and candidate paths distinct at both the architecture level and in the user experience — no ambiguity about which data you're looking at.
Revising policies deterministically — When validation fails, generating another unconstrained AI recommendation creates an unreliable loop. Revisions respond to specific failed searches and introduce narrowly scoped exceptions only.
Distinguishing missing evidence from failure — A search returning zero results could mean: no matching events existed, the time range was off, connectivity failed, or the policy removed required telemetry. SignalSmith keeps these states separate instead of collapsing them into a misleading score.
Supporting multiple connectivity modes — MCP execution, direct Splunk access, and offline replay have different capabilities and failure behavior. Unifying them behind one validation workflow while preserving evidence provenance was genuinely hard.
Baking governance into the core — Approval, auditability, rollback, and evidence provenance can't be afterthoughts. They're part of the product's core state machine. No policy can bypass validation and human review.
What Makes SignalSmith Different
Most telemetry optimization tools focus on estimating savings or generating filters.
SignalSmith focuses on proving the filters are safe.
| Typical tool | SignalSmith | |
|---|---|---|
| Optimization basis | Volume heuristics | Detection-aware analysis |
| Validation | Estimate only | Live SPL replay on shadow data |
| Safety signal | Global confidence score | Per-search threshold, individually evaluated |
| Failed policy | Discard and retry | Targeted revision with specific exception |
| Production risk | Filter applied directly | Candidate path, baseline untouched |
| Deployment | Recommendations | Deployable OTel config + rollback |
| Human control | Optional review | Required approval, no auto-deploy |
| AI assistant | Generic | Session-grounded, evidence-aware |
| Audit | None | Full trail on every approved policy |
Why It Matters
Telemetry growth is both an engineering problem and a financial problem.
Teams need to cut observability costs — but indiscriminate filtering creates hidden operational and security risk. The safest event to remove can't be determined by volume alone. It has to be evaluated against the searches, alerts, and decisions that depend on it.
SignalSmith is a practical bridge between FinOps, observability, security, and platform engineering.
It applies to: application and API logs, security telemetry, Kubernetes and infra events, network ops data, cloud audit logs, metrics and traces, custom detections, and organization-specific SPL workflows.
It changes telemetry optimization from a risky config exercise into a measurable engineering process.
It doesn't ask operators to trust an AI-generated filter. It asks them to inspect the proposal, review the savings, compare the searches, examine the revisions — and approve only when the evidence is strong enough.
Cut the noise. Keep the signal. Prove it first.



Log in or sign up for Devpost to join the conversation.