Overview
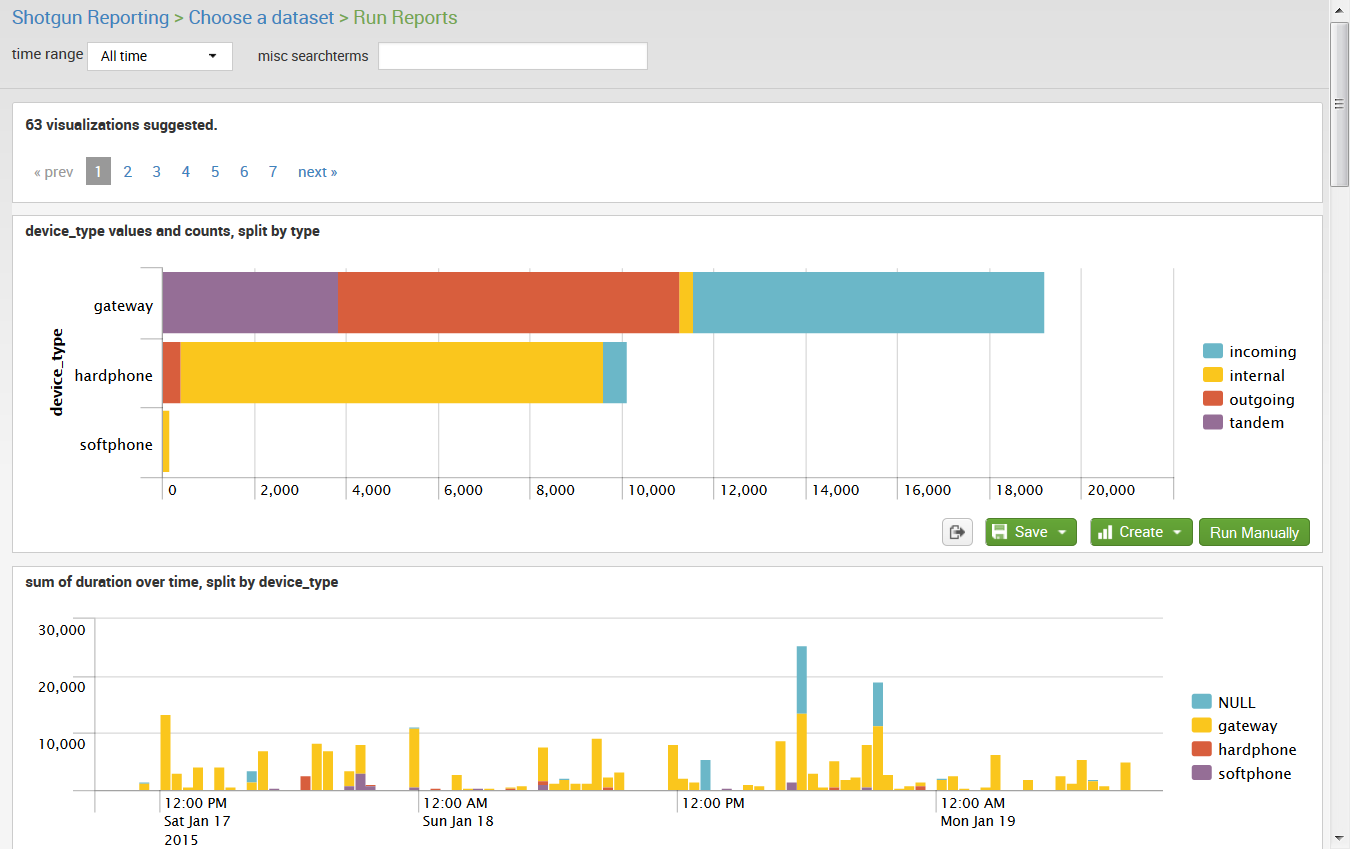
The app asks you to pick an index and a sourcetype. It then looks at the events and the fields. It analyzes them a bit and suggests a number of charts and tables, sorting them so that the ones it thinks you'll find interesting are at the top. It then goes ahead and runs and renders these charts and tables for you and lets you page through them. If that last sentence sounded a little funny to you, it's because this experience is somewhat unique in the Splunk world. Instead of paging through events or tabular results (normal), you are literally paging through a set of "visualizations" (o_O). Furthermore these are not abstract ones - these are actual live graphs and charts rendered with your actual real time production data. Surprisingly interesting ones.
Then, as you're looking through the charts and tables it suggested, you can click "add to dashboard" on any of them, or you can click "run search manually" if you want to dissect what it has done, or you can click anything in any of them. If you choose this last option, ie you click anything in any of them, then you get some options for drilldown, one of which is called "shotgun drilldown!", which we feel is worth both a try, and its terminal exclamation mark.
How to best use it
Try it on as many datasets as you can. Sometimes the reports will be a little ho-hum, but there's usually some gems hidden in plain sight on the first page or two. Make sure to try clicking things in the graphs and try the "shotgun drilldown!" option there.
Assumptions
It is designed to work with literally any data you have indexed in Splunk. However it does make some assumptions.
1) Someone or some app, has already done the "field extraction" work, meaning that for the sourcetypes you ask it to analyze, the relevant Splunk configuration is already present to extract those field names and values. Note that if no person or app has done this for you, you can just do it yourself! Check out the Interactive Field Extractor app in Splunk.
2) You are obeying Splunk's minimum hardware recommendations. aka you have a dual quadcore machine with a good disk subsystem and lots of RAM. aka 8+ CPU's and very fast disk. The problem if you run this app on anything less, is that when the app tries to dispatch ten reports for a given page of recommendations, with only one or two CPU's you can only run a few searches at a time. So all our searches will slam into a queue and take a very long time.
3) You have data. =/ If you don't, you can of course ask the app to analyze the _audit and _internal data that lives inside Splunk, and the app will of course analyze this data quite happily, but that's sad. Just go find some human or some machine that does have data.
4) You have downloaded and installed the latest Sideview Utils from the Sideview website ( http://sideviewapps.com/apps/sideview-utils/ )
Context
This app is one of a number of things we are working on, all united by the idea of "an app that builds itself". One other app in development builds out dynamic list views and detail views for the "nouns" identified in the app. A stretch goal for 1.0 was to combine that app's features with this one but this will instead be coming in a future release. Another project that really exists only on paper would take over the box for a few hours and run large numbers of searches to discover deeper relationships between fields and values, including recognizing alerting thresholds and attempting a categorization of distinct behaviors in different time periods. There is quite simply a huge amount of work that could be done in these directions.
Biggest Challenges
Coming up with a reasonably covering set of "reporting templates", and then devising heuristics to narrow down the set of visualizations from the tens-of-thousands that are almost all useless, to the 50 or so whose value ranges from fair to excellent.
There's a catch-22 around "app context" in apps like this one. For most sourcetypes you have to actually run your searches in that app context to get the benefit of the extractions/lookups/calculated fields etc. But how do you do that without pulling the rug out from under your own app's feet?
A lot of work was done to do heuristics based on continuity in frequency distributions, to differentiate which large-distinct-count, seemingly numeric fields were actually numeric and which were categorical. This got a little bogged down and so the direction was abandoned, which is why now the user has to double check. You'll notice that nonetheless for most fields the initial guess the app makes is actually right.
An unknown amount of thought was given to how to apply ideas from algebraic topology, including how to determine a metric space and calculate the Vietoris-Rips complex of a point cloud whose dimensions consisted of function(field) for all sensible (and some not) functions and for all numeric and categorical fields in the indexed data. However this caused a lot of accidental time travel and those worldlines proved unrecoverable.
Note to Judges
You do need to use the latest Sideview Utils, which is available for free from the Sideview website. Do not use the Sideview Utils that is on apps.splunk.com, as this is ancient. You need version 3.3.2 which is the latest.
If the free licensing on the Sideview site is somehow confusing, as a last resort I am happy to email you a tar.gz of Sideview Utils 3.3.2
NOTE: This app is primarily submitted to the "Innovation" category. However since this app can be used effectively against any data indexed in Splunk, I don't see any reason to not also submit it to the Microsoft SCCM category and the rules do not seem to preclude this.
Built With
- sideview-utils
- splunk

Log in or sign up for Devpost to join the conversation.