-

LITAF logo
-

Front page of web application
-
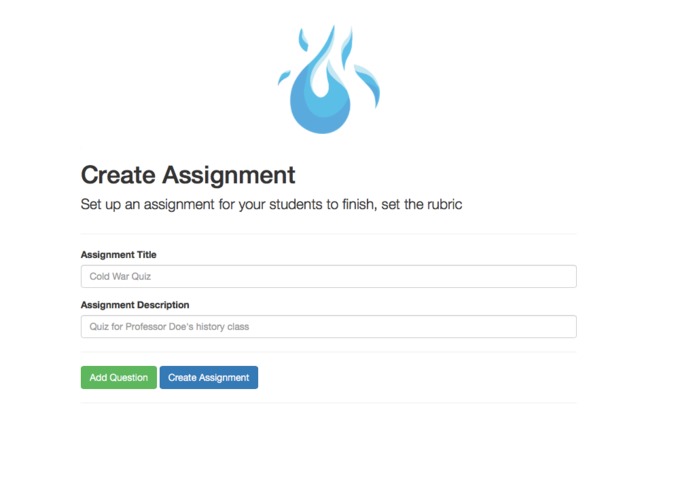
Interface for form creation
-
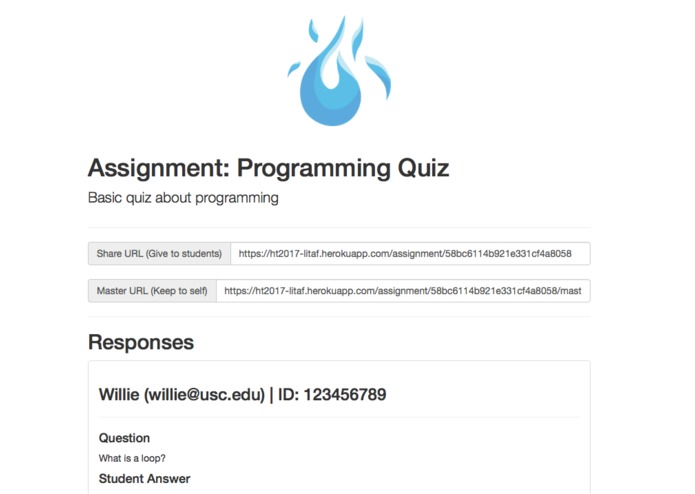
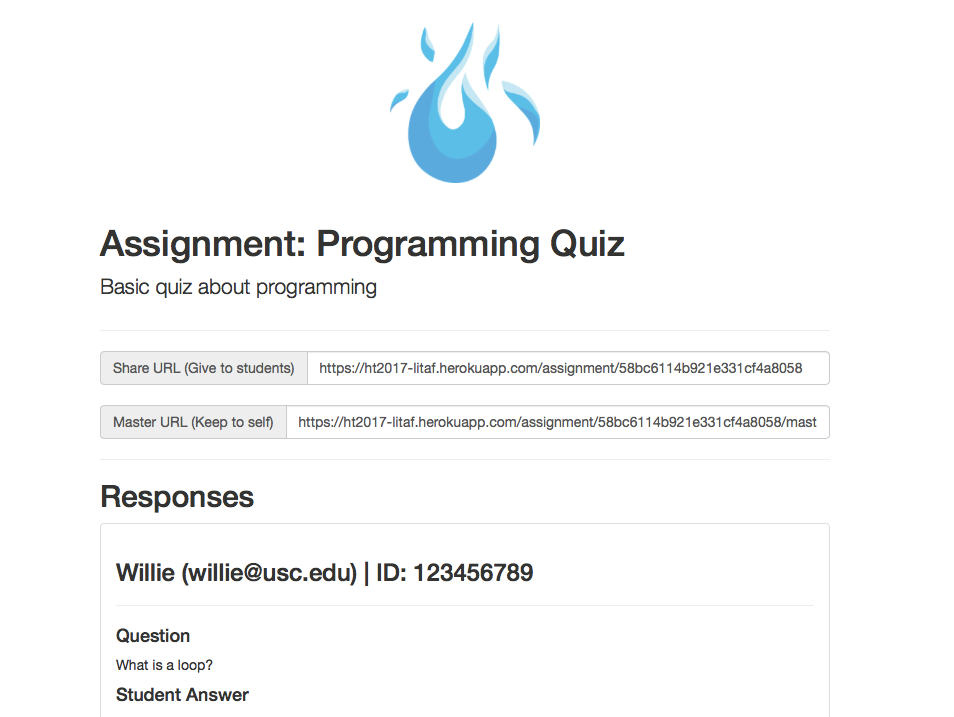
Sample quiz created by master user
-
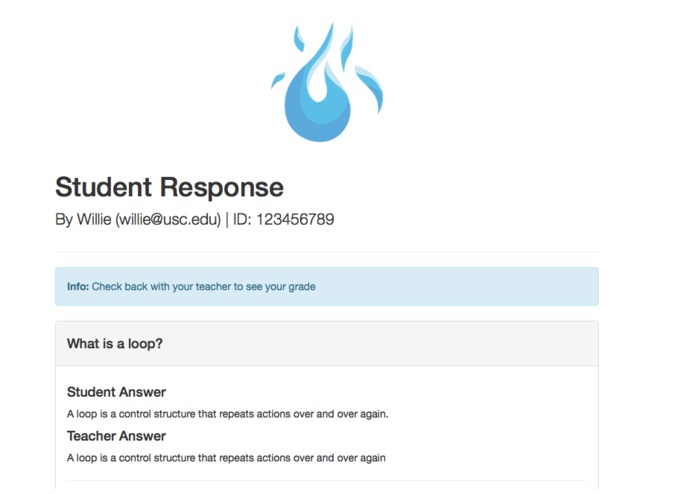
Sample data analytics page of student responses that master user can view


Inspiration
Professors and students alike face the challenge of a slow, tedious grading system that leaves graders spending hours poring over similar answers to an open question and students with no feedback until much later after the deadline. Thus, we decided to build an application that would assign students an automatic grade. By implementing this, professors can save time correcting similar answers to the same question and students can get immediate feedback on how to improve their responses in real time.
What it does
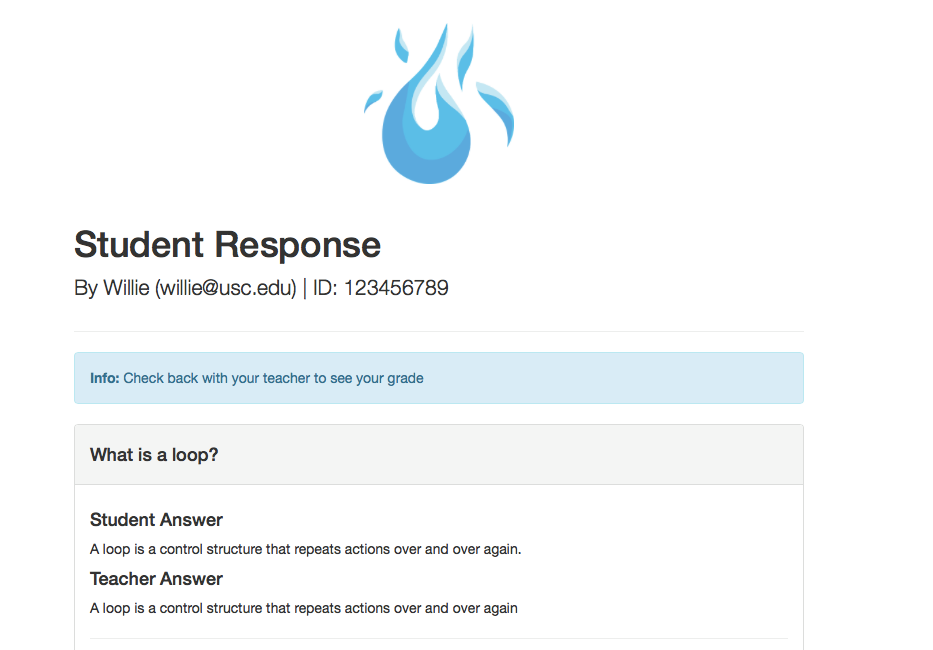
LITAF (Linguistic Informative Telecommunicational Assessment Feature) allows a master user to create a form and to share it via a custom URL. Students who have this URL are then able to input their own answers and, upon submission, receive an automatic response. The creator of the form, on the other hand, will be able to access student responses and view the results returned by our algorithm. The professor can synthesize this information to assign a final grade.
How we built it
We used the Microsoft cognitive services Text Analytics API and Academic Similarity API to develop our keyword analysis algorithm and academic similarity algorithm to assign grades to a student’s submission as well as our sentiment analysis function which analyzes the reactions students have towards each question. The database of student answers was built using MongoDB as well as the Node.js framework and Express.js library. Our frontend design was built using HTML/CSS and Javascript, and utilized the jQuery library and bootstrap framework.
Challenges we ran into
We had difficulties bridging the backend and frontend components and interpreting the JSON files returned by requests to Microsoft’s cognitive services API.
Accomplishments that we're proud of
We're proud of successfully integrating various API’s that we never used before and putting out a practical and functional application that can automate a tedious task and provide feedback to students more efficiently than traditional methods of grading
What we learned
We learned how to implement the Microsoft Cognitive Services API (Academic Knowledge and Text Analytics) into Node.js.
What's next for LITAF
Currently LITAF’s primary audience is teachers and students, but we plan on expanding our project to anyone who wants to create a shared form and analyze responses using a variety of built-in features immediately. We see this as applicable towards feedback forms for event planning committees, where master users will be able to view popular keywords (suggestions) or interest forms to gauge positive or negative reactions using the sentiment analysis algorithm. Other possible features include a plagiarism checker to scan for duplicated content amongst the responses.









Log in or sign up for Devpost to join the conversation.