
Inspiration
SOC analysts drown in alerts. Tier-1 triage is repetitive, investigation is correlation-heavy, and the genuinely hard part — is this a real threat, or just noise? — gets rushed because there are fifty more alerts in the queue. Most "AI for security" demos stop at "chat with your logs": they answer questions but never decide and never act. We wanted an agent that works the notable queue like a real Tier-1/Tier-2/IR team — and that can take action, but only ever behind a hard human gate.
What it does
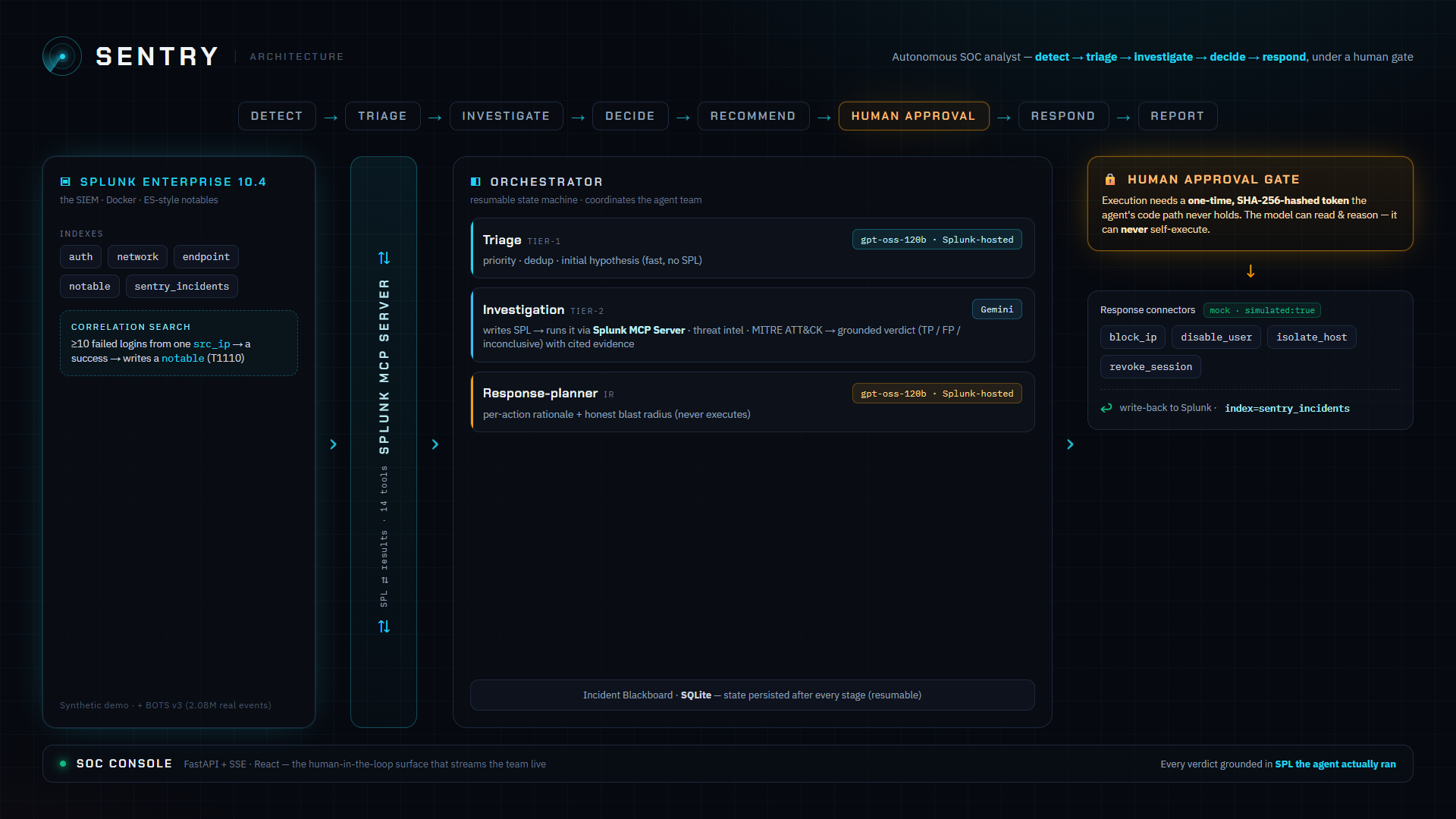
Sentry watches the Splunk notable queue and, for each alert, runs a coordinated agent team over a shared, persisted incident blackboard:
- Triage (Tier-1) assigns priority, a dedup key, and an initial hypothesis.
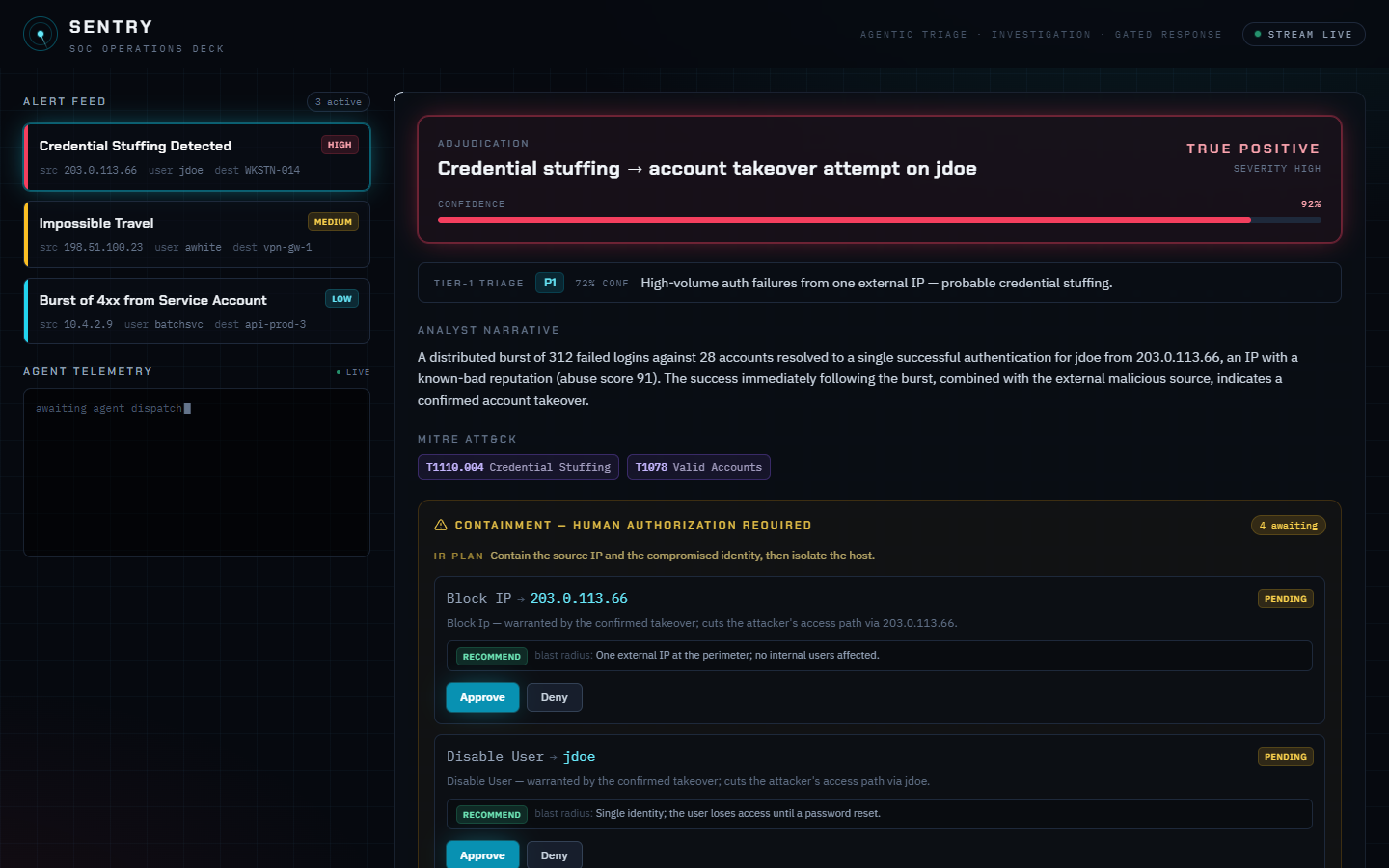
- Investigation (Tier-2) plans and runs SPL through the official Splunk MCP Server, enriches with threat intel, maps to MITRE ATT&CK, and returns a grounded verdict — true positive / false positive / inconclusive — with confidence and cited evidence.
- Response-planner (IR) turns the verdict into concrete containment, each action with a rationale and an honest blast radius.
A human then approves or denies each action in a live web console. Only an approved action runs, and the incident is written back into Splunk.
The headline is judgment. We run two scenarios through the same correlation rule: a real external credential-stuffing attack on jdoe → escalated (true positive, containment proposed); and a benign internal forgot-my-password storm on asmith → dismissed (false positive). Same alert, opposite verdicts — decided by what the investigation actually found. And it works on real data: the same agent investigates the BOTS v3 dataset (2M+ real events) and uncovers an AWS account compromise.
How we built it
- Splunk Enterprise 10.4 in Docker with
auth/network/endpoint/notable/sentry_incidentsindexes and an ES-style correlation search that fires notables via| collect. - The official Splunk MCP Server (Splunkbase app 7931) as the read/investigate interface; the Investigation agent is an MCP client driving
splunk_run_query. We also installed the Splunk AI Assistant app (7245), which surfaces itssaia_*NL→SPL tools over the same MCP server (10 → 14 tools). - A Python agent team: an
Orchestratorresumable state machine over a SQLite blackboard — state persisted after every stage, so an interrupted run resumes. - A per-agent, pluggable LLM layer: Tier-1 triage and IR response-planning run on gpt-oss-120b — a Splunk-hosted model; the deep investigation verdict runs on Gemini. Structured tool-calling throughout.
- A hard approval gate: one-time tokens, SHA-256-hashed at rest, that the agent's code path never receives — the model can reason all it wants but can never self-execute.
- A FastAPI + SSE backend and a React + Tailwind "command-deck" console that streams the team working live.
Challenges we ran into
- The Splunk Cloud trial blocks the REST API (port 8089) — which would kill both the MCP server and the action layer — so we moved to Splunk Enterprise in Docker.
- Enterprise Security isn't installable in the Docker image, so we faithfully emulate its notable / correlation / adaptive-response contracts.
- Notables read back as "Unknown Rule" —
| collectstash events aren't auto-field-extracted; fixed by referencing fields via| table. - The agent once dismissed a real attack because its events had aged out of the search window — which taught us the demo must seed fresh data inside the investigation window.
- A faster, cheaper model over-escalated the benign case, breaking the threat-vs-noise contrast — fixed by making the verdict hinge on real discriminators (source internal vs external, IP reputation, post-login lateral movement) instead of failed-login volume.
- A one-character bug (a stray null byte in a lookup key) silently dropped the blast-radius in the console — we traced it through the React fiber.
Accomplishments that we're proud of
- A genuinely closed loop on real Splunk — not a read-only assistant.
- Judgment, demonstrated: the same rule, escalated for the real attack and dismissed for the benign one, verified live.
- Proven on real-world data: the same loop flags the BOTS v3 AWS account compromise as a true positive, grounded in SPL it actually ran.
- A safety model that holds: a compromised or misbehaving model still cannot cross the gate.
- Deep, honest use of the official Splunk MCP Server: every claim in a verdict is grounded in a query the agent actually ran.
What we learned
Agentic security is less about the model and more about the harness around it — grounded tool use, a verifiable gate, resumable state, and demos built on fresh, realistic data. And that the last 10% (field extraction, time windows, a null byte) is where a demo lives or dies.
What's next
- Drive the full agent team over BOTS notables in the console and add BOTS-native correlation rules.
- Route the verdict to a security-specialized hosted model; wire in the AI Assistant's
saia_*tools once Cloud-Connected. - Real ES on a VM; multi-tenant scale-out; more correlation rules and connectors.
How it fits the prizes
- Security — an end-to-end autonomous SOC loop with a hard human-in-the-loop containment gate, ES-style notables, and write-back into Splunk.
- Best Use of the Splunk MCP Server — the Investigation agent is a first-class MCP client;
splunk_run_queryis the evidence engine behind every grounded verdict (and we extended the MCP inventory with the AI Assistant'ssaia_*tools). - Best Use of Splunk Hosted Models — two of the three agents (triage + IR planning) run on gpt-oss-120b, a Splunk-hosted model, via the OpenAI-compatible API.

Log in or sign up for Devpost to join the conversation.