Inspiration
At Accenture I was on the on-call rotation for an observability platform. Every page felt the same, especially at 3am: paste a service name into Splunk, scroll through logs, alt-tab to Grafana, check the alert in PagerDuty, then dig through a wiki for the right runbook. The hard part was never the thinking. It was the gathering. By the time I had all the data in front of me, ten minutes of an active incident were already gone, and every one of those minutes had a cost. What stuck with me most was a quieter problem. The times it hurt most were when the monitoring stack itself was degraded. A backed-up logging pipeline or a slow dashboard right when I needed it most. That is the exact moment an on-call engineer is least equipped to compensate, and it is the exact moment most tools (and most AI assistants) fall apart. I wanted to build a copilot that does the gathering for you, and that stays honest and useful precisely when its own dependencies are failing.
What it does
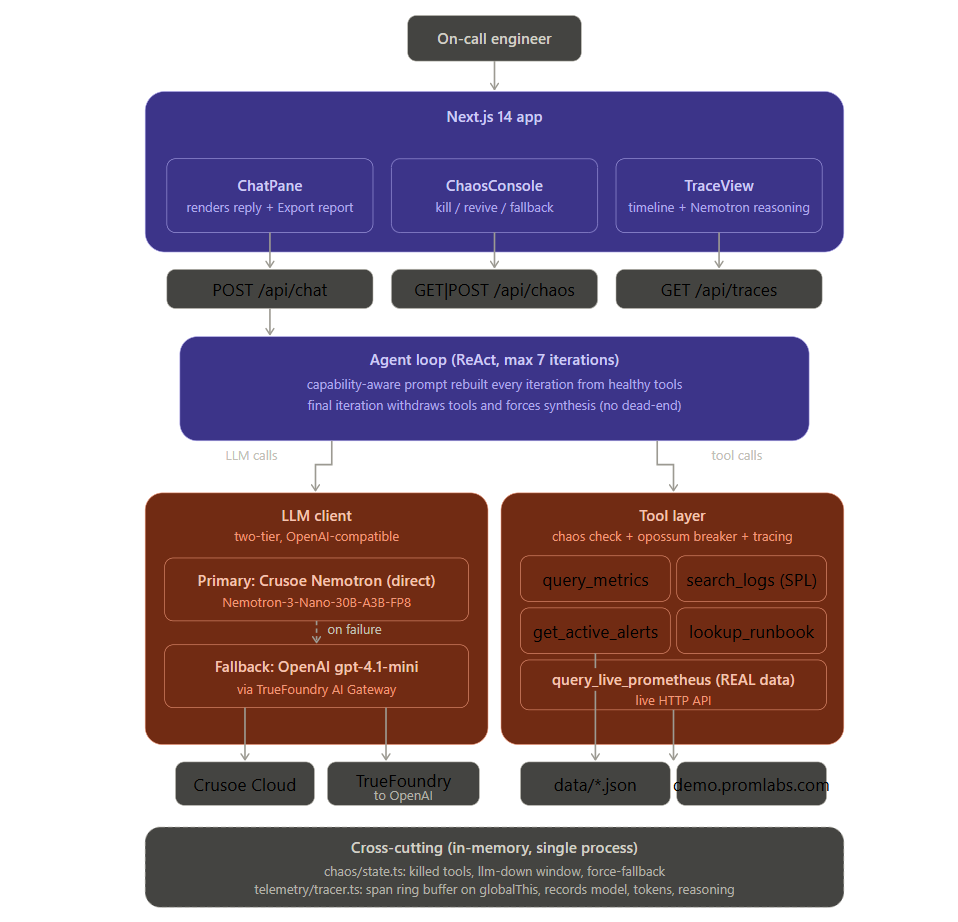
Sentinel is an AI incident-response copilot for on-call engineers. You ask it what is wrong with your system in plain English, and it runs the investigation a senior engineer would run: it queries metrics, searches logs using Splunk SPL syntax, checks active alerts, and pulls the matching runbook. Then it synthesizes an answer with cited evidence (exact timestamps, the specific log lines, the relevant alert, the runbook remediation) so you can verify its reasoning instead of trusting it blindly. The part that makes Sentinel different is how it behaves when things break. Every tool sits behind a circuit breaker, and every LLM call can fail over to a backup provider. When a data source goes down, Sentinel drops that tool from the model's available options, tells you openly that the source is unavailable, and reasons from what is left rather than fabricating a value it cannot actually see. A live degradation banner shows you exactly what is working and what is not. When you are done, one click exports a Markdown postmortem of the whole investigation. It runs on NVIDIA Nemotron via Crusoe Cloud Managed Inference, with a TrueFoundry AI Gateway failover path, and it works on real data: one of its tools queries a live Prometheus instance over HTTP, not just the bundled demo scenario.
How we built it
The stack is Next.js 14 with the App Router, React, TypeScript, and Tailwind on the front end, with the agent and all resilience logic running server-side in Node. The core is a ReAct-style agent loop. On every iteration it does four things: it checks which tools are currently healthy, rebuilds the system prompt and tool list from that live health snapshot, calls the model with only the healthy tools exposed, then runs whatever tool calls come back and feeds the results in. On the final iteration it withdraws the tools and forces the model to answer from the evidence gathered, so it never burns its whole budget without producing something useful. Three resilience patterns sit underneath that loop. Provider failover lives in the LLM client: the primary path is Nemotron on Crusoe, and a TrueFoundry gateway path to a backup model takes over on failure, all behind one OpenAI-compatible interface so the agent loop never knows which provider answered. Per-tool circuit breakers use the opossum library: a tool that keeps failing trips its breaker, fast-fails instead of hanging, and auto-recovers after a probe window. Capability-aware prompting ties it together: because the prompt is rebuilt from live tool health every iteration, a dead tool is physically absent from the model's options, which is what stops it from hallucinating data from a source that is down. For the demo, four tools read from a hand-crafted, internally consistent incident (a checkout latency spike caused by orders-db connection pool exhaustion, traced to a known leak in payment-processor), so the scenario is deterministic and reproducible on camera. A fifth tool hits a real live Prometheus API to prove the architecture is not just reading from fixtures. A Chaos Console lets me (or a judge) inject failures on demand: kill any tool, take the LLM down, or force the fallback. An in-memory tracer records every LLM call, tool call, retry, and failover, and the trace view renders it as a timeline with a panel showing Nemotron's reasoning at each step.
Challenges we ran into
The hardest conceptual problem was making the agent honest under failure rather than just resilient. My first version kept all tools advertised to the model and let failed calls return errors. The model would either keep retrying the dead tool or, worse, start inventing plausible-looking metric values to fill the gap. The fix was capability-aware prompting: rebuild the tool list from live health on every single iteration so the model literally cannot call, or fabricate from, a source that is down. Getting that rebuild to fire the instant a circuit breaker tripped, mid-conversation, took some careful sequencing. The mechanics of tool calling were a second source of pain. The model's assistant message carrying tool calls has to be preserved in the conversation history with its tool-call IDs intact, because the tool-result messages reference those IDs. Stripping that message (which felt natural, since I was already tracking the results) produced opaque API errors until I traced it back. Layering two independent failure systems also created subtle interactions. The chaos injection has to happen inside the circuit breaker so the breaker actually counts the induced failures and trips realistically, rather than around it, which would let chaos bypass the very mechanism I was trying to demonstrate. And making the in-memory tracer and chaos state survive Next.js hot reloading during development meant stashing them on globalThis, which is not obvious until your spans keep vanishing on every file save.
Accomplishments that we're proud of
I'm proud that Sentinel does the thing it claims: it genuinely behaves better when broken than a lot of agents behave when everything works. The demo where I kill a tool mid-investigation and it adapts honestly, then kill the model provider and it fails over without dropping the conversation, is the moment the whole idea becomes real. I'm also proud that it is not a toy. The live Prometheus integration proves the architecture handles real, real-time data, not just curated fixtures. And the forced-synthesis design means there is no dead-end failure mode where the user gets nothing. Building all of this solo, end to end, in the hackathon window, with a clean separation of layers that would let each mocked tool be swapped for a real production API without touching the agent above it, is the part I'm happiest with.
What we learned
The biggest lesson was that resilience for an AI agent is mostly an honesty problem, not an uptime problem. Keeping a degraded agent running is the easy half. Keeping it from confidently making things up when it is degraded is the hard and important half, and it lives in prompt construction as much as in infrastructure. I learned a lot about the practical edges of agentic systems: how brittle the tool-calling message contract is, why circuit breakers belong around individual tools rather than the whole tool layer, and how much an LLM gateway simplifies multi-provider failover by turning it into a configuration concern instead of application code. I also got a much clearer feel for the difference between a demo that looks impressive and a system that is actually architected to survive contact with production.
What's next for Sentinal AI
The immediate next step is swapping the mocked tools for real integrations: Splunk's REST API for logs, Loki, PagerDuty for alerts, and a wiki source for runbooks. The live Prometheus tool already proves the pattern, and because the agent loop is decoupled from the tools, each swap is a contained change in a single module. Beyond that: routing the primary LLM path through the TrueFoundry gateway as well, so all providers sit behind one control plane for centralized cost tracking and zero-code model swaps. Moving the chaos and trace state to Redis and exporting traces to OpenTelemetry for a real multi-worker deployment. Adding streaming responses so answers appear token by token during an incident. And eventually a learning loop, where resolved incidents and their postmortems feed back in so Sentinel gets sharper at recognizing recurring failure patterns over time.
Built With
- crusoe-cloud
- nanoid
- next.js
- node.js
- nvidia-nemotron
- openai-sdk
- opentelemetry
- opossum
- prometheus
- react
- react-hooks
- splunk
- tailwindcss
- truefoundry
- typescript
- zod

Log in or sign up for Devpost to join the conversation.