Inspiration
As LLMs grow more capable, the need to ground their responses in real, domain-specific data becomes critical. I was inspired by Google's Kaggle 5 day Gen AI course and with tons of inforamtion in each white paper especially in enterprise, research, and education. The release of Google’s Agent Development Kit (ADK) and Vertex AI RAG Engine offered the perfect foundation to build a system that lets anyone interact with their own documents — using natural language.
What it does
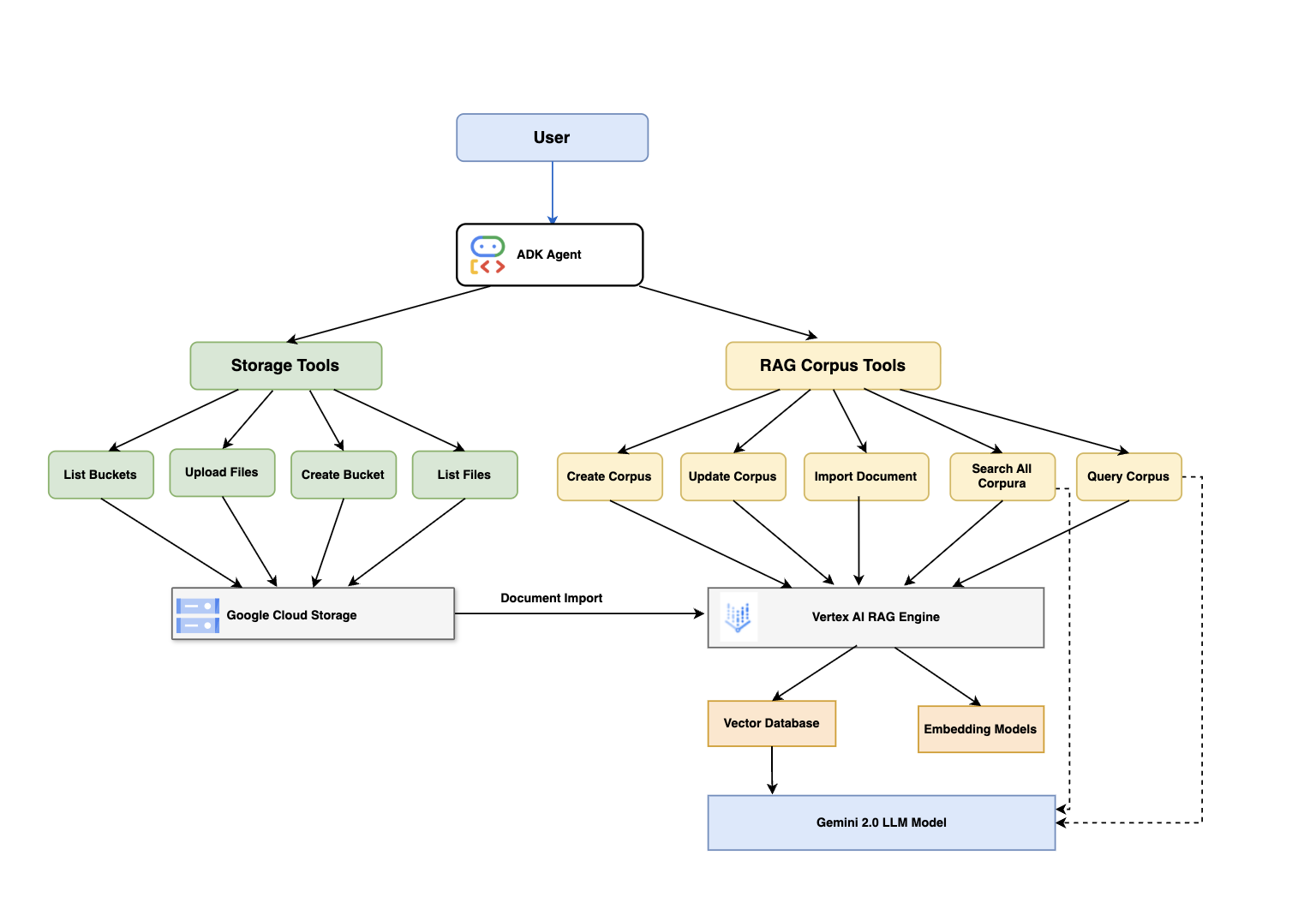
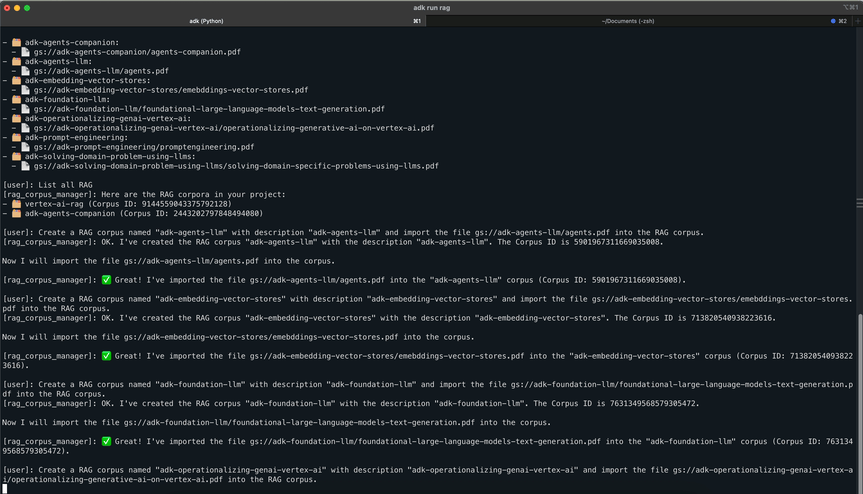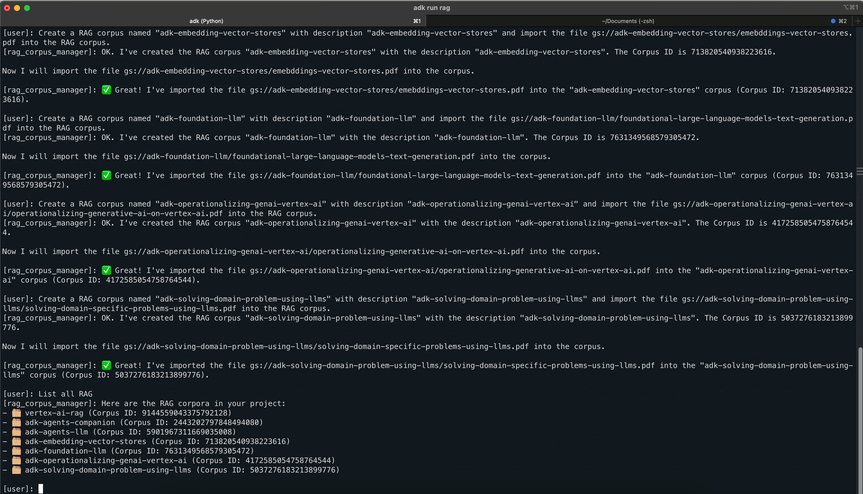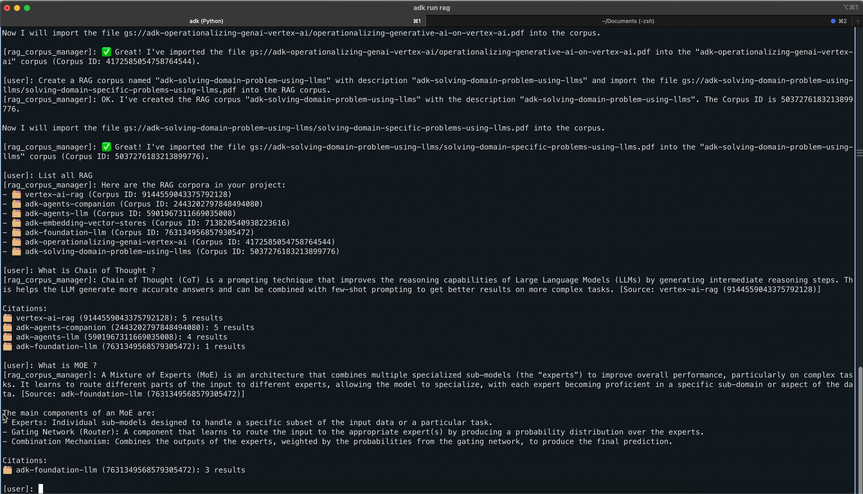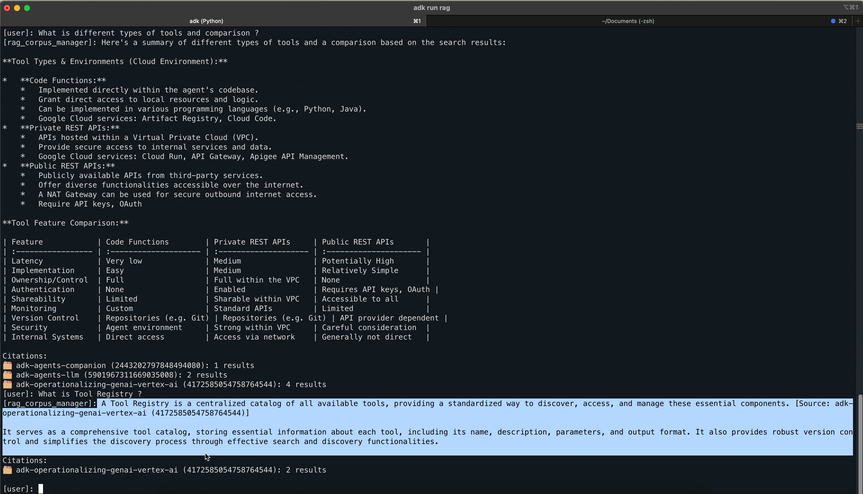
We built a Retrieval-Augmented Generation (RAG) agent that can: 📥 Ingest any PDF or text document via drag-and-drop 🧠 Chunk and embed it using Vertex AI RAG Engine 📦 Store and manage corpora in Google Cloud Storage 🔍 Perform semantic search across multiple corpora 🧾 Generate Gemini-powered answers grounded in source data, complete with citations
All orchestrated through Google’s Agent Development Kit (ADK) with both CLI and Web UI support.
How we built it
Built using Google ADK Web + CLI as the orchestration layer
Used FunctionTool-based modular toolkits for:
GCS operations (upload/list)
RAG corpus/file management
Multi-corpus querying and Gemini integration
Documents were uploaded through ADK Web and stored in GCS
Configurable metadata (bucket names, embedding models, corpus descriptions) were loaded dynamically
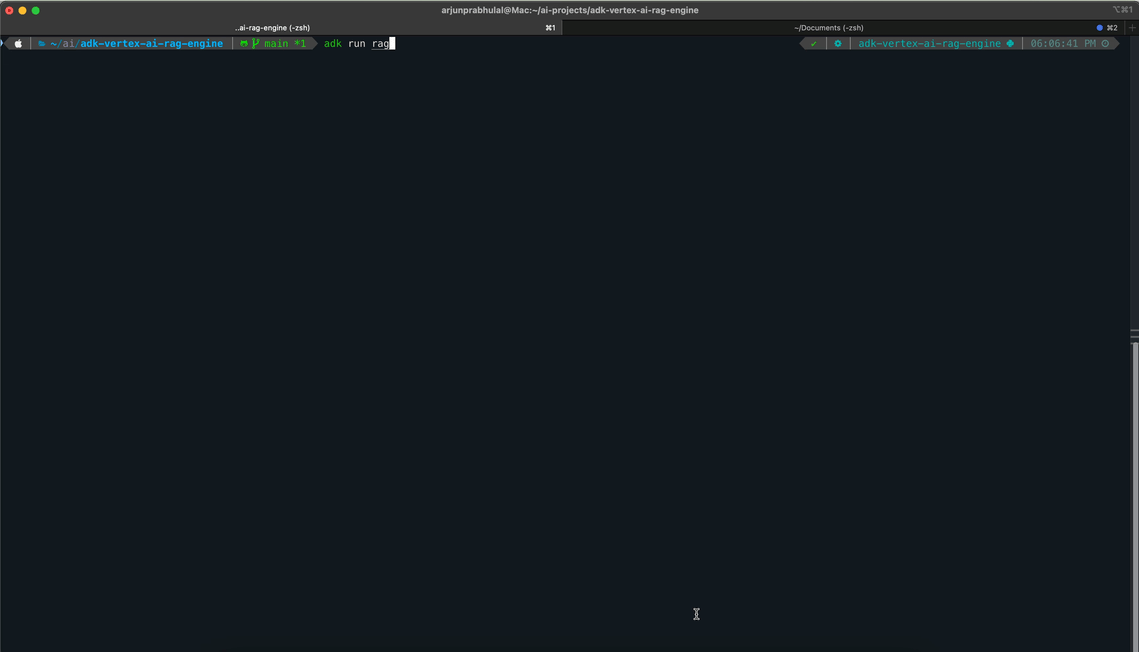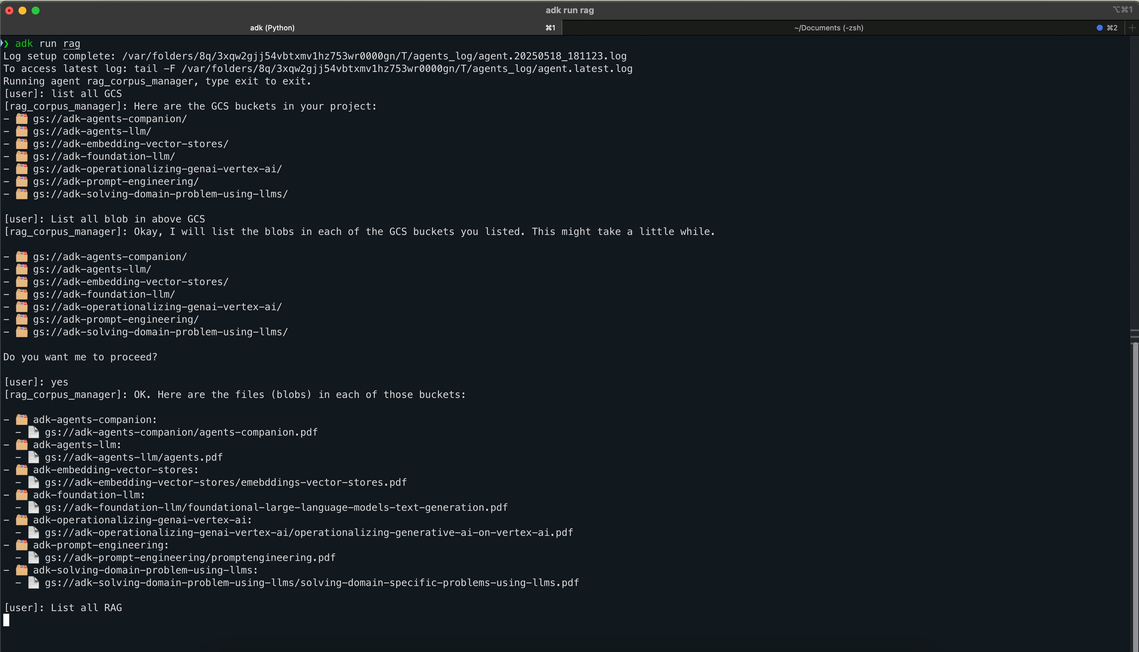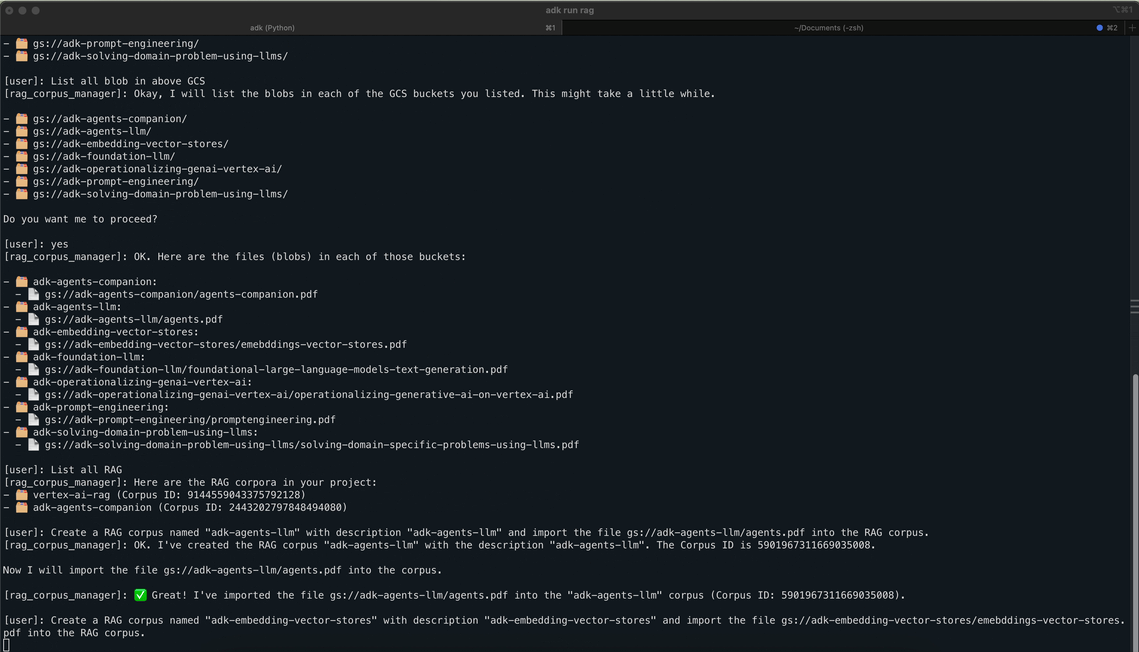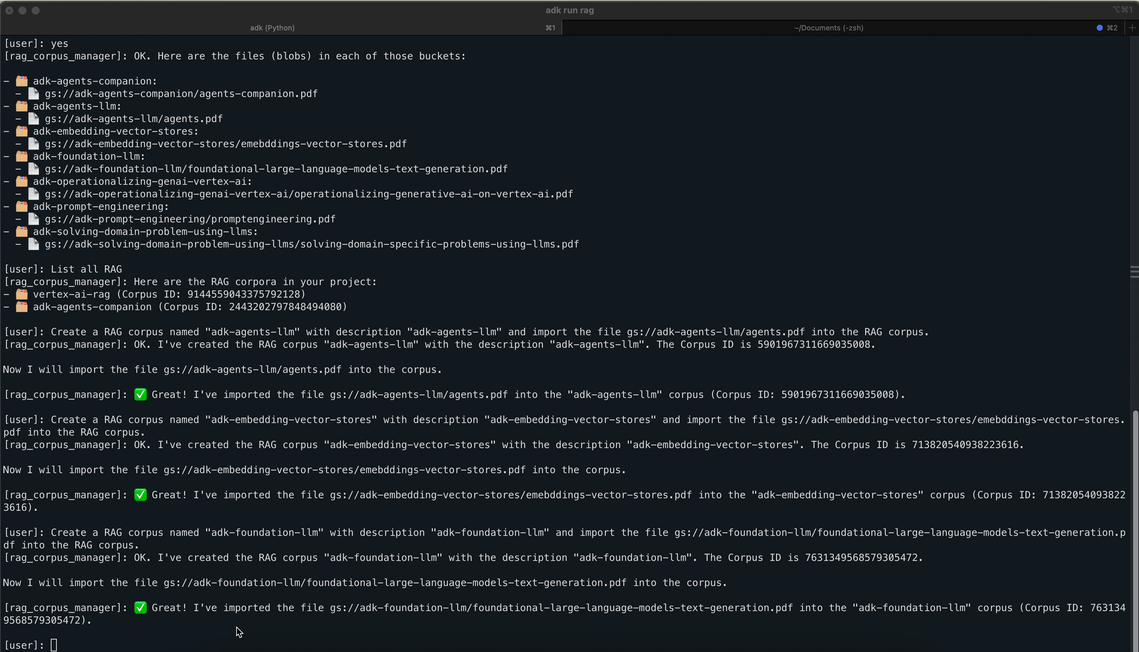
Tested on real-world data: 7 documents from Google’s 5 day GenAI Intensive course
Challenges we ran into
Understanding how to wire tools and user input using ADK’s FunctionTool APIs
Toughest part was Handling file MIME-type detection and binary upload logic within ADK’s artifact system -
Managing authentication for both GCS and Vertex AI across different stages with ADC and Service account
Formatting results with proper citation structure while maintaining LLM flexibility based on prompt
Accomplishments that we're proud of
Built a working RAG agent with end-to-end document ingestion and querying in under 2 minutes
Seamlessly integrated Gemini to produce accurate, grounded responses
Created a reusable, open-source framework that can be extended to any use case — internal Q&A bots, research assistants, legal search, and more
Made it usable even for non-engineers with an intuitive ADK Web UI
What we learned
How to design and deploy RAG pipelines using Google Cloud-native tools
Best practices for building multi-modal AI agents with ADK
Effective schema design and prompt tuning for citation-aware answers
How to bridge cloud infrastructure (GCS, Vertex AI) with agentic LLM interfaces
What's next for RAG agent using ADK and Vertex AI RAG Engine
📁 Add support for batch document ingestion from shared folders
🧠 Integrate memory-based follow-up questioning using ADK’s memory tools
🔐 Enable authentication and access control per corpus
🌐 Build a front-end dashboard to visualize corpora, sources, and queries
📦 Publish as a reusable ADK agent template for open-source and enterprise teams
Built With
- agent-development-kit
- cloudstorage
- gcs
- gemini
- google-adk
- google-cloud
- rag
- vertex-ai-rag-engine
- vertexai

Log in or sign up for Devpost to join the conversation.