-
-
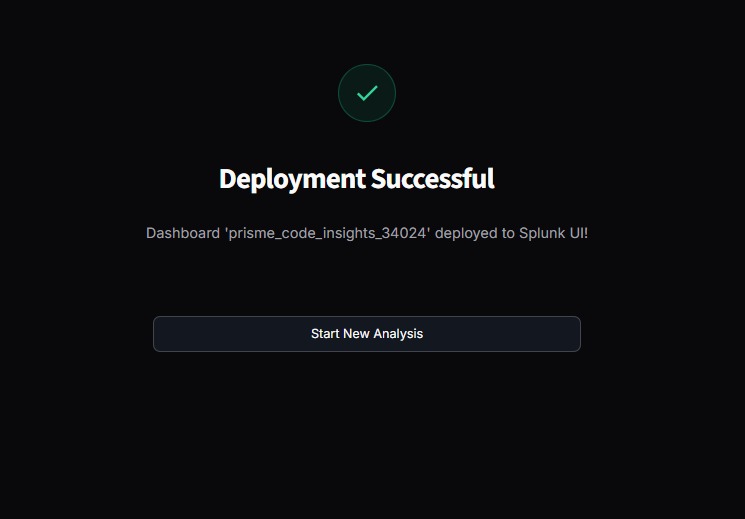
Deployment
-
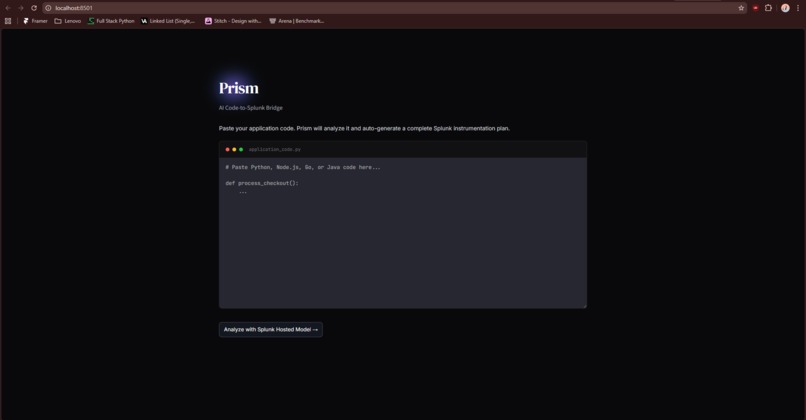
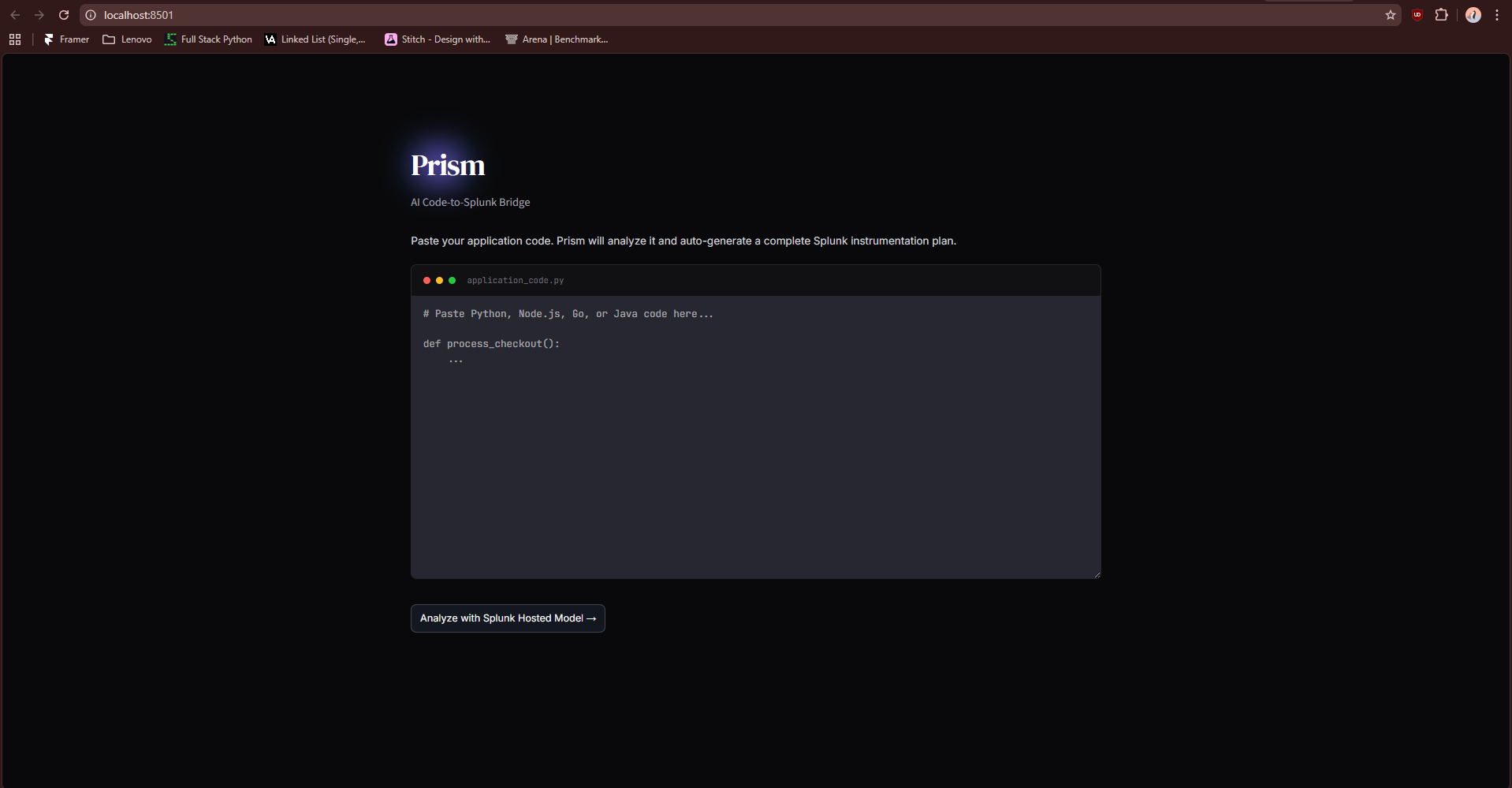
Main Screen
-
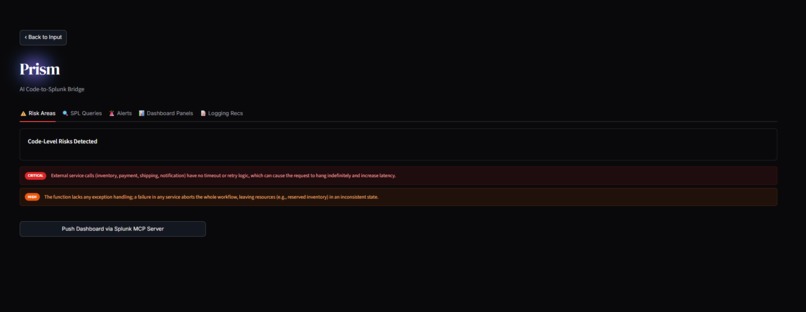
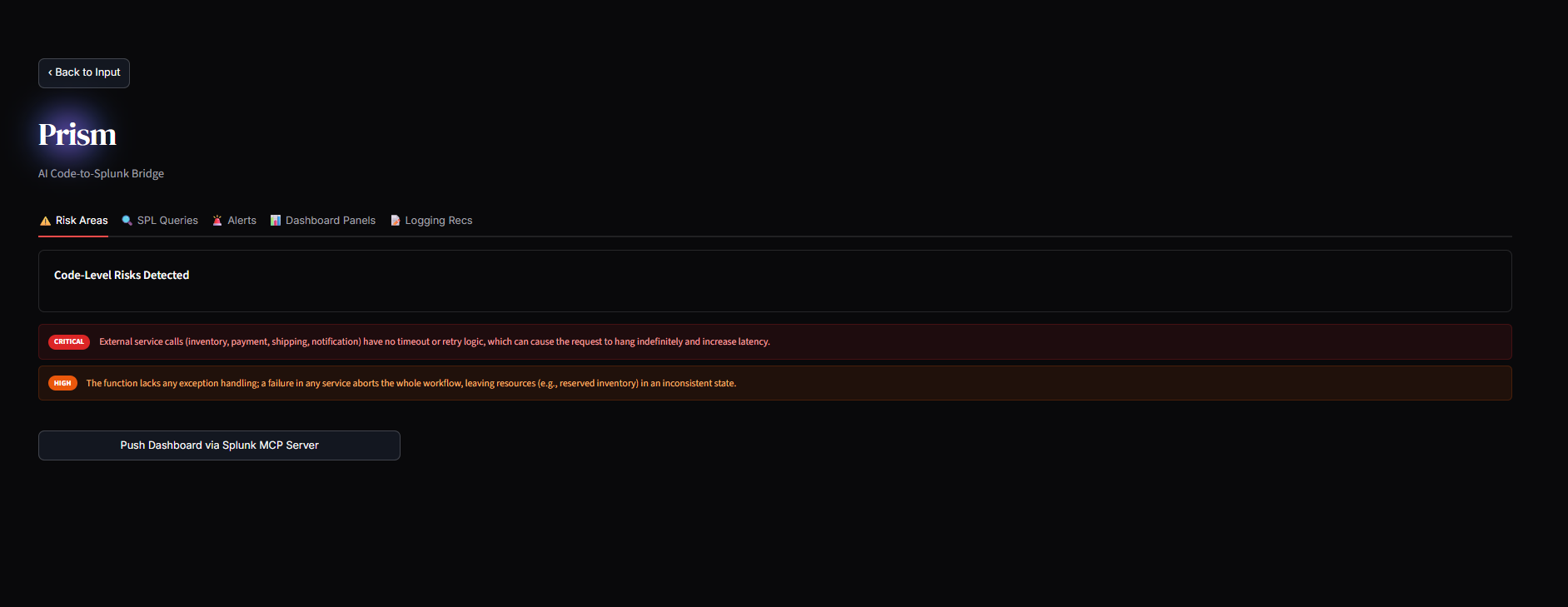
Risk Results
-
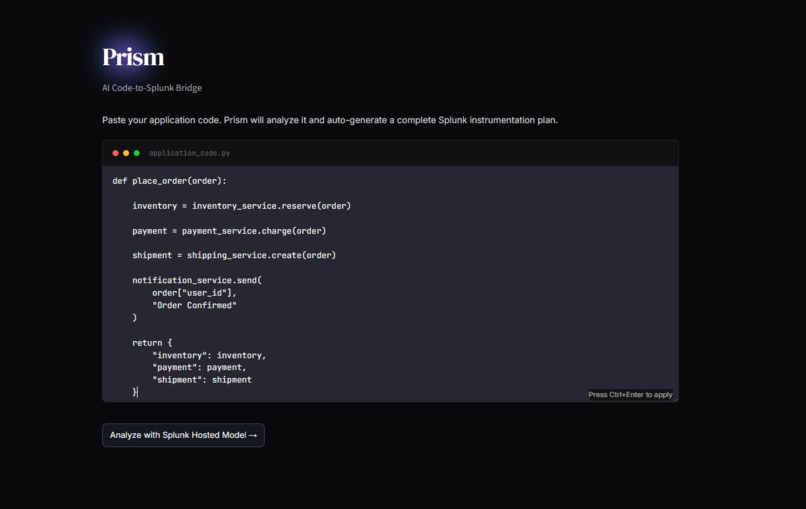
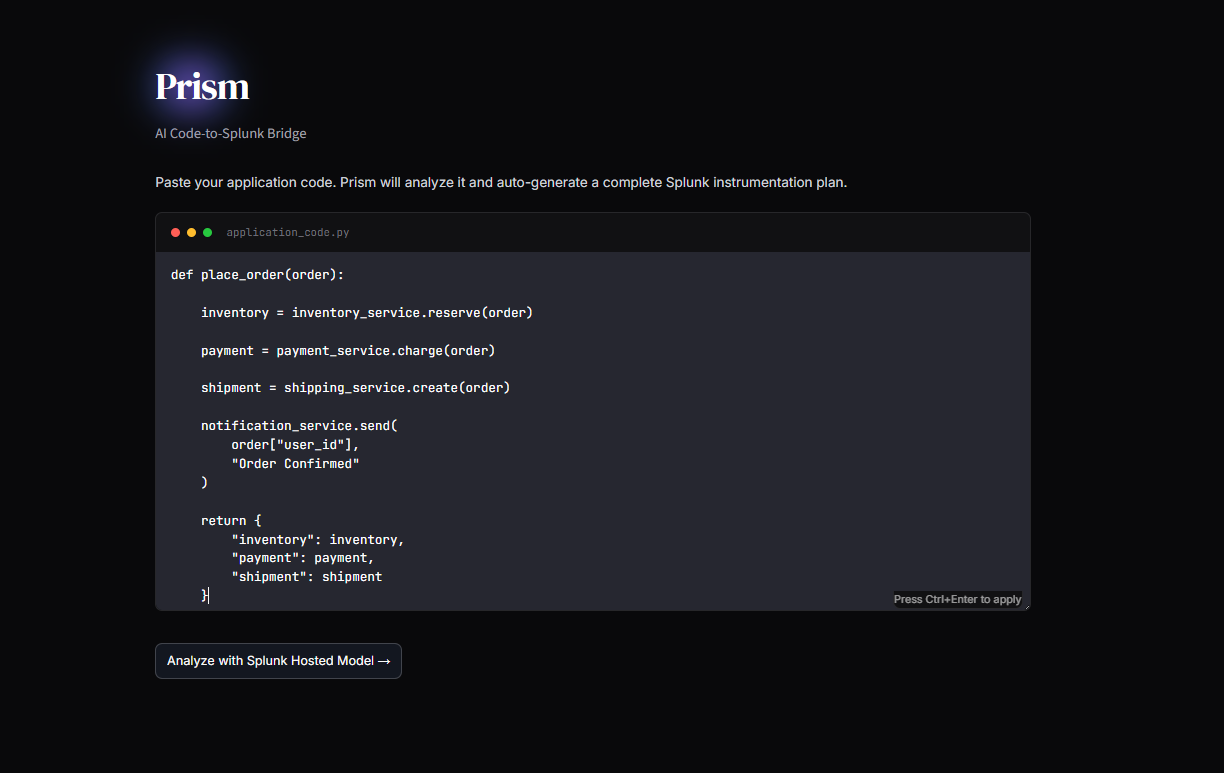
Code/Log Input
-
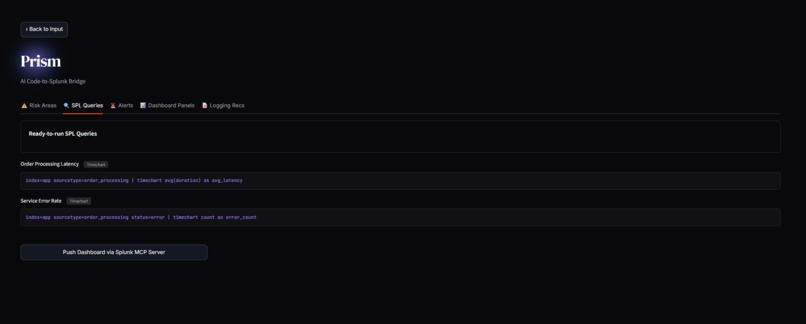
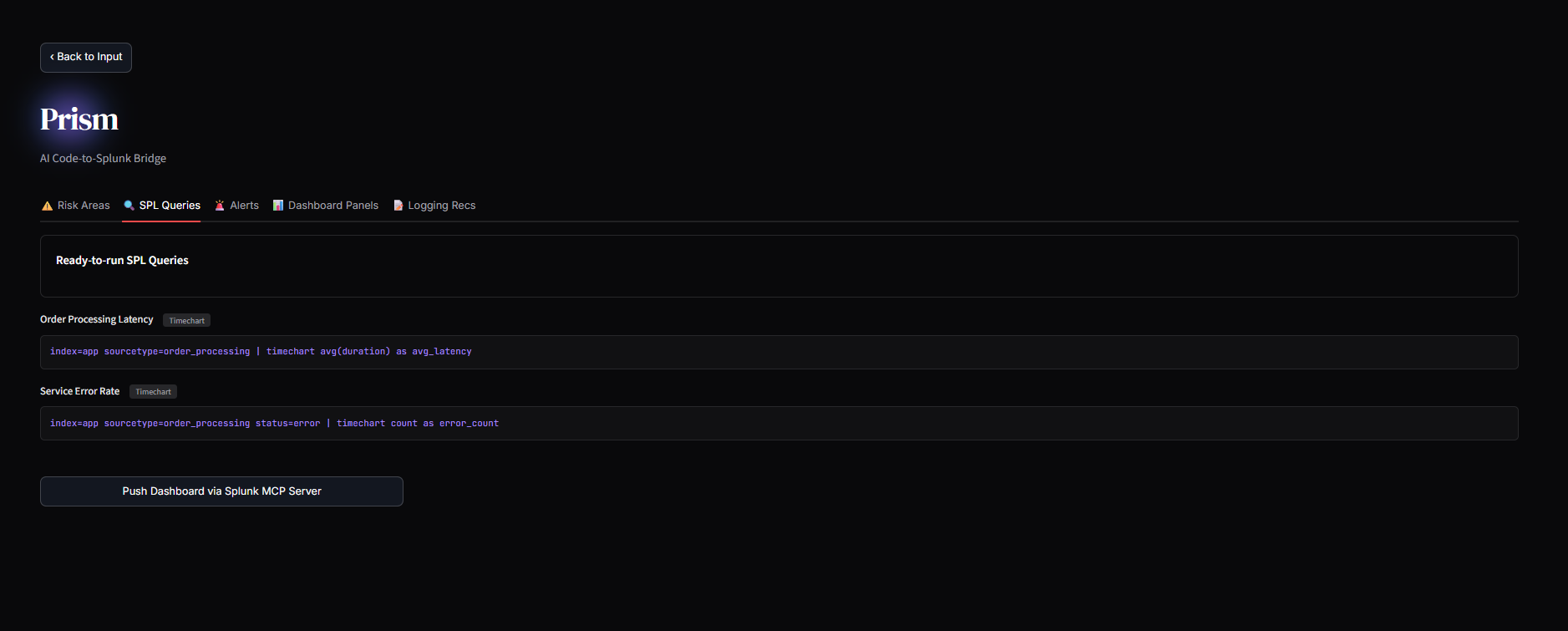
Queries
-
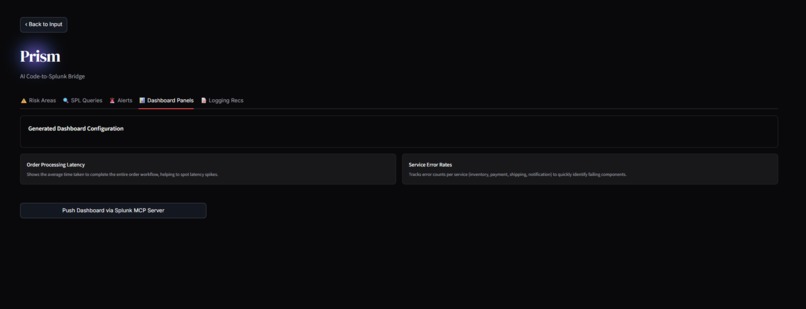
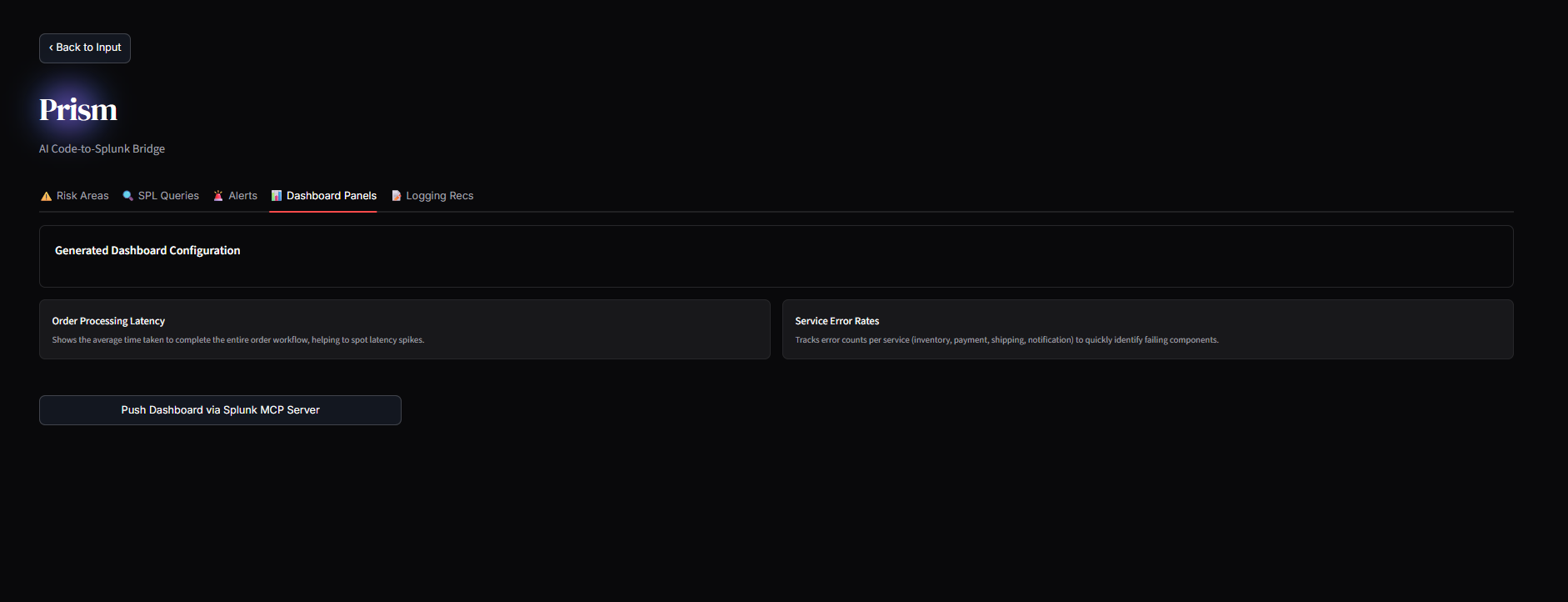
Dashboard
-
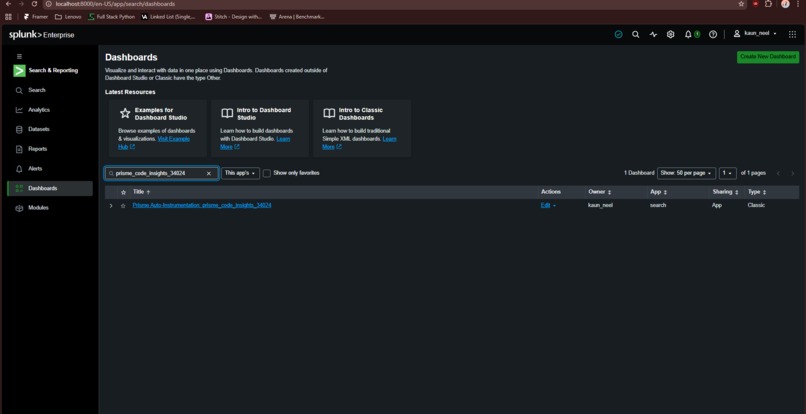
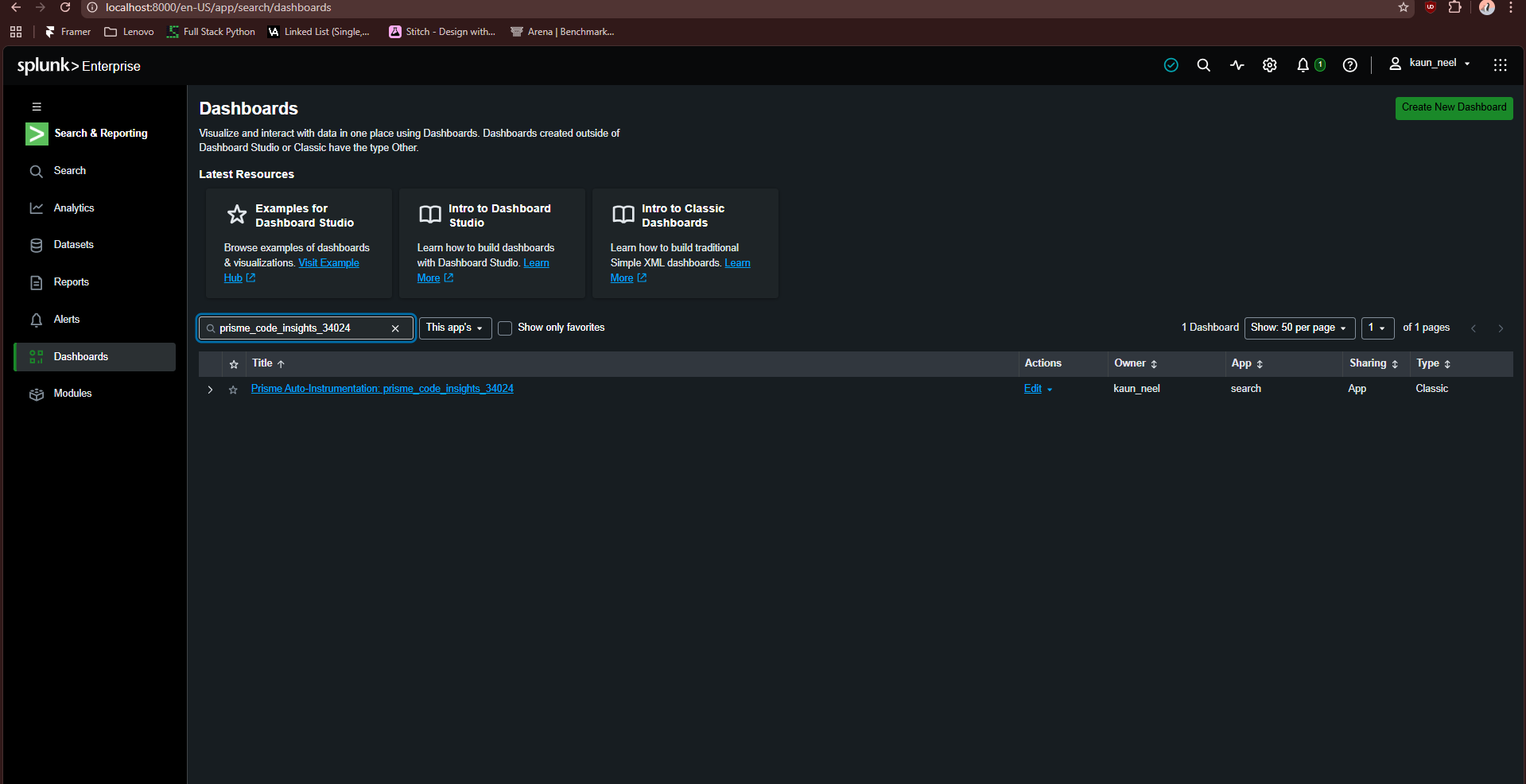
Result on Splunk Enterprise
Inspiration
Historically, the software development lifecycle has a massive blind spot: Observability is almost always an afterthought. Developers push code to production, wait for things to break, and then spend hours trying to onboard raw logs, write complex Regular Expressions, edit props.conf, and draft SPL queries.
By the time the Splunk dashboard is finally built, the system has already crashed, and the damage is done.
We asked ourselves: What if Splunk could instrument itself before the code is even deployed? We wanted to achieve true "Shift-Left" observability. This inspired Prisme: an autonomous Agentic Ops platform that eliminates manual data onboarding and transforms raw code into live Splunk environments in seconds.
What it does
Prisme is an enterprise-grade AI agent that operates through a dual-app platform:
1. Zero-Touch Data Onboarding:
Users paste a raw, unstructured log payload (e.g., custom JSON, messy syslogs, or deeply nested XML). Prisme's 120B parameter brain vectorizes the payload, identifies Splunk Common Information Model (CIM) fields, calculates exact parameters like MAX_TIMESTAMP_LOOKAHEAD, and autonomously creates the Source Type directly in the Splunk core via REST API.
2. The Code-to-Splunk Bridge: Users paste raw application code (Python, Node.js, Go). Prisme analyzes the Abstract Syntax Tree (AST) to identify unhandled exceptions, database connection leaks, and latency bottlenecks. It then dynamically generates ready-to-run SPL queries and autonomously pushes a live XML Dashboard into Splunk Enterprise, ready to catch errors the second the code goes live.
How we built it
We architected Prisme as a modular, 3-part microservice pipeline :
- The Brain (LangChain + gpt-oss:120b-cloud): We utilized a massive 120-billion parameter open-source LLM hosted on Ollama Cloud. Using LangChain, we engineered strict system prompts to force the LLM to act as a Senior Splunk Architect.
- The UI (Streamlit): We bypassed standard components, utilizing deep CSS injection and
st.html()to create a "Brutalist" Enterprise SaaS interface. It features real-time telemetry, simulated latency jitter, and cinematic fullscreen animations. - The Muscle (Python + Splunk REST API): The agent takes action in the real world by formatting the LLM's intelligence into JSON payloads and firing
POSTrequests to Splunk's/services/saved/sourcetypesand/servicesNS/nobody/search/data/ui/viewsendpoints.
We conceptualized the onboarding process as a deterministic mapping function, where the Agent ($A$) minimizes the Time-to-Observability ($TTO$). Given an unstructured input space $\mathcal{U}$ (raw logs or code), the Agent outputs a structured Splunk artifact set $\mathcal{S}$:
$$ A: \mathcal{U} \rightarrow \mathcal{S} \quad \text{where} \quad \mathcal{S} = { \text{Regex}, \text{props.conf}, \text{SPL}, \text{XML Dashboard} } $$
The agent mathematically computes configuration variables, such as determining the optimal MAX_TIMESTAMP_LOOKAHEAD by calculating the length of the extracted timestamp subset $T(x)$:
$$ L_{max} = \arg\max_{x \in \mathcal{U}} |T(x)| + \epsilon $$
By autonomously executing the API payload, Prisme reduces the manual onboarding time complexity from $\mathcal{O}(N)$ (human hours) to $\mathcal{O}(1)$ instantaneous API execution.
Challenges we ran into
- JSON Hallucinations: The 120B model occasionally wrapped its JSON outputs in Markdown backticks (e.g.,
json { ... }). When Python tried to parse this, the app would crash. We engineered a robust Regular Expression fallbackre.search(r'\{.*\}', raw_text, re.DOTALL)to surgically extract the JSON from the LLM's conversational text. - Streamlit DOM Corruption: While building the cinematic UI, we found that calling
st.rerun()while inside a custom HTML<div>caused the Streamlit engine to skip rendering the closing tags, permanently breaking the layout. We resolved this by cleanly separating our backend state-management from the frontend HTML rendering. - Splunk XML Parsing: Dynamically generating Splunk Dashboards via the REST API requires perfectly formatted Simple XML. We had to build a custom string-interpolation engine to wrap the AI's generated SPL queries inside valid
<row>,<panel>, and<chart>tags before posting to the API.
Accomplishments that we're proud of
- Closing the Loop: We didn't just build a chatbot that tells you what to do. We built a true Agent that safely executes
POSTrequests and configures an Enterprise Splunk engine on your behalf. - Enterprise Design: We successfully built a frontend that completely breaks out of the standard "hackathon prototype" look, delivering a sleek, dark-mode, Silicon Valley-style UI that feels ready for production.
What we learned
- We gained a deep understanding of Splunk's backend REST API authentication and endpoint structures (specifically how Splunk manages ownership spaces like
/servicesNS/nobody/). - We learned how to orchestrate multi-step Agentic workflows, passing state dynamically from user input $\rightarrow$ LLM generation $\rightarrow$ API Execution $\rightarrow$ Success Validation.
What's next for Prisme AI
During the hackathon, we proved that AI can autonomously construct Splunk environments. Next, we plan to fully integrate Prisme into the CI/CD pipeline using GitHub Webhooks.
Imagine opening a Pull Request with new application code, and Prisme automatically comments on the PR with a link to a freshly generated, live Splunk Dashboard specifically tailored to monitor your new feature. That is the true future of Agentic Ops.


Log in or sign up for Devpost to join the conversation.