-
-
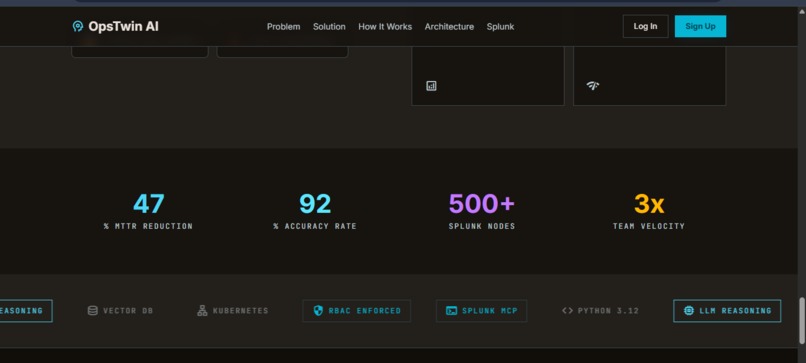
-
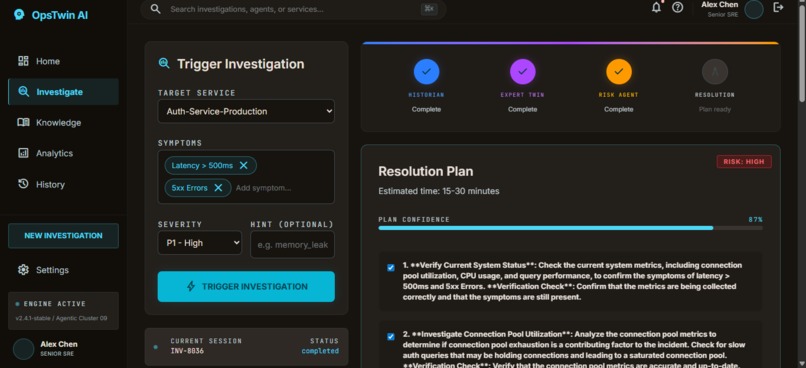
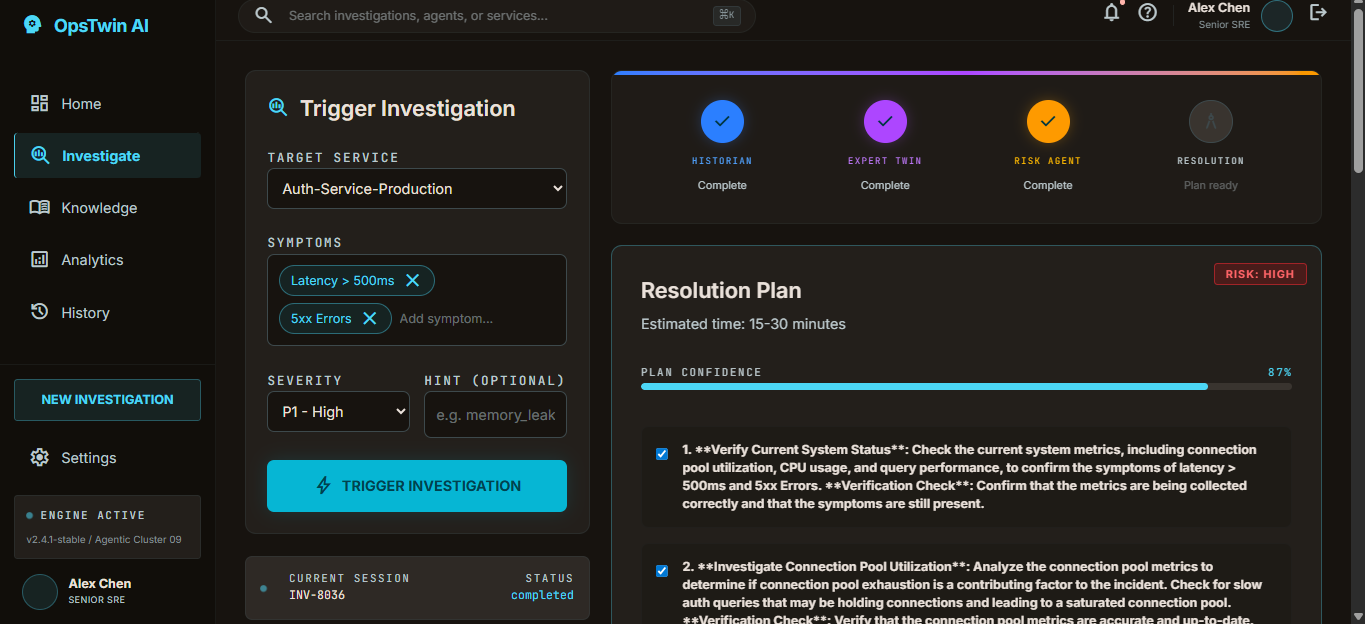
Dashboard Investigation page
-
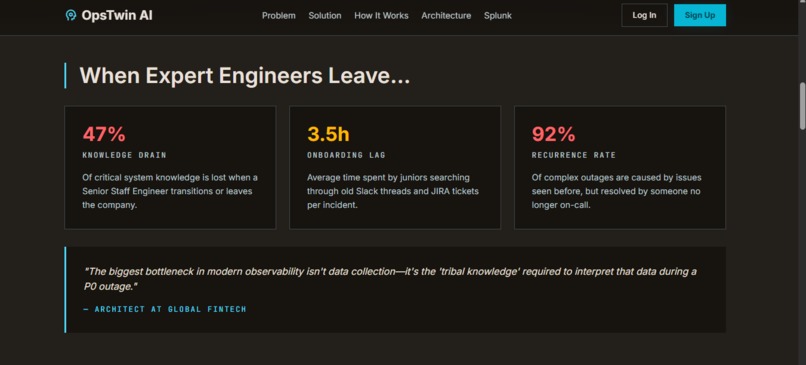
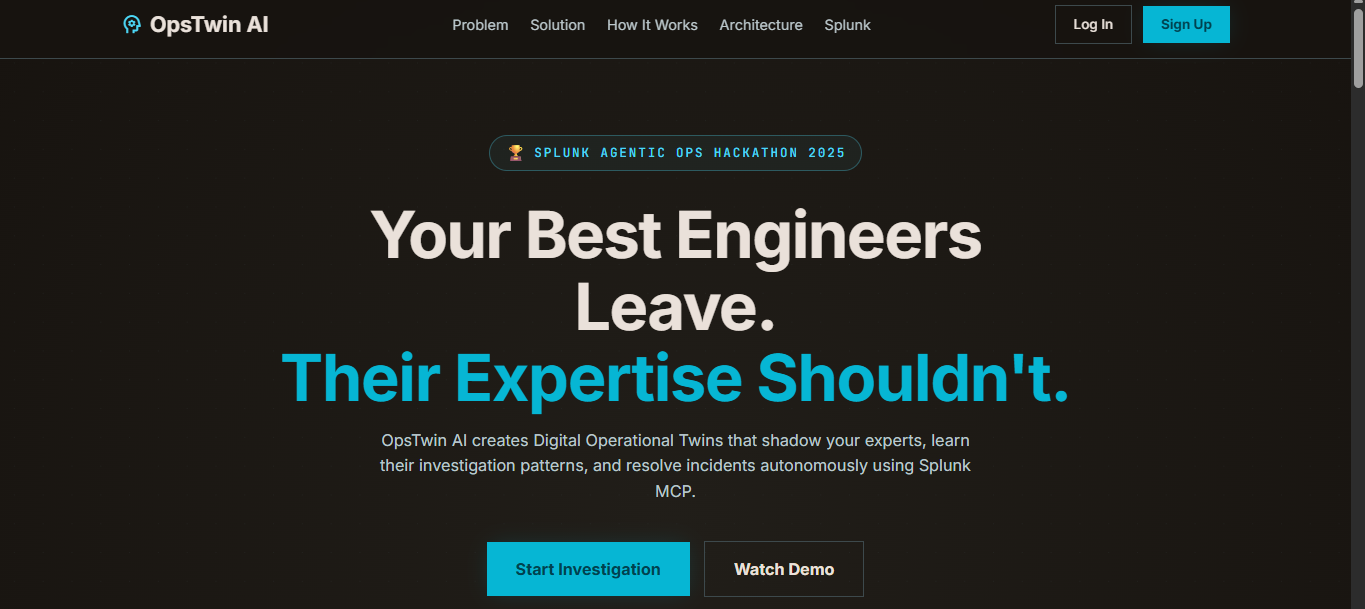
Landing page
-
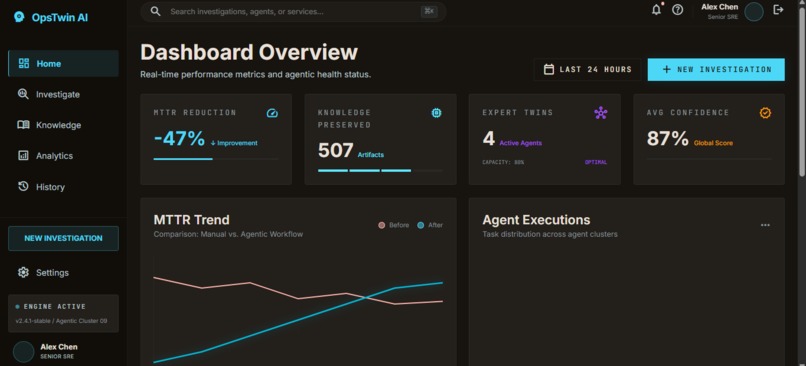
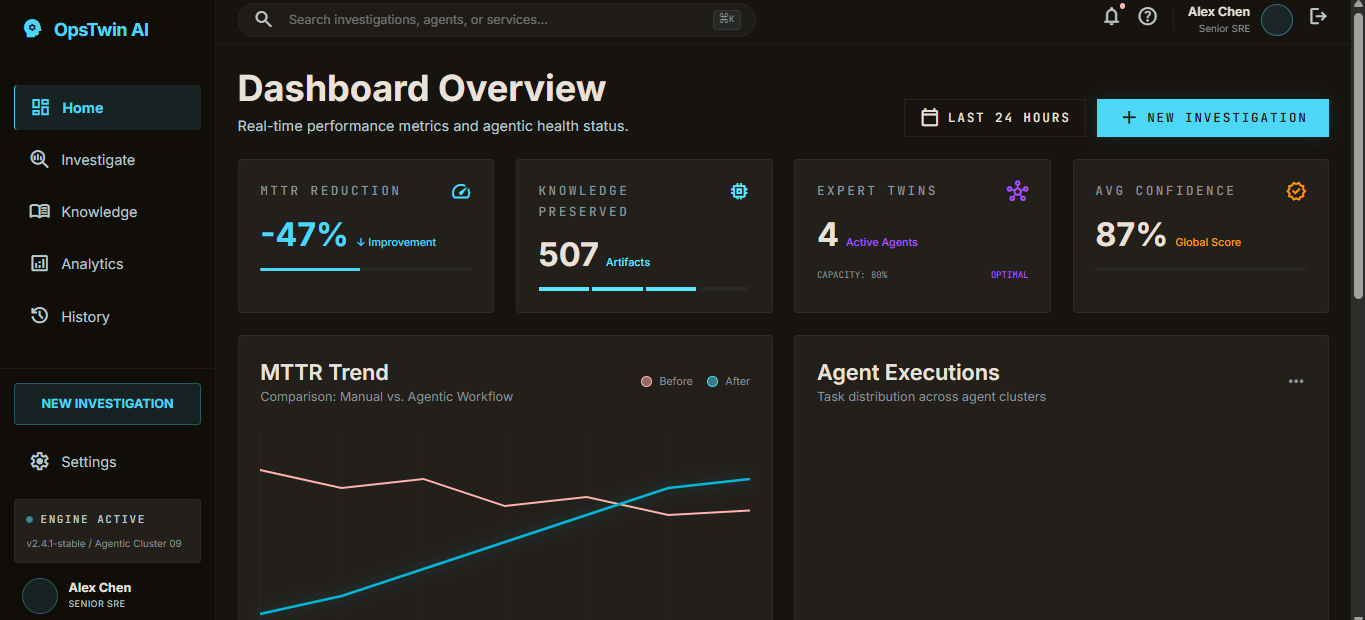
Dashboard Overview page
-
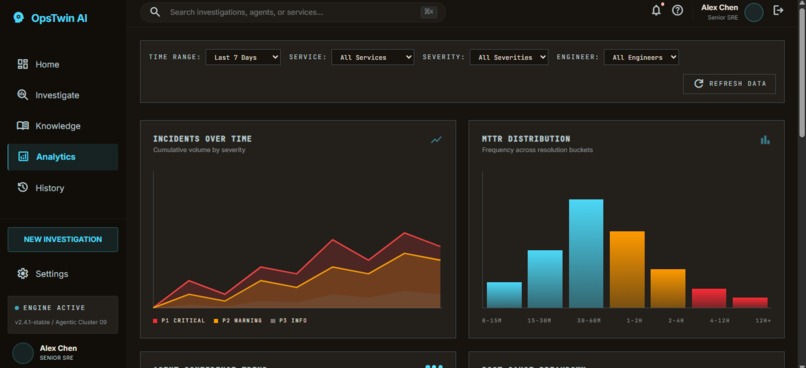
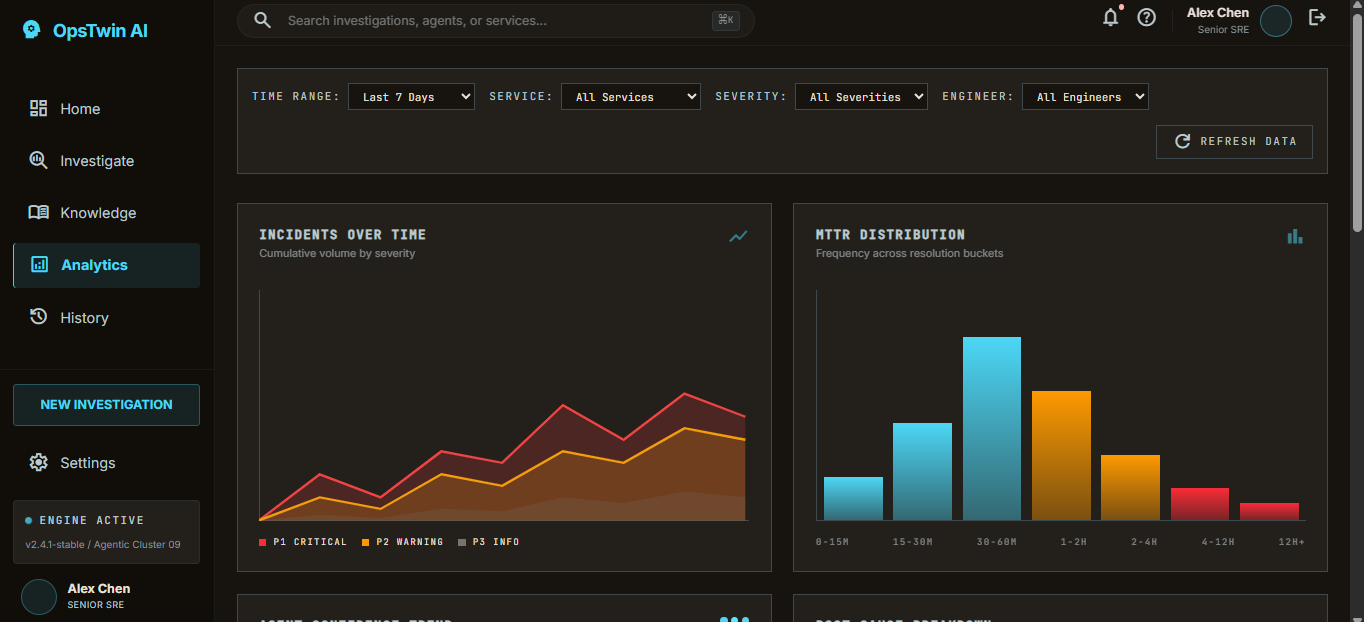
alaytics page
-
landing page
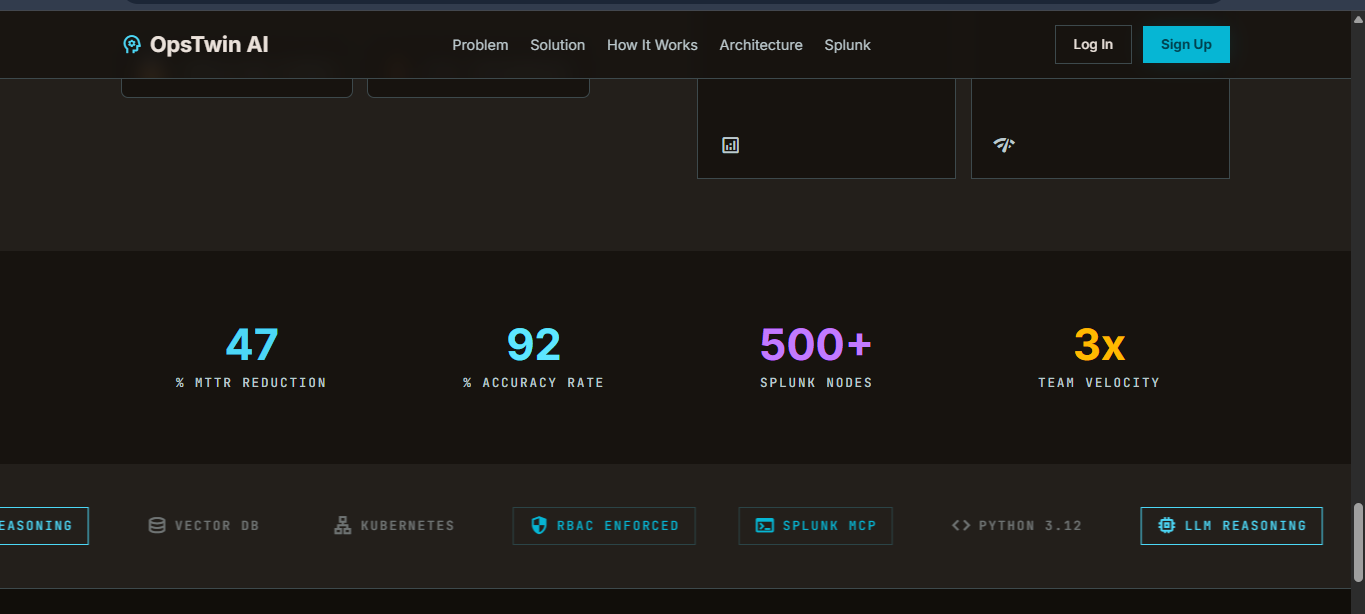
Inspiration
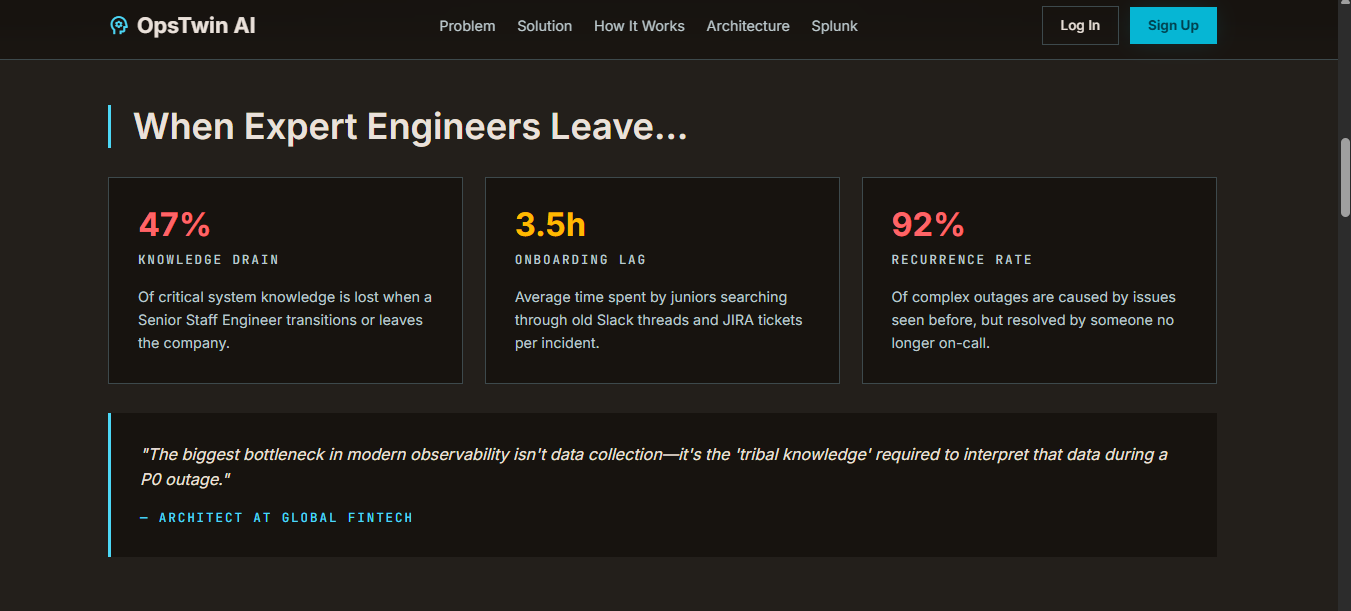
Every organization has that one senior engineer who can resolve critical incidents in minutes — they know which alerts actually matter, which metrics are misleading, and exactly where to look first. When these engineers leave, organizations lose years of accumulated operational wisdom overnight. We watched teams struggle with 3x longer resolution times after key engineers departed, repeatedly solving problems that had already been solved before. We asked: what if we could preserve that expertise as AI agents that never leave?
What it does
OpsTwin AI creates Digital Operational Twins of expert engineers. It learns investigation patterns, decision-making processes, and remediation strategies from Splunk operational data. When a new incident occurs, 4 specialized AI agents collaborate in sequence:
- Historian Agent — searches Splunk for similar past incidents and runs ML-based anomaly detection
- Expert Twin Agent — identifies the best engineer for this type of issue and simulates their investigation approach
- Risk Assessment Agent — calculates blast radius and ranks remediation actions by safety
- Resolution Planner — merges all findings into a step-by-step plan with a confidence score
The result: a junior engineer gets an actionable resolution plan in seconds — based on how the senior engineer solved similar problems before. Human approval is required before execution, ensuring safety while dramatically reducing MTTR.
How we built it
We started with Splunk Enterprise as the core data platform, loading 500 realistic incidents with distinct engineer specialization patterns (Alex specializes in Redis/infrastructure, Maria in auth/security, etc.).
The backend is a FastAPI application with a LangGraph-orchestrated agent pipeline. Each agent queries Splunk exclusively through our MCP (Model Context Protocol) service layer — no agent touches Splunk directly. We integrated Splunk's native ML capabilities via SPL for anomaly detection, root cause prediction, and MTTR estimation. For generative reasoning (expert simulation, plan synthesis), we use Groq's Llama 3.3 70B.
The frontend is a React dashboard built from custom stitch designs with a warm-charcoal and electric-cyan design system. Authentication uses JWT with Neon PostgreSQL storing users and persisting all investigation results.
Deployment: Frontend on Vercel with rewrites proxying to an AWS EC2 instance running both the FastAPI backend and Splunk Enterprise.
Challenges we ran into
- Splunk MCP Server compatibility — The community MCP packages had breaking dependency conflicts with fastmcp 3.x. We solved this by implementing our own MCP-style service layer that provides structured tools for agents while using Splunk's REST API underneath.
- Multi-Python version conflicts — Having Python 3.11 and 3.13 installed caused packages to install in one version but execute in another. Learned to always use
py -3.13 -mconsistently. - HTTPS mixed content — Vercel serves HTTPS but our EC2 backend is HTTP. Solved with Vercel rewrites acting as a proxy.
- Making synthetic data feel real — Random incident generation produced noise that agents couldn't learn from. We redesigned the data generator to give each engineer distinct specialization patterns, investigation styles, and service-specific resolutions.
- bcrypt version incompatibility — Newer bcrypt rejected passwords hashed by older versions. Required re-seeding the demo user on the production database.
Accomplishments that we're proud of
- End-to-end working system — From login to triggering a real multi-agent investigation that queries live Splunk data and returns an AI-generated resolution plan. Not a mockup.
- True Splunk integration — Every agent query hits real Splunk indexes. Splunk ML runs anomaly detection and prediction natively via SPL. We're not just displaying Splunk data — we're reasoning over it.
- The Expert Twin concept — When you trigger an investigation for "redis-cluster", the system identifies that "alex_chen" has resolved 175 similar incidents, retrieves his investigation patterns from Splunk, and the LLM simulates his reasoning process. This is genuinely novel.
- Full deployment — Live at https://ops-twin-ai.vercel.app with Splunk + Backend running on AWS EC2. Judges can try it without any local setup.
- Professional UI — Enterprise-grade dark dashboard with consistent design system, animations, and proper data visualization.
What we learned
- MCP is a pattern, not just a protocol — The value of MCP isn't the binary; it's the architectural principle of agents accessing data through structured tool interfaces rather than raw API calls.
- Data quality > model quality — Our agents became dramatically more useful when we switched from random synthetic data to coherent engineer-specialization patterns. The LLM reasoning improved by simply giving it better context to work with.
- LangGraph makes multi-agent orchestration surprisingly simple — Defining a sequential pipeline of agents that pass state to each other took ~50 lines of code.
- Hackathon deployment is underrated — Having a live URL that judges can click makes a 10x difference compared to "works on my machine" demos.
What's next for OpsTwin AI
- Real-time knowledge ingestion — Connect to Slack, Jira, and PagerDuty APIs to continuously learn from live incident resolution as it happens
- Interactive Expert Twins — Chat interface where you can "ask Alex" how he'd investigate a specific symptom
- Splunk Cloud + Hosted Models — Migrate to Splunk Cloud Platform to use native hosted generative AI models (data never leaves Splunk)
- Neo4j Knowledge Graph — Store engineer-to-incident-to-service relationships in a proper graph database for explainable reasoning paths
- Feedback loop — Track whether approved plans actually resolved incidents, use that signal to improve future recommendations
- Multi-tenant SaaS — Allow multiple organizations to create their own expert twins from their own Splunk data
Built With
- amazon-web-services
- aws-ec2-(backend-+-splunk-hosting)-**cloud-services:**-aws-ec2-t3.large-(compute)
- awsec2
- expert-simulation)
- fastapi
- hosting
- investigation-history
- langgraph
- langgraph-(multi-agent-orchestration)
- llama
- mttr-estimation)
- neon
- neon-postgresql-(database)
- postgresql
- python
- react
- react-(frontend-ui)
- root-cause-prediction
- splunk
- summarization
- vercel-(frontend-hosting)

Log in or sign up for Devpost to join the conversation.