
Inspiration
LLM answer quality degrades silently. A model update, a prompt change, or a drifting RAG index can drop groundedness 20–50% with no error, no red dashboard, no alert — teams find out from customer complaints, not telemetry. Splunk already watches infrastructure at terabyte scale; LLMWatch points that same machinery at answer quality and adds an agent that acts.
What it does
LLMWatch instruments every LLM call into Splunk, then runs a closed-loop agent:
- SENSE — reads quality signal from Splunk (MCP Server on Cloud, REST on local Enterprise)
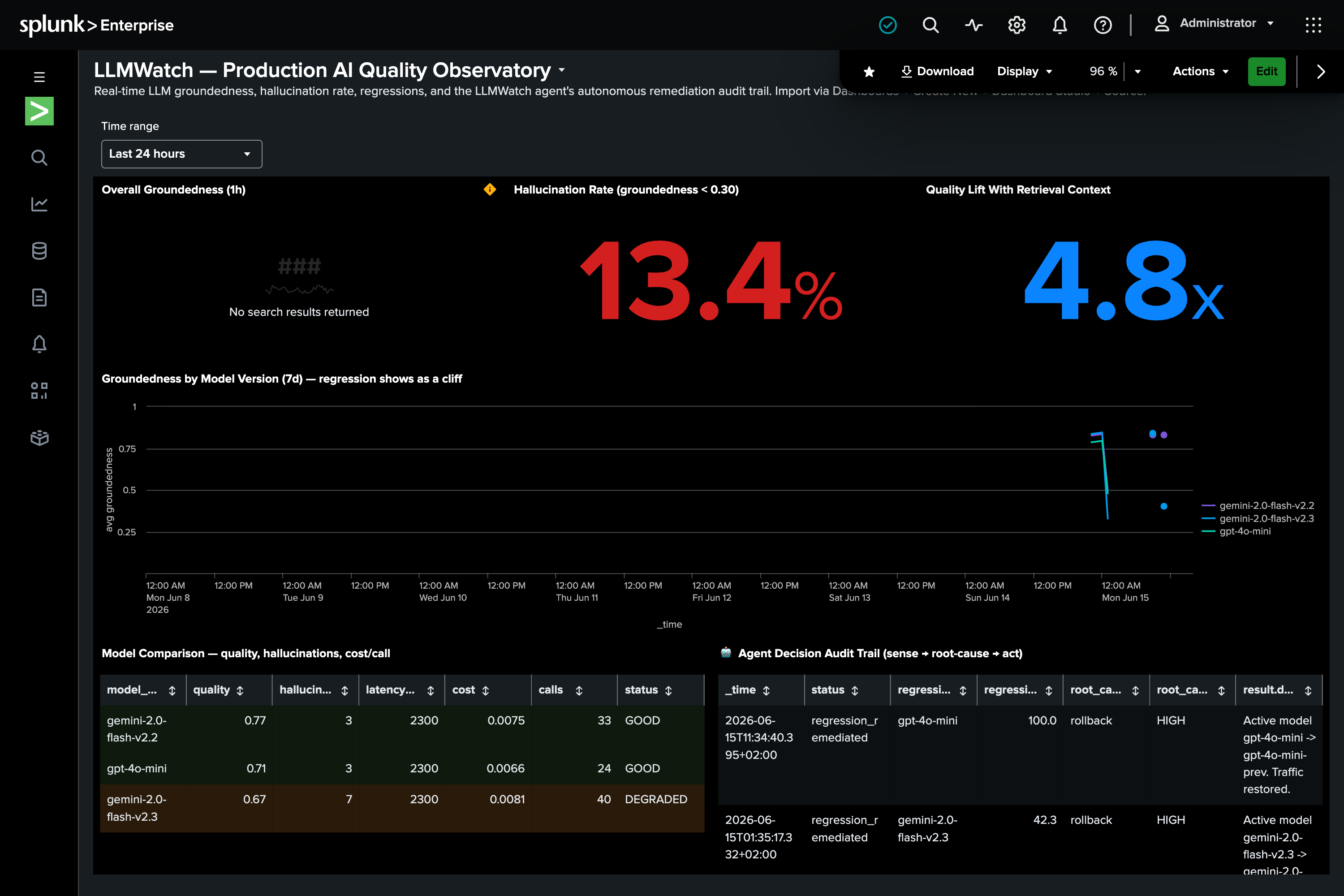
- DETECT — current hour vs 24h baseline, including silent drift
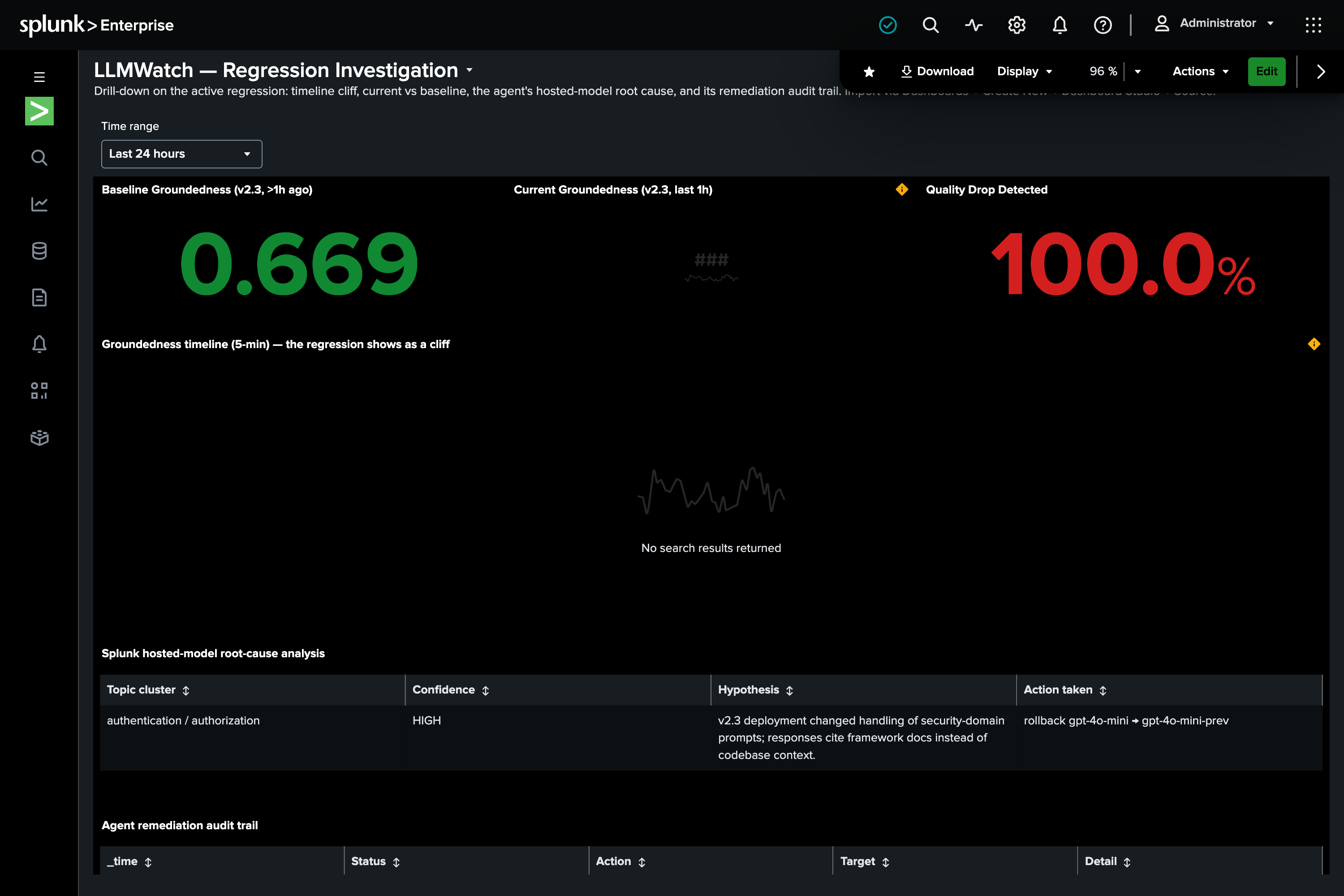
- INVESTIGATE — root-causes failing calls with a Splunk hosted model (gpt-oss)
- DECIDE & ACT — rolls back the bad model, behind a human-approval gate
- LOG — writes its decision back to Splunk as an audit trail
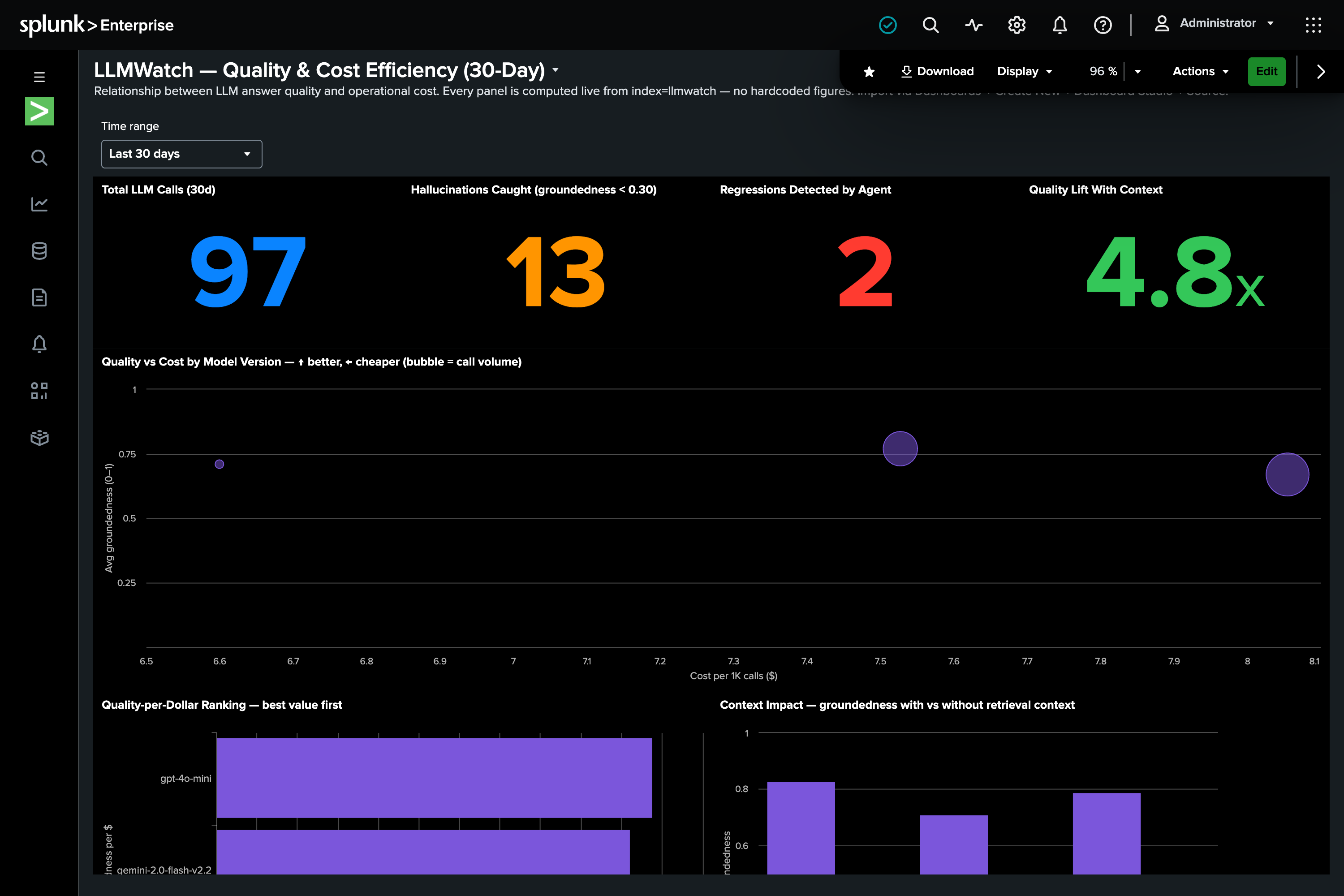
Three Dashboard Studio dashboards visualize the quality observatory, regression investigation, and cost-vs-quality.
How we built it
A Python package: collector (HEC ingestion), judge (hosted-model LLM-as-judge + root cause), mcp_client (MCP/JSON-RPC with the streamable-HTTP initialize handshake), splunk_rest (REST search), agent (the control loop), actions (rollback/reroute/incident + approval gate). Quality = groundedness scored 0–1; SPL drives all analytics; Splunk Alerts fire the agent. Verified live end-to-end on Splunk Enterprise 10.4.
Challenges we ran into
- Splunk 10.4 Dashboard Studio uses a new
tabs/layoutDefinitionsschema; the olderlayout.type/structureform plus a malformedhiddenElementsmeta caused "Layout undefined is not defined." Fixed by matching Splunk's own shipped dashboard format. - The Splunk MCP Server requires the streamable-HTTP
initializehandshake before anytools/call. - Splunk's bubble chart maps columns positionally (x, y, size, category last).
Accomplishments that we're proud of
A real, verified agentic loop on Splunk — not a mockup. On a live instance it caught a 52% groundedness drop, root-caused it to auth-domain prompts, and rolled back v2.3 → v2.2 autonomously, logging the decision back to Splunk. Responsible autonomy: human-approval gate + full audit trail. 9 unit tests; runs offline in ~5 seconds.
What we learned
Groundedness is the LLM metric nobody monitors — and it's exactly what Splunk observability + hosted models are good at. Closing the loop (act, not just alert) is what makes it agentic ops.
What's next for LLMWatch
Multi-signal scoring (latency + cost + groundedness), per-tenant baselines, a packaged Splunk app, and canary/reroute strategies beyond rollback.

Log in or sign up for Devpost to join the conversation.