-
-

kassi: an AI agent that load-tests a code change, finds the regression in live Splunk, and writes the fix. Audited end to end.
-
 GIF
GIF
A real run: kassi walks its state machine, correlates k6 load with live Splunk, names database is locked, and proposes a fix.
-
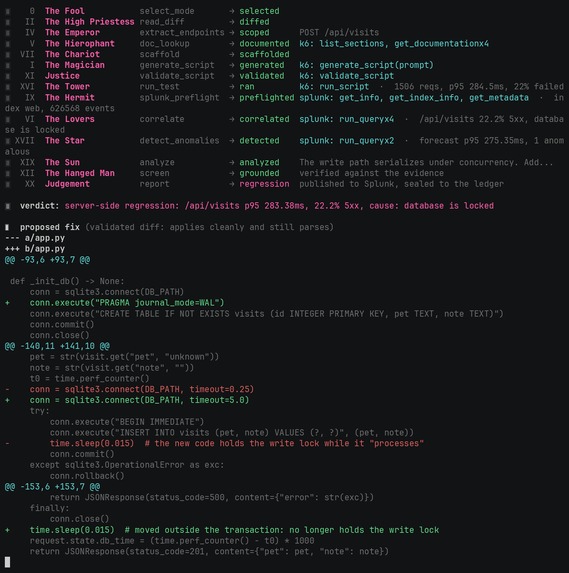
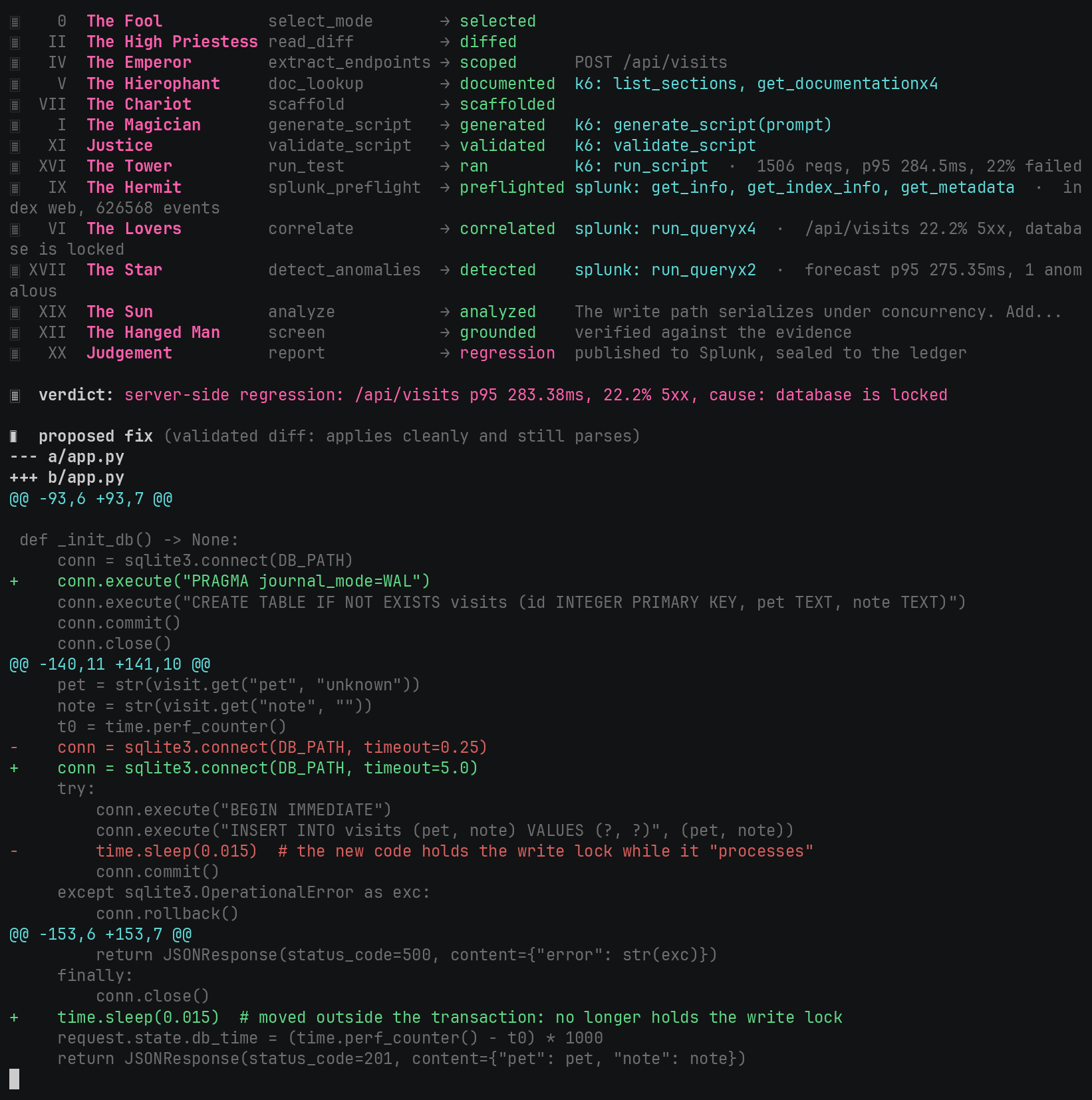
The same run, frozen: the full phase walk, the regression verdict on /api/visits, and the validated remediation diff.
-
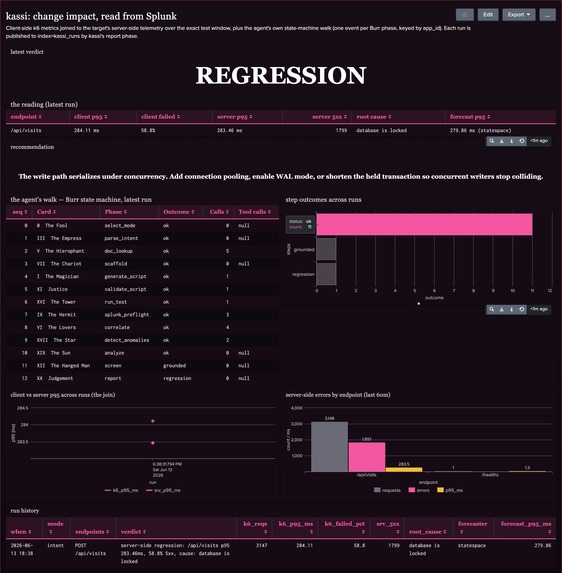
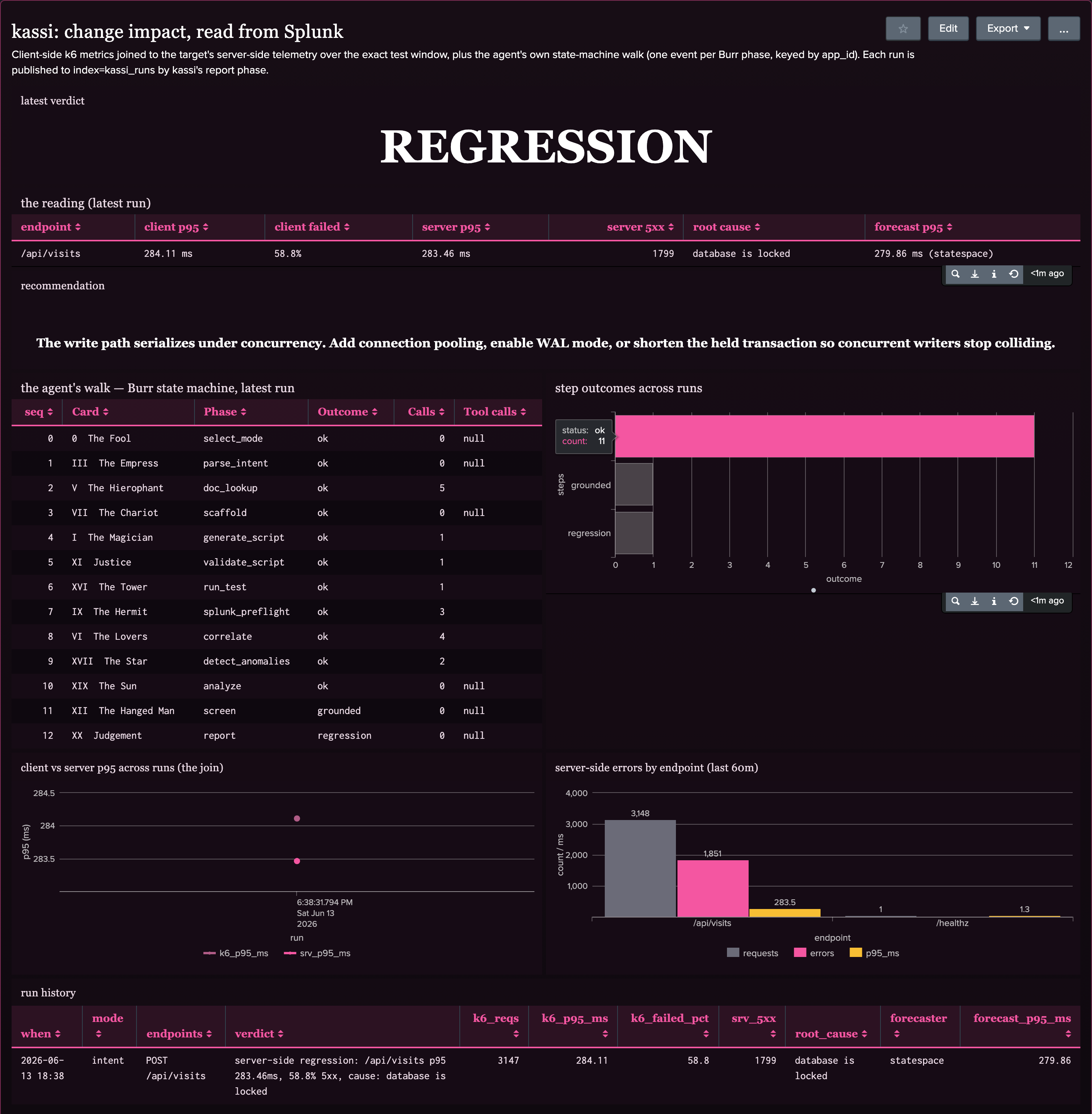
The verdict in Splunk. kassi reads telemetry from Splunk, then publishes its own run back, so it is observable in the system it observes.
-
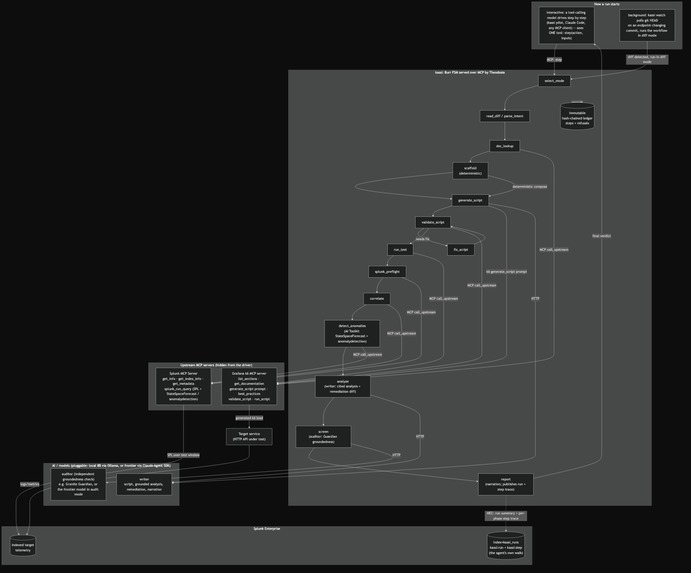
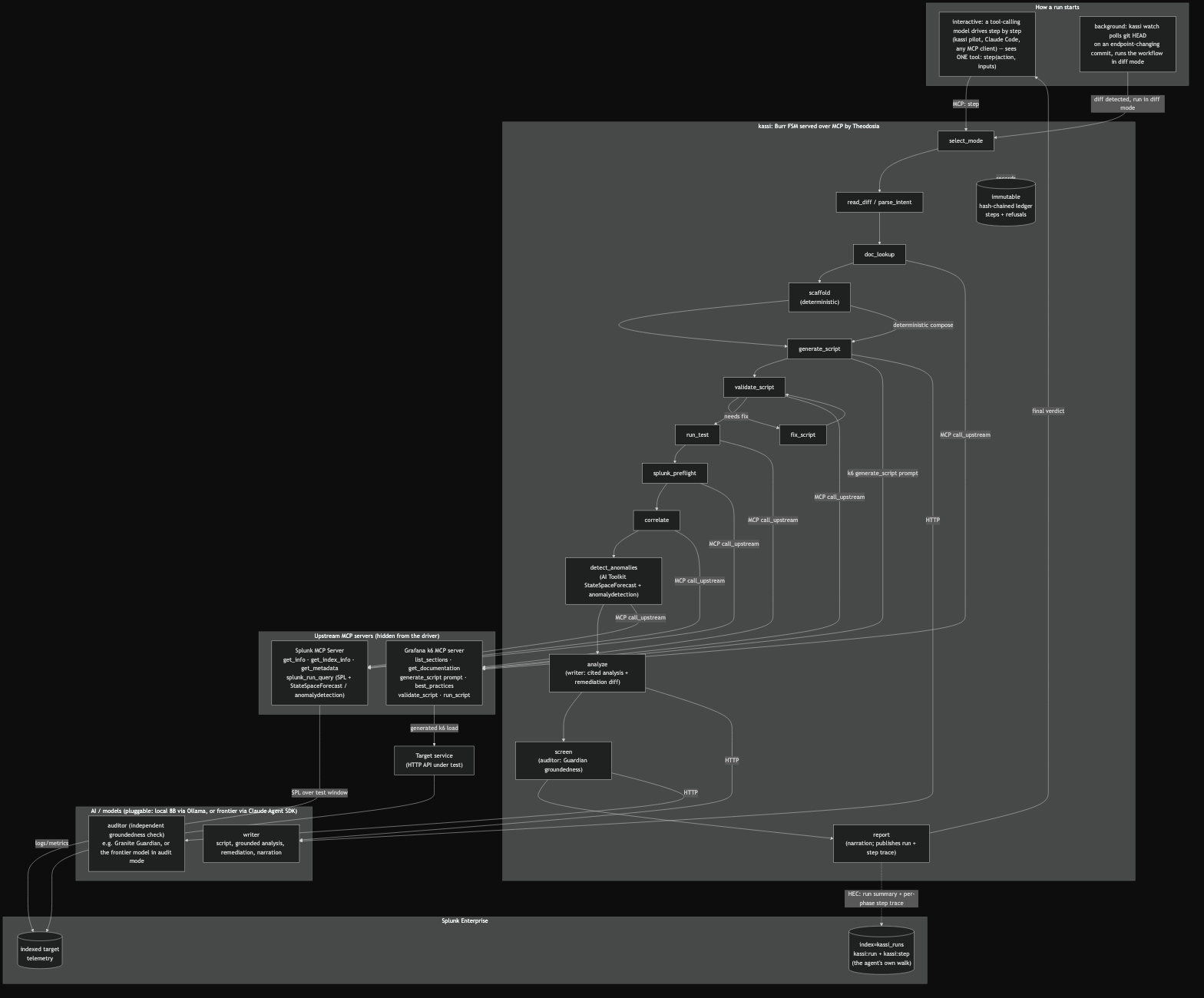
One agent, two MCP servers (Grafana k6 and the official Splunk MCP Server), a Burr state machine, a hash-chained ledger. Model-pluggable.
-
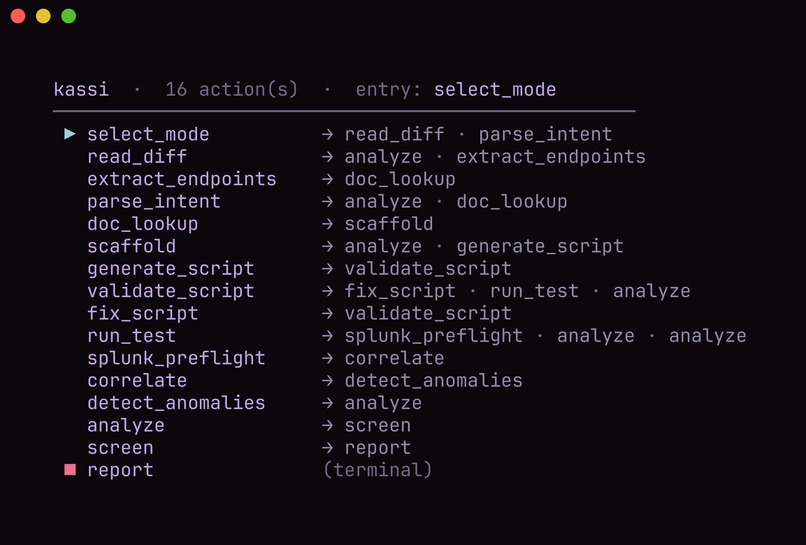
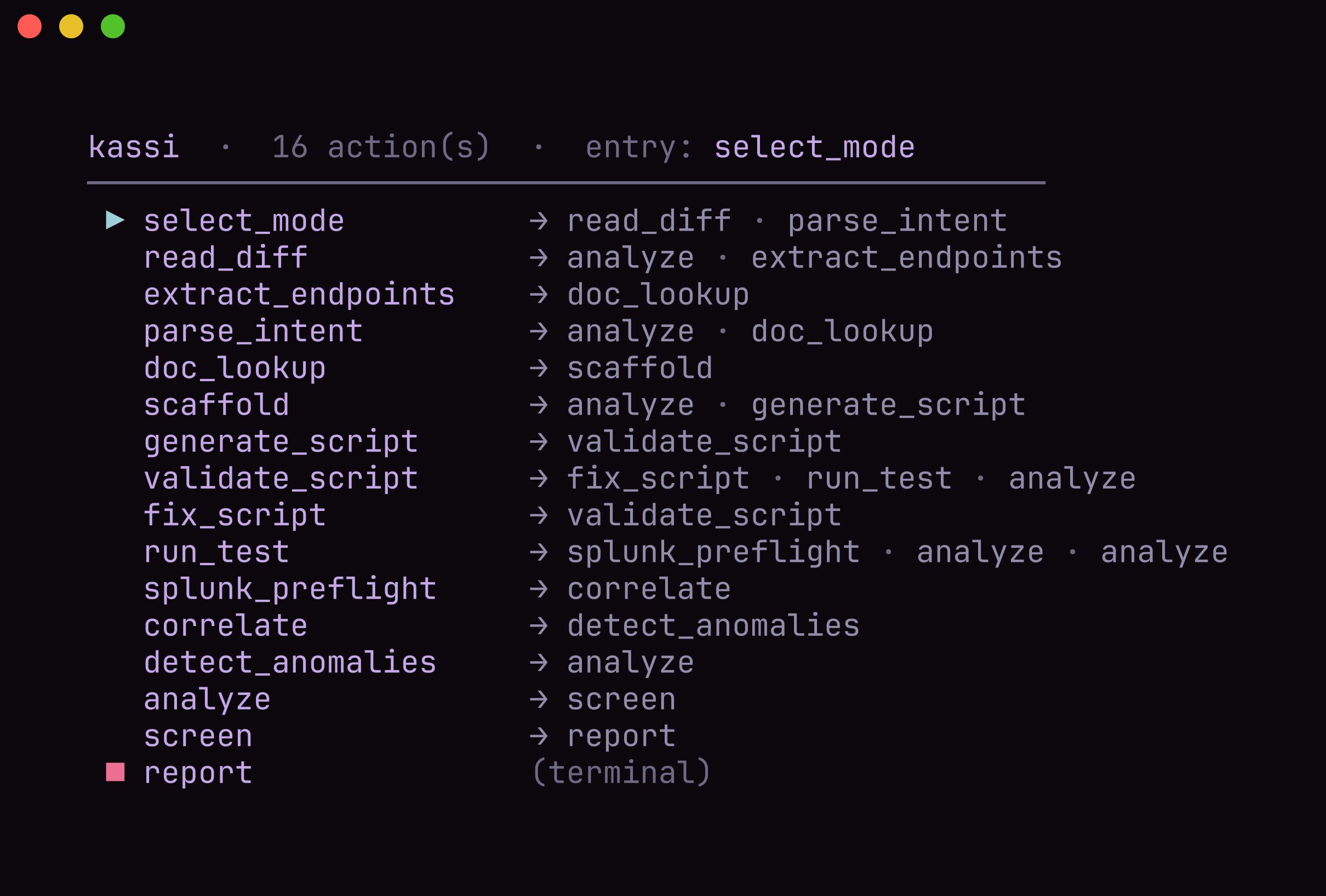
The workflow is a Burr state machine. The graph edges are the only legal moves, and the driving agent sees one tool: step.
-
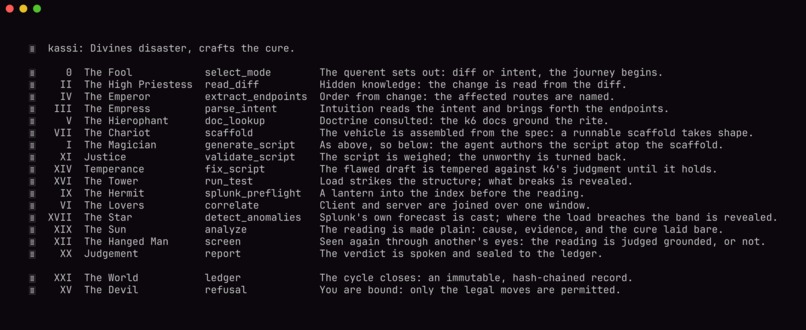
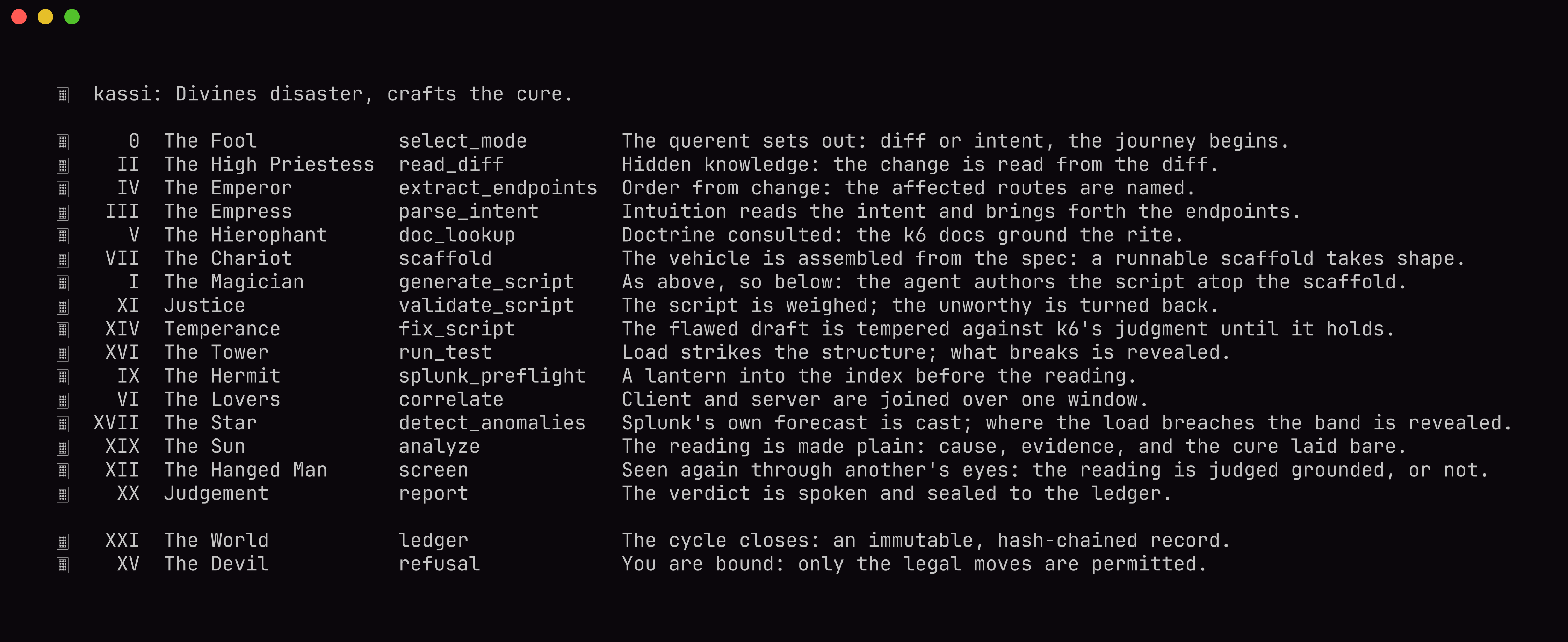
Each phase is a card of the Major Arcana, from The Fool (the run begins) to Judgement (the verdict, sealed to the ledger).
-
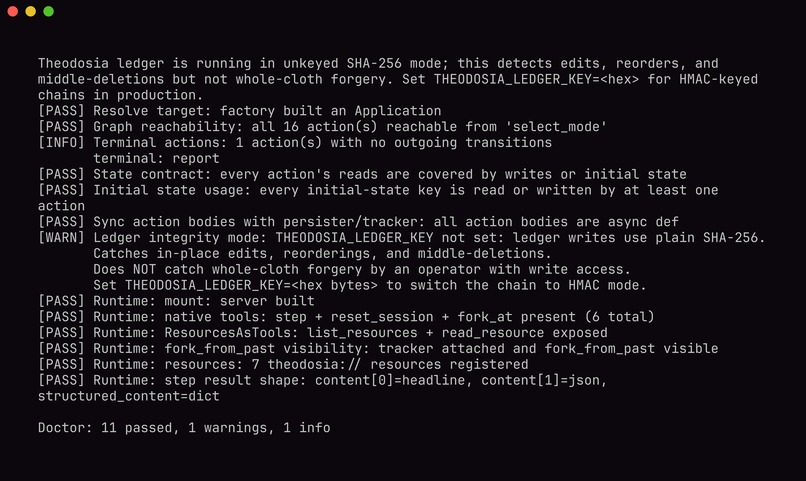
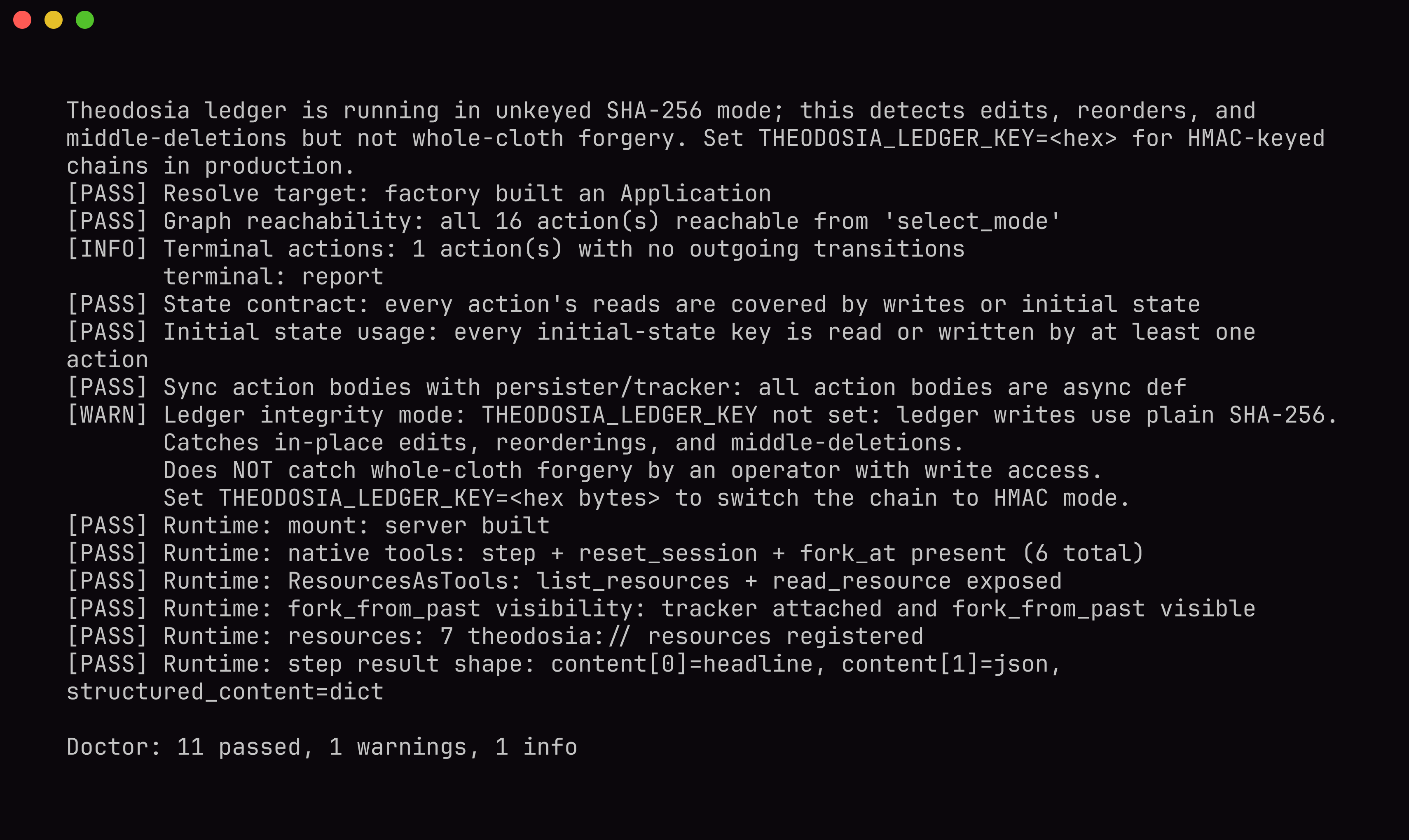
kassi doctor verifies the state machine, the audit ledger, and the runtime before anything runs. Autonomy safe to leave unattended.


kassi: the AI agent that divines the outage and writes the cure
kassi load-tests a code change, finds the regression in live Splunk, names the root cause, and writes the fix, before the change ever reaches production. A change comes in, a verdict and a validated remediation diff go out. Every step is sealed to a hash-chained audit ledger, and the agent publishes its own run back to Splunk, so it is observable in the system it observes.
Named for Kassandra, who foresaw disaster and was never believed. kassi's prophecy comes with proof, and a patch.
kassi runs on Theodosia, a framework I built for serving
a Burr state machine as an MCP server. The driver only ever
sees one tool, step. The state machine refuses any move that isn't a legal next step, and every
step and refusal is written to a hash-chained ledger that kassi verify can check. That
governance is what makes it safe to point an autonomous agent at production telemetry and let it
propose a fix.
Track: Observability · Repo: open source, Apache-2.0 · Full detail in the README.
The one-minute version
- Live Splunk AI, never simulated. Every run calls the official Splunk MCP Server and the Splunk AI Toolkit against a live Splunk Enterprise 10.4.0. That is the single biggest disqualifier in the brief, and kassi has none of it.
- Closes the loop both ways. Most tools tell you something broke. kassi runs the real experiment, explains why, and hands back a fix: a minimal unified diff that applies cleanly.
- Runs hands-free.
kassi watchguards a repo and runs the whole workflow the moment a commit changes an endpoint, so the regression is caught at commit time, not at 2am. - Governed autonomy. Built on Theodosia, the framework I wrote: the driver sees one tool,
illegal steps are refused, and every move is hash-chained so
kassi verifycan prove the trail. - Model-agnostic. The same harness runs the entire loop on a local open 8B (on-prem, air-gapped) or on a frontier model, unchanged.
- Measured, not just demoed. 0% false alarms on a live ground-truth benchmark, root cause in the top 3 100% of the time on a recognized academic RCA benchmark, and 15/15 on a third-party app.
Inspiration
Roughly 80% of production outages are self-inflicted: Gartner attributes them to people and process, not technology, and change is the single biggest cause, which is why change failure rate is one of the four DORA metrics. Every engineer has been Cassandra about a deploy: you sensed it was risky, you couldn't prove it, it shipped, and it took down prod at 2am.
The reason is structural. A change can pass every unit and integration test and still hide a flaw, a lock, an N+1 query, an unbounded loop, that only appears under concurrent load. A unit test checks that one request is correct. It cannot see what breaks when a thousand arrive at once. That impact surfaces only in server-side telemetry, and catching it means generating traffic, digging through Splunk, and correlating the two by hand, after the fact. So it almost never happens in time.
kassi is the seer that gets believed. It does that correlation autonomously, before production, and brings the receipts.
What it does
Give kassi a code change (a git diff) or a plain-language intent, and it:
- picks the affected endpoints from the diff, or by scoring an OpenAPI spec against the intent,
- generates and runs a real k6 load test through the Grafana k6 MCP server, grounded in k6's own documentation and generation prompts,
- reads the server-side truth back from Splunk over the exact test window through the
official Splunk MCP Server, then runs the
Splunk AI Toolkit's
StateSpaceForecastandanomalydetectionover that window to locate the saturation onset statistically, - writes a cited, grounded analysis (root cause, evidence, recommendation) and a remediation diff that fixes the cause,
- audits its own analysis with a second, independent model before publishing, then reports the combined client-and-server verdict and publishes its own state-machine walk back to Splunk.
A real run, nothing canned. Pointed at a diff that adds POST /api/visits, one agent
orchestrated the full walk across both MCP servers. It drove real k6 load (2937 requests, 59.4%
failed), read the server-side telemetry back from Splunk, and returned: server-side regression,
/api/visits, p95 318ms, 59.4% 5xx, cause database is locked, with the AI Toolkit forecasting
the latency band and flagging the anomalous bucket. Then it wrote the fix: move the write out of
the held lock, enable WAL, raise the busy timeout. The proposed diff is not a guess; the model
emits structured edits, kassi applies them, re-parses to confirm the file still compiles, and
only then renders the unified diff, so the fix is known to apply.
One trick, many failure modes. It ships five demo targets spanning the load-failure taxonomy, so the correlation is proven on distinct signatures: a write-lock 5xx regression, an N+1 latency creep with zero errors, an unbounded recompute the forecast catches before it hits the wall, a too-tight rate limit (429 throttling, which kassi correctly declines to page on), and a downstream timeout cascade. Four are written up as case studies. The verdict reflects the kind of failure: a 5xx reads as a regression, a zero-error latency creep reads as DEGRADING, a regression the error rate alone would miss.
How I built it
Theodosia, the framework underneath. kassi is built on Theodosia, the framework I wrote for mounting a Burr state machine as a governed MCP server. It handles the parts that make autonomy safe, so kassi doesn't reinvent them:
- One constant tool surface. However many phases the FSM has, the driving agent sees a single
step(action, inputs)tool. The action namespace lives instep's schema, so the agent's autonomy is bounded by the graph, not by a sprawling toolset. - Hidden upstreams. Theodosia spawns the Grafana k6 MCP server and the official Splunk MCP
Server as upstream MCP servers and exposes them only through one internal
call_upstream. The driver never sees them; kassi orchestrates both behind the singlestepsurface. - Governed transitions. The graph's edges are the only legal moves. An illegal step is refused with the valid next actions, so the agent cannot wander off the workflow.
- A hash-chained ledger. Every step and every refusal is written to an immutable, hash-chained
audit trail.
kassi verifyproves it was not tampered with, which is what makes the agent safe to leave running unattended on ops infrastructure.
Theodosia isn't specific to kassi; it would serve any Burr workflow the same way.
Deterministic where it counts, model where it helps. The model never writes SPL; pure Python composes the correlation queries. A deterministic scaffold always produces a runnable k6 baseline, so a run never fails for lack of a model. On top of that floor, the model authors the final load script, writes the grounded analysis, and proposes the fix. Keeping the work-phases deterministic and splitting the writer from an independent auditor model keeps the blast radius of a bad model output small.
Model-agnostic by design. The driver and the writer/auditor sit behind a model-neutral
surface (the MCP step tool and an LLM protocol with an Ollama backend and a Claude Agent SDK
backend). The whole loop runs on a single local open 8B, so an enterprise can run kassi fully
on-prem or air-gapped, no code or telemetry leaving the building and no per-token bill. It scales
up to a frontier model unchanged. The design scales with the model; it does not depend on one.
How Splunk is used at runtime (both live, neither mocked):
- The Splunk MCP Server (Splunkbase 7931) is the primary integration. The agent reads all
server-side telemetry through it:
splunk_get_info,splunk_get_index_info, andsplunk_get_metadatato preflight the index, thensplunk_run_queryfor the correlation queries and the anomaly scan, over the officialmcp-remotebridge with an encrypted token. - The Splunk AI Toolkit runs through that same tool.
StateSpaceForecastforecasts the latency band (corepredictis the automatic fallback), andanomalydetectionflags outlying buckets. Splunk's own ML locates the saturation onset, not a fixed threshold in kassi.
The agent is observable in Splunk, not just its results. After each run, kassi publishes its own execution back to Splunk over HEC: one event per state-machine phase, keyed by the run id. A dashboard renders the agent's walk next to the client-and-server join, so an operator sees not just what the change did but how the agent reached the verdict.
Challenges I ran into
- The k6 MCP runs a single script string and cannot resolve local imports, so codegen had to emit one self-contained file built from the OpenAPI schema.
- Correlation only works if the SPL window matches the test exactly. A near-instant run produces a zero-width window and zero rows, so the run records a real wall-clock span and scopes the SPL to it.
- Nothing in an autonomous agent can be allowed to hang. A model-authored k6 script can wedge the runner, so every blocking upstream call is bounded by a timeout that falls back to the deterministic scaffold, so the pipeline degrades gracefully instead of stalling.
- Wiring the official Splunk MCP Server over its streamable-HTTP transport, with an encrypted
token and a self-signed certificate, through the
mcp-remotebridge.
Accomplishments I'm proud of
- One agent orchestrating load generation and observability inside a single audited state machine.
- Client-side and server-side data correlated automatically over a precise window, driven from a code change, against the real Splunk MCP Server, not a mock.
- The loop closes both ways: kassi proposes the fix, validated to apply, not just the diagnosis.
- The forecast runs on Splunk's own ML, and every run publishes its verdict and its own walk back into Splunk where the ops team already works.
- An independent auditor model screens the analysis for groundedness before the verdict is sealed, so the writer is checked, not trusted on its word.
- The whole thing, driver included, can run on a single local open 8B, no cloud brain.
Validation
I did not want to claim kassi "correlates problems" on the strength of a demo, so I measured it.
- kassi-bench (live k6 to Splunk, my apps): 80 runs across five fault classes plus healthy controls. The verdict is computed deterministically from the Splunk correlation, so a run cannot pass on a hallucinated analysis. Across the fault runs: detection 90%, localization 92%, classification 90%, root cause 95% (on the error-bearing classes). Across the controls: 0% false alarms.
- RCAEval RE3 (a recognized academic RCA benchmark, WWW'25): on 57 Online Boutique and Train Ticket cases, kassi localizes the root-cause service at top-1 in 81% of cases and within top-3 in 100%, competitive with the strongest published methods and well ahead of the classical baselines.
- go-httpbin (a third-party app kassi never instrumented, observed through a generic access-log proxy): 15/15. It called the erroring endpoint a regression, the slow one a degradation, and stayed silent on the healthy control.
The benchmark earned those numbers by failing first: it surfaced three real verdict bugs, each now fixed and locked by a regression test. Harnesses and raw results are in the repo, each reproducible with one command. Detail in docs/benchmark/BENCHMARK.md.
What I learned
- Constraining the agent makes it more useful, not less. One
steptool with refusals is easier to drive and far easier to trust than a broad toolset. - The valuable signal is in the join. Neither the k6 numbers nor the Splunk rollup is new, but pairing them over the exact window turns "it got slower" into "5xx errors caused it."
- A deterministic scaffold is what lets the model safely do more.
What's next
- A Splunk-hosted model for the root-cause narrative, and the AI Assistant for SPL for intent-driven correlation queries.
- Richer synthetic load: schema-aware request synthesis, realistic traffic mixes, seeded faults.
- Extend the RCAEval run past RE3 and grow kassi-bench past five fault classes.
Built With
- burr
- k6
- splunk
- theodosia

Log in or sign up for Devpost to join the conversation.