-
-

Jemmie, Talk to the future. Not a text box.
-
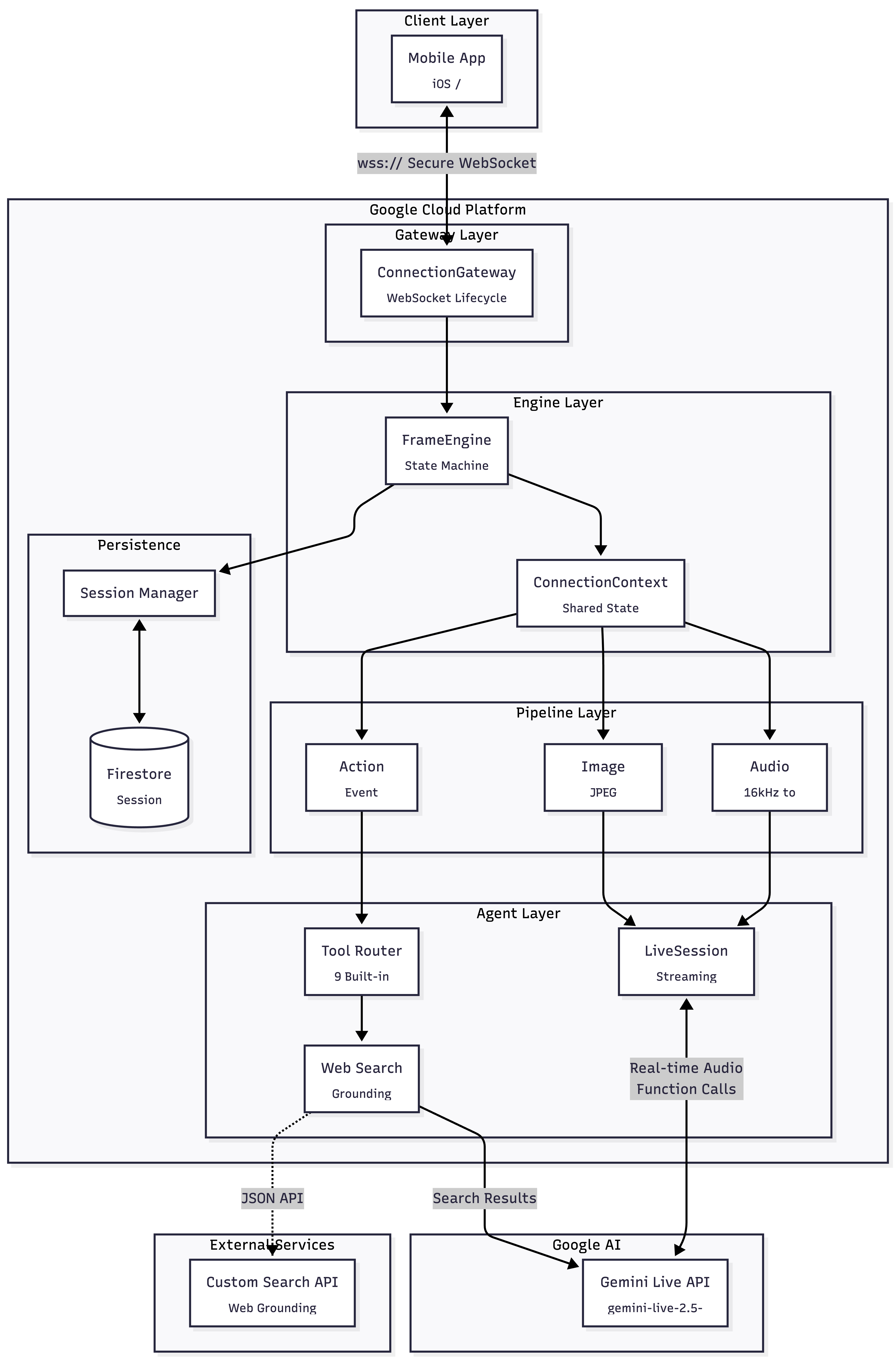
Backend Architecture

AI shouldn't feel like a chatbot, it should feel like a friend. Jemmie is a warm, brilliant AI companion just a phone call away. Speak naturally, share your day, and never type prompts again.
About Jemmie
💡 What Inspired Us
Current AI companions feel like exactly that—machines. They live inside text boxes, require clunky “push-to-talk” buttons, and enforce rigid, robotic turn-taking. We realized that typing limits human expression and emotion. We wanted to build something for the post-text era of AI: an always-on, deeply empathetic companion that feels exactly like taking a phone call from a close friend. The goal with Jemmie was to break the fourth wall and make interacting with AI natively fluid, allowing you to speak naturally, interrupt, and share your environment effortlessly.
🛠️ How We Built It
We built Jemmie using a true voice-first, native architecture to minimize latency and maximize immersion.
- Frontend (iOS): We built a native Swift application leveraging
SwiftUIfor fluid animations. We deeply integrated Apple's CallKit so that talking to Jemmie looks and acts exactly like receiving a standard VoIP call from the lock screen. - Backend: We created a Python-based asynchronous gateway using
FastAPI, bridged by bi-directional WebSockets. - The Brains: At the core of Jemmie is the Gemini Live API (
StreamingMode.BIDI). We stream raw PCM audio buffers directly from the iOS microphone to Gemini in real-time, receiving voice and transcript streams back. We also integrated Multimodal Vision, allowing users to share their camera feed so Jemmie can see and intelligently react to their physical environment.
⚠️ Challenges We Faced
Building real-time bi-directional voice applications is incredibly difficult, and we ran into two major engineering hurdles:
- The Acoustic Echo Loop: Initially, when Jemmie spoke out of the iPhone’s speaker, the microphone would pick up her own voice, causing the AI to accidentally interrupt itself. We solved this by diving deep into
AVFoundation, enforcingAVAudioSession.Mode.voiceChat, and unlocking Apple's strict hardware-level Acoustic Echo Cancellation (AEC). - Trigger-Happy Interruptions: Humans pause to take breaths when they speak. Early on, Gemini’s Voice Activity Detection (VAD) was too eager and would cut the user off mid-sentence. We overcame this by modifying the
RealtimeInputConfigon the backend, increasing thesilence_duration_msthreshold to 1200ms and lowering sensitivity, allowing for completely natural, relaxed conversation flows.
📚 What We Learned
This project was a masterclass in real-time audio engineering and human-computer interaction. We learned how to manipulate raw audio buffers in Swift, how to properly interface with the iOS audio hardware layer, and how to maintain persistent async WebSocket bridges. More significantly, we learned how radically prompt engineering changes when you are designing for voice instead of text. By curating a warm, exceptionally empathetic persona with polyglot capabilities, we discovered how subtle changes in an LLM's system prompt drastically shape the tone, cadence, and comfort of a spoken conversation.
Built With
- avfoundation
- callkit
- cloud-firestore
- docker
- fastapi
- github
- google-cloud-run
- google-gemini-multimodal-live-api
- google-genai-sdk
- python
- swift
- swiftui
- websockets

Log in or sign up for Devpost to join the conversation.