GOVWORLD
Inspiration
Every infrastructure decision a government makes starts somewhere as a row in a spreadsheet: a road gets widened, a budget gets approved, a contract gets signed. But the people who actually live and work on that street can become an afterthought.
We kept asking one question:
What if decision-makers could see how a policy affects real people before a single brick is laid?
That became GOVWORLD: a human-first infrastructure simulator.
Instead of treating roads, budgets, and contracts as the final output, we treat them as inputs and simulate their effects on people’s daily lives.
What it does
GOVWORLD is a SimCity-style policy simulator that lets users place an infrastructure proposal into a living city of AI citizens, observe its consequences over time, hear competing expert perspectives, and identify accountability risks before public money moves.
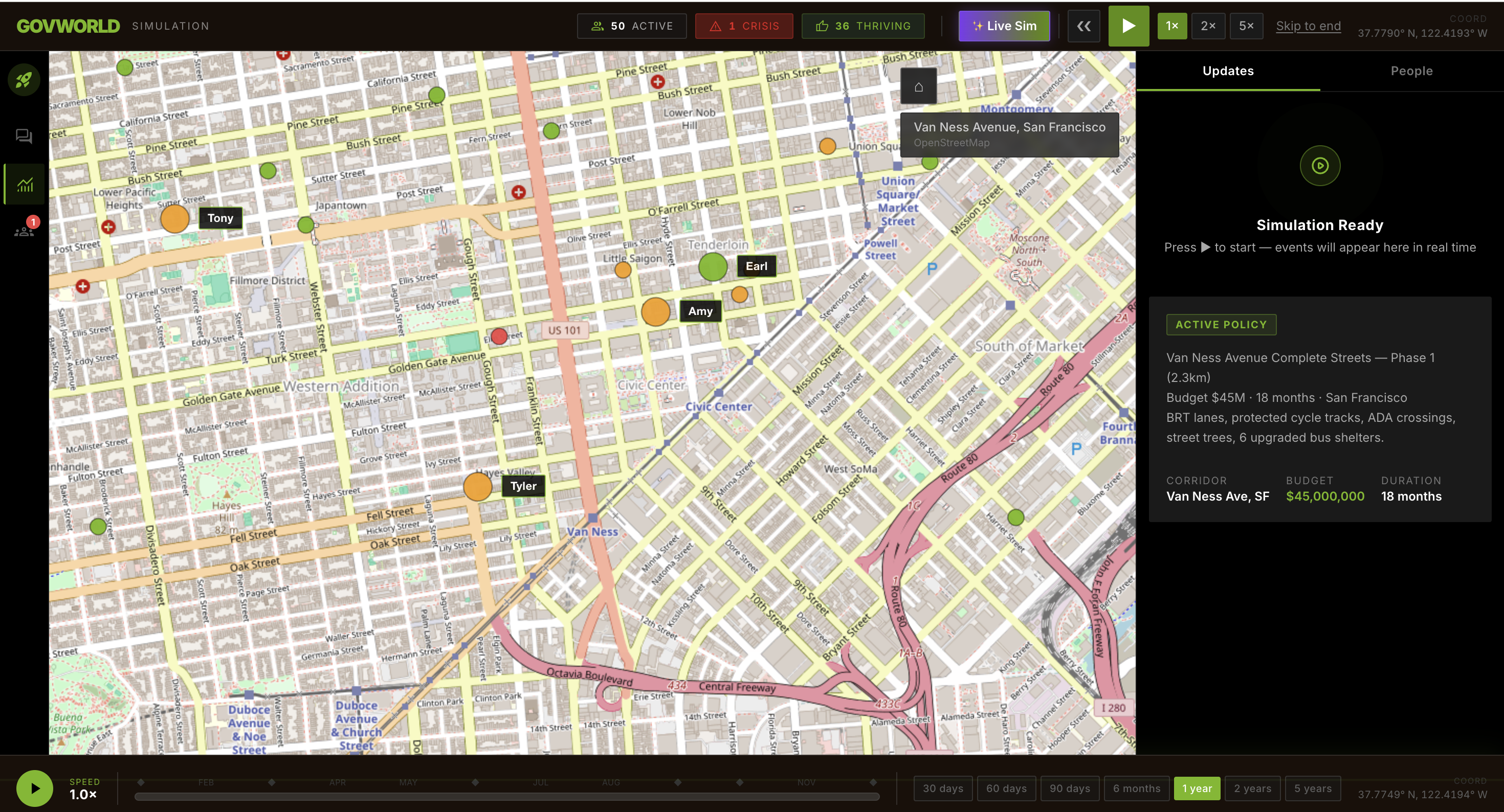
Our demo models San Francisco’s Van Ness Avenue Complete Streets project, a roughly $45M and 18-month infrastructure effort.
A living population
The city contains around 50 AI citizens. Each has a name, job, family situation, income, concerns, aspirations, and a daily route through the neighborhood.
Users can click on citizens such as:
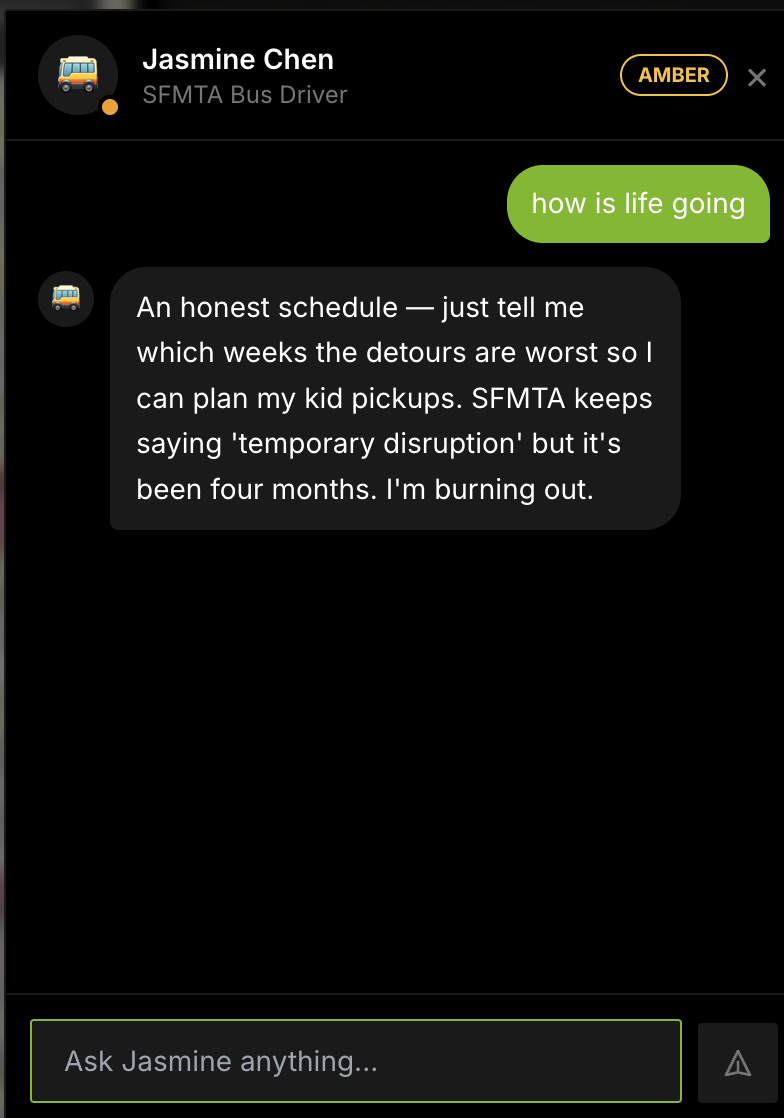
- Jasmine, an SFMTA bus driver
- Tony, a restaurant owner
- Earl, a retired resident with diabetes and no car
They can then speak with these citizens by voice to understand how construction affects their lives.
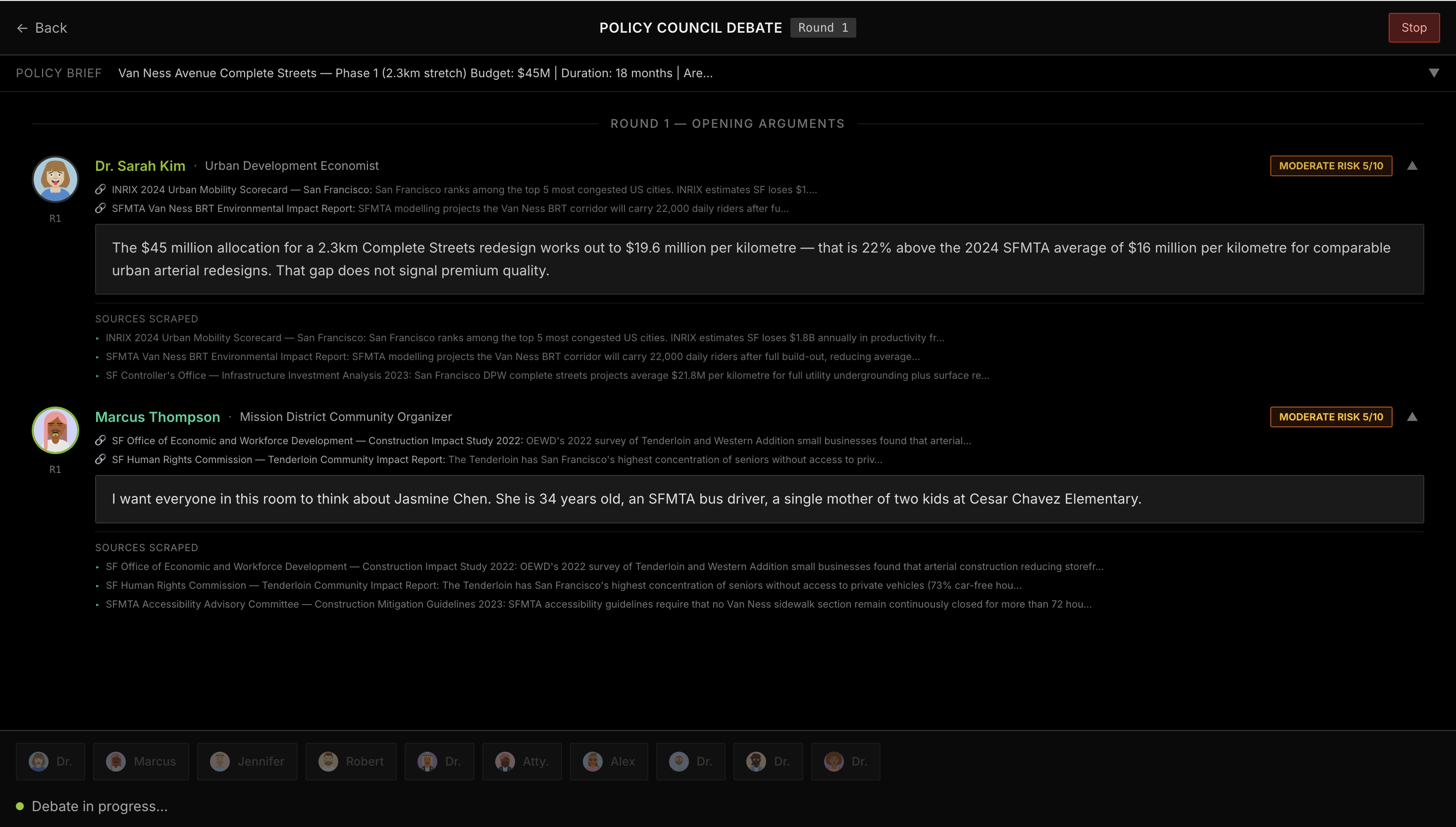
An adversarial policy council
A council of ten AI expert personas, including an economist, transit engineer, climate analyst, community advocate, lawyer, and corruption watchdog, debates the proposed policy.
Each expert researches relevant live information, forms a distinct perspective, and argues through synthesized speech.
The goal is not to create fake agreement. The goal is to surface tradeoffs decision-makers may otherwise miss.
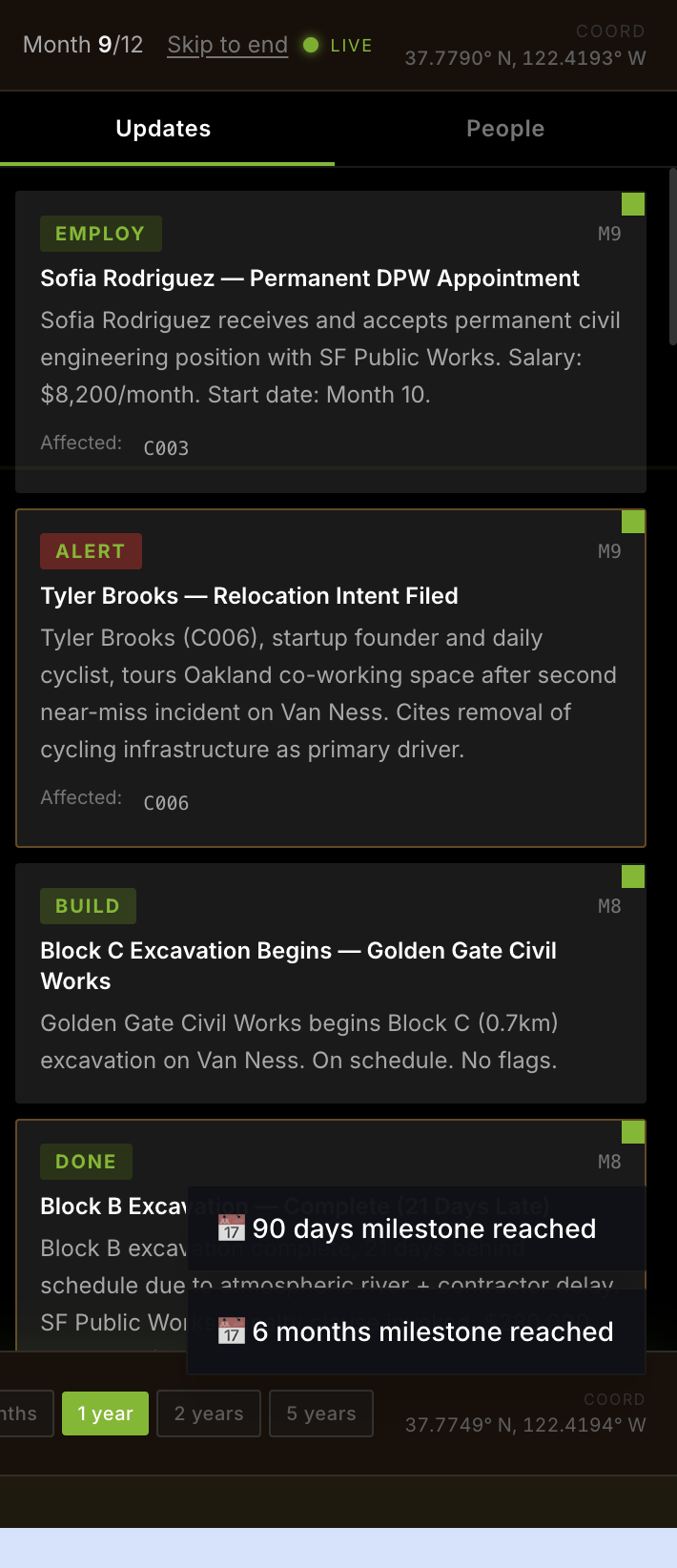
A 12-month city simulation
A generative-agent director advances the city through a 12-month timeline. It introduces realistic disruptions such as:
- Utility conflicts
- Weather delays
- Contractor fraud
- Permit challenges
- Legal injunctions
As events unfold, citizens’ wellbeing changes from green to amber to red, showing how one infrastructure decision can ripple through jobs, mobility, health access, local business revenue, and trust in government.
An accountability ledger
GOVWORLD tracks contractors, budget lines, project milestones, delays, and cost overruns. It flags potential risks before they become invisible problems buried in project documentation.
How we built it
GOVWORLD is a browser-first application built with:
- React 18, Vite, and TypeScript for the application
- Zustand for state management
- Leaflet and OpenStreetMap for the interactive city map
- react-three-fiber for the 3D debate arena
- A centralized
llm.tsrouting layer so models can be swapped by task
We used different AI providers based on what each task required:
| Task | Technology |
|---|---|
| Citizen profiles, reactions, and council arguments | Gemini 2.5 Flash |
| Real-time voice chat and debate rebuttals | Groq / Llama 3.3 70B |
| Expert debate speech | Deepgram Aura-2 |
| Live expert web research | Browserbase |
| LLM-as-judge evaluations | Anthropic Claude |
| LLM observability | Arize Phoenix |
Our simulation engine is inspired by Stanford’s Generative Agents research. Citizens retain memory streams, and the director retrieves relevant memories using a weighted combination of recency, importance, and relevance.
score(memory) =
recency_weight × recency(memory)
+ importance_weight × importance(memory)
+ relevance_weight × relevance(memory)
This lets past events meaningfully shape future citizen reactions instead of making each simulation step feel disconnected.
We also built the project with Claude Code as our pair-programmer.
How we used Arize Phoenix
We traced every council argument in Arize Phoenix and evaluated responses with a Claude-based judge on two criteria:
- Whether the expert cited named sources
- Whether the argument was coherent, specific, and evidence-based
The evaluation exposed a real failure mode. Without an explicit instruction, our experts cited named sources 0% of the time and relied on vague claims.
We added a requirement that each expert cite at least two named sources, then re-ran the evaluation.
Citation rate: 0% → 100%
That loop of tracing, evaluating, fixing, and re-evaluating made the system measurably more accountable instead of relying on whether the outputs merely “felt good.”
Challenges we ran into
Connecting browser-side AI calls with Python evaluation tooling
Arize Phoenix evaluations are Python-based, while our application runs in the browser.
We handled this through browser-side OpenTelemetry instrumentation and a CORS-enabled tracing workflow, without exposing API keys to users.
Provider reliability
During development, Groq was blocked on our network and Gemini’s free tier rate-limited heavily.
We made our model routing provider-agnostic and moved the evaluation judge to Claude so our evaluation loop could continue.
Making each simulation rerun genuinely different
Our first rerolls changed the edge-case panel but did not meaningfully affect the main story.
We expanded the event pool from 10 to 28 scenarios, sampled 5 to 7 seeded events per run, and injected them directly into the simulation timeline.
Now each run produces a different but coherent city story.
Demo reliability
Hackathon judges should not have to watch loading spinners.
We precomputed and cached all AI outputs for the primary demo scenario, allowing the full experience to run with zero live API calls if the network fails.
What we learned
- Building generative agents is not just about creating personalities. It is about modeling memory, reflection, cascading consequences, and compounding failures.
- LLM observability turns “this response feels weak” into an issue that can be measured, fixed, and re-tested.
- Multi-provider AI routing improves resilience, but every external dependency needs a fallback plan.
- The hardest part of simulating a city is not rendering the map. It is making every citizen feel like a person whose life deserves consideration.
What’s next
- Scale from approximately 50 citizens to 1,000 through our prototype social-opinion swarm pipeline.
- Allow governments, researchers, and communities to upload a real proposed policy for any neighborhood.
- Connect the Arize evaluation loop to CI so every prompt change is automatically tested for evidence quality, safety, and reasoning.
- Expand the accountability ledger into a more robust early-warning system for delays, overruns, and procurement risks.
Our north star
Human-first, not infrastructure-first.
The road is the input. The human life is the output.
Built With
- anthropic
- arize-phoenix
- browserbase
- claude
- claude-code
- deepgram
- express.js
- google-gemini
- groq
- leaflet.js
- llama
- node.js
- open-meteo
- openstreetmap
- opentelemetry
- python
- react
- react-three-fiber
- tailwind-css
- three.js
- typescript
- vite
- web-speech-api
- zustand


Log in or sign up for Devpost to join the conversation.