-
-
Benign Output - False Positives
-
Banner
-
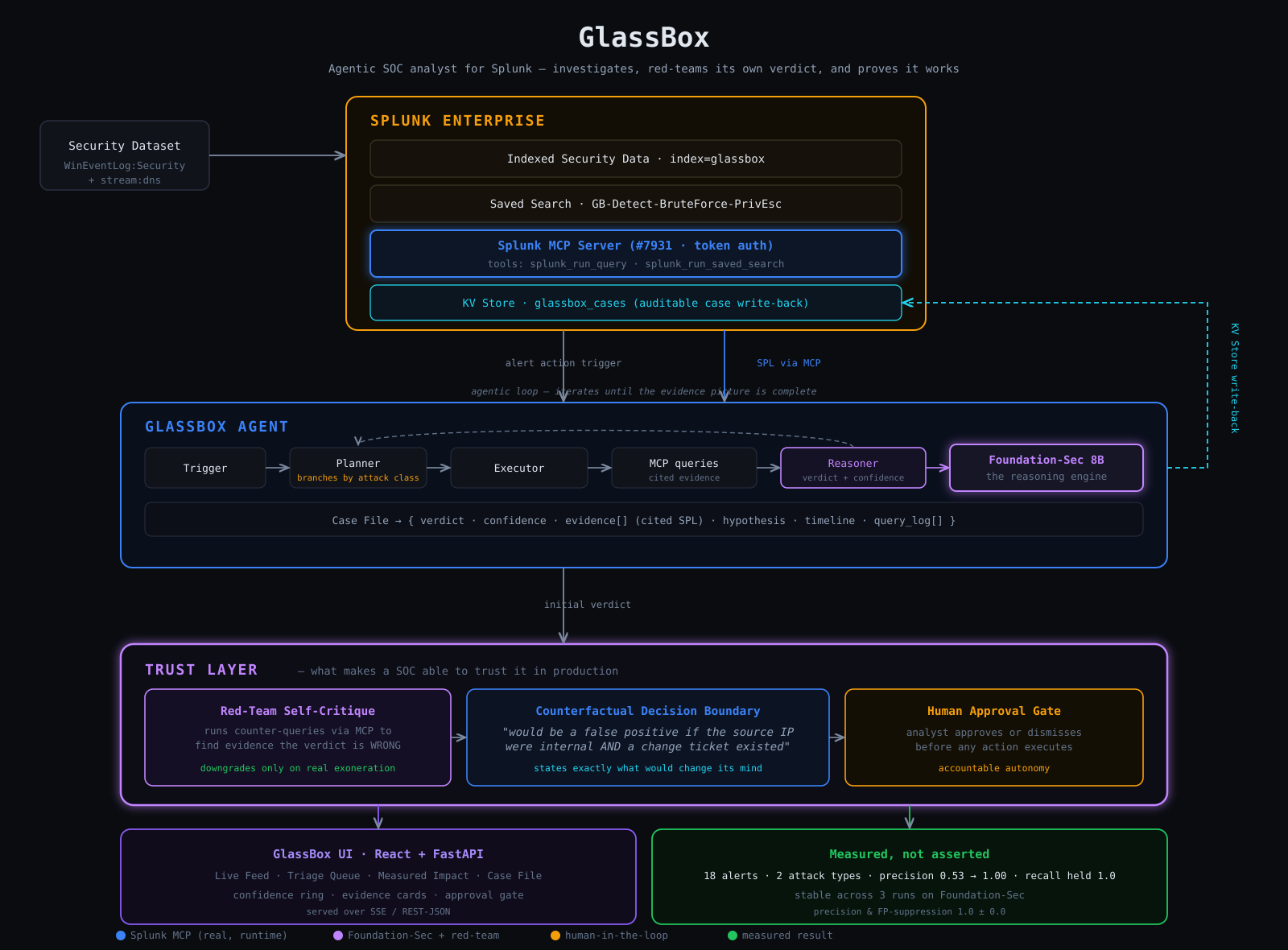
Architecture Diagram
-
UI Case File
-
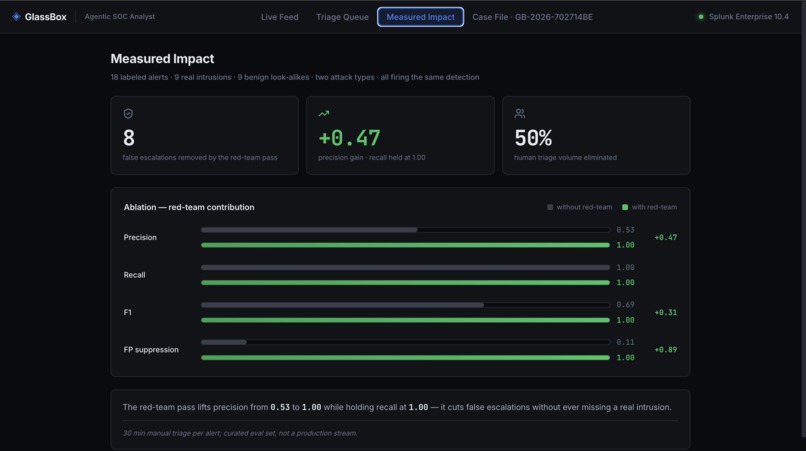
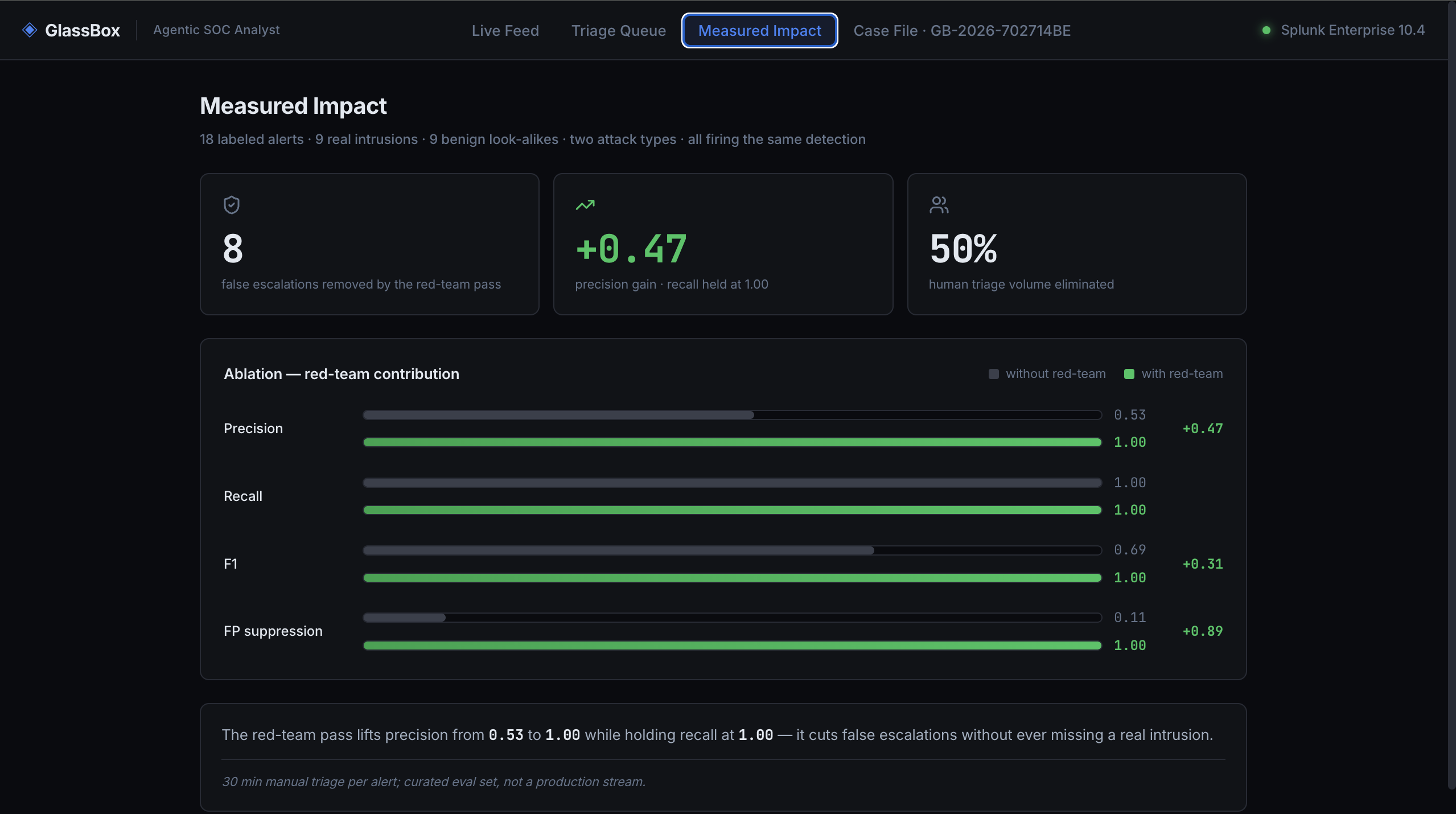
UI Measured Impact Scorecard
Inspiration
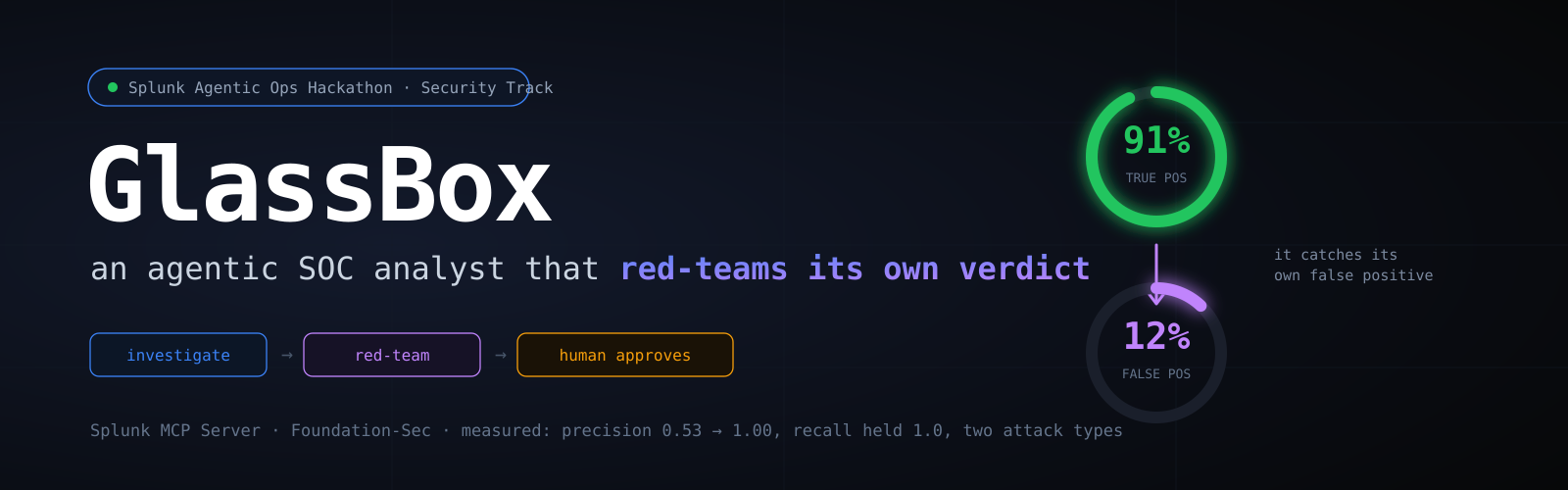
SOC analysts drown in false-positive alerts. AI agents could triage them — but no security team hands triage to a black box, because when an agent recommends disabling an account, someone has to defend that decision to an auditor. We kept coming back to one realization: the blocker to automating security triage isn't capability, it's trust. So we set out to build an agent designed not for maximum autonomy, but for maximum accountability — one whose every decision a security team could verify, challenge, and stand behind.
What it does
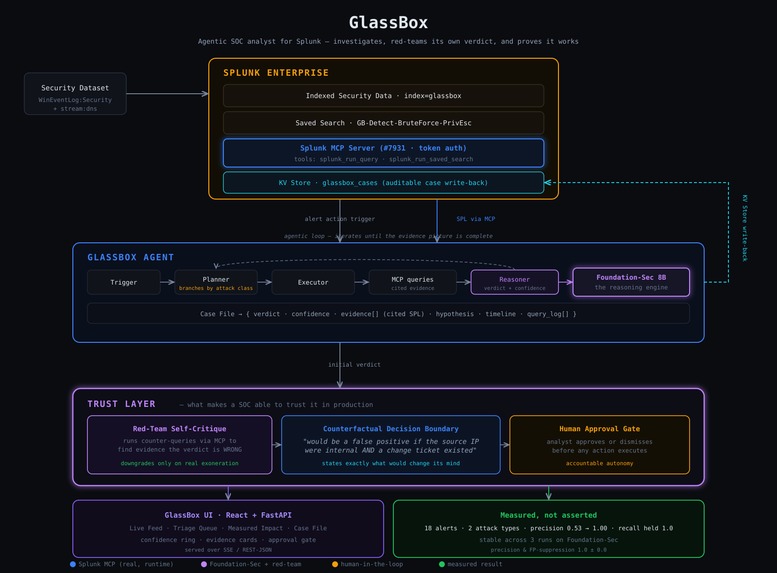
When a Splunk alert fires, GlassBox autonomously investigates it:
- Plans an investigation — Foundation-Sec (Splunk's hosted security model) chooses each next SPL query from the evidence so far, branching by attack class (auth queries for intrusions, network/DNS queries for exfiltration).
- Runs every query through the Splunk MCP Server — token-authenticated MCP tool calls against live Splunk are the agent's entire data path. Each evidence item carries the exact SPL and row count that produced it.
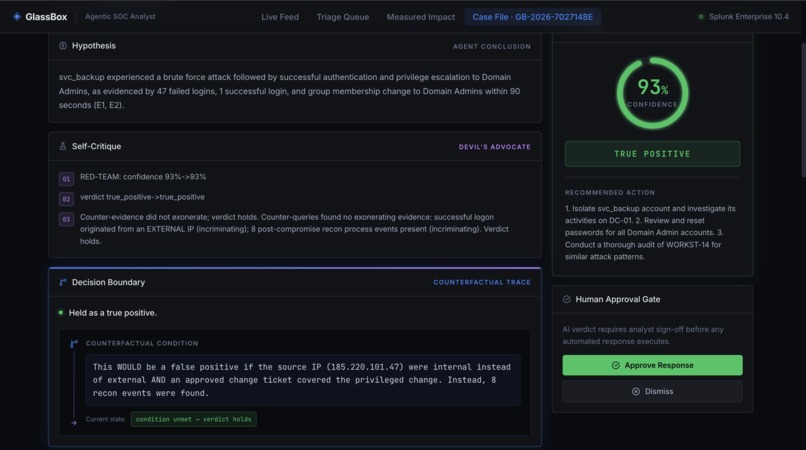
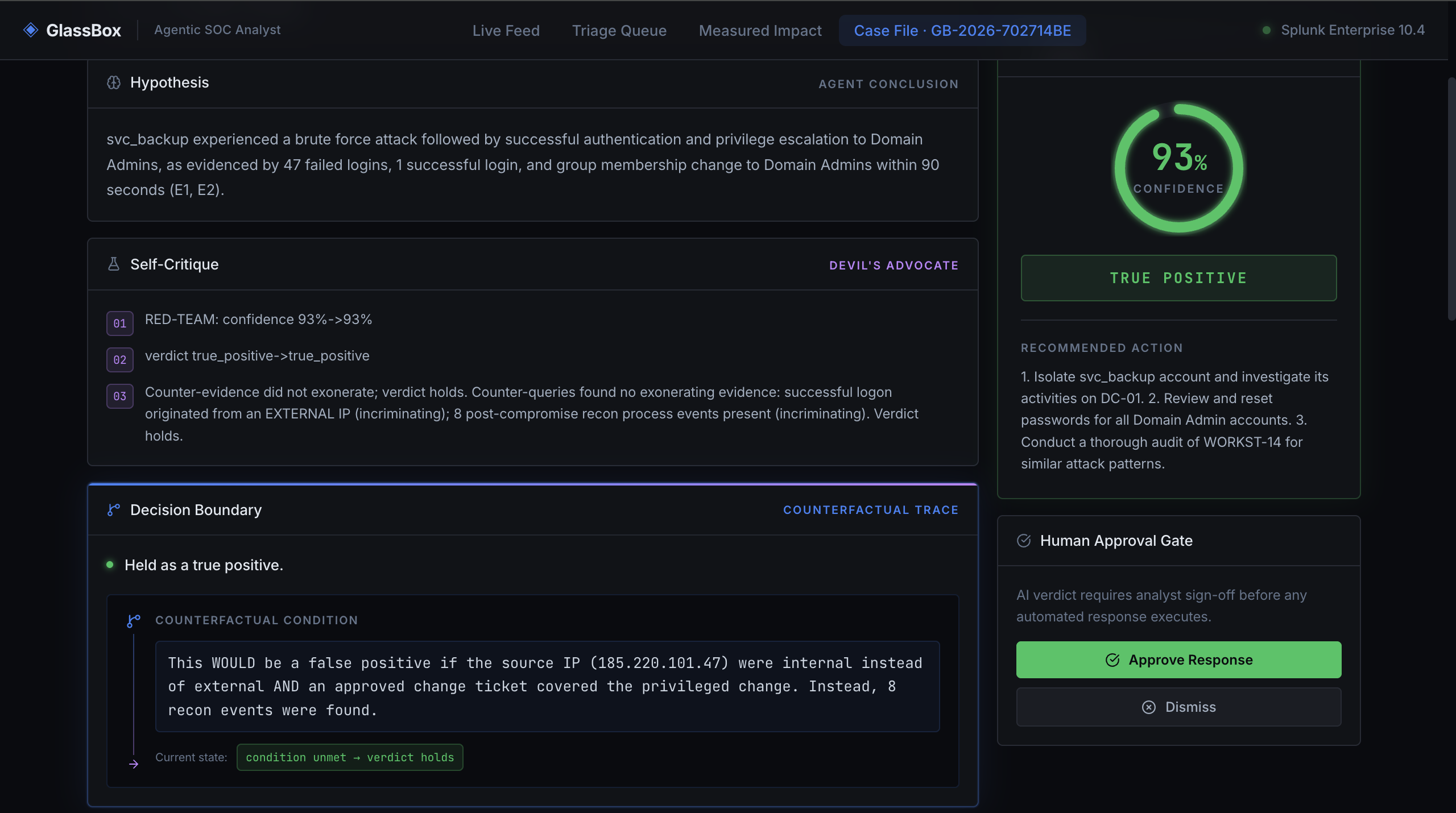
- Reasons with Foundation-Sec — a verdict, a calibrated confidence, and a hypothesis where every claim cites a specific evidence ID.
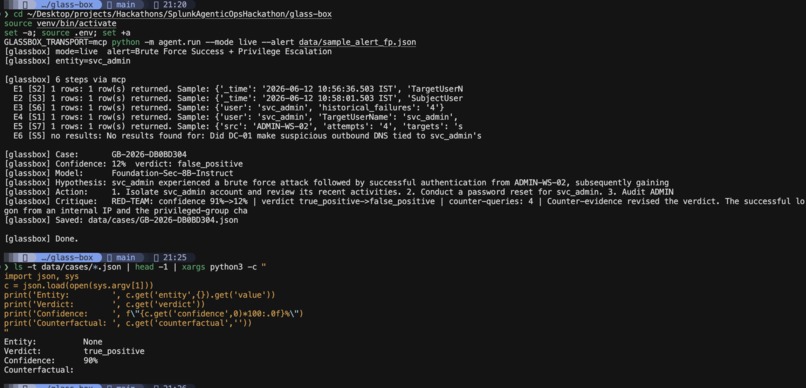
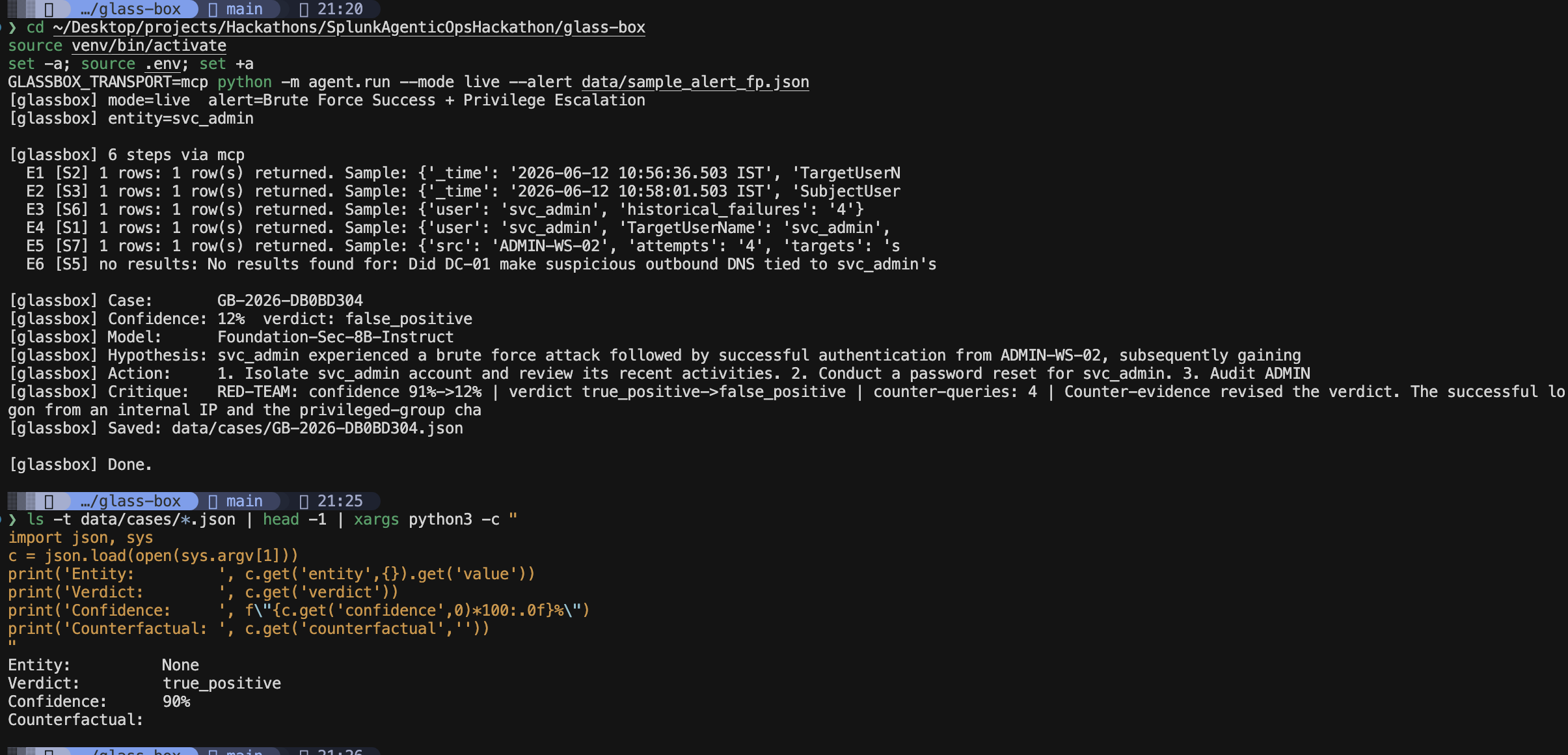
- Red-teams its own verdict — the core idea. After reaching a conclusion, GlassBox runs counter-queries through MCP that look for evidence it's wrong (an internal source IP, an approved change ticket, an allowlisted destination, a non-tunneling DNS pattern). A deterministic gate downgrades the verdict only when it finds real exonerating evidence — so genuine intrusions stay escalated while benign look-alikes get dismissed. It never silently waves away a real attack.
- Explains its decision boundary — for every verdict it emits a counterfactual: one sentence stating exactly what evidence would have flipped its decision ("this would be a false positive if the source IP were internal and an approved change ticket existed").
- Writes an auditable case file back to Splunk's KV Store, and a human approves or dismisses before any action executes.
How we built it
A Python agent (planner / executor / reasoner / red-team) reasoning with Foundation-Sec-8B-Instruct via Ollama. All Splunk access — investigation queries and adversarial counter-queries alike — goes through the Splunk MCP Server (#7931) over token auth, with a REST fallback. A Splunk app bundles the alert-action trigger, the saved search, and the glassbox_cases KV Store collection. The UI is React + a FastAPI backend that streams the live investigation over SSE. The benchmark harness measures precision/recall with a with/without-red-team ablation and a multi-run variance check.
MCP isn't a feature here — it's the agent's entire nervous system. The agent's ability to challenge its own verdict depends on it: the red-team counter-queries run through the same MCP path as the original investigation. A recorded MCP round-trip is committed at eval/results/mcp_proof.txt.
Challenges we ran into
The hard part wasn't getting an agent to produce a verdict — it was getting one a security team could trust. A confidently wrong agent is worse than no agent. Making the agent overturn itself only on real evidence (not just because a model felt unsure) took a deterministic code-level exoneration gate sitting between the model and the verdict. And proving it works meant building a benchmark with benign look-alikes that fire the same detection as real attacks — then measuring the result rather than asserting it.
Accomplishments that we're proud of
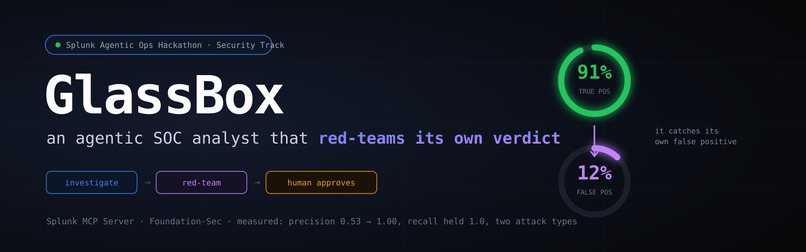
On a labeled benchmark of 18 alerts across two structurally different attack types, the red-team pass lifts precision from 0.53 to 1.00 while holding recall at 1.00 — removing every false escalation without missing a single real attack. Across 3 runs on Foundation-Sec, precision and false-positive suppression are a perfect 1.0 with zero variance. And the counterfactual decision-boundary trace — the agent stating exactly what would change its mind — is something we haven't seen any other agent do.
What we learned
That "trustworthy" is an engineering property, not a vibe. Calibrated confidence, evidence citations, a deterministic exoneration gate, a counterfactual, and a human approval gate each had to be built deliberately — and that measuring an agent honestly (including the one run where it routed a real intrusion to "needs human" rather than guess) is more convincing to a security audience than claiming perfection.
What's next for GlassBox
More attack classes beyond intrusion and exfiltration; wiring the approval gate to real response actions (account disable, host isolation) through Splunk SOAR; and learning per-environment baselines so the red-team's benign signals (allowlists, change-ticket sources) come from the customer's own data rather than configuration.
Built With
- css3
- fastapi
- foundation-sec
- javascript
- model-context-protocol
- ollama
- python
- react
- splunk
- splunk-mcp-server
- vite
Log in or sign up for Devpost to join the conversation.