-
-
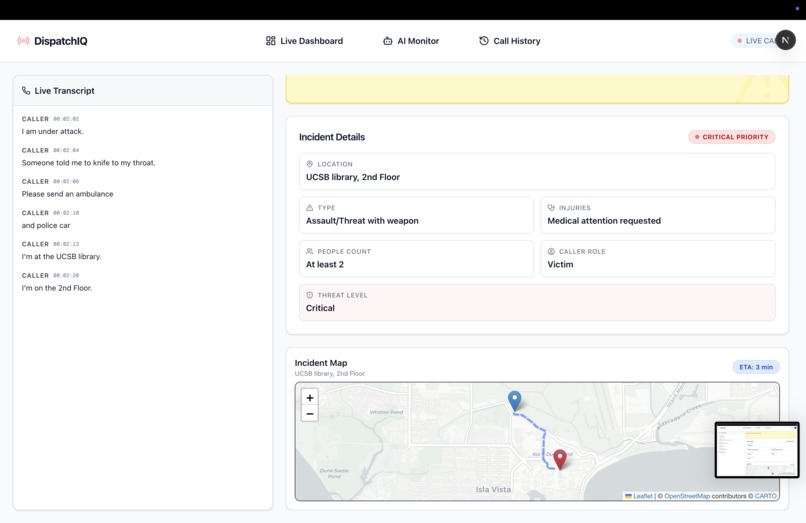
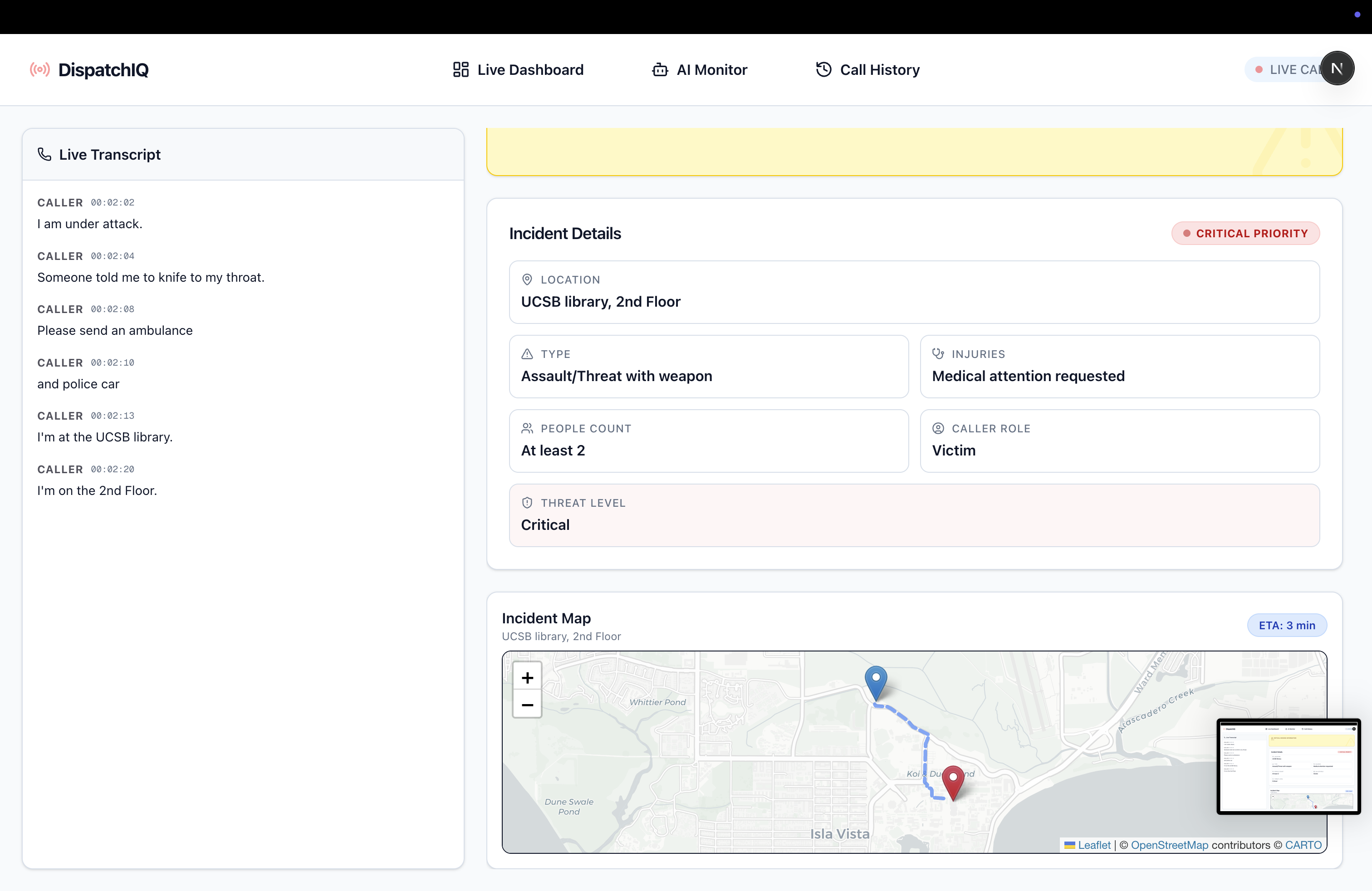
Live Dashboard During a Call
-
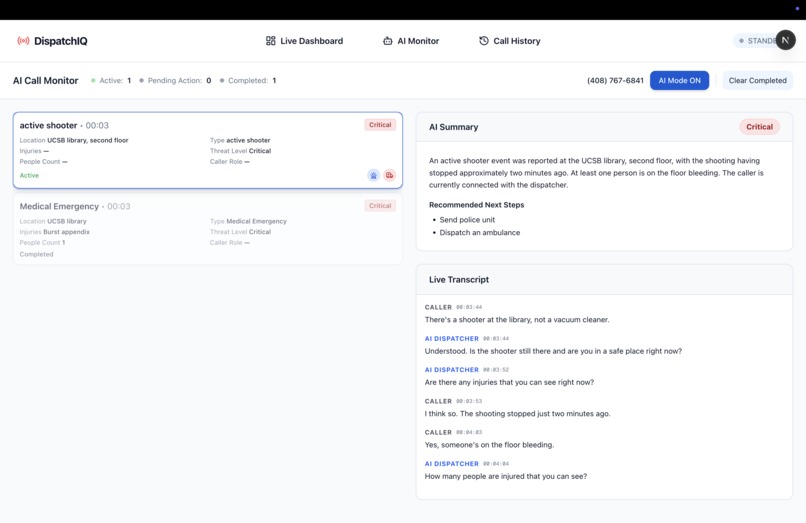
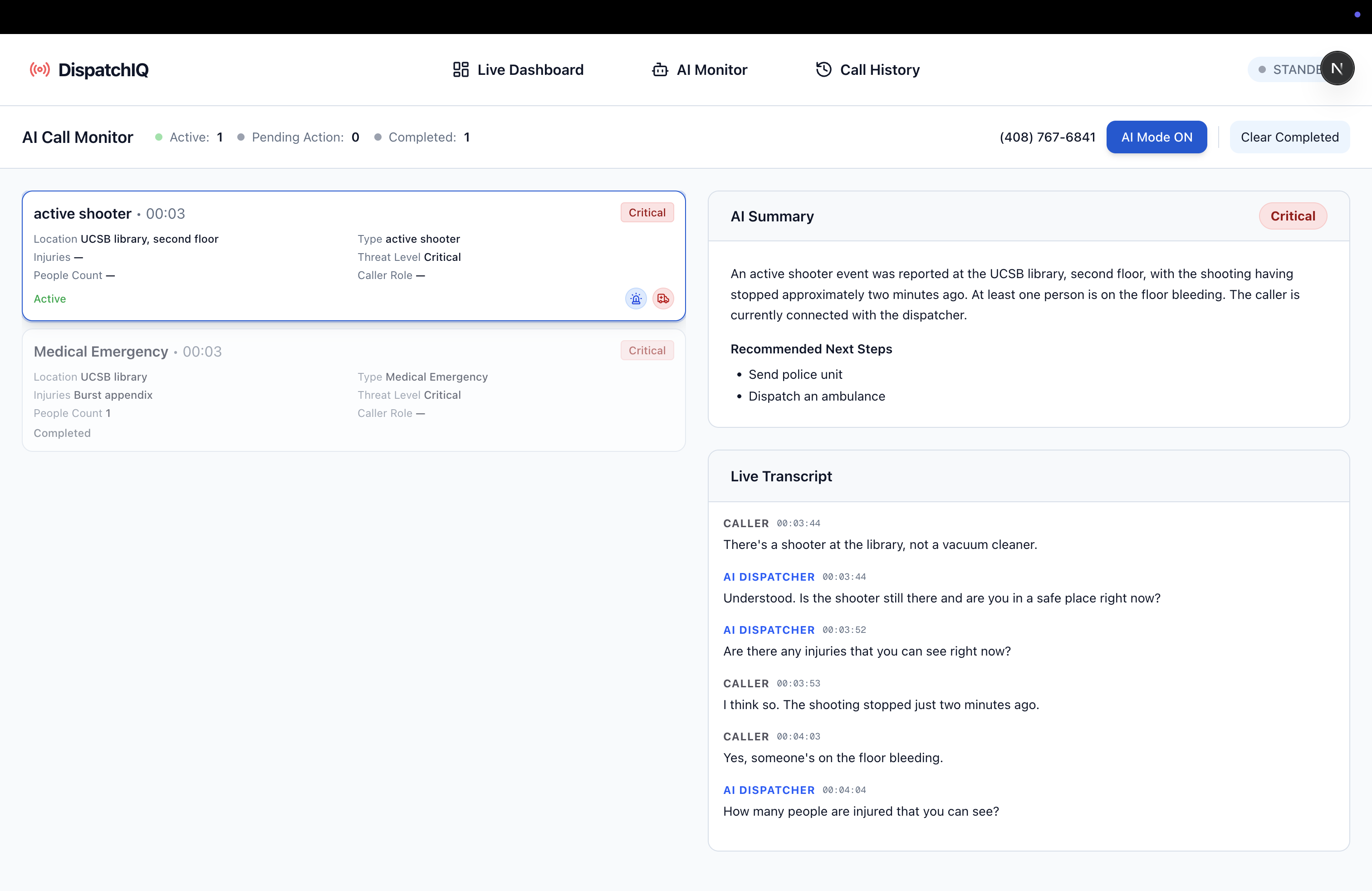
AI Monitor Page
-
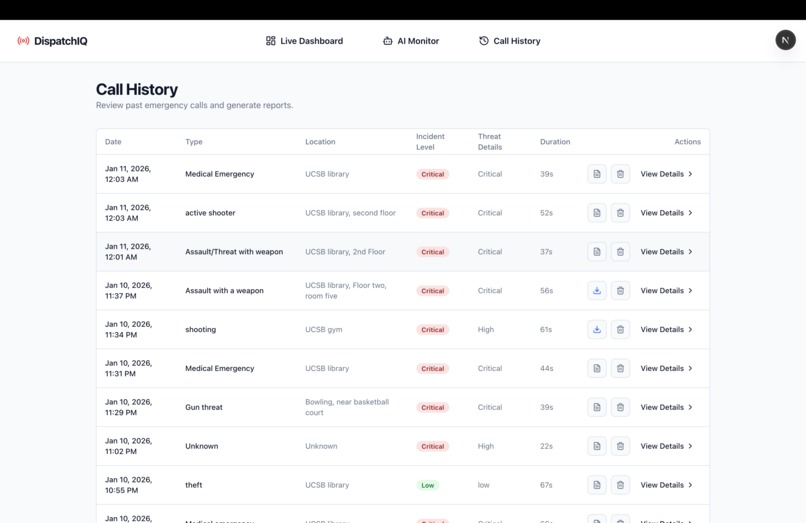
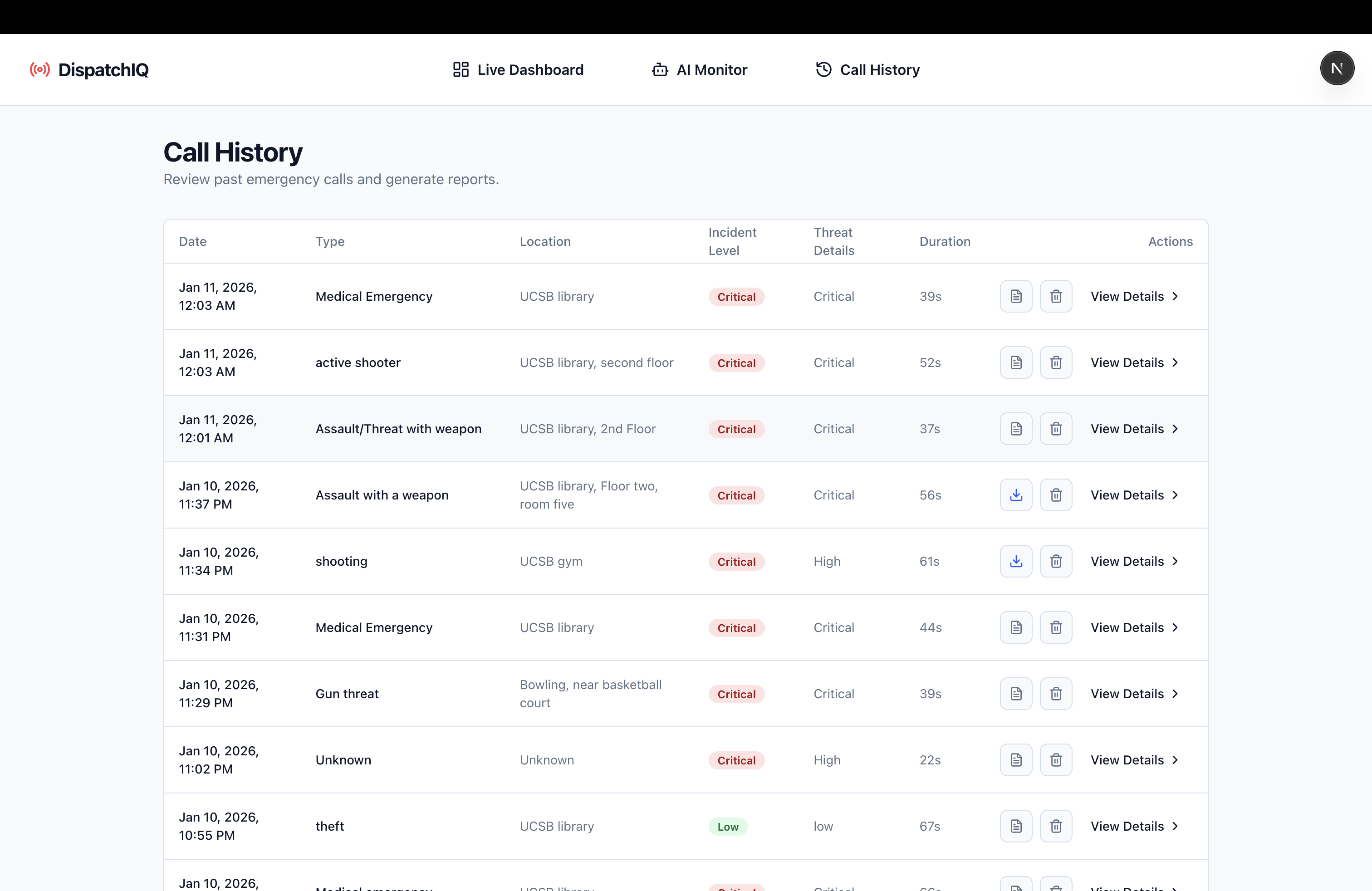
Call History
-
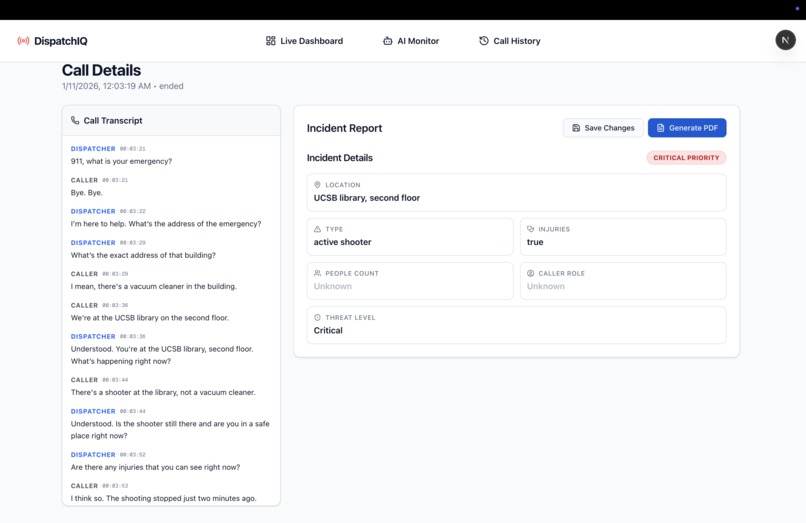
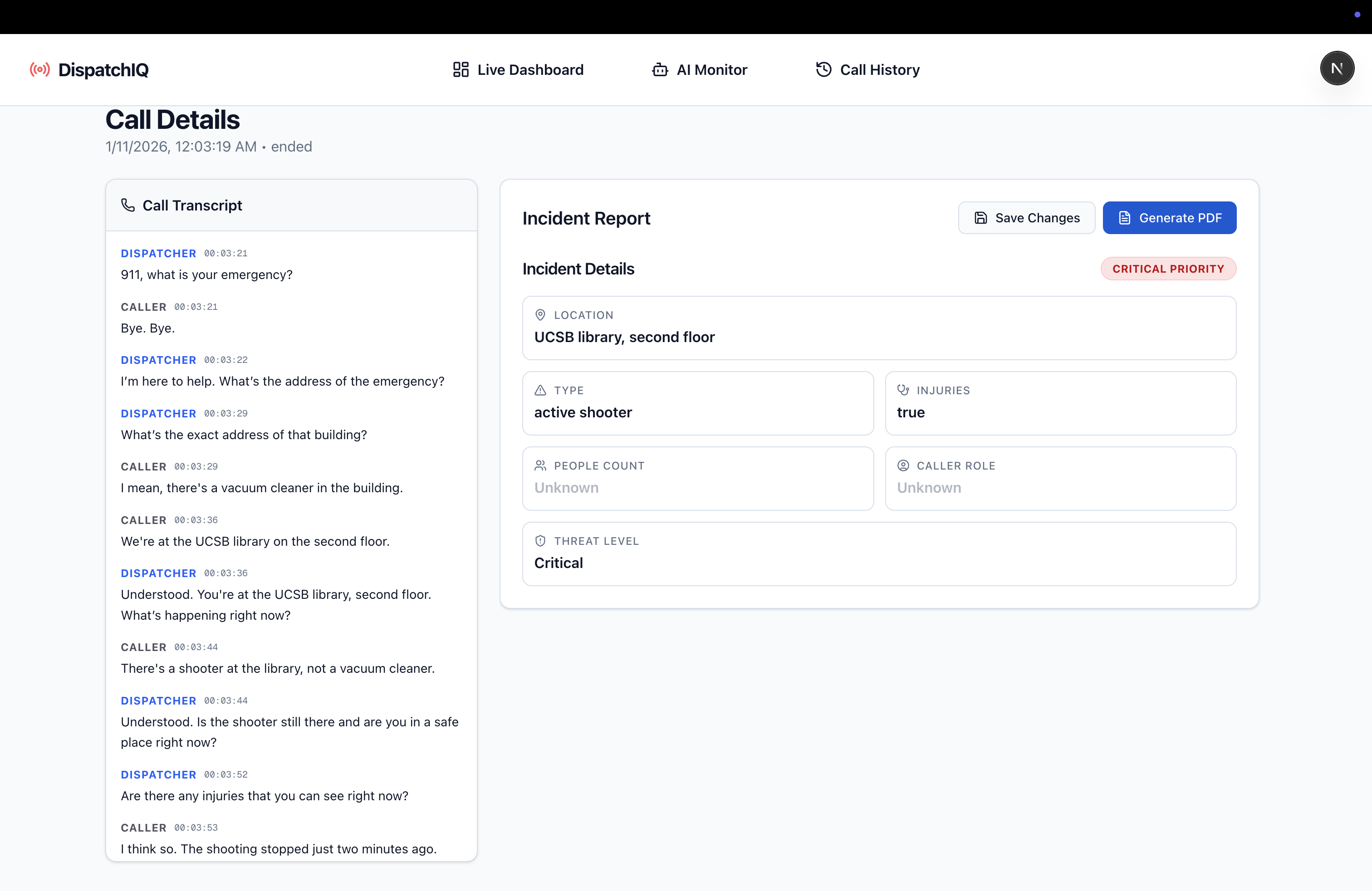
Call Details
-

PDF Generated from Transcript

Inspiration
We wanted to make something that was usable and helpful on a societal scale rather than personal or industrial, and we eventually landed on emergency dispatchers. Getting help out to people as quickly as possible is vital, and these high-intensity situations can put a lot of stress on dispatchers. Emergency situations, long calls where it's hard to keep track of all the information, dispatchers being overwhelmed by the number of calls, etc., are all things that make the dispatching job stressful, yet it remains vital. So, we aimed to relieve this stress and ease the jobs of dispatchers through this project, while also trying to increase the response times of these institutions. Given that our aim is not to replace dispatchers, but ease their duties, we created an AI dispatcher copilot.
What it does
DispatchIQ is a real-time AI crisis intake and wellness support assistant. When human responders are available, it helps them keep track of important information during emergency calls, as well as helping with reports afterwards. When human responders are busy, the system calmly guides callers through sharing critical information, reduces panic through structured conversation, and helps estimate response timelines. The goal is to improve communication, reduce stress, and ensure important details aren’t lost during urgent situations.
How we built it
We built DispatchIQ around a real-time dispatcher assistant that transcribes calls, extracts key details, and keeps an up-to-date incident summary for human responders. Twilio handles phone calls and audio streaming, DeepGram provides live speech-to-text, and Gemini reasons over transcripts to track structured information for the dispatcher interface. When dispatchers are unavailable, an AI voice fallback using OpenAI’s real-time speech-to-speech capabilities can temporarily answer calls and collect important details. it's designed so transcription, reasoning, and UI updates happen continuously, minimizing latency so it can actually aid a dispatcher in real-time.
Challenges we ran into
One of the biggest challenges was latency - even small delays feel significant during a live emergency call. We had to tune our speech-to-speech pipeline, endpointing, and response timing to keep response latency down.
Accomplishments that we're proud of
We’re proud of building a system that feels responsive, and helpful under pressure. Achieving low latency voice interaction while still collecting important data was definitely an achievement. We’re also proud that the project emphasizes human well-being We’re also proud that the project emphasizes human well-being - support for callers and aid for dispatchers - rather than focusing purely on automation.
What we learned
We learned that in a real-time calling web app like this, speed is very important. even a 2-3 second delay for an LLM query or something similar can feel like ages when you're in an emergency situation. We also learned some things about how to make a UI feel intuitive, like minimizing the amount of segments on the screen at a time, keeping important information large and more centered, and choosing a proper color scheme for your use case.
What's next for DispatchIQ
Next, we’d like to further decrease latency. Some of the API calls, like to Gemini, still take some time to return the information and render it (a couple seconds), and could definitely be improved to make it feel overall more responsive. Also adding multi-language support would be cool.
Built With
- deepgram
- gemini
- next.js
- openai-realtime-api
- openstreetmap
- supabase
- twilio
- typescript

Log in or sign up for Devpost to join the conversation.