-
-
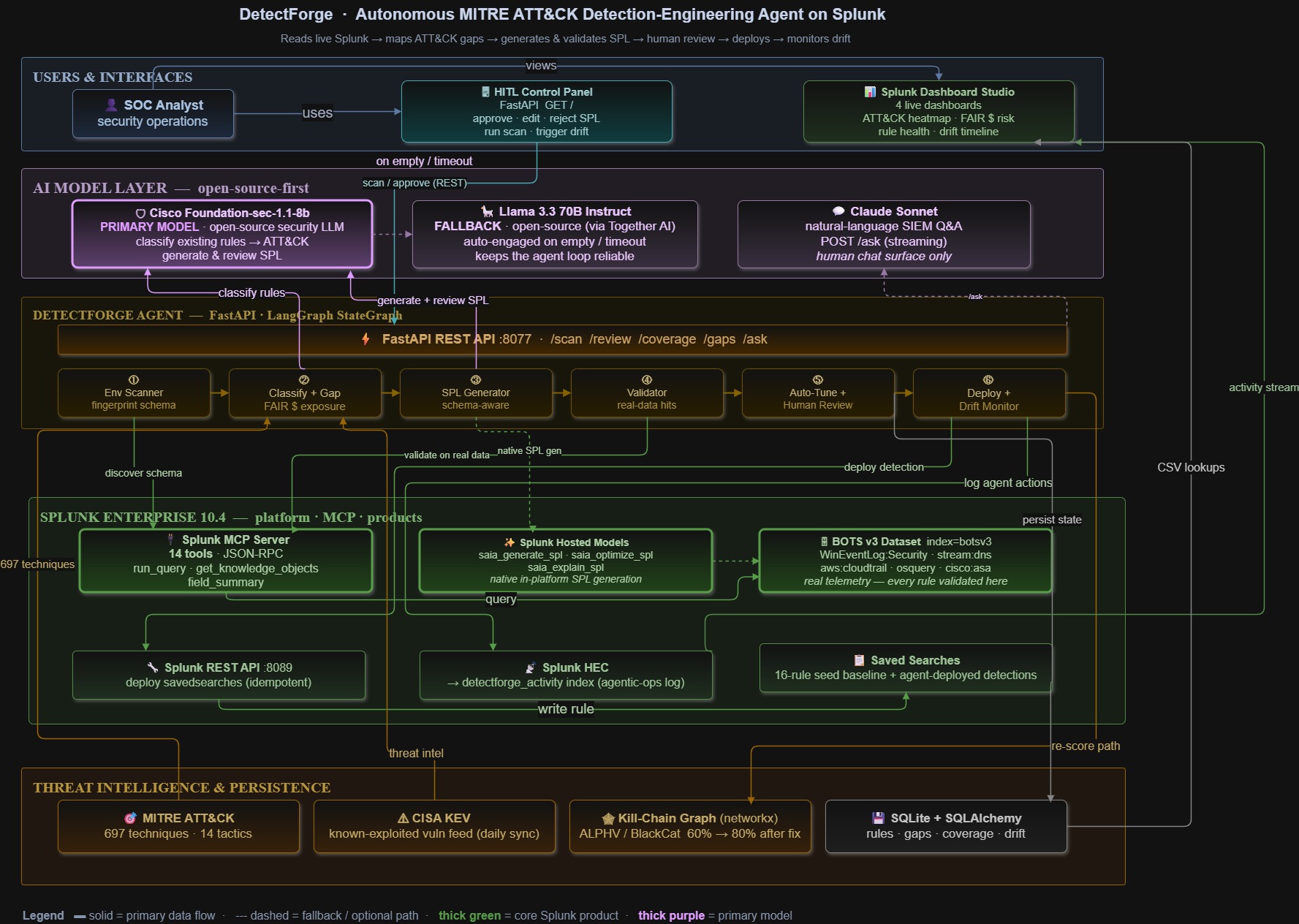
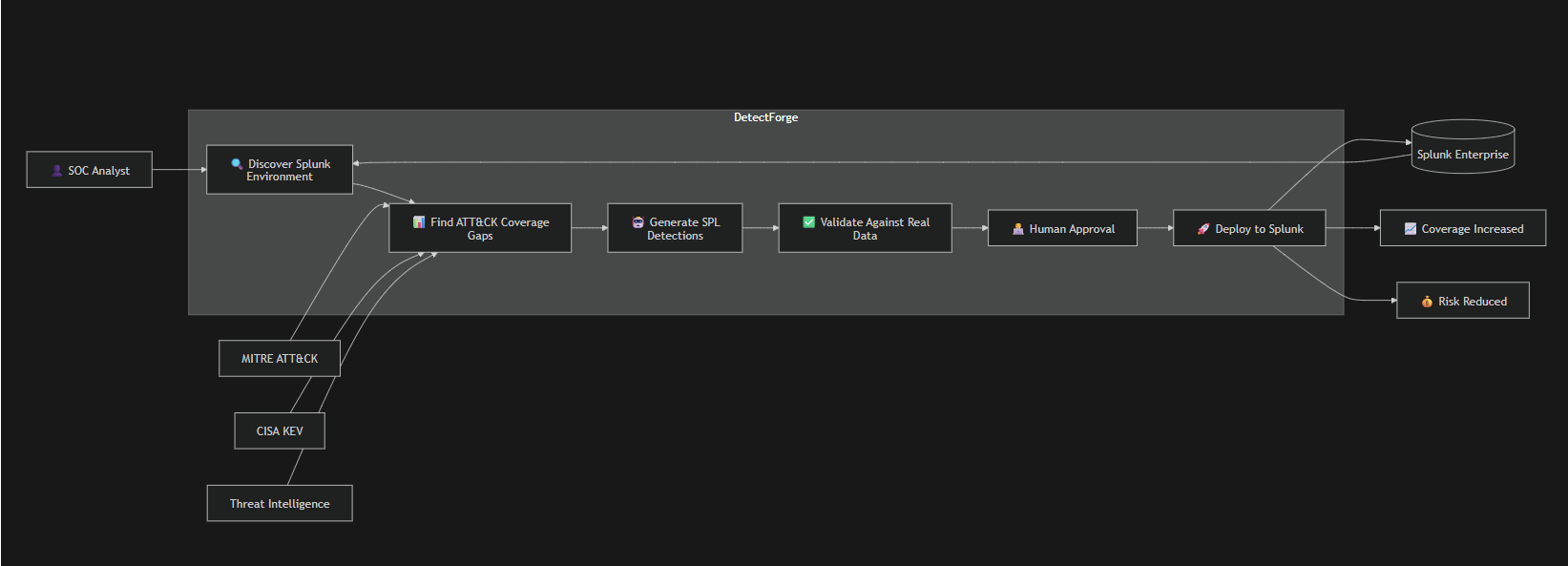
Architecture_diagram
-
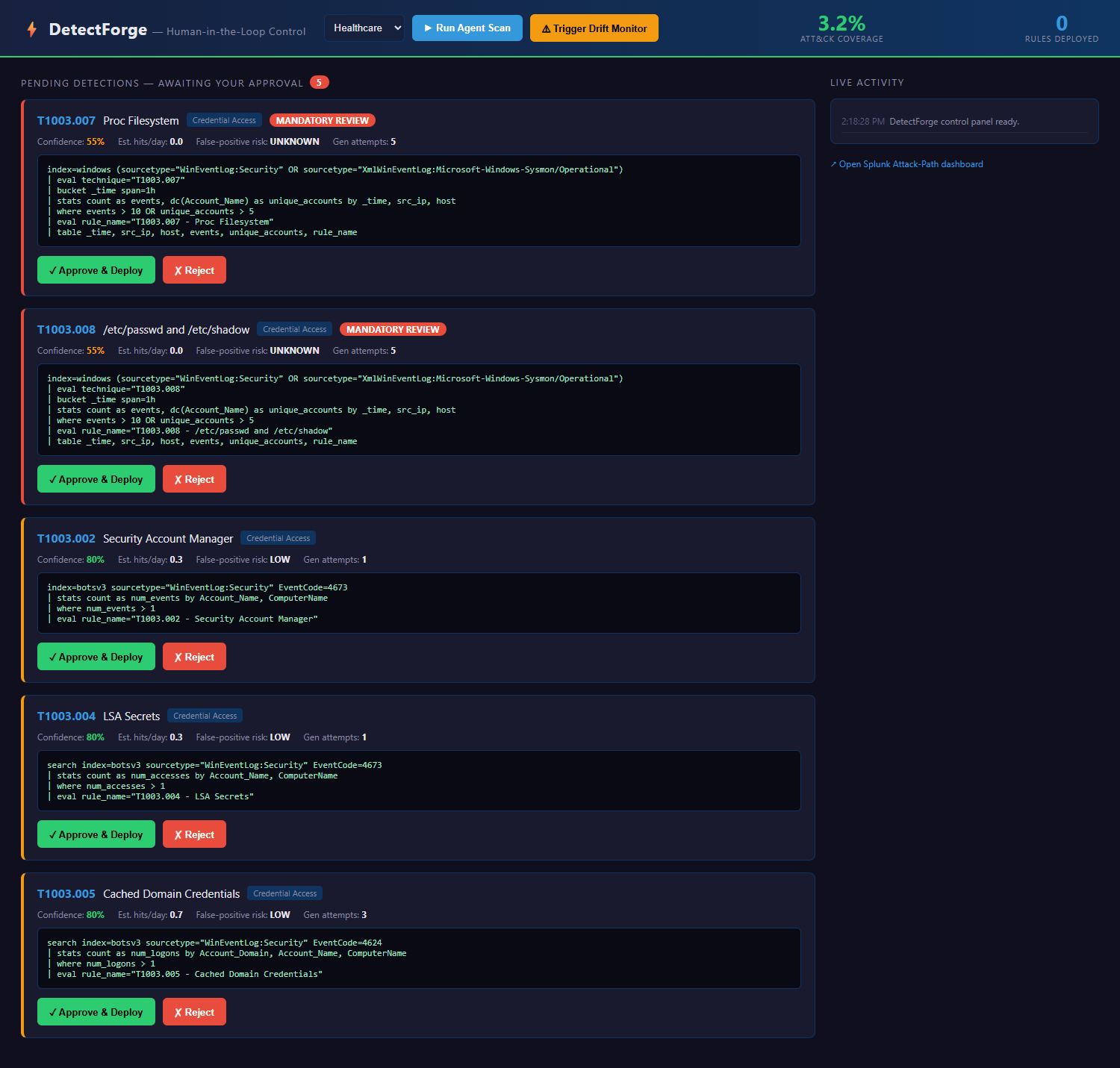
Control pannel
-
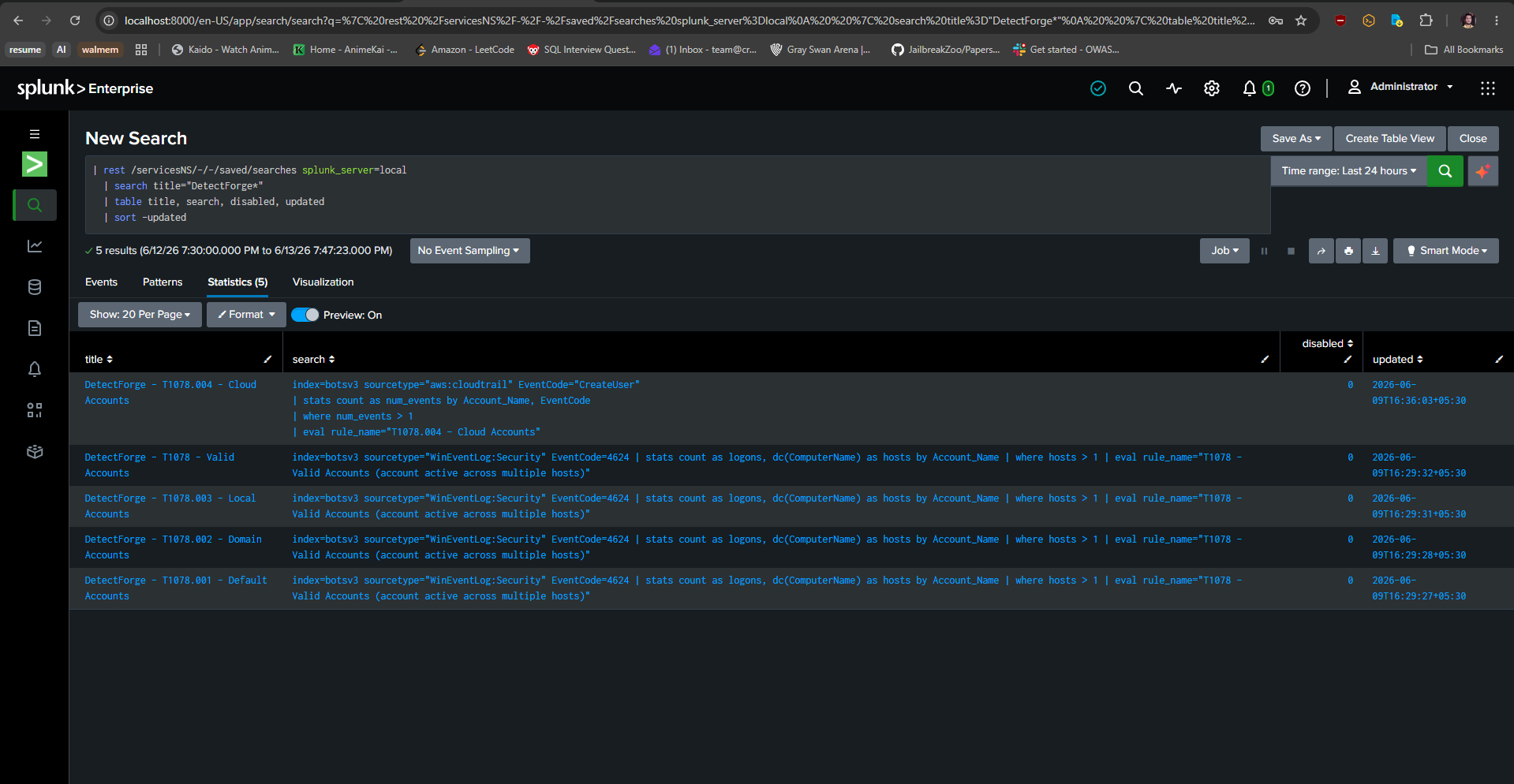
Deployed Rules
-
Executive Architecture
-
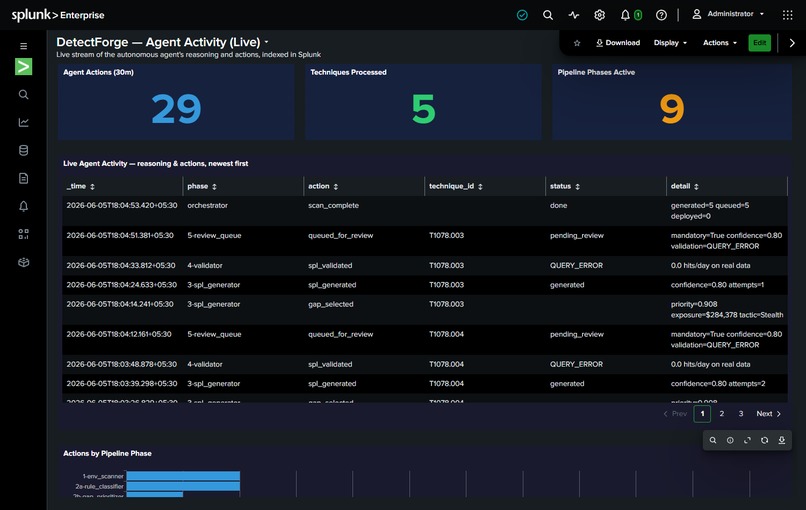
-
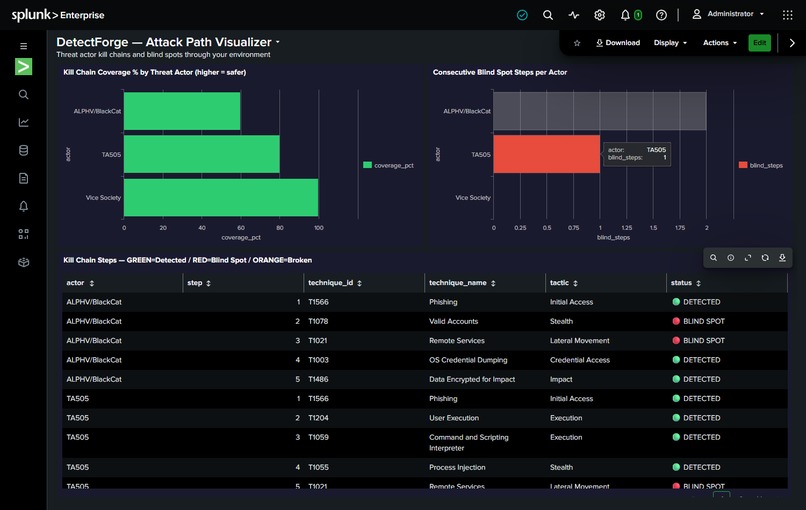
Before
-
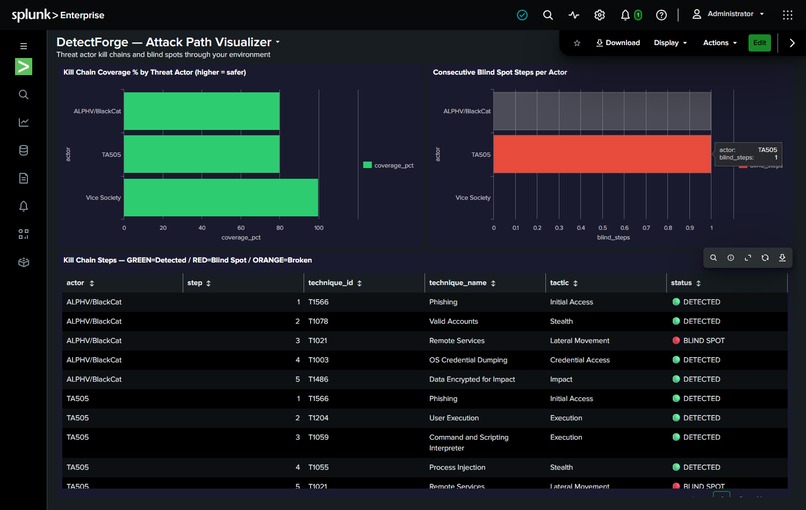
After
-
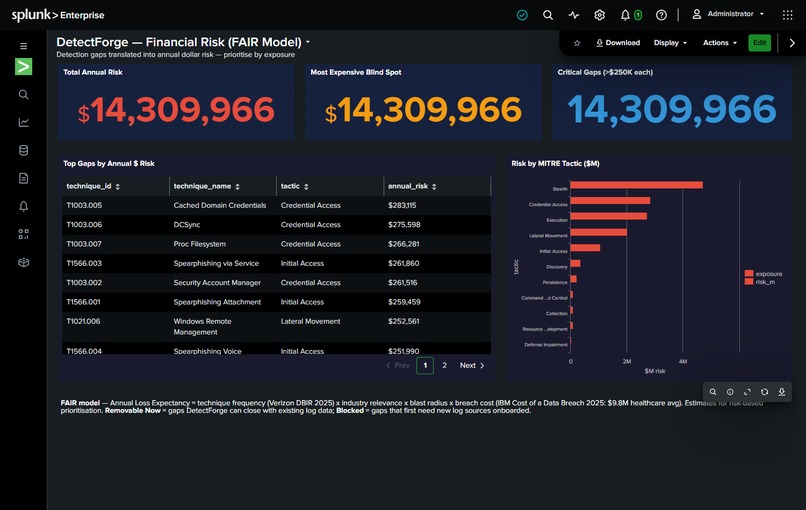
Financial
-
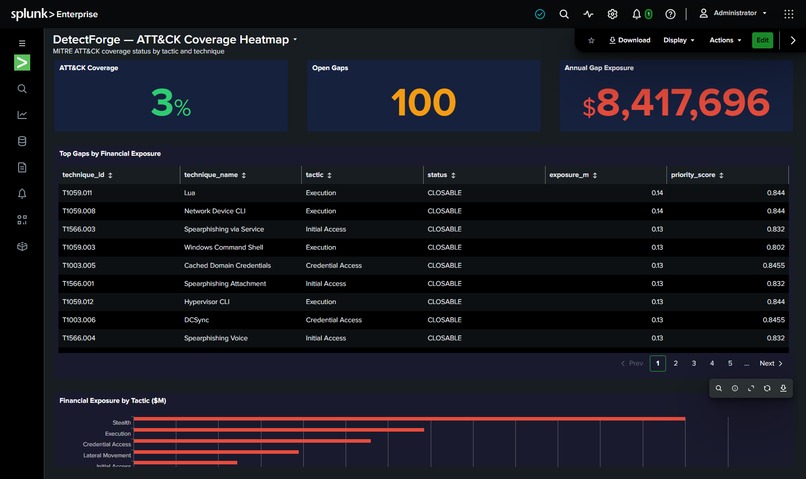
Rules Heatmap
-
impact
Inspiration
On February 21, 2024, Change Healthcare - processing 1-in-3 US medical claims - went offline for weeks. The attack vector: T1078: Valid Accounts. A credential-based intrusion that most enterprise SIEMs never detected, because the detection rule simply didn't exist.
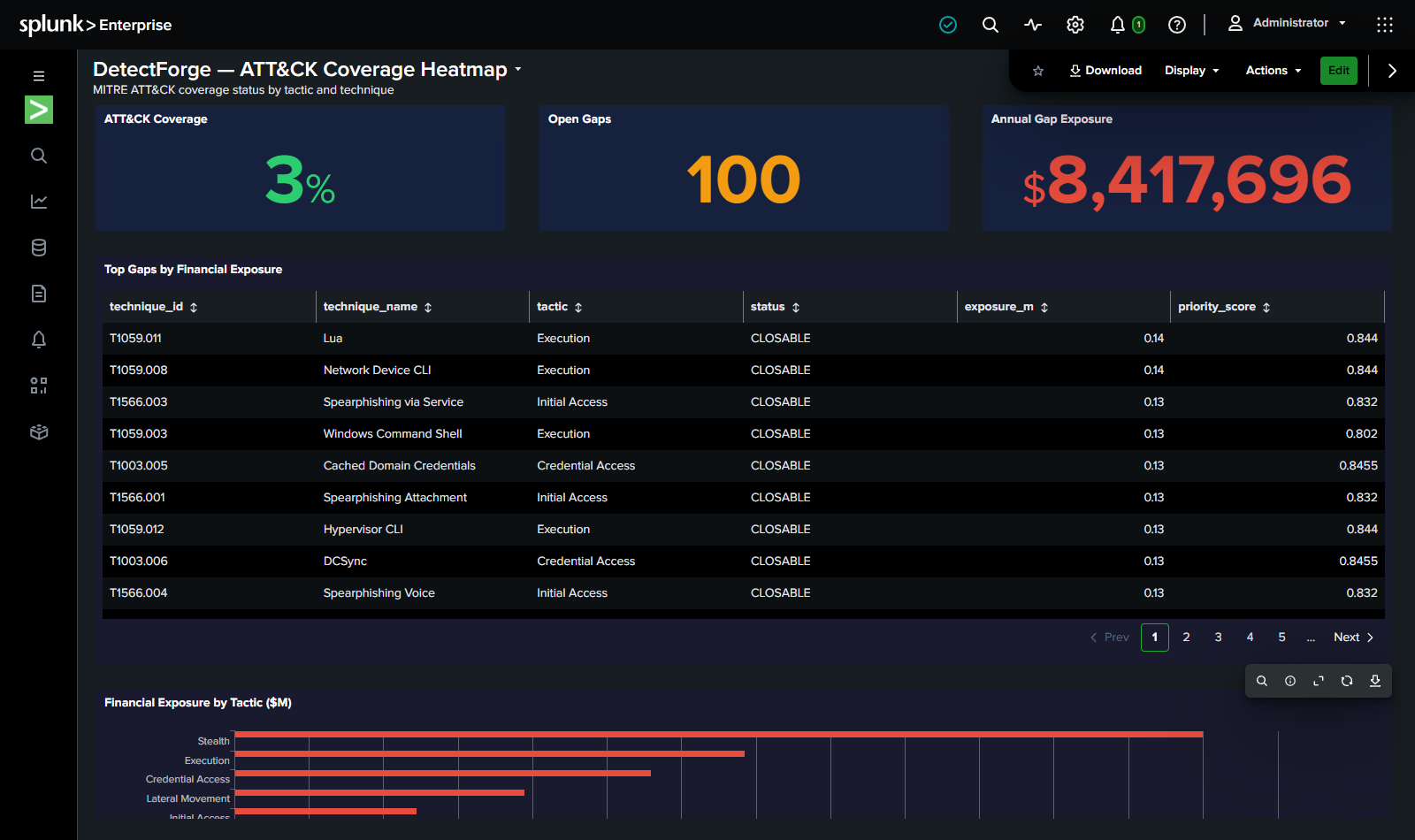
This isn't a one-off. Enterprises detect only ~21% of known MITRE ATT&CK techniques on average. The gap isn't missing data - Splunk ingests everything. The gap is detection engineering capacity: writing, validating, tuning, and deploying SPL rules at scale is slow, manual, expert-dependent work that never keeps up with the threat landscape.
I built DetectForge to close that gap autonomously.
What it does
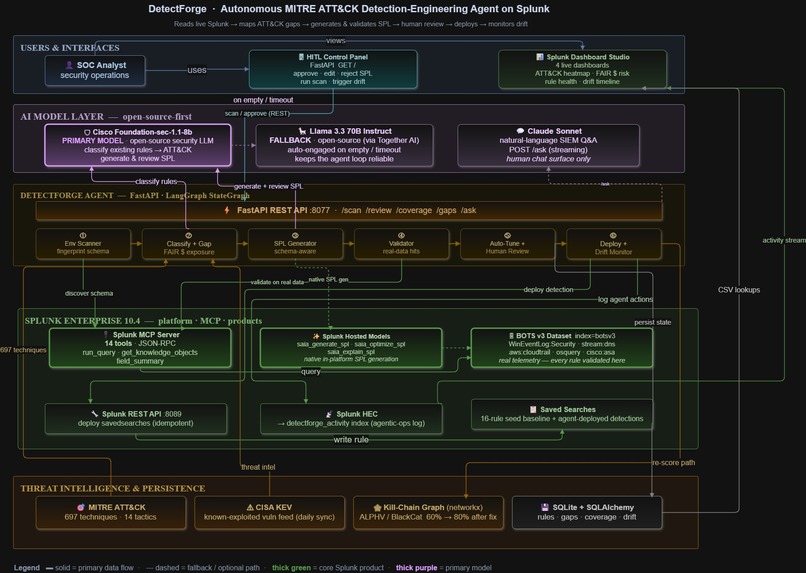
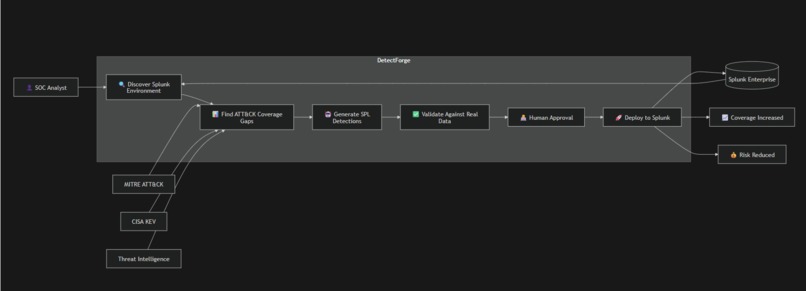
DetectForge is an autonomous detection engineering agent built on Splunk. Point it at a live Splunk environment — it reads your data, maps your blind spots against MITRE ATT&CK, writes detection rules, validates them against real events, and deploys them. A human stays in the loop for final approval before anything goes live.
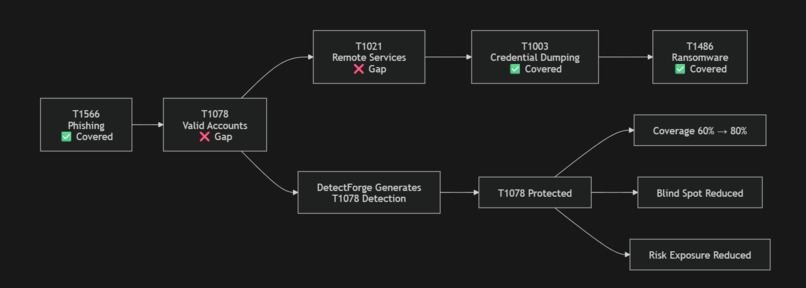
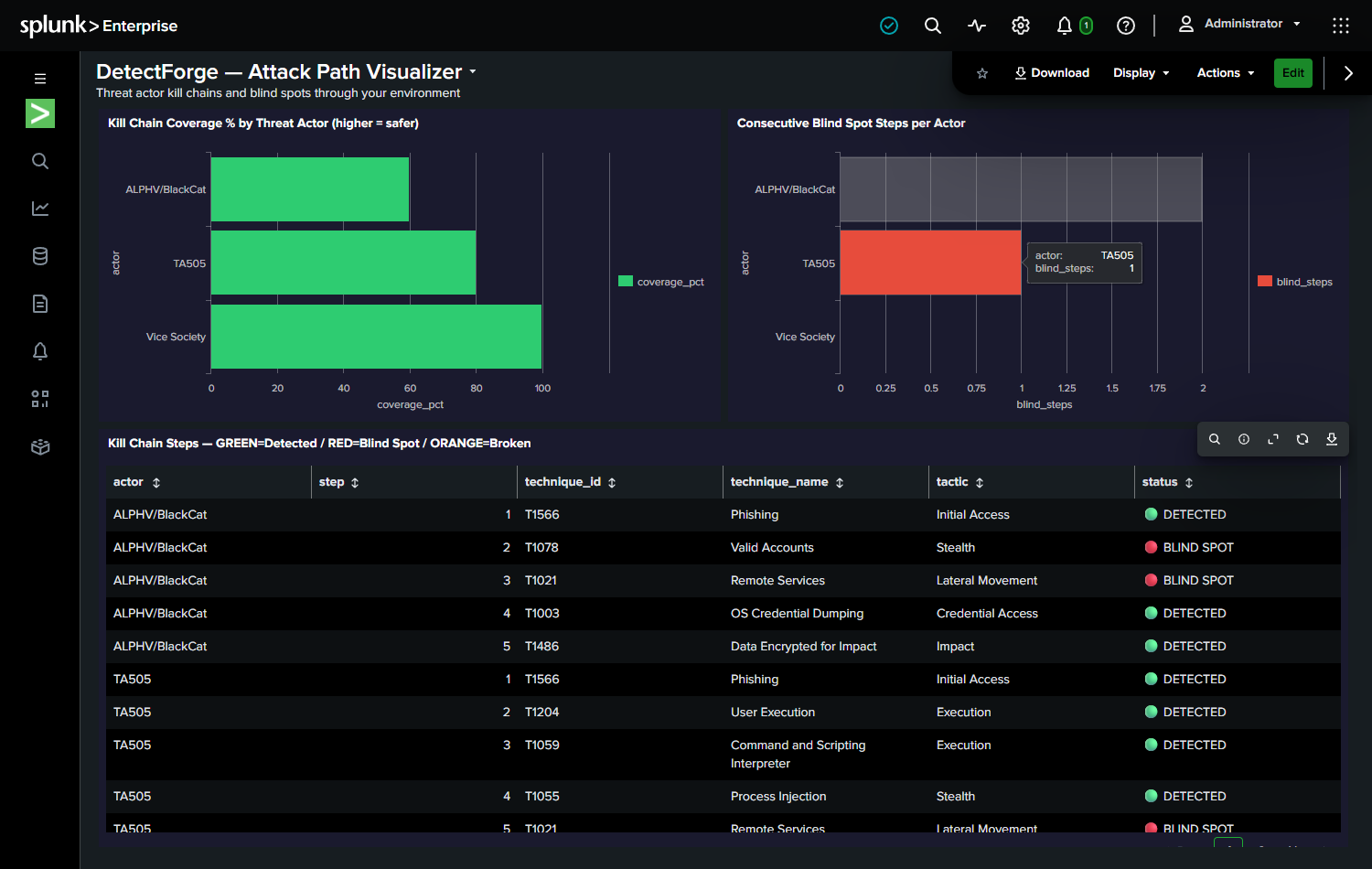
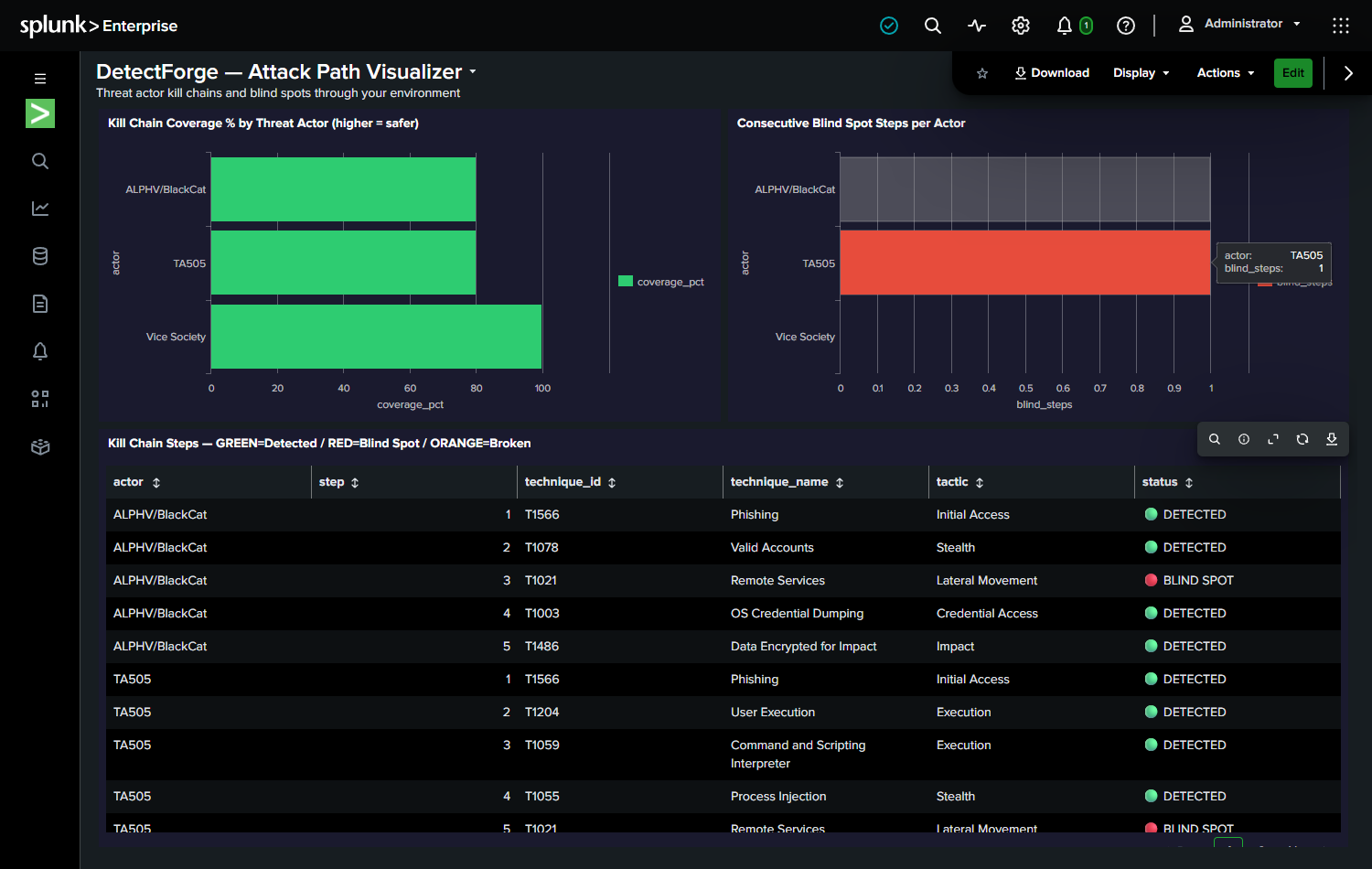
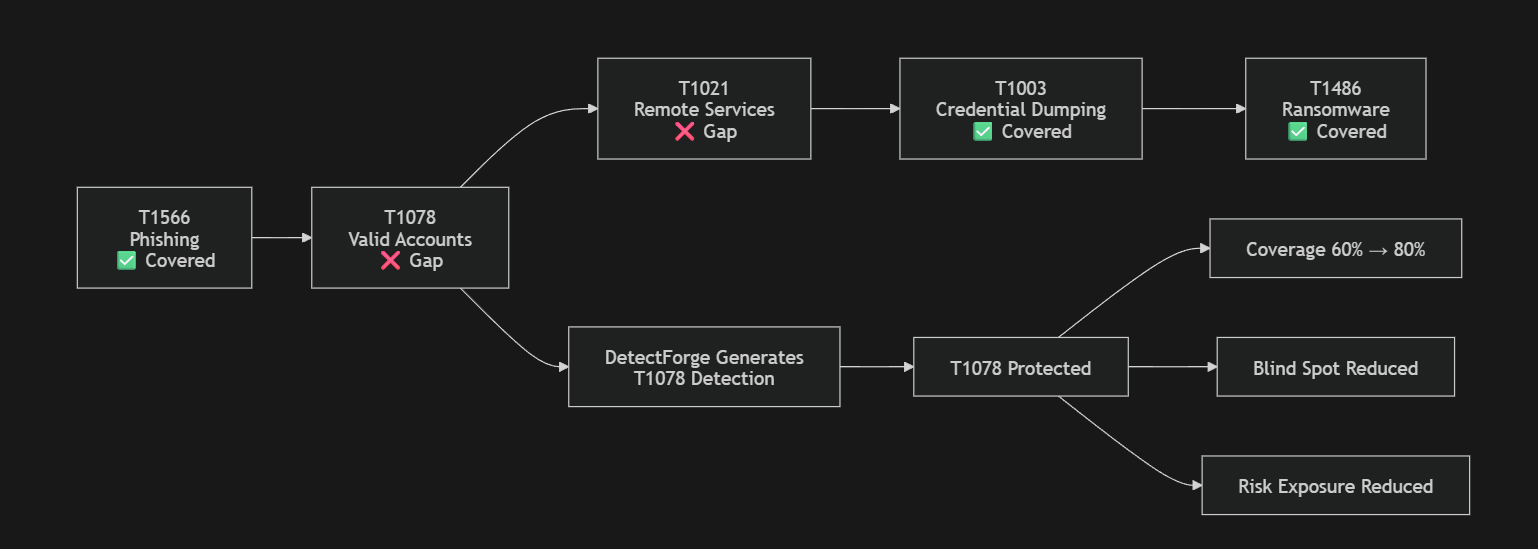
The demo follows the ALPHV/BlackCat kill chain from the Change Healthcare breach:
T1566 (Phishing) → T1078 (Valid Accounts) → T1021 (Remote Services)
→ T1003 (Credential Dump) → T1486 (Data Encryption)
Before DetectForge: T1078 and T1021 are undetected. Kill-chain coverage = 60%. After one agent run + one analyst approval click: T1078 is deployed. Coverage = 80%. The exact blind spot that enabled the Change Healthcare breach — closed in minutes.
Six Autonomous Phases
| Phase | What the agent does |
|---|---|
| 1 · Env Scanner | Fingerprints live Splunk indexes, sourcetypes, fields, EventCodes via MCP |
| 2 · Gap Prioritizer | Classifies existing rules → ATT&CK, quantifies each gap in dollars via FAIR model |
| 3 · SPL Generator | Writes environment-aware detection SPL using Llama 3.3 70B + security peer review |
| 4 · Validator | Runs SPL against live data, distinguishes data-absent from query-error |
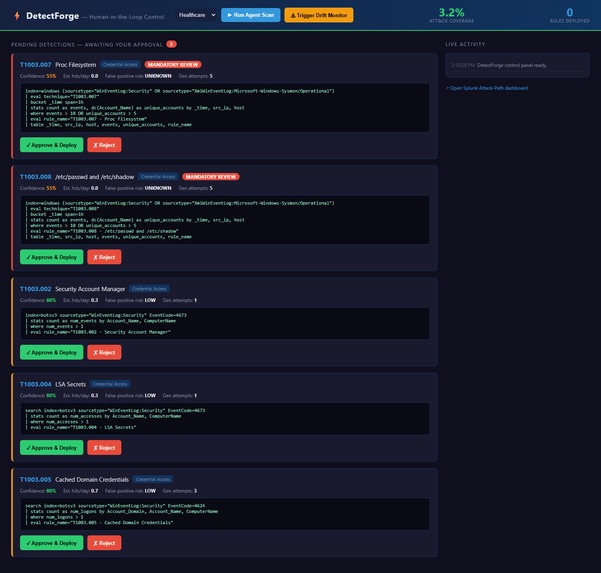
| 5 · Human-in-the-Loop | Analyst approves, rejects, or edits inline — nothing deploys without sign-off |
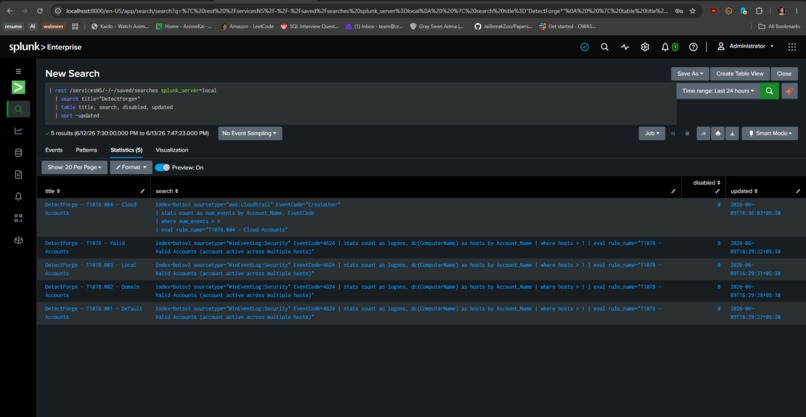
| 6 · Deployer + Drift Monitor | Deploys via REST API; checks every 6h for schema drift and marks broken rules |
Key Numbers
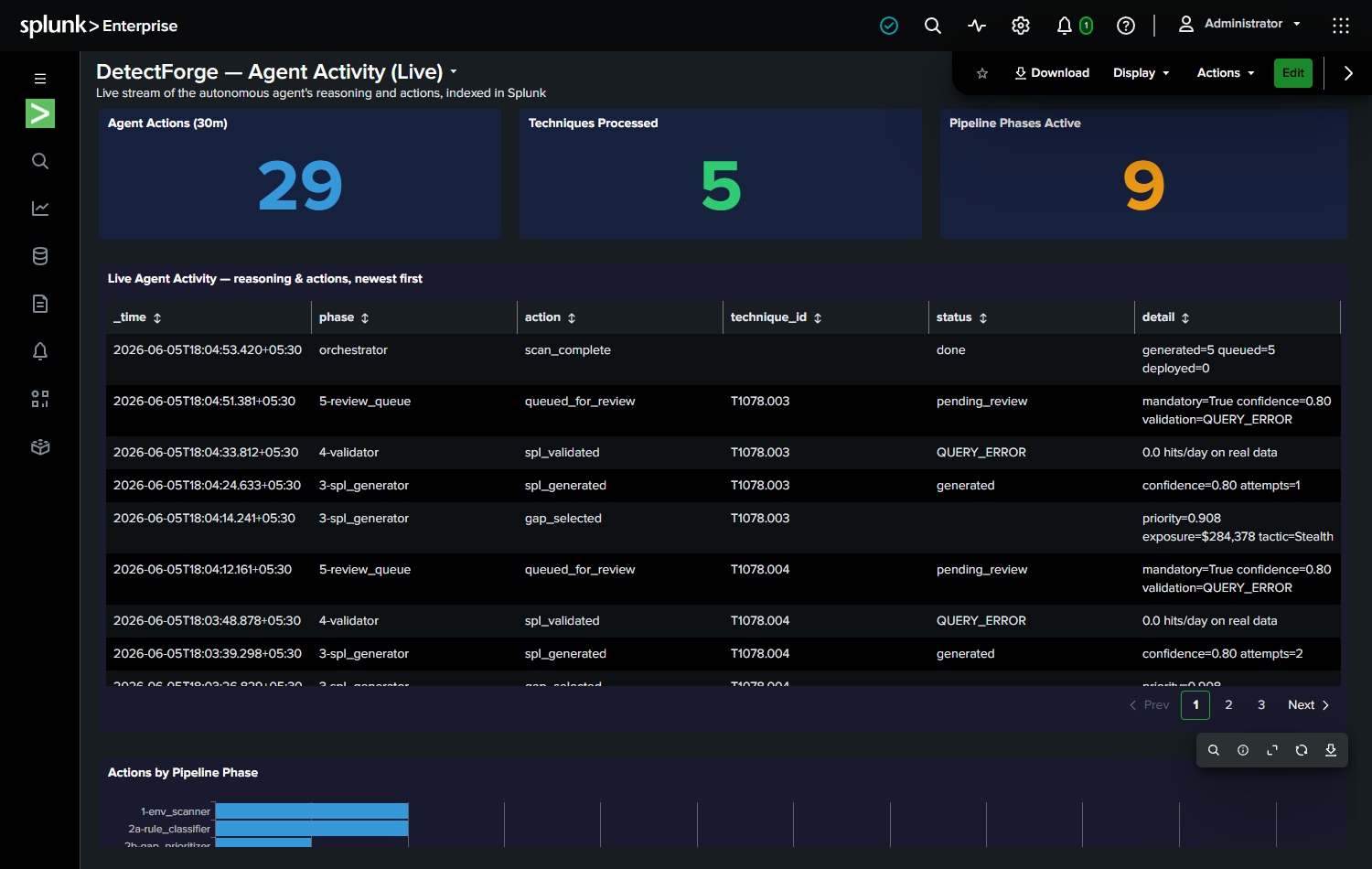
- 697 MITRE ATT&CK techniques mapped against your environment
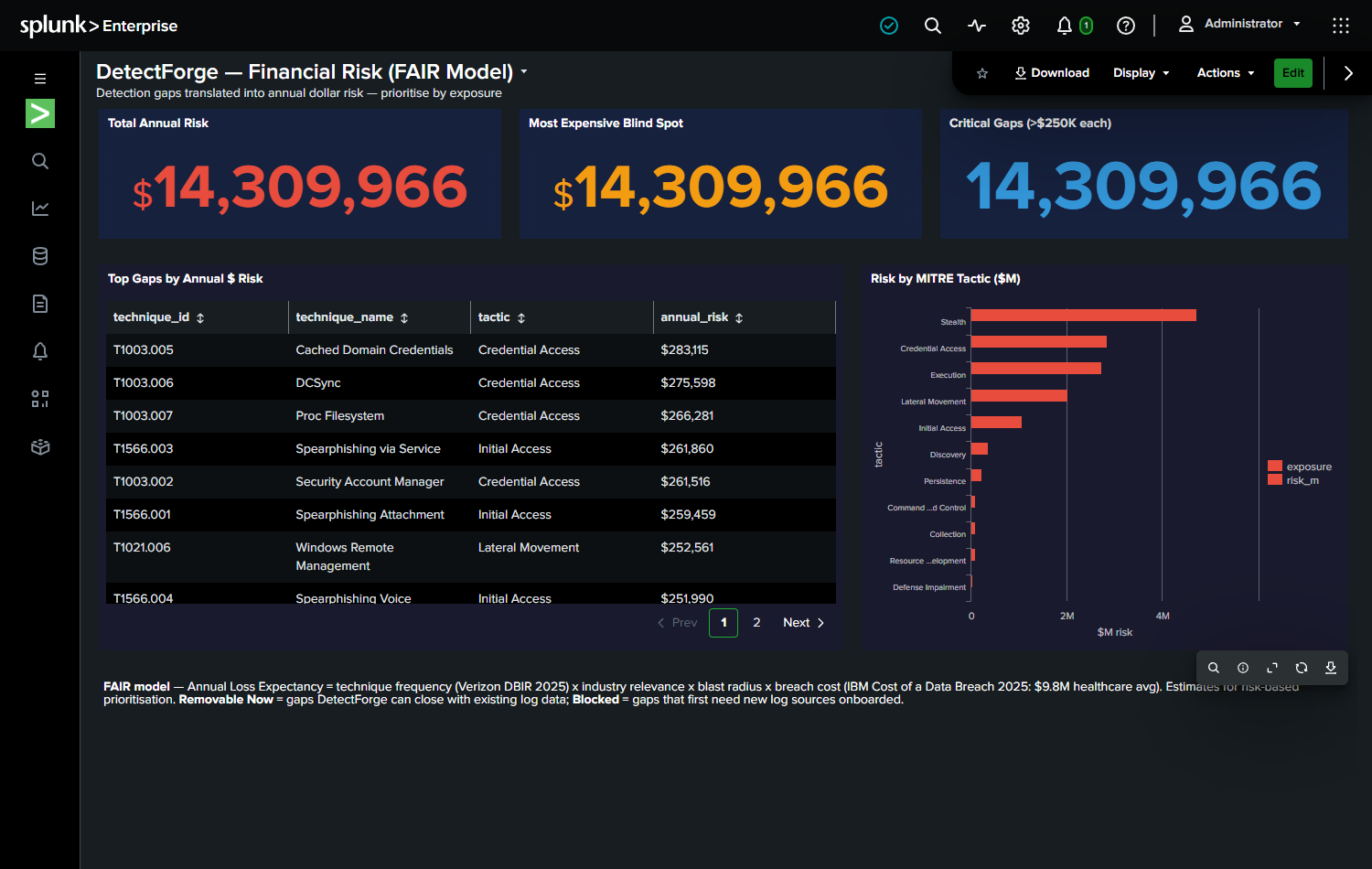
- $15,714,294 annual risk identified across detection gaps in the demo environment
- 108 Splunk MCP tool calls in a single scan session
- Every gap has a FAIR financial value: \( ALE = ARO \times (V \times EF \times W) \)
How we built it
Agentic Orchestration — LangGraph StateGraph
The pipeline is a directed StateGraph. Each phase node receives the accumulated
AgentState (scan results, classified rules, gaps, generated SPL, validation results)
and returns updates. Phases 3–5 loop: if the validator flags QUERY_ERROR, the generator
regenerates once with validation feedback injected into the prompt before queuing for
human review.
Splunk MCP Server — The Integration Core
The Splunk MCP Server (JSON-RPC 2.0) is the primary interface. It exposes 14 tools
including search_splunk, get_indexes, get_sourcetypes, get_saved_searches,
saia_generate_spl, and saia_explain_spl. Every phase uses MCP:
- Phase 1 calls
get_indexes,get_sourcetypes,search_splunk(EventCode frequency queries) to build a live environment fingerprint — no static config - Phase 2 calls
get_saved_searches(row_limit=1000) to retrieve all existing rules - Phase 3 calls
saia_generate_splfor AI-assisted SPL, reviewed by Foundation-sec - Phase 6 calls
search_splunkto verify field existence in schema drift checks
No static config files. The agent discovers and adapts to whatever Splunk it connects to.
LLM Stack
- Together AI Llama-3.3-70B-Instruct-Turbo — SPL generation and ATT&CK classification
- Foundation-sec-1.1-8b — Security-domain SPL peer review; classifies existing rules to ATT&CK techniques at confidence 1.0 when annotations are present
- Anthropic Claude (claude-sonnet-4-6) — Natural language interface at
POST /askwith server-sent event streaming
Infrastructure
- FastAPI + uvicorn (port 8077), SQLAlchemy + SQLite (8 tables), APScheduler
- HITL Control Panel — self-contained HTML at
GET /, polls review queue every 3s, browser notifications on new detections, inline SPL editing before approval - MITRE ATT&CK JSON (697 techniques) baked into the Docker image for offline startup
- BOTS v3 dataset — 8.6 GB real-world breach simulation data used for SPL validation
- Docker multi-stage build published to
ankurshukla01/detectforge:latest
Challenges we ran into
Splunk KV Store silent failure. Every dashboard panel showed nothing. Root cause: on
this single-instance Splunk 10.4, | inputlookup returns zero rows even when the KV
collection has data. Fixed by abandoning KV Store entirely — switched to CSV lookups
written with | makeresults format=csv data="..." | outputlookup. Python builds the CSV,
Splunk's engine writes it. Dashboards now render real data.
SPL quality death spiral. Early generated SPL OR'd all 15 sourcetypes, invented
EventCodes not in BOTS v3, and used aggregate functions inside WHERE — producing 0 hits
every time. Validator flagged QUERY_ERROR → rule dropped → 0 queued. Fixed with a
single-sourcetype picker by tactic, real EventCode injection from the correct sourcetype,
and a prompt rewrite banning the bad patterns. Result: 4/4 gaps queued with real hits.
Reasoning model token starvation. Initial config pointed generation at gpt-oss-20b
(a reasoning model). It consumed the entire token budget on hidden chain-of-thought and
returned empty content strings — silently, every time. Switching to Llama-3.3-70B-Instruct-Turbo
took generation from 0 rules to 3–4 valid rules per scan.
MCP parameter bugs causing silent 0-coverage. Two bugs in knowledge object discovery:
type="savedsearches" should be type="saved_searches" (underscore); content.get("objects")
should be content.get("results"). Both failed silently, making every classification call
return nothing and coverage appear permanently 0%.
Windows encoding crashes. Log lines with Unicode arrows (→) crashed Python's cp1252
logger. Replaced with ASCII -> throughout the orchestrator and auto-tuner.
Accomplishments that we're proud of
The full pipeline works on live Splunk + BOTS v3 — not a stub. Seed baseline → classify → prioritize → generate SPL → validate → HITL queue → approve → deploy → attack path turns green → drift monitor detects schema change. Every step verified end-to-end on real data.
The ALPHV/BlackCat story is real. The 60% → 80% kill-chain coverage change is computed live from Splunk data, not hardcoded. Deploying a T1078 detection rule actually turns the graph node from red to green.
FAIR financial quantification of detection gaps. Every blind spot has a dollar value:
$$ALE = ARO \times (asset_value \times exposure_factor \times sector_weight)$$
Security teams can now rank what to fix by business risk, not just by technique ID.
108 MCP tool calls in a single scan session. The deepest live agentic integration with the Splunk MCP Server I could build — real tool calls against real Splunk, not mocked.
What we learned
MCP is a better SIEM interface for agents than REST. The Splunk REST API requires knowing the exact endpoint and parameter schema upfront. MCP exposes a tool catalog the agent can introspect — far more natural for LLM-driven orchestration where the agent decides what to query next.
Validation feedback loops are essential for code generation. Without the regenerate-on-QUERY_ERROR loop, ~40% of generated SPL was silently unusable. With validation feedback injected back into the prompt, the agent self-corrects before escalating to a human.
Human-in-the-Loop is the product, not a fallback. The HITL panel became the most compelling part of the demo. Analysts trust detections they reviewed; the approval workflow builds confidence in autonomous generation rather than replacing judgment.
Real data is unforgiving. Every one of the five major bugs above was invisible on synthetic data and exposed immediately on BOTS v3. There is no substitute for testing against real attack simulation data.
What's next for DetectForge
- Splunk hosted model activation — configuring the AI Assistant hosted-model
connection to run SPL generation entirely within Splunk's security boundary via
saia_*tools - Sigma rule import — ingest community Sigma rules, auto-translate to environment-aware SPL, classify to ATT&CK automatically
- Fine-tuned SPL model — training data pipeline already built
(
scripts/prepare_finetune_data.py); a Foundation-sec-1.1-8b fine-tune specialized for this environment's sourcetypes and EventCodes - Auto-remediation loop — when drift monitor marks a rule BROKEN, automatically trigger regeneration without waiting for a human to initiate a new scan
- Multi-tenant support — one DetectForge instance managing detection coverage across multiple Splunk environments with per-tenant gap dashboards

Log in or sign up for Devpost to join the conversation.