You can visit the website now at www.dccrashes.tech.
Inspiration
Several of our team members ride bikes. One of our members recently sustained a permanent injury due to traffic. He used Google maps to plan a route that led him through a dangerous intersection. We thought of a way to display these dangerous accident hotspots from crash data.
What it does
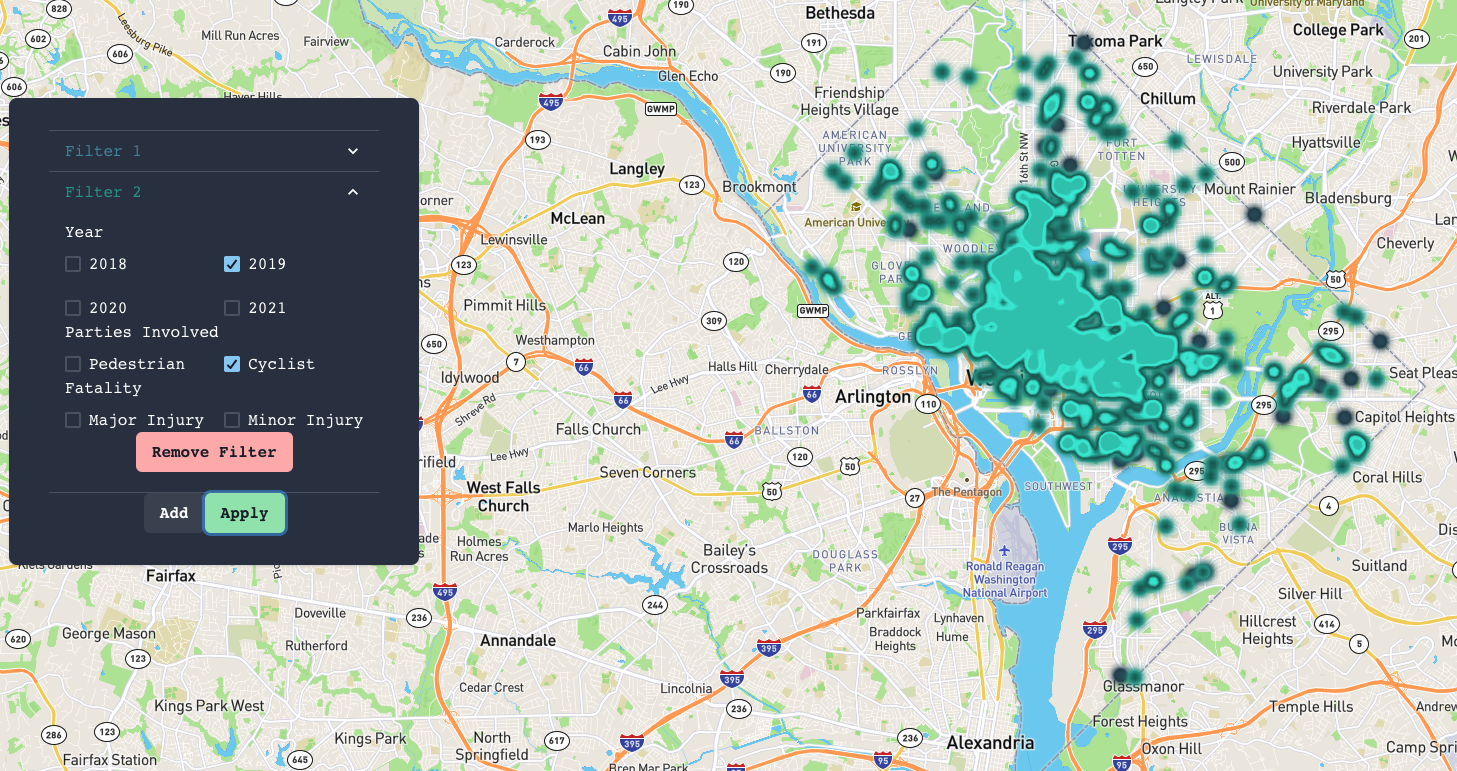
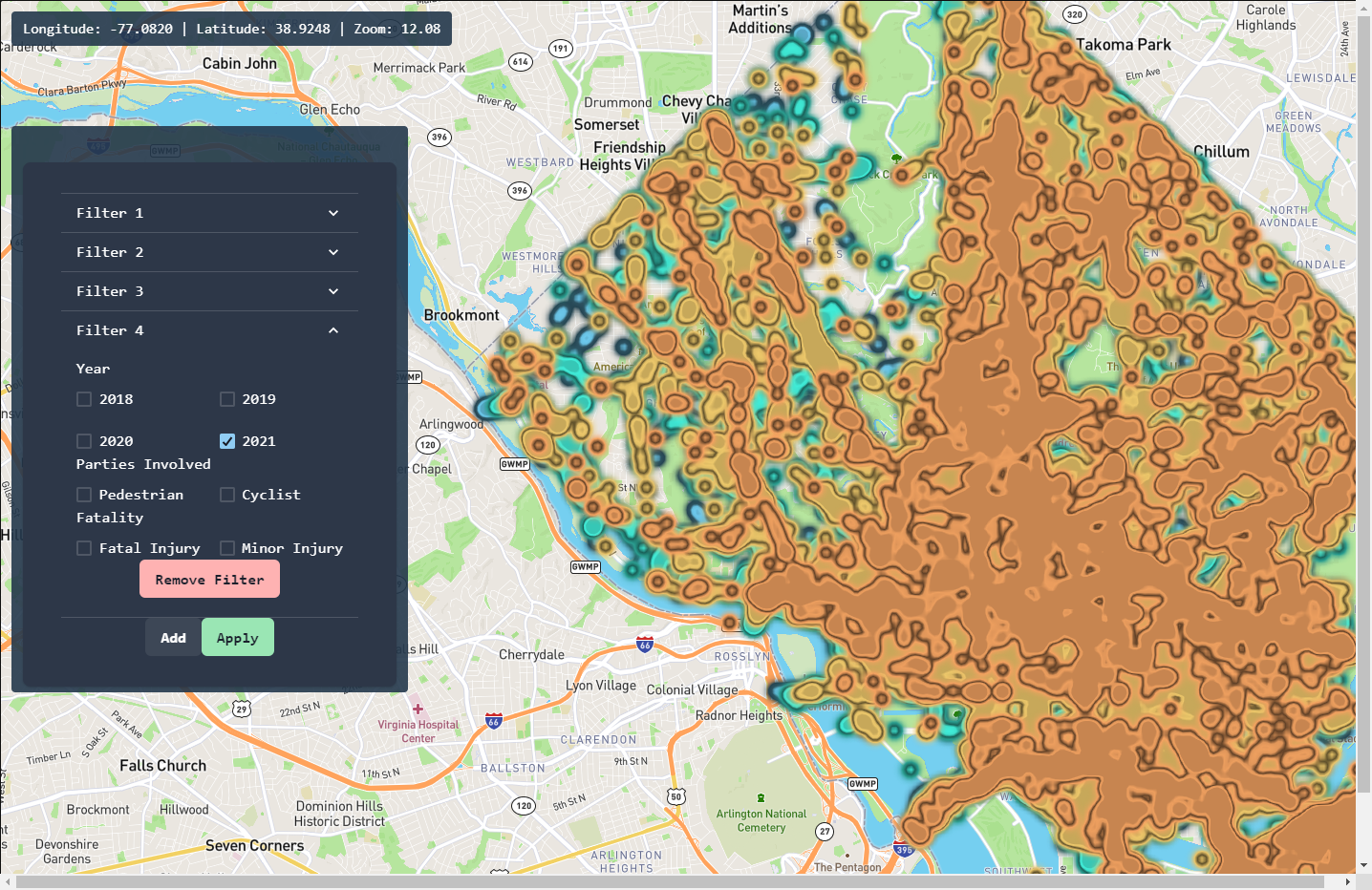
Our site fetches publicly available historical data from the D.C. government about traffic crashes. A user can filter data from the database to investigate incidents related to certain modes of transport like cycling or pedestrians. We then use a k-means clustering algorithm to show accident hotspots for bike riders and pedestrians. This application could potentially reduce cycling and pedestrian traffic at busy intersections by routing users away from zones of high traffic incidents. Traffic engineers could also use the data shown to optimize busy intersections.
How we built it
We acquired data from OpenData DC on all crashes in the past 20 years. We then filtered out and sorted the data for just the last 4 years using JavaScript. We also made a separate file that would hold the clusters for given years so that we could display them separately. Then, a React app was made which would display the Mapbox map along with filter options using Chakra UI. Once we finalized the UI and backend, we used AWS to host our website on the domain we got from Domain.com.
Challenges we ran into
Finding a good hosting service. When going through the data to filter, we found some data in the database was wrongly inputted, meaning they shifted the location of our clusters. In addition, the data files we worked with were extremely large and caused problems when running our code and with efficiency. Since we would need to hide the layers in the map not wanted, we had problems trying to only display the wanted layer.
Accomplishments that we're proud of
We were proud that we were able to make a website that was running on an actual domain since it was the first time for many of us. We are also proud that we have a data display that you can draw conclusions from and use in traffic engineering and could potentially prevent many traffic-related incidents.
What we learned
Through this project, we learned how to use Mapbox with React. Using Turf, we learned how to do spatial data analysis in order to gain more insights into our data. For many of our members, this was our first time using JavaScript so we learned a lot about the language. We also learned how to use AWS to host our website.
What's next for Crash Central
In the future, we hope to use route generation software that avoids accident hotspots with an easy-to-use UI. We also plan to implement data for new types of transportation like scooters as they appear in datasets. Also include pedestrian, bike, and car traffic to find the relative danger levels for different areas. For example, 1 crash out of 10 crossings = 100 crashes out of 1000 crossings so they should have the same level of danger, but 1 crash compared to 100 is misleading as of right now. We would also like to widely expand the amount of data we have because right now we only have data from DC.
Built With
- amazon-web-services
- chakra
- esri
- geojson
- git
- html5
- javascript
- json
- kmeans-algorithm
- mapbox
- node.js
- opendatadc
- react
- turf
- yarn







Log in or sign up for Devpost to join the conversation.