-
Thumbnail
-
-
Inspiration
Every day, thousands of NGO care coordinators across India face the same impossible question: which hospital should I send this patient to?
India has 10,000+ healthcare facilities in government registries — but those records are self-reported. A facility lists "ICU" in a spreadsheet with no proof. A dialysis center claims 12 machines; no one has verified that since 2019. A family travels 200km based on a record that hasn't been updated in years.
Priya, an NGO coordinator in Nagpur, spends 2 hours per referral calling facilities, getting put on hold, and writing names on sticky notes. We built CarePath India — our submission to Track 3: Referral Copilot — to give her 30 seconds instead.
What It Does
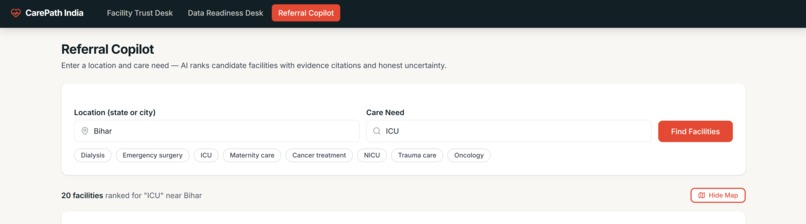
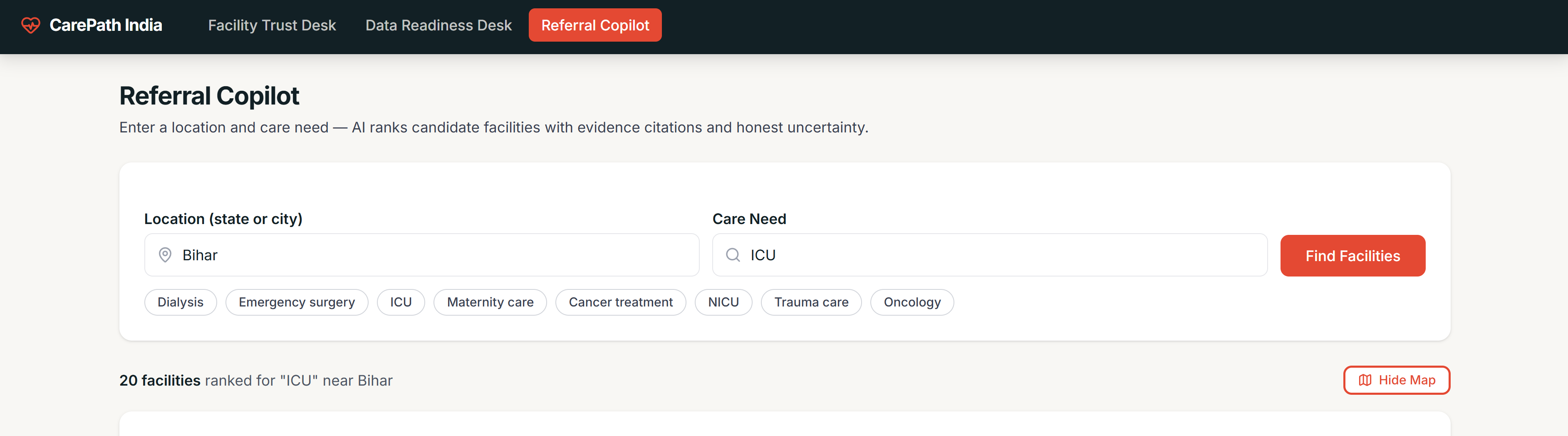
CarePath India is an AI referral copilot that answers the track's exact question: given a location and a care need, where should a patient or coordinator actually go?
- A coordinator types a location (e.g. "Maharashtra") and a care need (e.g. "Dialysis")
- The app queries 10,000 real Indian facility records via a Databricks SQL Warehouse, filtering server-side before any AI call
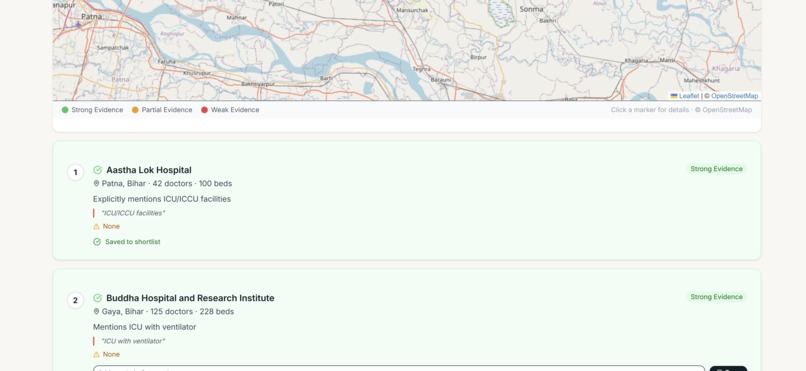
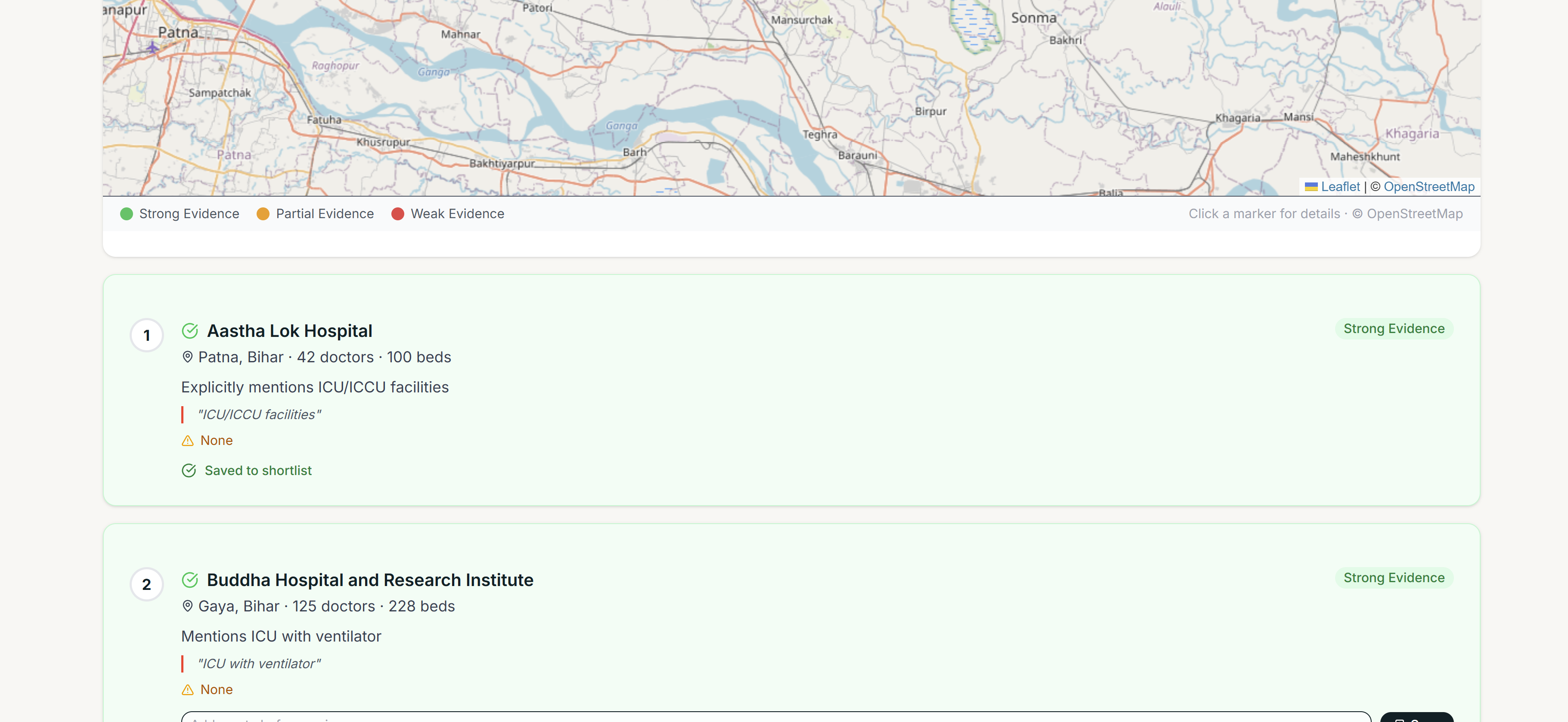
- A Llama 3.3 70B pipeline reads each facility's own description, capability, procedure, and equipment text in two steps: first extracting a verbatim supporting quote (or none, if the claim isn't backed by anything in the record), then classifying evidence strength — Strong, Partial, or Weak — based on whether that quote is corroborated elsewhere in the facility's own fields
- Every ranking shows that exact quote, plus an explicit gap reason when evidence is thin ("primarily an eye hospital, may not have general ICU capabilities") — so the coordinator sees the reasoning, not just a score
- The coordinator saves the best options with notes to Databricks Lakebase, which persists across sessions so the whole care team benefits from one coordinator's legwork
The core insight: the AI cannot hallucinate capabilities a facility never claimed. If the text doesn't support it, the system says so. In a dataset where equipment data is missing for 23% of facilities and capacity data for nearly 75%, treating "we don't know" as a valid, clearly-labeled answer is the difference between a tool coordinators can trust and one that quietly sets them up to fail. A "Weak Evidence" label is exactly as important to us as a "Strong Evidence" one — and when a whole region returns mostly weak or no-claim results, the app says so explicitly rather than dressing up a data gap as a care gap.
How We Built It
Full Databricks stack:
- Databricks Apps — hosts the entire app (React frontend + Express backend) with a single
databricks apps deploycommand - Unity Catalog / SQL Warehouse — server-side
WHERE state LIKE '%maharashtra%'query filters 10,000 facilities before any AI call; candidates returned in under 2 seconds - Model Serving Endpoint —
databricks-meta-llama-3-3-70b-instructruns a citation-then-classify pipeline per facility: extract supporting text first, classify confidence second, so the label is always anchored to a quote rather than a freestanding guess - Lakebase Postgres — stores coordinator shortlists and notes persistently, keyed so repeat saves update existing entries rather than duplicating them; loaded on every page open so institutional knowledge survives across sessions and across team members
Notable engineering decisions:
- Moved facility search server-side (warehouse
WHEREfilter) after discovering AppKit silently drops responses over ~5MB — 10,000 rows × 1.2KB is 12MB, well past that limit - Built a balanced-brace JSON scanner to extract valid JSON from LLM responses that append explanatory text after the closing brace
- Medical term alias expansion (ICU → "intensive care unit", "critical care") so searches work even when facilities use full terms instead of abbreviations
- Leaflet map with Nominatim geocoding centers on the searched location, not just the average of result coordinates, so sparse-result regions still render a sensible map view
safeStr()helper to handle AppKit's auto-JSON-parsing of string fields, since several columns in the raw dataset store JSON arrays as text
Challenges
- Data messiness: 10,000 real Indian facility records with JSON arrays in text fields, inconsistent state name spelling, numeric values stored in string columns, and missing GPS for a meaningful share of records.
- LLM rate limits: Switched from a 120B to a 70B model and added 3-retry exponential backoff on 429s to keep the demo path reliable under load.
- Lakebase permissions: AppKit uses on-behalf-of (OBO) tokens in request handlers — tables created by the Service Principal needed explicit
GRANT ALL PRIVILEGES TO PUBLICat startup before user writes would succeed. - AppKit response limits: Discovering the silent 5MB drop took longer than fixing it — the real fix was rethinking where filtering should happen (warehouse, not browser) rather than patching around the symptom.
What We Learned
A keyword filter alone can't be trusted on self-reported medical text, so we didn't rely on one. Facility descriptions don't follow a fixed vocabulary — "dialysis," "haemodialysis," "hemodialysis," and "renal replacement" can all describe the same capability, which is why our search expands aliases before filtering. But alias lists are never complete, so when the keyword filter returns nothing for a given state, the system falls back to sending all of that state's facilities to the model and letting it judge relevance from the full text rather than requiring an exact match. The tradeoff is slower, more expensive calls in exchange for never returning an empty result to a coordinator who has a real patient waiting.
Databricks Lakebase is genuinely the right tool for OLTP user state in an Apps context. A shortlist that persists across sessions and updates in place, rather than disappearing on refresh or piling up duplicates, isn't a demo feature — it's what makes this a tool a coordinator would actually adopt instead of going back to sticky notes.
Built With
- databricks-lakebase
- databricks-model-serving
- databricks-sql-warehouse
- express.js
- leaflet.js
- llama-3.3-70b
- node.js
- openstreetmap
- react
- tailwind-css
- typescript
- unity-catalog
- vite

Log in or sign up for Devpost to join the conversation.