





Inspiration
On average, more than 450,000 children are reported missing annually in the United States alone. This alarming and frankly unbelelievable statistic was our inspiration for BT Tracker, because we felt that with the versatile application of technology, we could stop these events as and before they are happening. BT Tracker creatively applies GPS technology, cell phones' built-in magnetometers, crowd-sourced data, and the physical capability of an inexpensive Bluetooth beacon to localize the position of a lost kid or even a lost pet so that rescuers can start looking and find the child before it is too late. With this combination of the technological capability of our commonplace devices and a unique data structure on the server-side, BT Tracker can provide parents and guardians a practical and affordable solution to a shockingly commmon problem.
Features
Security
Share your child's unique beacon ID with your loved ones - only they will be able to access your child's data, and this increases the search capability and calculation accuracy of the algorithm running behind the scenes. However, only those with the unique code will be able to access the output of the localization algorithm.
Speed & Accuracy
Within a couple seconds, the algorithm behind the scenes can pinpoint the most likely position to within a couple meters - more than enough time and precision for an alert rescuer.
Accessibility
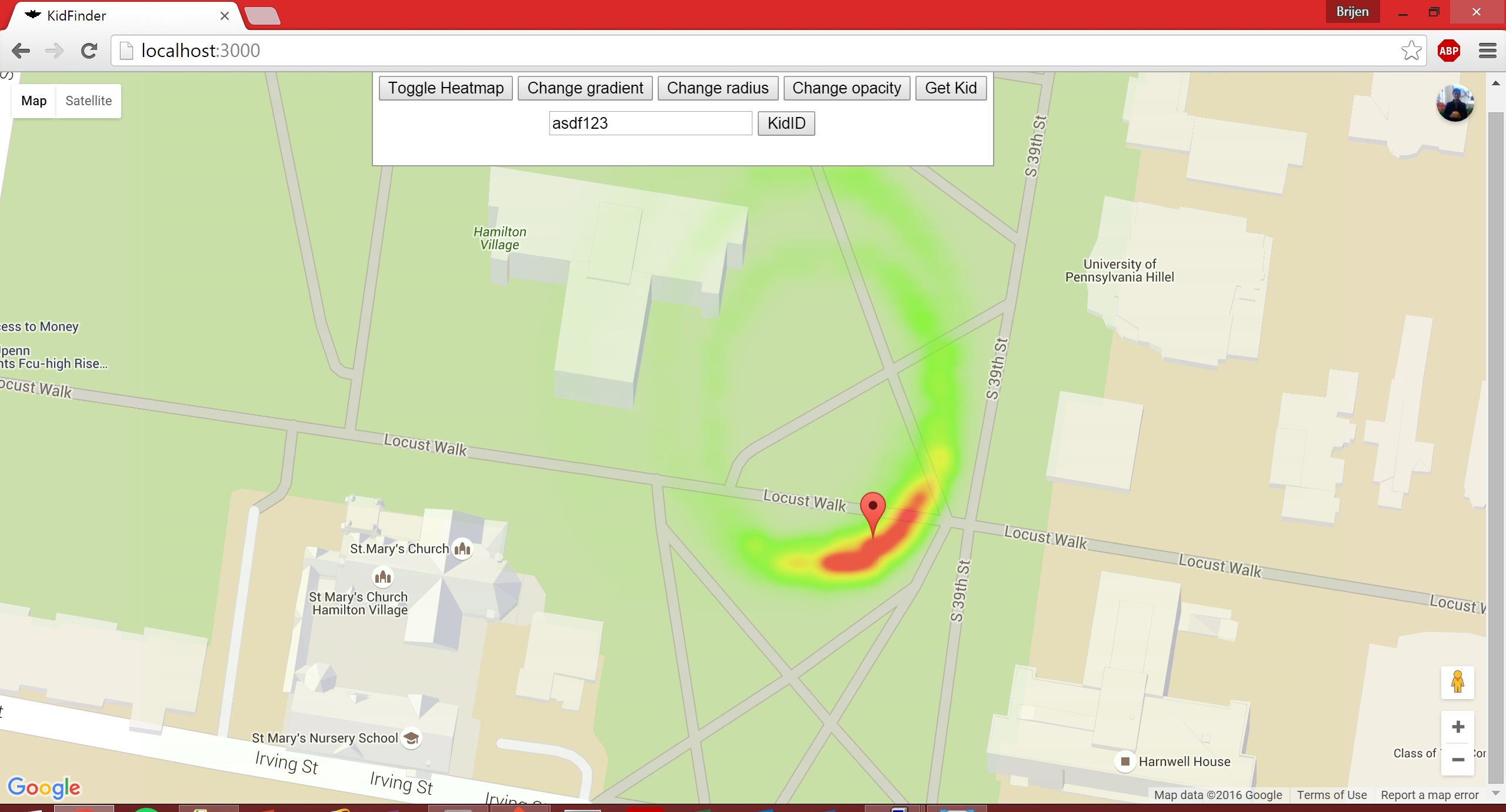
With just your child's ID, you and your loved ones can visualize the localization process in a crisis from wherever you are - from your phone on a mobile platform, to your laptop on a web interface using Google's Maps API and LFHeatMap.
Real-time Updates
The mobile and web platforms update frequently to return heatmaps illustrating the discrete probability distribution of where the missing child is most likely to be and the heading that the user should head toward. This provides users with the most accurate and most recent data, which we believe is of the utmost importance.
Technology & Theory
The Stack
This project is hosted on an Amazon EC2 Linux AMI t2.micro instance, and uses NGINX as a reverse proxy to redirect HTTP traffic to our application, which is powered by the MEAN stack.
The Localization Algorithm
The data structure we implemented and manipulated to perform our localization calculations without GPS location of the child and noisy sensor readings of the Bluetooth beacon was the Hidden Markov Model. In a traditional Markov Model, we know the current state and how states transition to other states, which we can use to make inferences. In our case, we never know the position of the child directly, so we must make inferences based on our evidence variables (the noisy sensor distance readings) to infer the probability of an unknown state. Using this and along with our crowd-sourced data, we can easily make our distribution of potential locations converge to a centralized peak. Typically exact inference algorithms on Hidden Markov Models are used with relatively small distributions, but we wanted to make our search area large. So, we are running a Markov Chain Monte Carlo algorithm called Particle Filtering so that our inference runtime is fast but also correct. This algorithm is typically used for robot localization, but we realized that it had a wide range of purposes in our project. The algorithm both accounts for noisy input and simulates the movements of missing children and is unaffected by the movements of the tracking individuals.
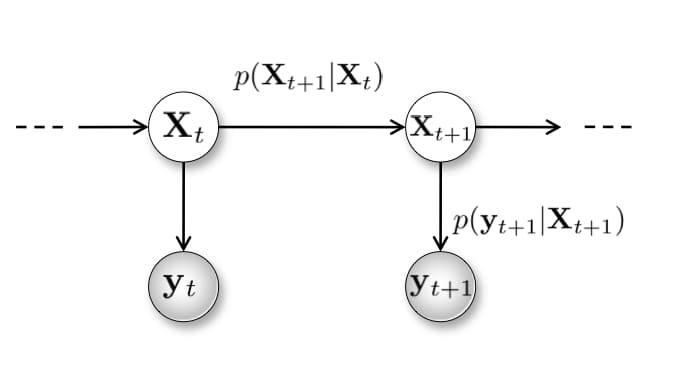


The Filtering Algorithm
The Bluetooth beacon we are using is small and was selected in its cheap cost in mind. Furthermore, Bluetooth is not designed for location or distance tracking purposes, so we had to work with the SDK and run experiments to extrapolate distance measurements from signal strength. For this reason, however, we were receiving extremely noisy data with random fluctutations. While the algorithm on the server-side was designed with a simple model of how noisily we expected the sensor to behave, we wanted to do better. So, we passed our data through an averaging, causal, BIBO-stable, discrete-time, low-pass filter to stabilize our readings and make sense of the noise before we sent them through the server.

Challenges
In our intentionally cheap implementation of this solution, we predictably came across a handful of problems. The biggest problem was that GPS signal of our phones is extremely unreliable and spotty indoors. To confront this issue, we used the phone's magnetometer in conjunction with the Indoor Atlas SDK, which is designed to map indoor locations using the unique magnetic signature of positions based on the ferromagnetic composition of a building's internal structure. This fix worked fairly well and phones' magnetometers are surprisingly well-endowed, but in large open locations that are also indoors, it is still somewhat difficult to distinguish between locations because of the more uniform ferromagnetic composition of positions. Secondly, not very many locations are mapped using this method yet, so we had to manually map all of the indoor locations where we tested the application. The second problem was that our beacons are very cheap so that they can be practical and affordable solutions, but this means we needed a way to make sense out of our data which was predictably unintelligably noisy before processing. To fix this, we passed the discrete-time signal through a digital filter as detailed above. Another challenge was the sheer amount of computing that our algorithm would need to perform, but this was handled above using a probabilistically correct algorithm that we modified from its normal purposes.
Potential
We believe that BT Tracker has the potential to prevent tragedies from happening before they occur. However, our work and experimentation have also highlighted some areas we could focus on in the future to improve performance. With improvements in hardware choices including beacons focused on transmit power, the quality of our data can only increase which increases our capacity to perform meaningful calculations on it. The strength of this application can increase incredibly with an increased userbase, because of the way in which data is crowd-sourced in order to perform calculations. The more points we have to triangulate from, the more easily we can pinpoint location and the larger the area we can search. Lastly, with better and more common magnetometer mapping of more locations using services such as the Indoor Atlas SDK, we can better use our app in indoor locations.

Log in or sign up for Devpost to join the conversation.