-
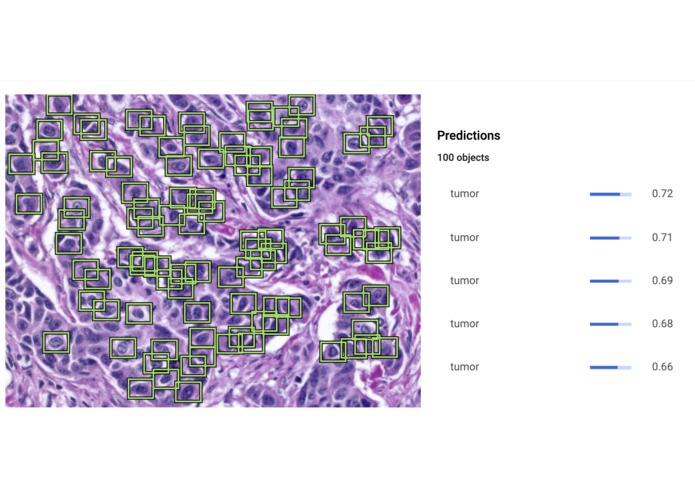
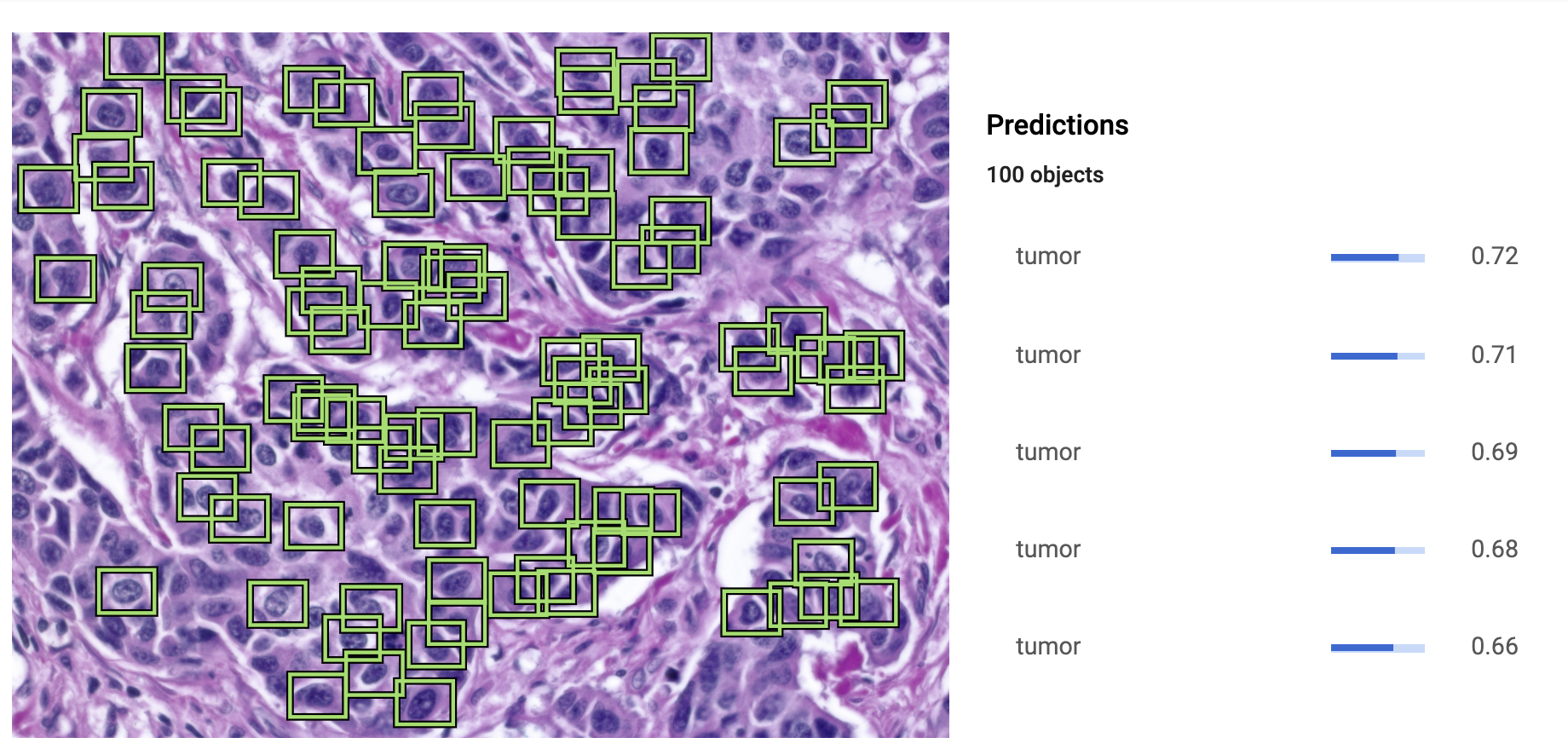
Trained model recognizing tumors, lumen, and more.
-
Homepage
Inspiration
Medical imaging, in this case histopathological tissue images, is generally incomprehensible to a layperson, even though these tissue images are extremely vital in diagnosing breast cancer and estimating the aggressiveness of the cancer. To even begin understanding these images and ensuring thorough, accurate diagnoses requires second opinions from multiple gold-standard pathologists and doctors who can manually identify tumor types and grades, which is oftentimes financially unsustainable and also inefficient for medical practitioners with many patients.
What it does
Bean provides an effective way for individuals with little to no medical experience to understand histopathological tissue imaging for breast cancer, reducing economic costs associated with having to get many second opinions as well as informing the patient about their condition in a straightforward manner. It analyzes the cancer grades and therefore the aggressiveness of the cancer using a modified Nottingham grading system, and identifies and analyzes the tissue as benign or malignant based off of nuclear pleomorphism, tubular formation, and mitotic count. The images are annotated in a way such that a layperson can understand the issues present in the images in a clear and efficient way.
How we built it
We used Flask to build the web app, along with a combination of HTML/CSS/JavaScript. We use Google Cloud to train a machine learning model that is capable of regional classification. Then, using REST API, we integrate the model with our web app, creating a seamless experience for the user to upload images and analyze histology images.
Challenges we ran into
It was difficult to find a sufficient data set in the time that we had, because most medical images are only partially publicly available to preserve patient privacy. We ran into challenges training our model and connecting the front-end and back-end. We were also initially unfamiliar with Google Cloud and how to use it. Also, at first, we were unable to run the web server and implement Flask to create the app.
Accomplishments that we're proud of
Our model is trained to be 78% accurate, which, although is not extremely high, is impressive given the amount of time (< 1 day) of training and lack of pre-processing data. While we achieved this accuracy using Google Cloud's ML toolkit, we believe that we can achieve higher values in the future through original research. In addition, we are proud of how robust our software is. Not only is it able to point out individual cells, but it is also able to point out the type of tumor, lesions, and frequency of mitotic events.
What we learned
This experience proved to be a challenging feat for us. All of us came in with barely any background in medical imaging, and it was our first time utilizing a machine learning based cloud software. As a diverse team, our group split into groups of two: front-end and back-end for figuring out how to improve the UI/UX and getting the machine-learning based model to work, respectively. After working for a weekend, we learned about how we can all come together in software engineering from our diverse background, and how the diversity in thought between us sparked innovation and creativity.
What's next for Bean
In the future, we hope to expand Bean to medical practitioners as well as the current audience of laypeople, because not only would an accurate model that effectively and efficiently reads histopathological images reduce costs, it would also make an accurate diagnosis more efficient and available to more people. With more time and data, we could also perfect our model and make it even more accurate, as well as implement more precise grading techniques.


Log in or sign up for Devpost to join the conversation.