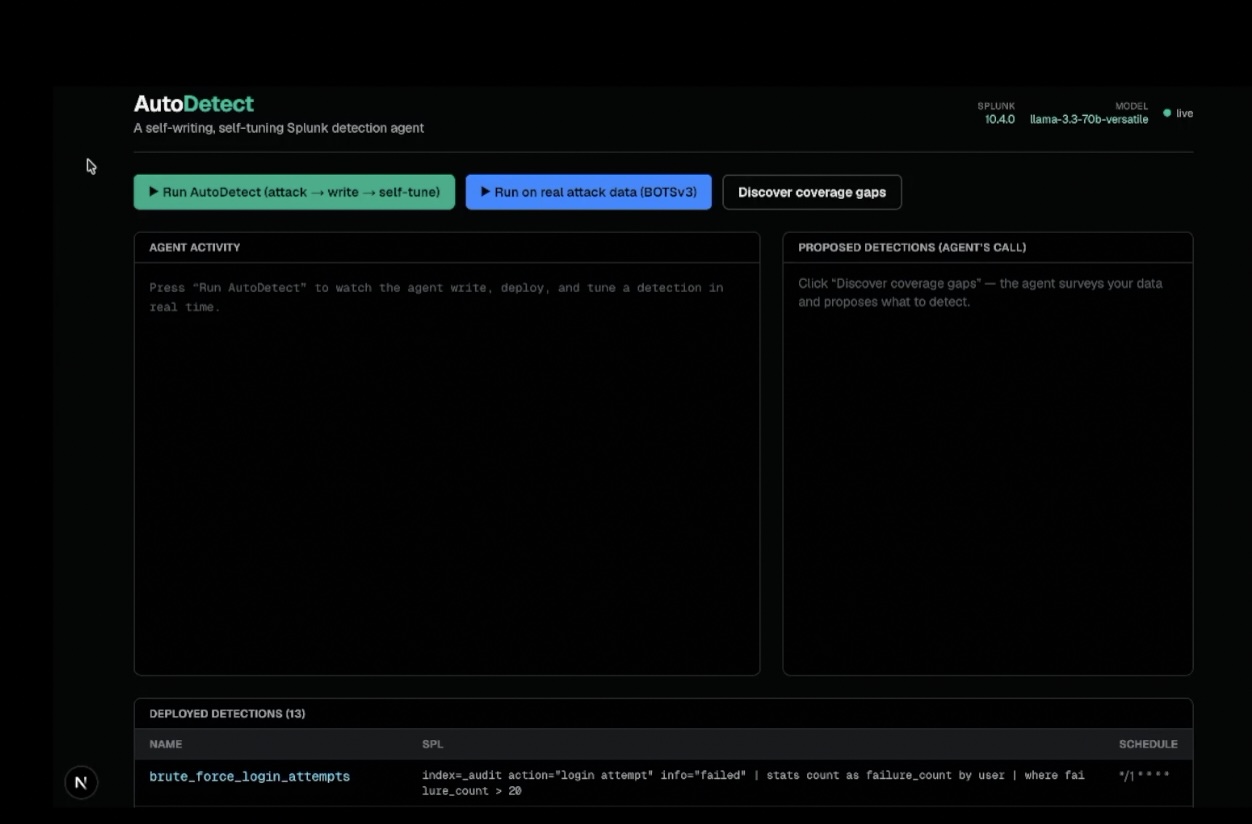
AutoDetect
Inspiration
Detection engineering is one of the most painful, never-ending jobs in security. Attackers have thousands of techniques; teams can't write tripwires fast enough to cover them, and the rules they do have quietly rot they break when systems change, or they start firing on harmless activity until everyone ignores them. A tripwire that cries wolf is how real attacks get missed.
Almost every "AI + security" demo we'd seen was a chatbot that helps a human investigate faster. The hackathon was literally named Agentic Ops, so we wanted to build the opposite: an agent that does the tedious, expert work a human can't keep up with -and does it autonomously, end to end. Not "ask the AI about a log," but "let the AI decide what to detect, write the detection, prove it works, deploy it, and tune it - by itself."
What it does
AutoDetect is a self-writing, self-tuning Splunk detection agent. It runs the full loop a detection engineer runs:
decide → author → validate → self-correct → calibrate → deploy → tune
- Profiler surveys the data that actually exists and proposes the highest-value missing detections, each mapped to a MITRE ATT&CK technique.
- Author (an LLM) writes the real SPL, grounded on a per-technique signature playbook so it writes behavioural detections, not naive volume counts.
- Validator runs the SPL against real data — a hard, factual check, deliberately not AI.
- When a rule is invalid, empty, or noisy, the agent reads what went wrong and rewrites its own rule, calibrating thresholds against the real data distribution.
You watch the whole thing think, live, in a dashboard.
How we built it
We built in thin, verified slices, always de-risking the scariest thing first.
- Prove the agent can actually change Splunk. Before anything else we wrote a connection test to confirm our code could create a real detection via the Splunk REST API. If it couldn't, the whole idea was dead. It passed — green light.
- One detection, end to end. The agent wrote a detection for a simulated brute-force attack, validated it, and deployed it. This proved the spine.
- Make it self-improving. We added the two things that make it genuinely agentic:
self-correction (fix invalid SPL from the Splunk error) and a Tuner that
measures false positives and raises the threshold until only the real attacker is
caught — e.g. lifting a rule from
> 5failures to> 10to stop alerting on forgetful users. - Let it decide for itself. The Profiler proposes the targets, so we don't even hand it a goal.
- Ground it in reality. We ran it against Splunk's BOTSv3 "Boss of the SOC" breach dataset — millions of real events — not just synthetic data.
- Make it visible. A FastAPI backend streams every agent step over WebSockets to a Next.js dashboard, so you can watch it reason and correct itself.
The architecture is four layers — Browser → FastAPI → Agent → Splunk — with the LLM as a swappable brain behind an OpenAI-compatible client. The agent's two hands and eyes on Splunk are deliberate: the REST API does all the writing (create, tune, deploy detections), and the MCP Server is the AI-native reading interface.
Challenges we ran into
The hard part wasn't writing SPL once — it was getting the agent to write SPL that's correct, not just valid. A rule can run cleanly and still be completely wrong.
Thresholds borrowed from the wrong quantity. Our first data-aware version measured "events per host," then the model reused that number as a byte threshold in a different detection — flagging 100 results at a meaningless 28 KB bar. The fix: the agent now measures the real distribution of the exact metric it thresholds on, computed through the detection's own pipeline — so the number is never borrowed from a different quantity.
A silent Splunk gotcha. Our calibration query kept returning zero rows. The cause: Splunk hides any field whose name starts with
_, and our aggregation aliases used__. The whole result was being dropped silently. Renaming the aliases fixed it — a one-character bug that cost real debugging time.Thresholds above the maximum that exists. The model would set a bound above the data's max, guaranteeing zero hits forever, then climb higher on each retry. We made the agent calibrate against the true range and never propose an impossible bound.
Over-constrained detections. A strong model writes ambitious rules — four conditions ANDed together. But ANDing several independent "top 5%" thresholds is nearly unsatisfiable: $0.05^4 \approx 6\times10^{-6}$, so the intersection is empty and the rule catches nothing. We taught the agent to keep one primary threshold near $p_{95}$ and loosen or drop the rest.
Hitting the daily token wall. Each failed retry re-sends the full prompt; a spinning loop burned through a free-tier daily token cap mid-build. We made the loop converge instead of spin, then moved the brain to Ollama Cloud's
gpt-oss:120b— stronger SPL, no daily cap — via a one-line.envchange, thanks to the provider-agnostic client.
The throughline: we engineered against false positives and hallucinated detections. When the agent can't find a genuine outlier, it now says so and deploys nothing — it refuses to ship a hollow or noisy rule.
What we learned
- "Valid" is not "correct." Getting an LLM to produce runnable SPL is easy; getting it to produce a true detection — right field, right metric, right direction (high for volume, low for rarity), a threshold that matches reality — is the whole game.
- Give the model reality, not vibes. The single biggest quality jump came from feeding the model measured distributions from the actual data and letting it correct against them, rather than trusting it to guess thresholds.
- The factual checker has to be non-AI. The Validator's hard "this returned N rows, 3 of them innocent" is what keeps the agent reasoning over reality instead of its own confidence.
- Self-correction is the demo. The moment that makes people lean in isn't a perfect first answer — it's watching the agent run its rule, get zero hits, measure the real data, realize its own number was impossible, and fix itself. That visible recovery is the most "agentic" thing in the whole project.
What's next
- RAG grounding over Splunk's
security_contentso the Author models its SPL on hundreds of production-grade detections. - Ground-truth scoring against BOTSv3's known indicators, to prove a detection caught the documented threat, not just a statistical outlier.
- A multi-agent v2 (Profiler · parallel Authors · Reviewer · Deployer) orchestrated as a LangGraph state machine with checkpointing and a human-approval gate before deploy.
Built With
- botsv3
- fastapi
- gpt-oss
- groq
- llama-3.3-70b
- llm
- mitre-att&ck
- next.js
- ollama
- openai-sdk
- python
- react
- rest-api
- spl
- splunk
- splunk-enterprise
- splunk-mcp-server
- splunk-rest-api
- tailwindcss
- typescript
- uvicorn
- websockets

Log in or sign up for Devpost to join the conversation.