Anchor — A MemoryAgent for SRE incident response
Capture a "golden fingerprint" of a time window when your system was healthy. Later, compare any window against it and get a plain-English narrative of what drifted, why it matters, and which SPL to run next — informed by what the agent learned from every past investigation.
Inspiration
Every on-call engineer has lived through the same five minutes. An alert fires at 2 a.m., you open Splunk, and instead of finding the bug you find yourself asking a more embarrassing question:
"Wait — what does **normal* even look like for this service?"*
We kept watching this happen during our own internships and study-group SREs at UW. The dashboards everyone built didn't actually answer that question. ML anomaly detectors trained on rolling recent data — which meant they had often quietly trained on an already-drifted week. ChatGPT-style prompts could tell you "yes this looks weird," once, and then forget everything the moment the window closed.
We wanted the opposite of all of that:
- A baseline that's a deliberate human choice, not a moving average.
- An assistant that remembers which signals turned out to matter and which were red herrings — across weeks, across incidents, across on-call rotations.
- And an assistant that forgets old opinions on a schedule, so last quarter's flaky deploy doesn't haunt this quarter's pager.
That's Anchor. The name is the metaphor: drop an anchor on a moment when the system was healthy, and every future investigation can drift-compare against it instead of guessing.
It also fit the Splunk + Qwen MemoryAgent track exactly — persistent memory, accumulating experience, more accurate decisions across sessions, and timely forgetting of outdated information — so we leaned in.
What it does
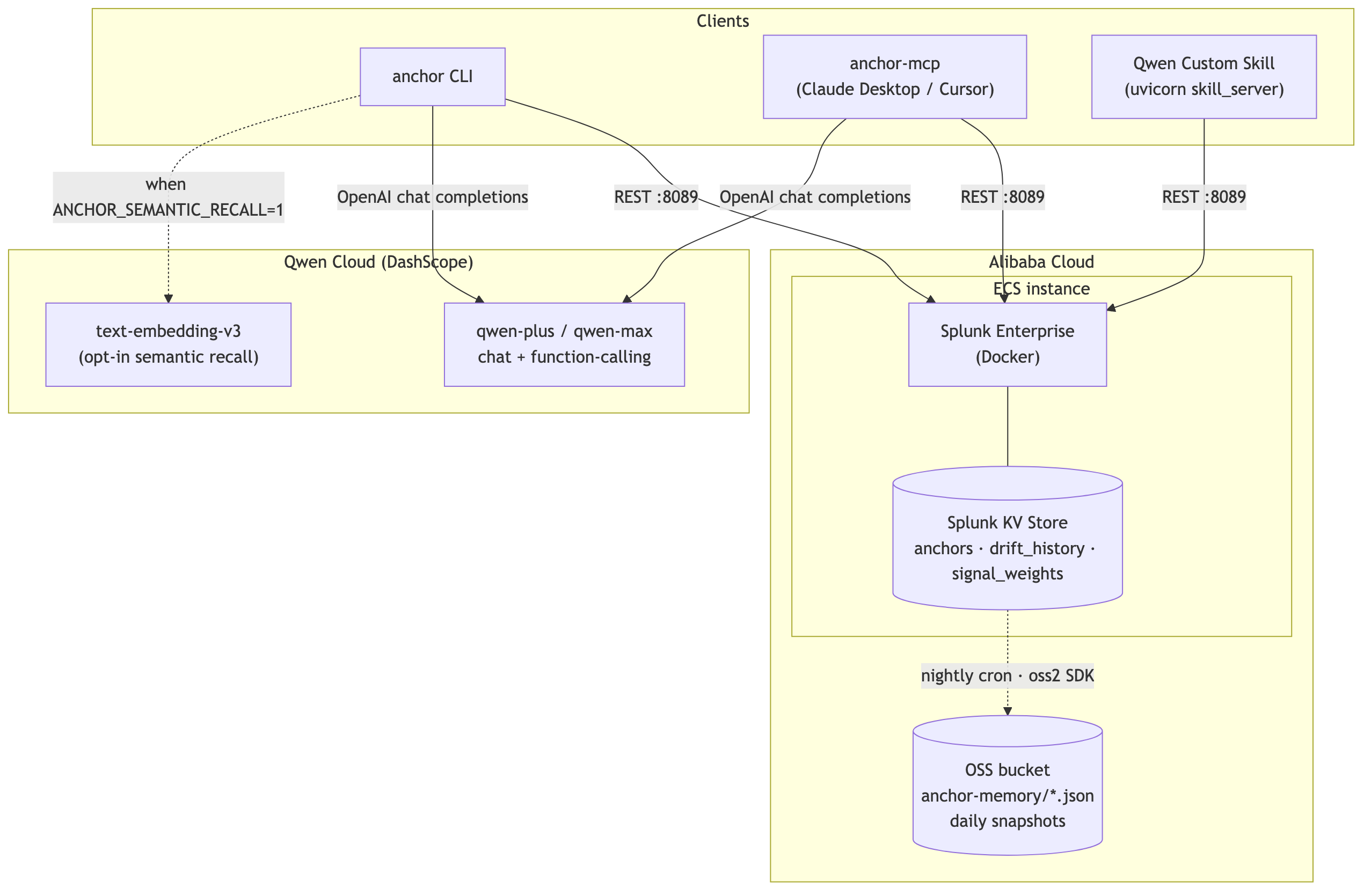
Anchor is a CLI + MCP server + Qwen Custom Skill — three surfaces, one backend — that turns Splunk's KV Store into long-term memory for an LLM SRE agent.
anchor capture— fingerprints a known-good window (volume, log templates, error rates, metric percentiles, top hosts) and persists it to Splunk KV Store as an anchor.anchor compare— diffs a target window against an anchor, ranks the diffs byseverity × learned weight, recalls the most-similar past incidents, and asks Qwen to narrate it in plain English with a suggested drill-in SPL query.anchor compare --deep— same compare, but hands Qwen a function-calling toolbelt (recall_similar,run_spl,read_drift, …) and lets it run a bounded ReAct loop until it converges on a hypothesis.anchor feedback— engineer marks a drift asresolved/false_positive. This is the one input that mutates the agent's memory.anchor learned/history/blind-spots— introspection commands so you can audit what the agent has actually internalized.
The memory model (the bit that makes it a MemoryAgent)
| Memory | Stored in | Purpose |
|---|---|---|
anchors |
Splunk KV Store | The human-curated baseline. Survives raw-log retention. |
signal_weights |
Splunk KV Store | Per-signal multiplier learned from feedback. |
drift_history |
Splunk KV Store | Every past compare + outcome, with optional embedding for semantic recall. |
The ranking function is intentionally boring and inspectable:
$$ \text{score}(s) \;=\; \text{severity}(s) \;\times\; w(s) $$
where the learned weight \(w(s)\) is updated on feedback and decayed over time:
$$ w_{t+1}(s) = \begin{cases} \min\bigl(w_t(s) + 0.1, 3.0\bigr) & \text{resolved} \\ \max\bigl(w_t(s) - 0.2, 0.1\bigr) & \text{false_positive} \\ w_t(s) & \text{otherwise} \end{cases} $$
…and idle weights drift back toward neutral with a 30-day half-life:
$$ w_{\text{decayed}} \;=\; 1 + (w - 1)\cdot 2^{-\Delta t / 30\,\text{days}} $$
That's the "timely forgetting." A signal that mattered three weeks ago and hasn't been confirmed since quietly gives up its bonus.
Recall of past incidents uses Jaccard similarity over signal sets by default,
with optional cosine similarity over Qwen text-embedding-v3 vectors when
ANCHOR_SEMANTIC_RECALL=1:
$$ J(A, B) \;=\; \frac{|A \cap B|}{|A \cup B|} \qquad\qquad \cos(\mathbf{u}, \mathbf{v}) \;=\; \frac{\mathbf{u}!\cdot!\mathbf{v}}{\lVert\mathbf{u}\rVert\,\lVert\mathbf{v}\rVert} $$
Top-3 similar past drifts get pulled into the LLM context as evidence — never the whole history, so the prompt stays bounded.
How we built it
The shape of the system is "deterministic core, LLM at the edges." The diff
engine, the ranking, the recall, the persistence — all of that is plain
Python, fully testable, and would still work without any model attached. Qwen
only narrates and (in --deep mode) plans.
┌──────────────────────┐ ┌─────────────────────────┐ ┌────────────────────┐
│ anchor CLI / MCP / │───▶│ Splunk Enterprise │ │ Qwen Cloud │
│ Qwen Custom Skill │ │ • SPL fingerprint │ │ • qwen-plus │
└──────────────────────┘ │ • KV Store memory │ │ chat + tools │
│ anchors / drifts / │ │ • text-embed-v3 │
│ signal_weights │ │ (opt-in) │
└─────────────────────────┘ └────────────────────┘
│
▼
Alibaba Cloud OSS
nightly KV snapshots
Stack
- Python 3.11 with Pydantic v2 for the model layer — every record that goes into KV Store is a typed model, validated on the way in and out.
splunk-sdkfor SPL execution and KV CRUD over REST:8089.click+richfor the CLI / report rendering.- OpenAI-compatible Qwen DashScope endpoint for chat and embeddings —
one swap of
base_urland key, no other code changes. - Splunk Enterprise 9.x in Docker for the local sandbox; same image runs on an Alibaba Cloud ECS instance for the hosted demo.
- Alibaba Cloud OSS +
oss2for nightly KV Store snapshots, so the agent's memory survives reimaging the VM. - MCP (
mcpPython SDK) for the Claude Desktop / Cursor integration — eight tools, all thin wrappers over the same memory layer the CLI uses. - FastAPI + uvicorn for the Qwen Custom Skill HTTP shim with bearer auth, registered into Qwen Cloud Application Center via an OpenAPI spec.
Build order
- Modeled the three KV collections and wrote
ensure_collections()so the schema is self-installing on first run. - Wrote the SPL fingerprint extractor with a strict identifier whitelist
(
^[A-Za-z0-9_*\-]+$) — the CLI is the trust boundary, but every user-supplied index / sourcetype / metric field gets re-validated before it's interpolated into SPL. Defence in depth. - Built the diff engine and ranking without an LLM at all. Every test in
tests/test_diff.pyruns offline. The agent has to be useful in airplane mode. - Layered Qwen narration on top. The LLM gets a structured prompt with
ranked diffs and recalled past incidents, and is asked to produce a
summary + hypothesis + suggested SPL. It can cite a past drift
idto explain its reasoning. - Added the feedback loop, the decay function, and the
learned/blind-spotsintrospection commands. - Replicated the CLI surface as MCP tools, then again as a Qwen Custom Skill, so the same memory loop drives all three clients.
- Containerized Splunk, deployed to ECS, wired up the OSS backup cron, wrote the verification scripts.
Challenges we ran into
Splunk KV Store ergonomics. The KV Store is fantastic for "I need a tiny
document database that's already trusted by the SOC team," but the REST
contract is finicky — _key collisions, schema-less collections that still
quietly reject malformed timestamps, the dance between kv_insert and
kv_update. We ended up centralizing every CRUD call through splunk_client.py
and round-tripping through Pydantic so a bad write fails loud and early.
Permissions inside the Splunk container. docker exec defaults to root,
but the Splunk daemon owns /opt/splunk/var/..., so the obvious
splunk add oneshot invocation in our seed script silently failed to ingest
the demo logs on Docker Desktop. The fix was one flag (-u splunk) and one
extra paragraph in the README, but it cost us a debug session we did not
budget for.
SPL injection. Anchor takes --index, --sourcetype, and --metric from
the CLI and interpolates them into SPL. Treating that as untrusted from day
one — instead of "we'll harden it later" — let us ship a defensible threat
model and saved a rewrite. The whitelist regex lives next to the SPL
builders, not three files away.
Making the agent's memory legible. It's easy to build a system that
"learns" and then can't tell you what it learned. We deliberately added
anchor learned and anchor blind-spots before writing the LLM narration,
so a skeptical engineer can always answer "why did it rank this signal so
high?" without reading source.
Keeping the LLM context bounded. Naively, recall could dump 200 past drifts into the prompt and blow the context window the moment the agent gets useful. Top-\(k\) Jaccard with \(k = 3\) is the smallest thing that worked, and the optional embedding path was added behind a feature flag so the deterministic core stays fast and free to run.
Three surfaces, one backend. Late in the build we realized the CLI, the
MCP server, and the Qwen Custom Skill were starting to drift apart. We
collapsed them onto a shared service layer (memory.py, investigator.py,
narrator.py) so a feature added in one surface lights up in the other two
for free. This is the change we're proudest of.
What we learned
- Memory is a product feature, not an implementation detail. The moment we
exposed
anchor learnedandanchor history, our own trust in the agent went up — because we could audit it. We now think of memory introspection as a first-class UX surface, on the same level as the report itself. - Forgetting is as important as remembering. A weight that only ever goes up is a superstition machine. The 30-day decay was a small change with outsized impact on demo quality.
- An LLM is a great narrator and a mediocre source of truth. Putting Qwen after the diff/rank/recall pipeline — instead of asking it to do all four — gave us a system that's debuggable, testable, and still feels conversational.
- Function-calling earns its keep when the tools are small and obvious.
The deep-compare ReAct loop only became useful once we capped it at six
steps and gave it boring tools like
run_spl(query, earliest, latest). - The OpenAI-compatible Qwen endpoint is a superpower for hackathons. One
base URL change and the same agent code that ran against a local model
worked against
qwen-plusin the cloud.
What's next
- Multi-anchor support per service (e.g., weekday vs. weekend baselines).
- A web UI over the same memory layer — the data model is already there.
- Active learning: surface drifts where the agent is uncertain (low recalled-similarity, mid-range score) and prompt the engineer for feedback, closing the loop faster.
- Cross-team memory sharing via the OSS snapshot format, so a fix learned by one on-call rotation can be replayed by another.
Built With
- alibaba
- click
- cloud
- fastapi
- mcp
- openai
- qwen
- rich
- splunk
- uvicorn

Log in or sign up for Devpost to join the conversation.