Inspiration
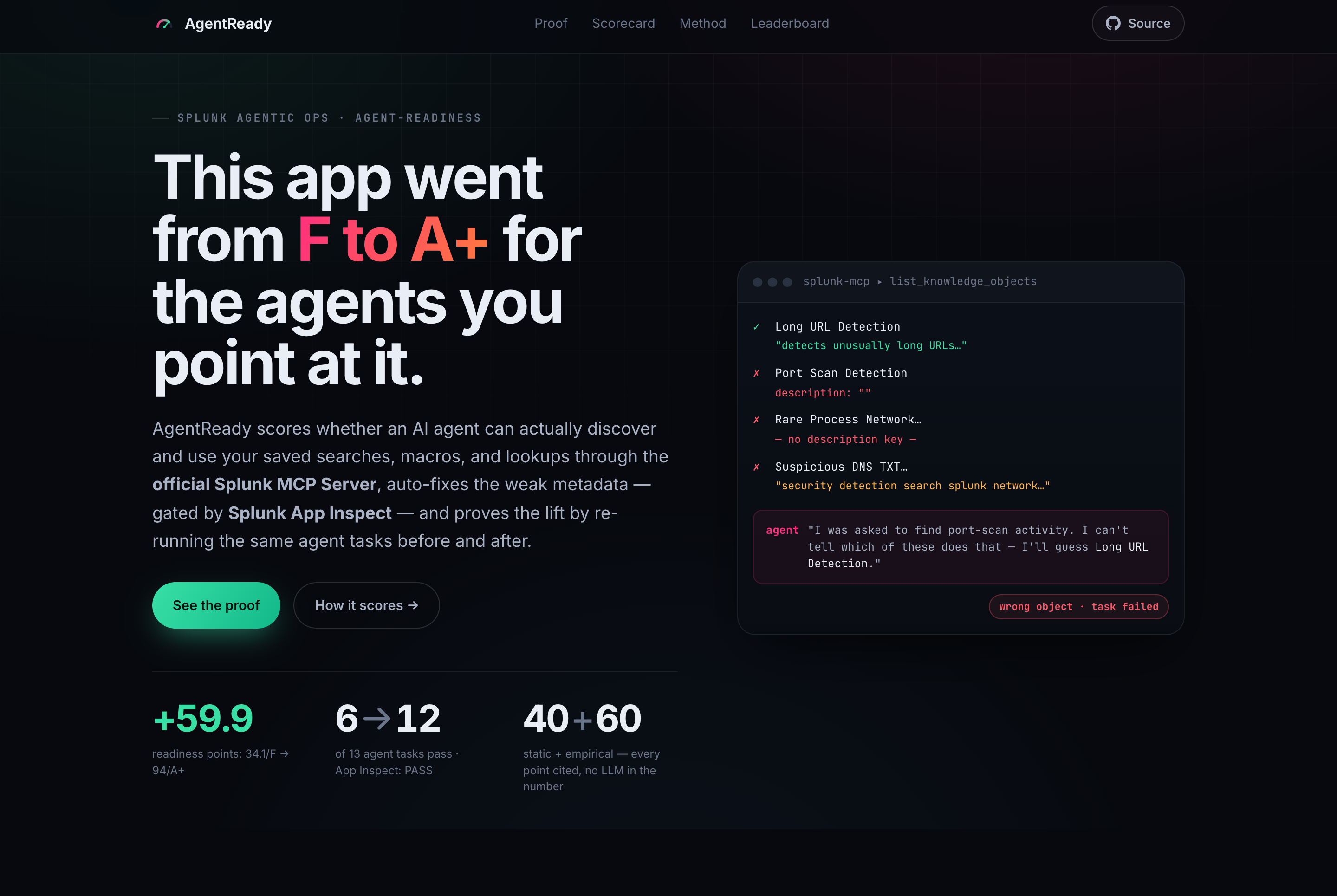
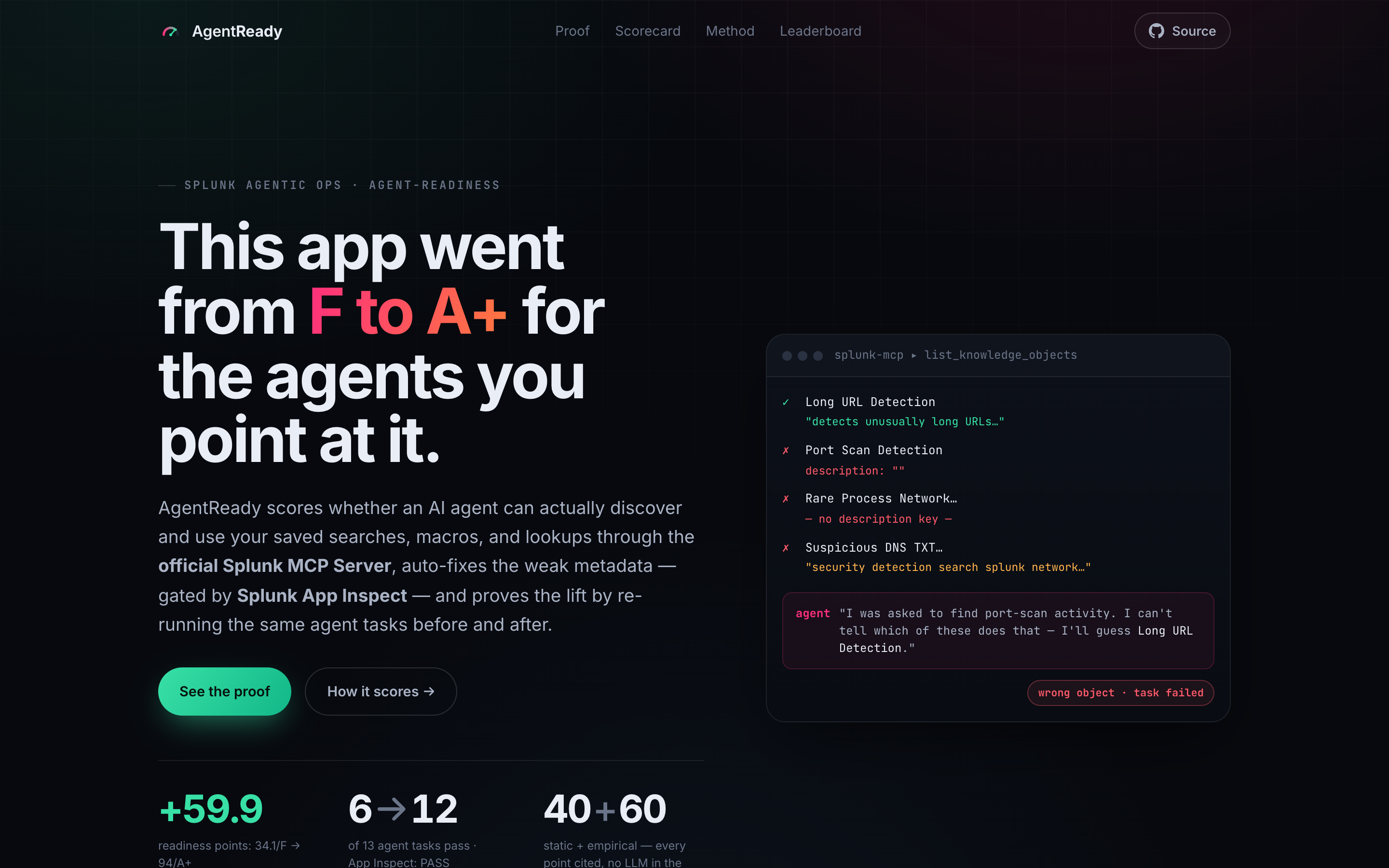
Splunk's official MCP Server is the bridge to Splunk's agentic-ops future: it lets an AI agent discover and run an app's saved searches, macros, lookups, and data models. But agent discovery runs on the description metadata of those knowledge objects — and most Splunk apps ship those descriptions blank or boilerplate.
A saved search with no description runs perfectly for a human who already knows what it does. To an AI agent reaching it through the MCP toolset, it's an unlabeled box: the agent can't find it, can't name its outputs, can't trust it. So the bottleneck on Splunk's agentic future isn't the model and isn't the protocol — it's a wall of empty metadata sitting in thousands of .conf files.
Think of a library where the books have no titles on their spines. A person can pull one off the shelf and skim it. A robot scanning the shelves is completely lost. Splunk gave agents the library and the card catalog (the MCP Server). I built the thing that writes the titles back onto the spines — and proves the robot can now find the book.
What it does
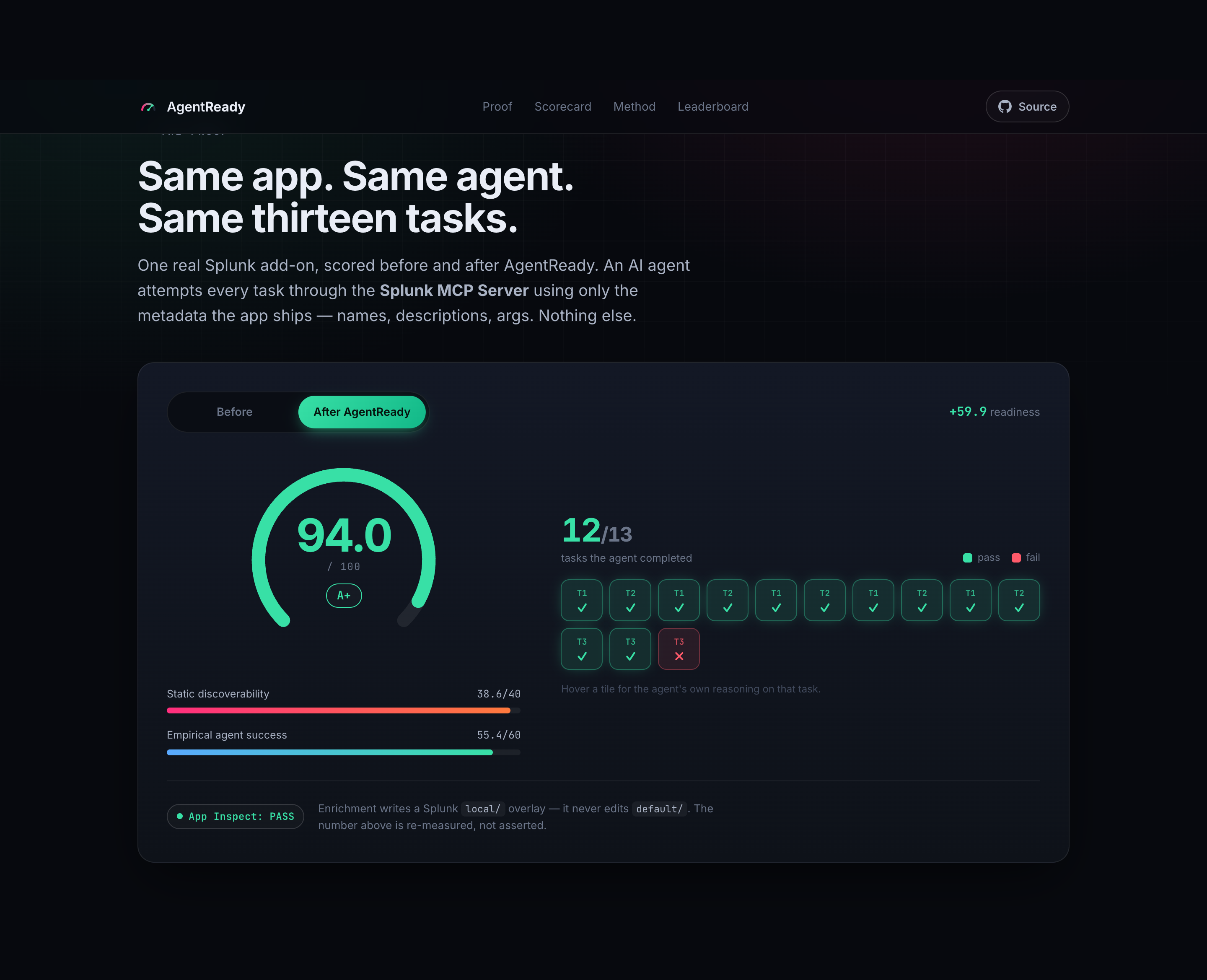
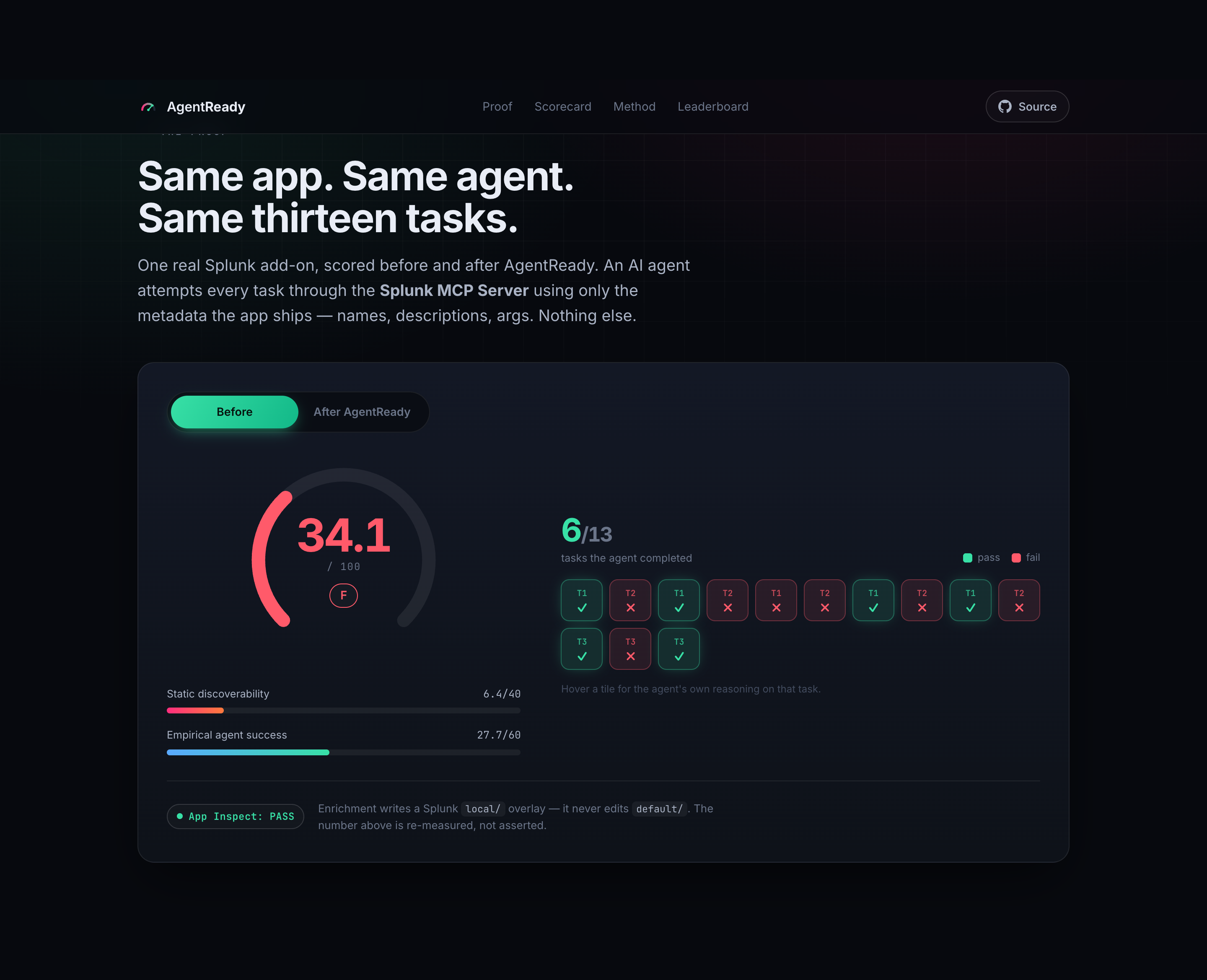
AgentReady scores whether an AI agent can actually discover and use a Splunk app's knowledge objects through the official Splunk MCP Server, auto-fixes the weak metadata (gated by Splunk App Inspect), and proves the lift by re-running the same deterministic agent tasks before and after.
The pipeline, end to end:
- Parse the Splunk app's
.conffiles with correctlocal/overdefault/overlay semantics — the same precedence Splunk itself applies. - Score agent-readiness 0–100, split into two honest halves:
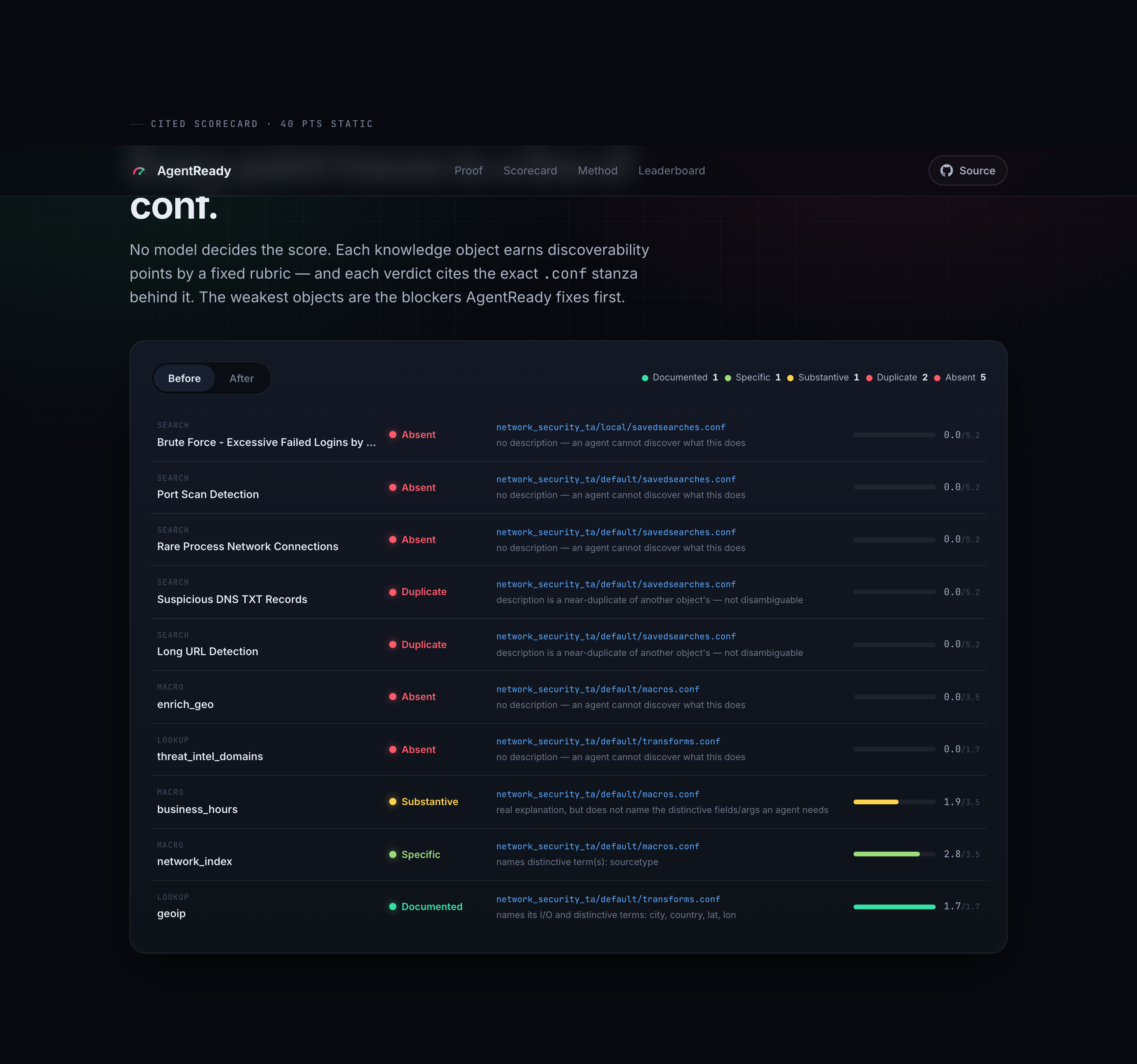
- 40 pts static discoverability — per-object, cited tiers for how findable each knowledge object is from its metadata alone.
- 60 pts empirical — an agent attempts a deterministic, app-derived task suite through the MCP toolset. The score is simply how many tasks it completes. This is the half that can't be faked: either the agent finds and uses the object, or it doesn't.
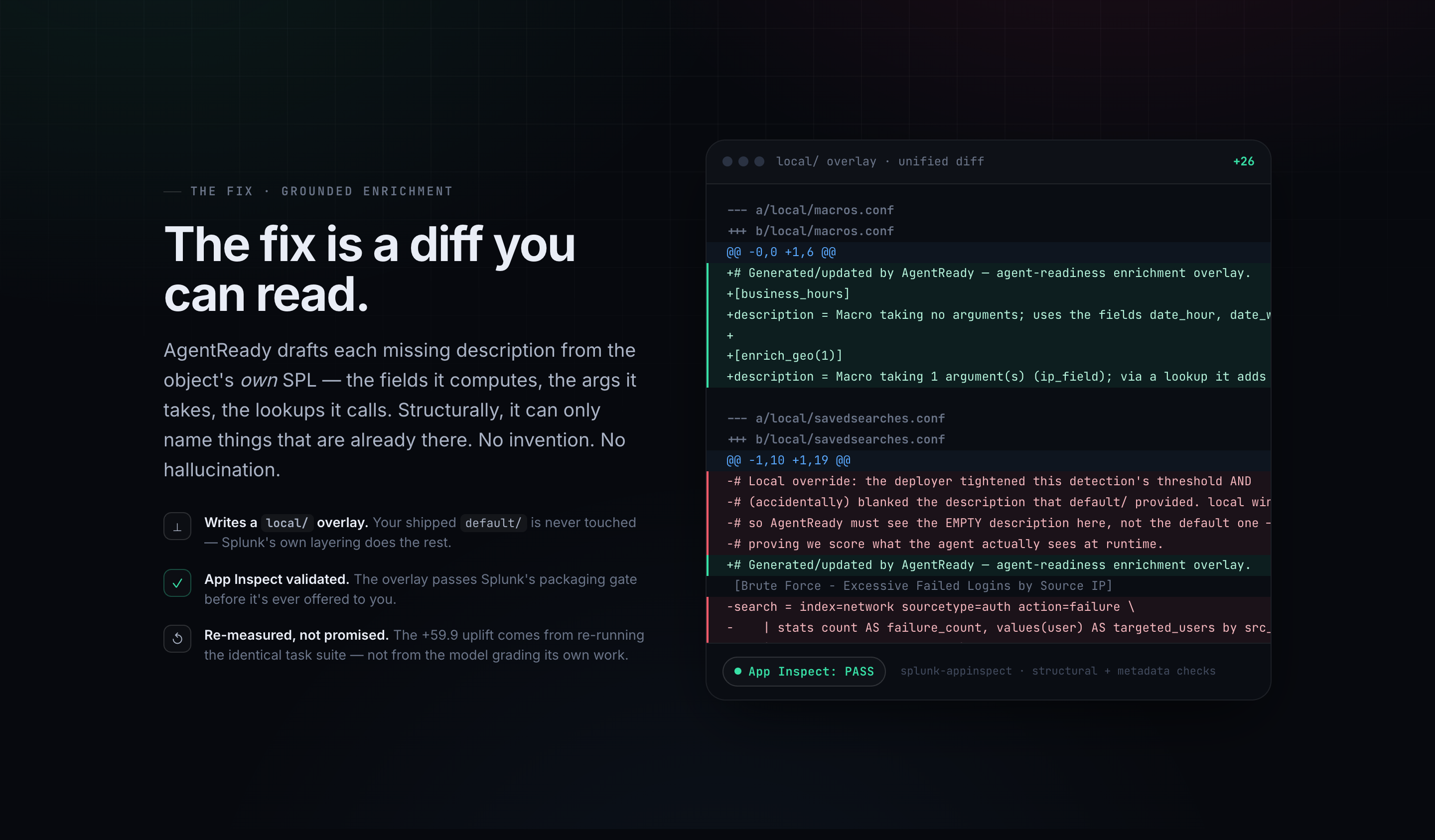
- Auto-draft grounded descriptions for the weak objects. Every field or source a drafted description names provably appears in that object's own SPL — no hallucination — and the fix is written as a reviewable
local/overlay, never a destructive edit. - Gate the fix through Splunk App Inspect, so the output is a package that passes Splunk's own validation (with a deterministic builtin-gate fallback when App Inspect isn't installed).
- Re-run the identical task suite to prove the uplift — the same graders, the same tasks, before and after.
How we built it
This is a solo build. The whole thing is engineered so the central claim survives an adversary trying to break it.
- Python CLI with six verbs:
audit,enrich,prove,evidence,leaderboard,mcp-smoke. Built onpydanticfor typed models andhttpxfor transport. - A JSON-RPC streamable-HTTP client for the live Splunk MCP Server — Bearer-token auth and the full MCP lifecycle handshake. This path is implemented and unit-tested against a mocked transport. It is not yet run against a real live server (see What's next — I'm calling this out plainly because honesty about it is the point).
- Splunk App Inspect as the fix gate, with a deterministic builtin-gate fallback so the pipeline is reproducible even where App Inspect isn't installed.
- A SvelteKit static web console where every figure is baked from a real pipeline run — no hand-typed numbers on the page.
- OpenRouter (Claude Haiku) powers the optional LLM agent and the optional description polisher. Both are off the critical path: the headline number contains no LLM at all.
Splunk pieces named and used throughout: the official Splunk MCP Server (Splunkbase app 7931), Splunk App Inspect, Splunk knowledge objects, and the local//default/ .conf overlay semantics.
It's covered by 153 automated tests and a green CI pipeline (GitHub Actions): tests on Python 3.10 / 3.11 / 3.12, a web build, and a clean-room reproduce job that asserts the headline regenerates and is byte-identical across Python hash seeds.
The headline (deterministic, no API key, runs in CI)
Using a deterministic ReferenceAgent — no LLM in the number, no API key, fully reproducible in CI — the bundled hero fixture goes:
34.1 / F → 94.0 / A+ · +59.9 readiness points · agent tasks 6 → 12 of 13 · Splunk App Inspect: PASS
The after score is a deliberate 12/13, not a perfect 13/13. One generically-named macro (network_index) can't be resolved from grounded signal alone, so AgentReady reports it honestly as unresolved rather than forcing a clean sweep. A tool that can't ever show you its own ceiling isn't measuring anything.
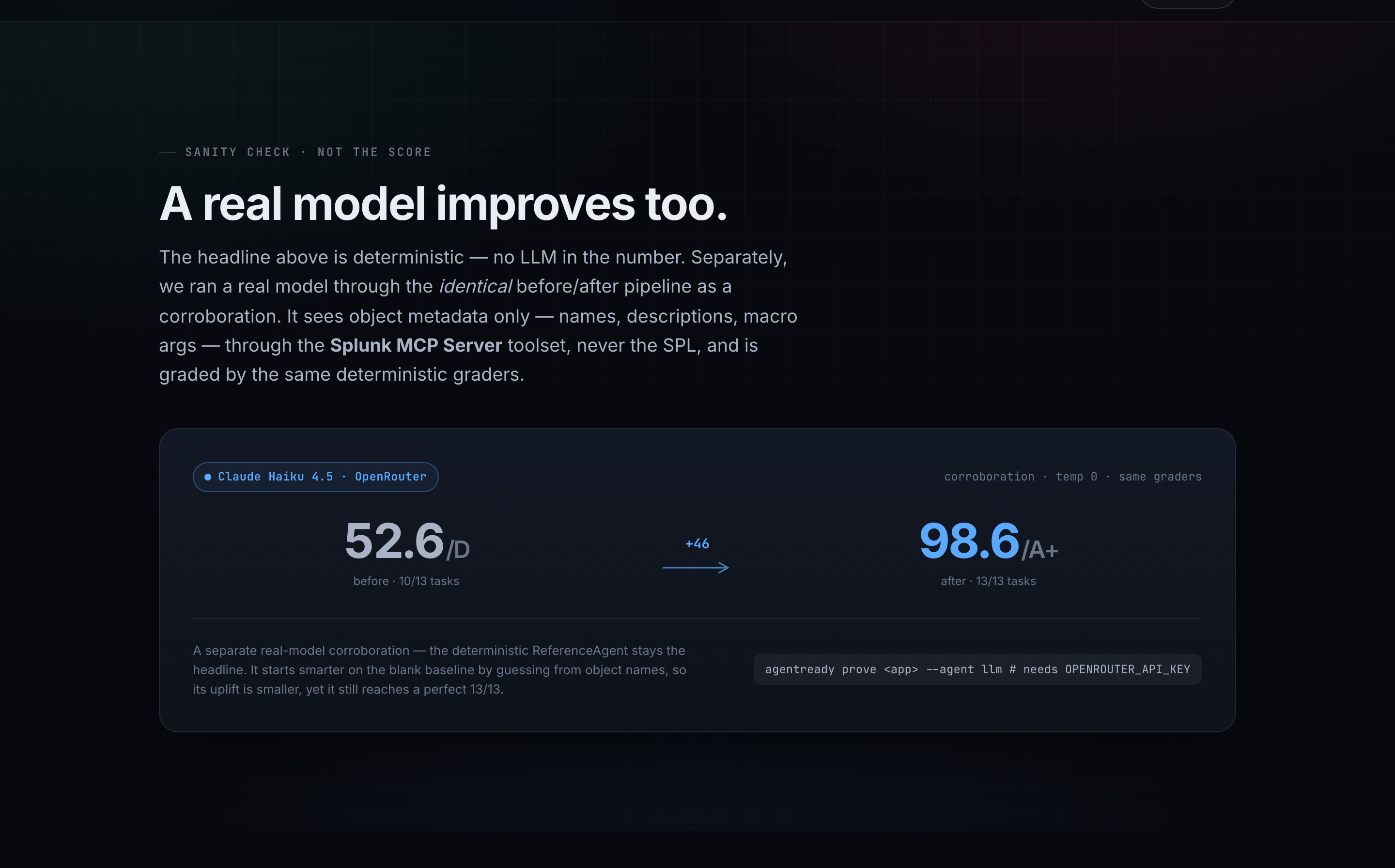
Real-model sanity check (separate — never merged into the headline)
To confirm the lift isn't an artifact of a hand-written agent, I ran a real Claude Haiku 4.5 agent (via OpenRouter, temperature 0, stable across 2 runs) through the same before/after pipeline:
52.6 / D (10/13) → 98.6 / A+ (13/13) · +46.0
Crucially, this real agent sees object metadata only — names, descriptions, macro args — through the MCP toolset. It never sees the SPL, and it's graded by the same deterministic graders as the reference run. A real model independently improving after enrichment corroborates that the lift is real, not a quirk of my own agent. This number lives separately from the headline on purpose.
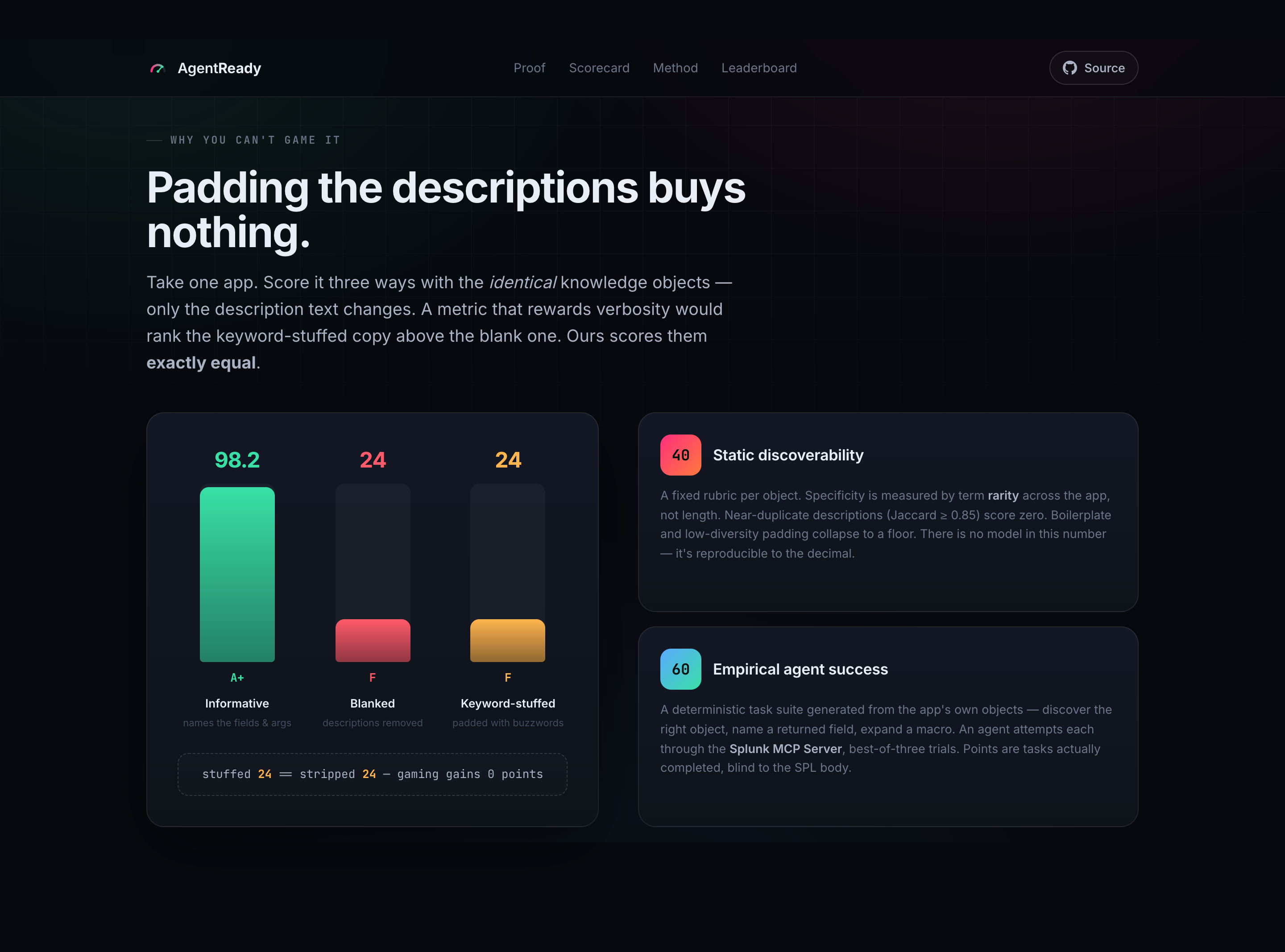
You can't cheat the score
The scorer rewards specificity, not volume. A keyword-stuffed app and an app with its descriptions deleted land on the exact same score — 24.0 — while a genuinely good app scores 98.2. Specificity rewards term rarity; near-duplicate descriptions score 0. Gaming the metric is mathematically pointless.
Challenges we ran into
Three hard problems, all about trust in the number:
Making the empirical proof non-circular. A before/after benchmark is worthless if the test secretly knows the answer. So the task prompts describe an object's purpose and never leak the exact output field or sourcetype the grader checks. The question and the answer are authored by independent code paths — the prompt-writer and the grader don't share the secret.
Making the score un-gameable. I wanted keyword-stuffing to be a dead end, so I designed scoring around term rarity and near-duplicate penalties until a keyword-stuffed app scored identical (24.0) to a blank one. If you can't cheat it, the score means something.
Guaranteeing byte-identical reproducibility. A real bug bit me here: a
set's iteration order leaked into the task prompts, which made the final score depend onPYTHONHASHSEED. The published number could drift between machines. I fixed the ordering and locked it in CI, so the headline now regenerates byte-for-byte on a judge's machine.
Accomplishments that we're proud of
- A readiness score that is adversarially honest: you can't cheat it (24.0 == 24.0), it never hides its own ceiling (12/13 by design), and it reproduces byte-for-byte across machines.
- A decircularized empirical benchmark where the question and the grader genuinely don't share secrets.
- A headline that needs no API key and no LLM to verify — yet a real Claude Haiku agent independently corroborates the lift through the identical pipeline.
- 153 passing tests and CI that fails if the headline ever stops reproducing.
- An offline evidence pack that lets a skeptic audit the whole claim without trusting my environment
What we learned
The hardest part of a "we improved X by Y%" claim isn't getting the improvement — it's making the measurement impossible to fudge. Every interesting bug in this build was an integrity bug, not a feature bug: a benchmark that knew its own answer, a score you could stuff, a number that silently depended on a hash seed. Building the scaffolding that makes a metric trustworthy turned out to be most of the work — and the right work. I also learned how cleanly the Splunk MCP Server exposes an app's knowledge objects to an agent, which is exactly what makes the empty-metadata gap so fixable.
What's next for AgentReady
- Flip live validation from pending → validated by running the read-only
mcp-smokecheck against a real Splunk MCP Server. The client is built and unit-tested against a mocked transport; the next step is a real handshake against a live instance. - Broaden knowledge-object coverage to data models and dashboards.
- A CI gate that fails an app's PR if its agent-readiness drops — agent-readiness as a build-time contract, the way test coverage already is.

Log in or sign up for Devpost to join the conversation.