💡 Inspiration
Every SOC has an AI that triages alerts faster. None of them ask why there are too many alerts in the first place.
We kept coming back to one observation: alert fatigue is a symptom, not the disease. The disease is upstream — hundreds of correlation searches that are stale, broken by schema drift, or were never tuned to the environment they fire in. Every agentic-ops tool we looked at was a triage copilot: it ranks, summarizes, and routes the noise. It mops the floor faster. Nobody fixes the faucet.
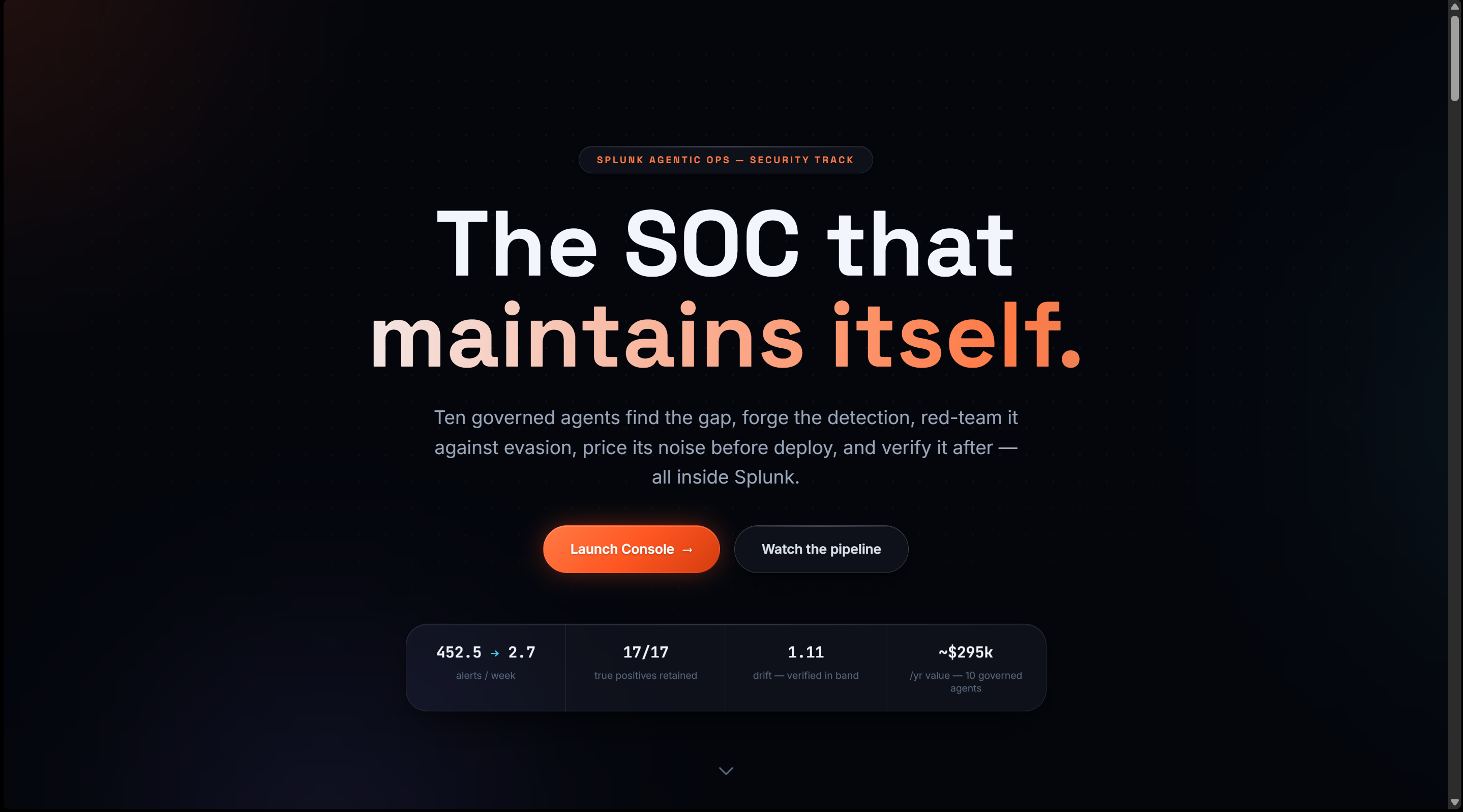
So we asked a different question: what if AI agents didn't just read Splunk — what if they maintained it? What if a swarm of agents could find a coverage gap, write the detection, prove it works, price its noise before it ships, and keep watching it after deploy? That's Aegis Foundry — the SOC that maintains itself.
⚙️ What it does
Aegis Foundry is a ten-agent autonomous detection-engineering pipeline that runs the full lifecycle inside Splunk:
Intel Scout → Coverage Cartographer → Detection Author → Backtest Engineer → Noise Forecaster → Tuning Optimizer → Red-Team → Governor → Deployer → Verifier
A threat advisory comes in; the swarm maps it against the live saved-search
inventory over the Splunk MCP Server, finds an uncovered MITRE ATT&CK
technique (T1059.001), authors SPL, backtests it over 90 days of labeled
history, forecasts its future alert volume with the Cisco Deep Time Series
Model, tunes it under a false-positive budget, red-teams it against evasion
variants, gates it behind an evidence pack + human approval, deploys it as a
native saved search, and verifies post-deploy drift — then books the ROI and
attests the compliance controls it satisfies.
🔬 How we built it
A typed, single-responsibility agent contract. Every agent is
run(state) -> state. They only touch Splunk and the models through
Protocol-typed clients, so the same code runs against deterministic mock
fixtures (offline, judge-friendly) and a live Splunk deployment — a factory
swaps the adapters.
Verifiable by construction, not by trust. An LLM can hallucinate prose; it cannot fake a backtest. Every generated rule must execute and score against labeled ground truth before it can reach a human:
$$ \text{recall} = \frac{TP}{TP+FN}, \qquad \text{precision} = \frac{TP}{TP+FP} $$
Our demo rule retained 17/17 true positives (recall $=1.0$) through tuning.
Forecast-gated deployment. This is the part nobody else does. The Backtest Engineer's raw hit count becomes a weekly rate,
$$ r_{\text{wk}} = \frac{\text{hits}}{\text{window days}}\times 7 = \frac{5{,}818}{90}\times 7 \approx 452.5 \;/\text{wk}, $$
and the Noise Forecaster predicts the future rate (CDTSM, or a deterministic EWMA + day-of-week seasonal fallback):
$$ \hat{y}t = \ell_t + s{(t \bmod 7)}, \qquad \text{band} = \hat{y}t \pm z{0.95}\,\hat{\sigma}_t . $$
The v1 forecast of $\approx 382/\text{wk}$ blew the $25/\text{wk}$ budget, so the gate rejected it before deploy. One tuning pass later: $2.7/\text{wk}$, within budget. Alert noise became a pre-deploy contract, not a post-deploy apology.
A Red-Team gauntlet. Backtest recall only measures the past. Our Red-Team agent mutates the labeled attacks into MITRE-faithful evasion variants (case-folding, flag aliasing, whitespace/argument tricks, payload swaps) and replays them against the rule's own SPL predicate:
$$ \text{adversarial recall} = \frac{\text{variants caught}}{\text{variants total}} = \frac{21}{24} = 0.875 . $$
It honestly flags the one miss (the -enc abbreviation) as a hardening gap.
Provable governance. Every deploy ships an evidence pack + 8 policy checks, and every agent action lands in a tamper-evident, hash-chained audit ledger:
$$ h_i = \text{SHA256}\big(\text{body}i \,|\, h{i-1}\big), $$
so editing any past entry breaks the chain — verify_audit_chain() pinpoints
where.
Quantified impact. The run computes its own ROI from measured numbers:
$$ \text{\$/yr} = \Delta_{\text{wk}} \cdot \frac{m}{60}\cdot c_h \cdot 52 = 449.8 \cdot \tfrac{10}{60}\cdot 75 \cdot 52 \approx \$292{,}374, $$
(alerts avoided/wk $\times$ triage minutes $\times$ analyst hourly cost), plus authoring cost saved — ~\$295K/year on a single rule.
Stack: deliberately Python standard library + vanilla JS (no web
framework, no CDN — judges run it fully offline in 60 seconds), the Splunk MCP
Server (JSON-RPC 2.0), AI Toolkit | ai / | apply CDTSM, Foundation-
Sec-1.1-8B and gpt-oss, an AppInspect-validated packaged app, and an
eleven-view liquid-glass console. 39 tests, CI green, live on Render.
🧗 Challenges we faced
- Making AI output trustworthy. We refused to ship "trust the model." The answer was layering: live syntax validation → labeled backtest → adversarial red-team → policy gate → human approval → post-deploy verification. Hallucinated detections are structurally unable to ship.
- CDTSM is Splunk-Cloud-only. Judges can't all reach it. We built an EWMA +
seasonal fallback that is deterministic and labels itself honestly
(
fallback-ewma) in every forecast, evidence pack, and dashboard — honest degradation, never silent substitution. - Determinism for the demo. A pinned mock SPL dialect and a deterministic forecaster mean the entire storyline ($452.5 \to 2.7/\text{wk}$, drift $1.11$) replays identically, forever, with zero credentials.
- Read/write safety. Agents read via MCP; the only write path (deployment) sits behind the Governor. A compromised authoring agent cannot deploy anything.
- The unglamorous gauntlet: an AppInspect
indexes.conffailure, free-tier cold starts, and chasing every number to be consistent across the README, the console, the docs, and the architecture diagram.
📚 What we learned
- Governance is a feature, not overhead. "Trust as a feature" — evidence packs, rollback tokens, a tamper-evident ledger — is what makes an agent swarm something a real SOC would actually let near production.
- Verifiable-by-construction beats clever prompting. The hardest part of agentic ops isn't the agents; it's making their actions provable and safe.
- Forecasting noise changes everything. Treating alert volume as a quantity you predict and gate on — instead of discover in prod — reframes the whole problem.
- Honest degradation earns trust. Labeling the fallback, flagging the red-team miss, showing the drift — being honest about limits made the project more credible, not less.
🏆 What's next
Multi-technique coverage campaigns, closed-loop self-healing (auto re-tune on drift), Enterprise Security correlation-search integration, live TAXII/MISP intel feeds, and per-environment tuning learned from the cross-run episodic memory we already collect.

Log in or sign up for Devpost to join the conversation.