-
AbstractNet Architecture
Inspiration
Inspired by the continued effort being done over on Kaggle to mine information from all the Covid-19 papers we decided we could also do our part. Based on our previous project Natural Language Recommendations we decided to create another search engine that would encompass biology and medicine instead of computer science. Our search engine has also be trained with all the currently available Covid-19 publication included. We hope our search engine can aid researchers in finding relevant papers within the domain of biology and medicine that can help with finding a cure or a vaccine to the ongoing global pandemic.
Otherwise, our motivation for this project is the same as our last previous project we did for TF 2.1, which you can read over at our Natural Language Recommendations submission.
TL;DR: We all share a belief that with the ever-expanding quantity of research papers being submitted that the issue scientific information retrieval is increasingly becoming important. We need our best and brightest researchers to have the most relevant information presented to them instead of buried by less relevant papers. Giving researchers access to the knowledge specific to their area of research will help shorten the time to discovery and as well accelerate the creation of more impactful technologies. We encourage you to go and read our previous submissions presentation where we've gone more in-depth with our motivation, including examples of when better information retrieval techniques would've helped researchers.
What it does
Our search engine is straightforward, provided a query of interest and it will return to you the papers it deems to be the most relevant to that query. For example, try this query in our demo: "Docking site for covid19"
How we built it
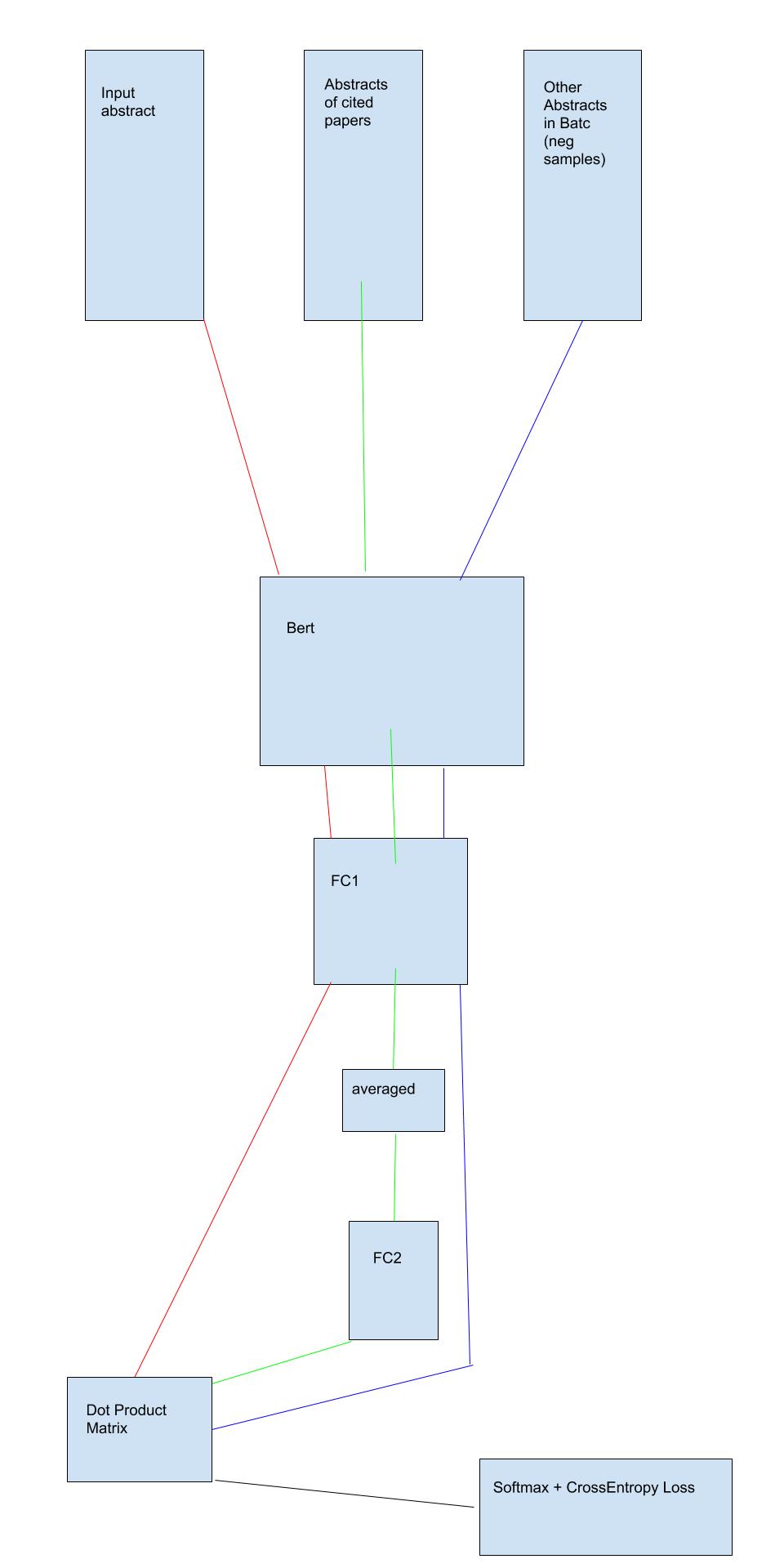
Our model architecture is very similar to our previous project. However, for AbstractNet we are directly linking abstracts to abstracts using the citation networks created by papers referencing each other. Below is our modified architecture.

Specifics
Using the Semantic Scholar’s Open Research Corpus we gathered 30 million papers related to biology and medicine and as well have included all the papers from Allen ai's COVID 19 research paper dataset. We then pass through the abstracts an academic paper cites in their reference section (green path) and the paper abstract itself. The following dense layers (FC1 and FC2) layers are to ensure that BERT will learn what abstracts are similar to each other, while the negative samples that contain some abstracts from randomly sampled papers from our corpus are to reinforce the learning scheme of BERT to create richer embeddings. The target values for our training is 1 for positive samples (abstracts from cited papers) and 0 for negative samples (abstracts from a random paper in the corpus).
Challenges we ran into
With 30 million abstracts comes with a lot of complications with training, arguably the largest issue we had with this project is how to deal with fetching data on disk since loading all the files in memory was impossible for us. However, since our training has multiple components from fetching the abstracts based on the paper ID which we did not at first know which file out ~180 files contained the abstract we wanted to train on for a certain paper.
Another issue that was detrimental to the project state at the time of submission was time, we decided to start this project too close to the submission date which made us rush through the planning phase as well create unneeded stress in trying to find solutions to the new problems we encountered that we did not have in our previous search engine project.
Accomplishments that we're proud of
What we learned
What's next for AbstractNet
Profit
Built With
- huggingface
- tensorflow




Log in or sign up for Devpost to join the conversation.