



Motivation
Scientific information retrieval has been my biggest fascination for several years now (and now some our members share the same interest!), and it started with my research positions in biomedical research, where one of the greatest areas of friction was the difficulty in finding all the research that was relevant to my projects. This is a very common issue with researchers, especially in chem/bio/medical research due to the huge variations in terms and phrasing.
To CS people, I use this example to describe what it’s like searching for information in chem/bio: imagine that StackOverflow doesn’t exist, and there’s no unified documentation for any platform, framework, or library; and all the documentation that’s available has variation in terminology and phrasing. Imagine how slow development is in these circumstances. Imagine what the state of the internet, software, hardware would be under these circumstances. That’s the type of friction that research in chemistry and biology is dealing with right now; the world is missing out on a ton of amazing scientific progress because of this friction.
There were many times where I would stumble upon a very relevant paper, months after I had completed a project it was relevant to. Not only does this type of friction slow down research, it stifles creativity and the imagination towards the goals these researchers have.
The latest advancements in NLP has the potential to significantly reduce this sort of friction. Vector representation of queries and documents reduces the dependency of a particular keyword or phrase for robust information retrieval. Vector representation is already being implemented into information retrieval systems at the highest levels; Earlier this year, Google announced that it is incorporating Bert into its main search engine, affecting up 10% of all search results.
I think the potential for significant acceleration of scientific research makes this field an area very much worth pursuing. I have seen directly what the world is missing out on, and I suggest to anyone who looking for a particular focus in NLP, to consider scientific information retrieval. But you don't have to take my word for it, in 2017 IBM found 96 cases of relevant treatment options in patients that doctors had overlooked
I feel that its import to pursue as many varied information retrieval techniques/models as possible. Although many of these models will overlap, the most import aspect is if a model can find papers that the other models left behind. This becomes increasing important for very difficult topics to search. And often, 1 paper can have a huge impact on the direction of a project.
For the Semantic Scholar Corpus, we found a very unique way of modeling information retrieval. The corpus has citation network data, and abstracts. We were able to correlate text encodings to the citation networks.
One reason for this project is found in our team's composition. Our team is primarily made up of researchers (as well as a high schooler!) from a variety of backgrounds and interests, from material science, chemistry, top tier autonomous vehicles and natural language processing academics. One thing that we had in common was doing research, whether it be for school, work, or passion. In our research experiences, we’ve aspired to push the boundaries of human knowledge in our respective fields of science. However, with the millions of papers related to the numerous fields of science and the ever-increasing amount of papers published every year, we found it difficult to easily find relevant papers to aid in our research goals.
One thing we considered was the current algorithms that we use to find papers for our research. We noticed a level of information overload from hundreds of relevant papers based on different weighing algorithms over text, which can be based on attributes like the number of citations, how often a paper is cited, how recent a paper has been cited, or the journal it was published in. (This is how multiple paper search engines rank papers based on text queries, Ex: Google Scholar). We found that current methods could always be improved to streamline the process and avoid giving the user more info than they could handle.
This was the issue that spurred our desire to create a contextualized search engine for papers to allow researchers (and ourselves!) to use the context of our queries to automatically find relevant papers across multiple fields. With an easier ability to access relevant scientific information, we hope that all researchers can push toward novel innovations and discoveries.
With the context of our queries, our project will allow students, academics, and researchers to find answers in papers even if it's from a different field.
Here's an example we observed: applications and new material discoveries in photovoltaics can be extremely relevant in researching efficient photocatalysts for the treatment of organic and inorganic contaminants in our potable waters.
In all, we want to help humanity push the boundaries of science by allowing researchers to easily and automatically find relevant discoveries to improve their groundbreaking work and innovations.
How we built it
Through cross-continental collaborations between new-found friends of differing levels of expertise and experiences, we came together to tackle a problem we all found to be important.
This project used modern state of the art natural language architectures that have been easily made available through huggingface’s Keras implementation of Bert. In addition, we had to come up with our own solutions such as our preprocessing filters through the Semantic Scholar API and our word2vec model and our custom-built library tpu-index.

Specifics:
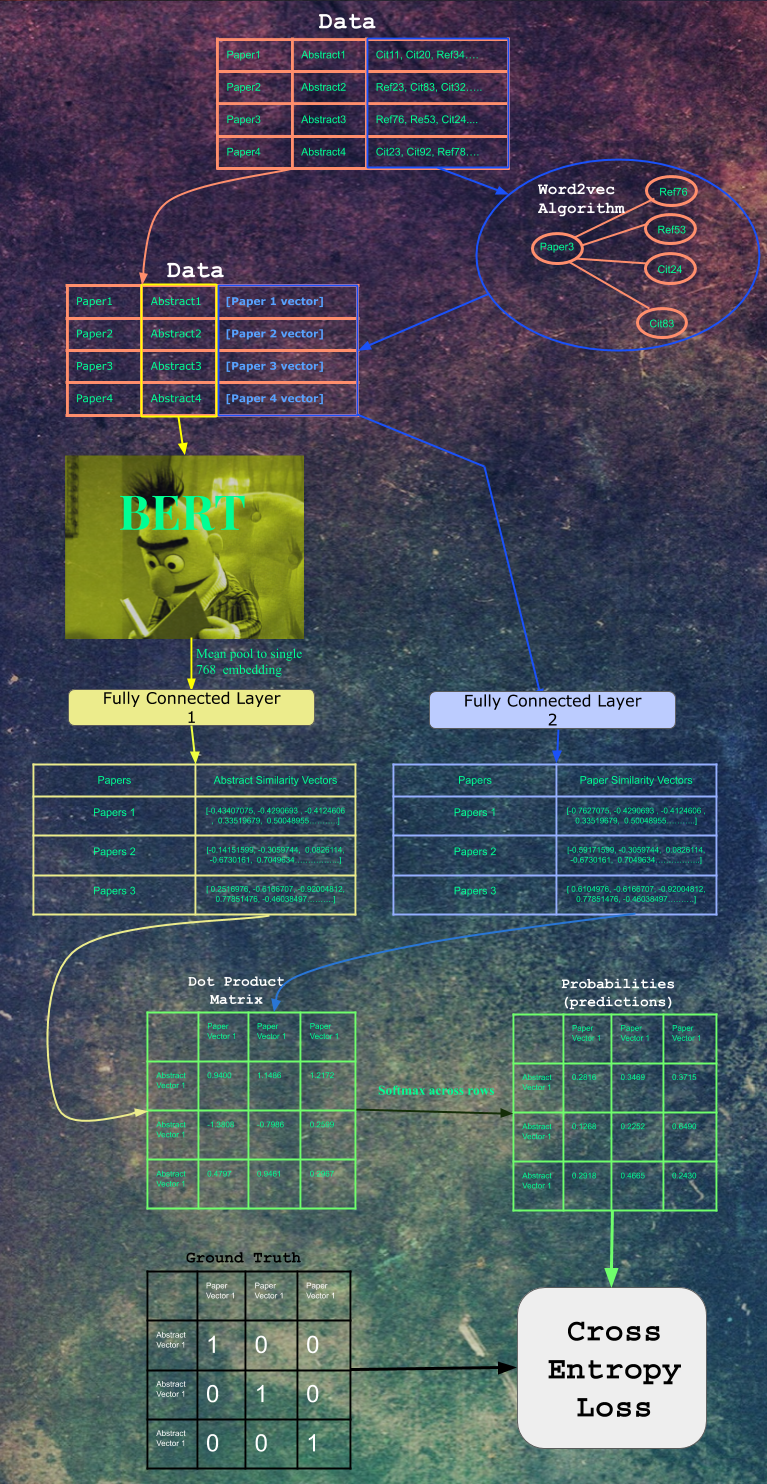
From a past project, I learned that Bert can act as a powerful paragraph encoder [https://github.com/re-search/DocProduct] and from another project, I learned that citation network data can be trained using the word2vec algorithm to create embeddings that can effectively represent each paper [https://github.com/Santosh-Gupta/Research2Vec]. I decided to combine the two properties: train a citation network on the word2vec algorithm, and set each paper embedding as a label. The input being that paper's abstract text, and the model being Bert, whose output will be the mean pool of the last hidden layer. The Bert output and the citation vector both pass through separate fully connected layers, and the resulting embeddings can be dot product'd. We also use negative sampling, all Other citation embedding vectors within a batch were used as negative samples. The logits were softmax'd for each paper, and use use cross entropy for the loss.

From the ground up we gathered 1.3 million papers from the Semantic Scholar’s Open Research Corpus to create our two datasets. One consisting of paper’s titles and abstract and the other consisting of our created citation network (a dataset of papers and their corresponding citations). Using Word2Vec CBOW we created citations vectors and our labels.. We then trained Bert using negative sampling on the abstracts of the papers. We built our paper recommender using huggingface’s recently released Bert TF2.0 implementation as part of their transformers NLP library. We then used a library created for this project by team member Srihari Humbarwadi called tpu-index, TPU Index is a package for fast similarity search over large collections of high dimension vectors on TPUs. Using this library allowed for the quick search of similar papers with the query provided to our model during inference.
A more detailed look at our process can be found in our Github README
Challenges
The field of science is ever-expanding and spans hundreds of industries, therefore for an initial proof of concept and prototype focusing on one subfield was optimal within the time constraint of the competition. So we’ve gone with the industry that each member shares a passion for, Computer science (this is a deep learning competition after all). Beyond having to reduce the scope of our project (we’re still working with 1.3 million papers), we also came across challenges of finding the right team members who wanted to actively contribute and work on the issue and dealt with our team of 5 spanning 4 countries and 4 different timezones. We ran into memory issues storing our word embeddings from our word2vec training over citation networks that we couldn’t solve within the time we had left in competition, forcing us to switch from our beloved pure TF2.0 implementation into a hybrid implementation using PyTorch to train our embeddings using SpeedTorch (Created by Santosh! One our members) so we could store embeddings on the CPU and GPU during training. This allowed us to have greater word embeddings sizes to allow for more information to be contained within our citation embeddings. This issue stemmed from each member's lack of experience using TPUs and with the timeline of our project not allowing for us to figure out an equivalent TF2.0 implementation. For a lot of the members, we didn't quite have an advanced understanding of TF2.0 and Keras, and through this project, we developed a deeper understanding of it.
A lot of the design decisions were tricky (embedding size, data filtration, model architecture) because we didn't yet have the intuition to confidently pick the right parameters. We would have preferred to do more testing, but with the deadline coming up, we had to make decisions and roll with them. We were a bit lucky to have the model end up working pretty well.
Accomplishments we’re proud of
• Completing this project while some of us had no experience with Tensorflow prior to the competition.
• Sticking to this project for multiple months, with an international team that worked together entirely remotely.
• Using the TensorFlow Research Cloud to train our models.
• A completely new, unique model for a research paper search engine.
What we learned
Liam: How to work with a team on a Machine learning project and all the workflows required to complete a project like this from data acquisition to model creation, training, and inference. Learning lots about TPUs through Srihari's work and as well increasing my experience with Tensorflow thanks to be able to work with more experienced members of the community.
Akul: This was my first online hackathon, so I learned how to work with multiple people across different time zones remotely. In addition, I learned how to process large amounts of data with cloud services like Google Colab as well as the overall process necessary to complete a machine learning project with so many moving parts.
Srihari: I learned to work and collaborate in a team remotely, use Google Cloud TPUs to train huge models, setting up an efficient data input pipeline using the tf.data API and also created my first python package.
Santosh: I further learned about the capabilities of Bert to encode text, particular scientific text, and overall how machine learning models can correlate text in general to find particular research papers. I also learned a lot about TPUs. I had a tricky time with them at first, but I think I pretty much get the hang of utilizing them effectively.
SideQuest
Eventually, we are going to be working with 179 million research paper embeddings, each of dimension 512, and we're going to run similarity on all of them. This can be very computational resource and time consuming. There are libraries for this, like Faiss, but as we were getting to know how to utilize TPUs, Srihari came up with an idea of running cos similarity indexing over TPUs, and make a library around it.
Check it out
https://github.com/srihari-humbarwadi/tpu_index
https://pypi.org/project/tpu-index/
Ultrafast indexing, powered by TPUs, no loss in quality.
What’s Next?
User Feedback
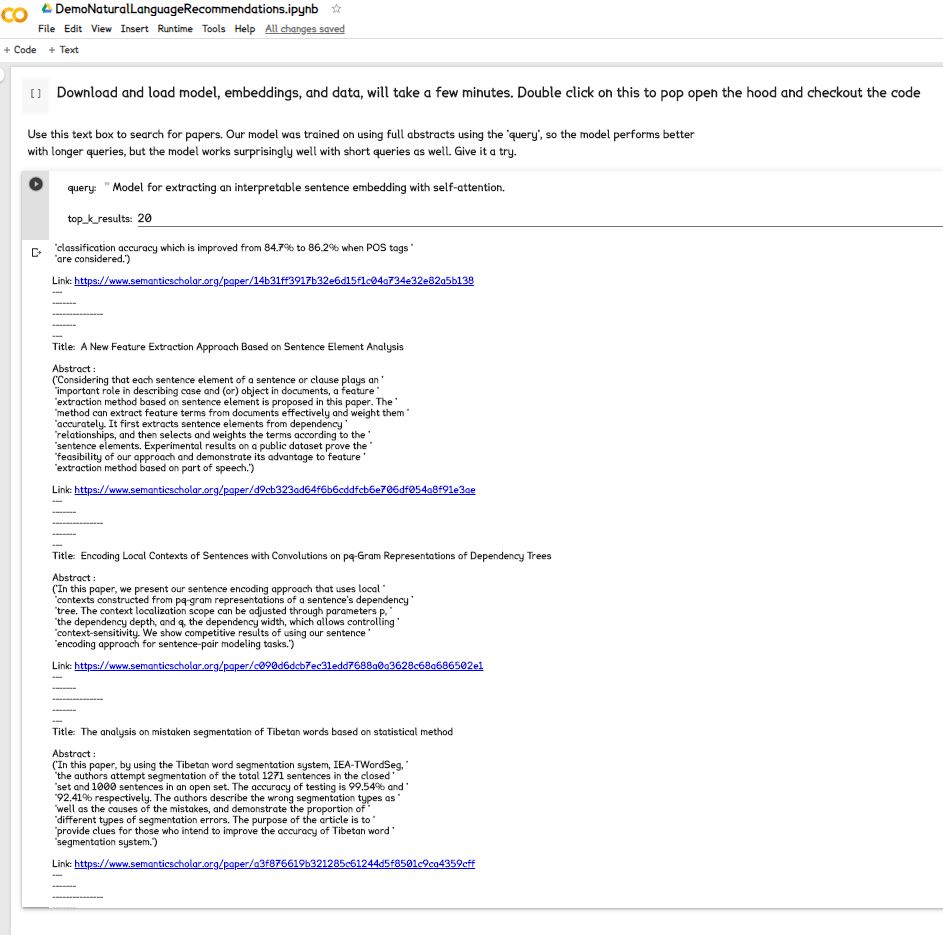
First thing we want to do is get as many people to test it as possible. From the testing our team has done, the model is very promising. We would like to see how others respond to it. We are hopeful that it will be helpful in finding research papers, especially on topics with no or unknown established phrasing.
Head-to-head.
We would like to compare the results of our model to Semantic Scholar and Google Scholar. Both of these search engines will likely give more and overall better results in most cases, but that's a given since they use ensemble methods carefully created by the best information retrieval engineers and scientists over many years. Our criteria for success if our model can find papers that the others have left behind. We did not get around to this at the time of the hackathon deadline, but we are optimistic since as far as we know, this is a radically new method of scientific paper retrieval.
Metrics
Judging the results just qualitatively. . . they're really really Really Good. (But don't take our word for it, try it out. We have colab notebooks that downloads the model and the data within a few clicks, and you can use it to search papers in CS). We are looking for ways to give our qualitative experiences quantitative metrics. If you have any ideas, please contact us at Research2vec@gmail.com .
Model Variations
We have gained quite a bit of insight during this project, and have idea of what may further improve the quality of the results. We have quite a few ideas on variations on our model which we are curious to test out in the near future.
Bigger/Better Subsets
Since the Semantic Scholar corpus is so large, we can only test subsets of subjects at a time, but there's no way to currently filter out a certain subset directly, so we have to get creative on how we create our subsets. We are hoping to improve upon our filtering methods to get more specific/accurate subsets from the corpus.
We are also hoping to figure out ways to increase the number of parameters we can train word2vec on. Currently, our capacity is around 15 million. We are aiming to get up to 179 million, which would take up a ton of memory (200 gb?) to have them all loaded into memory at the same time. If you have any ideas for this, please get in touch.
Paper
We are also looking to perform experiments and write up our work in a high enough level of quality that would make a significant contribution to the field of NLP, and thus qualify for getting accepted into a prestigious venue/journal. We are also looking for mentors who have accomplished this. If interested, please get in contact with us.
We want to keep expanding our project to other fields! Can our solution help find new applications for materials in other fields than the one it was discovered for? We also want to increase the relevance of the recommended papers by optimizing and trying other solutions.
Our goal is still to make something meaningful for the scientific community, and this prototype is just the first step of our collaboration.
Built With
- huggingface
- keras
- pytorch
- speedtorch
- tensorflow
- tpu







Log in or sign up for Devpost to join the conversation.