-
-
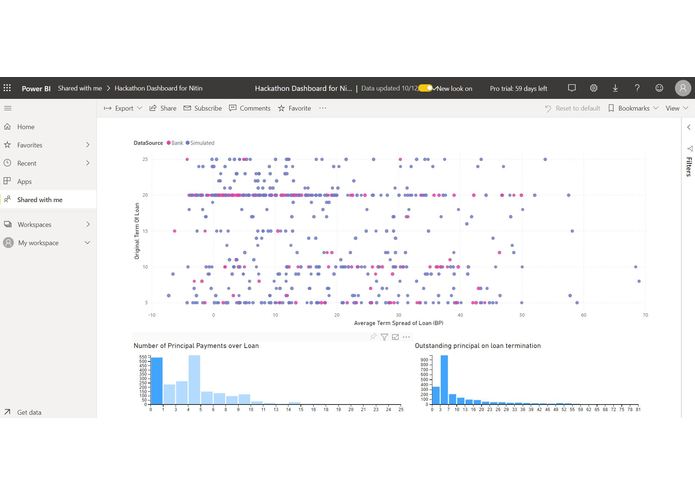
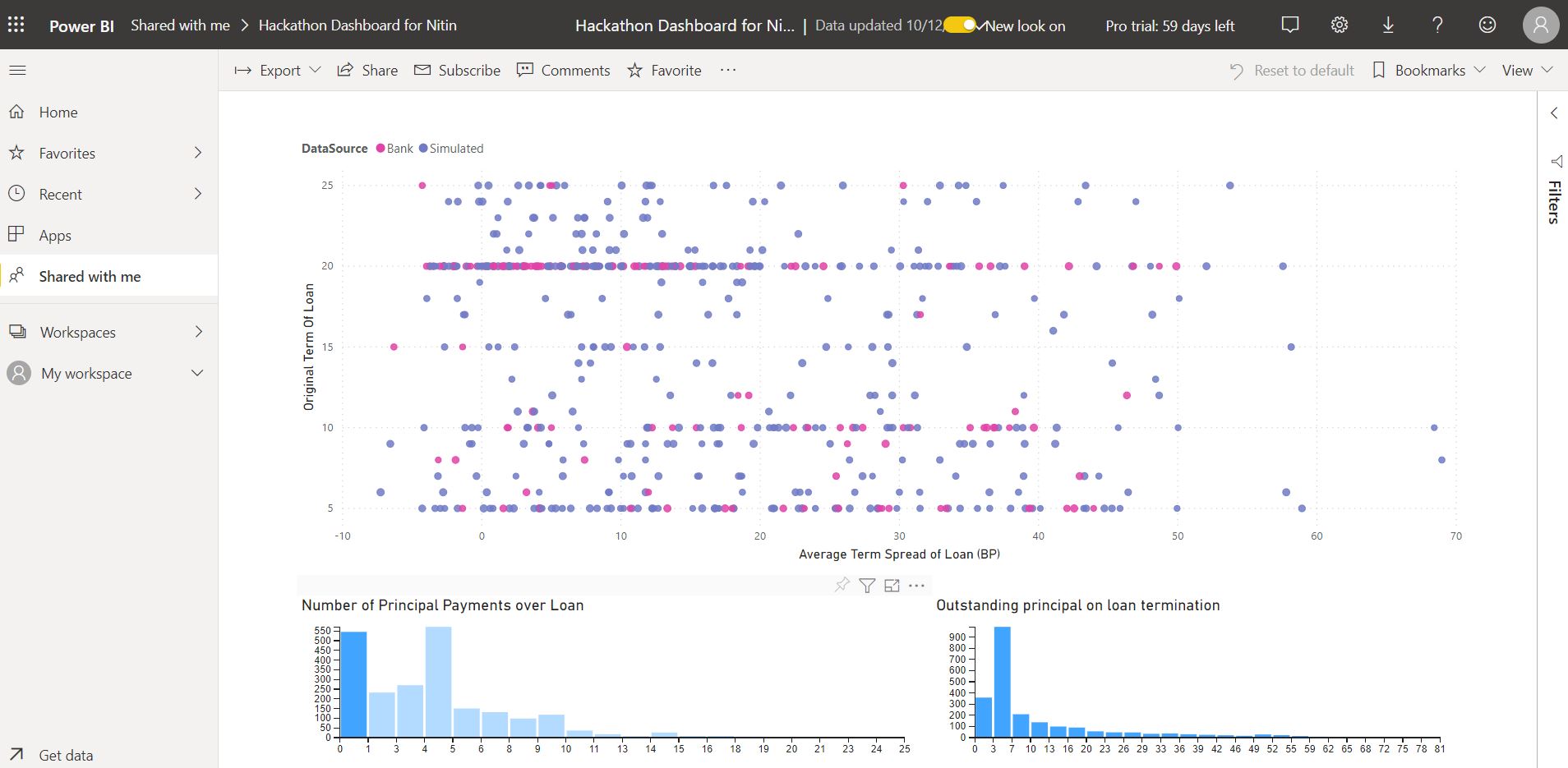
Output results - Microsoft PowerBI
Inspiration
Machine learning is touted as a solution capable of automatically learning complex functional relationships without the explicit need for programming. It has been applied in fields as varied as financial prediction or medical diagnosis, and has led to novel applications from both technology titans and agile start-ups. However, data is the lifeblood of this new emerging economy, i.e. the resulting solutions are as good as the data available to train and validate them. Deep learning (and especially reinforcement learning) can require millions of data samples to properly train a model. While these are readily available in high volume digitised domains like web traffic or e-commerce, when we turn to financial domain, we are confronted by a chronic data scarcity caused, among others (especially in our core Tier 3- customer base), by the lack of historical data, its bias, obsolesce (e.g. due to shifting economical regimes), and its quality, not mentioning the data privacy constraints. In addition, within the context of risk management, handling of potentially disastrous events is of utmost importance, but these are naturally rare and so under-represented in the available historical data. The challenge of having good data has therefore been increasingly noted and analysed (e.g. see [1],[2],[3],[4]). Still, the solutions are at early stage in general, and within financial domain, in particular for regional institutions and the fintech industry serving them.
_ [1] Buehler, Hans, et al. "Deep Hedging: Hedging Derivatives Under Generic Market Frictions Using Reinforcement Learning-Machine Learning Version." Available at SSRN(2019). _
_ [2] Li, Junyi, et al. "Generating Realistic Stock Market Order Streams." (2018). _
_ [3] Moriyama, Koichi, et al. "Reinforcement Learning on a Futures Market Simulator." J. UCS 14.7 (2008): 1136-1153. _
_ [4] Hernandez, Andres. "Model Calibration: Global Optimizer vs. Neural Network." Neural Network (July 3, 2017) (2017). _
What it does
To tackle this challenge, our approach is to learn and model the distribution of the underlying data driven by a possibly minimal real dataset and well-founded models (e.g. for rare events/black swans). In particular, the solution incorporates the so-called _ Peek-over_Threshold _ model developed by University of Leeds (see the attached flyer). Once the application learns the distribution and/or its calibrating features, we can sample an infinite number of training examples, correlated with real data the distribution was derived from, to feed the data-hungry machine learning algorithms.
Sample data has been analysed using Mixture Density Networks to retrieve the underlying data distribution (Gaussian distributions is currently supported), which then has been used to calibrate the associated survival Cox models supporting Weibull and log distributions. The prototype is able to generate loan prepayment events and associated data.
Our aim is to make this tool available in FFDC such that it can be incorporated into the workflow of applications deployed on the platform, e.g. Fusion Optimum to train its Deep ALM optimizer, and address the data deficiencies that limit their effectiveness.
How I built it
The solution has been built in co-operation with the Department of Statistics University of Leeds leveraging Microsoft Azure and Machine Learning Studio platforms. The solution employed Keras available within TensorFlow 2.0 library and Azure DataBricks for data management. We have also used proprietary C code to implement the statistical models designed by University of Leeds.
Challenges I ran into
It was difficult to get some real data due to data protection and ownership issues (surprise! ;). Challenging was also to define the data sample format/features, as well as the data model and API , so they are extendable/generic. Also testing was painful again due to the limited data availability but also user friendliness of the Azure ML Studio (web browser based, no offline mode, paid features, which were not available). Nevertheless, the fast prototyping capabilities of the platform helped to deliver the solution.
Accomplishments that I'm proud of
As far as we am aware, this is the first case of a model augmented data simulator, where the data driven AI algos have been coupled with rigid mathematical models, avoiding the curse of dimensionality. The use cases are endless, starting from an outright scenario generator to the market environment simulation for reinforcement learning agents. The achievement has also been possible by a clever combination of existing reliable toolkits (Azure, ML studio, Keras) and proprietary experience of the team. The tool can be used by our customers and fintechs to generate the data badly needed to train their own AI models. It is also a critical supporter of our own work on the Deep ALM balance sheet optimiser, which employs reinforcement learning and so needs to have a simulation environment.
What I learned
We learned to use the FFDC and Azure ML Studio efficiently, esp. in terms of including external libs, like tenor flow. Also, the models coming from the academic research enriched our understanding of data and its use scenarios. We’ve learned the challenge of a proper data modelling and testing. It was refreshing to see that our thinking out of the box approach I possible to be implemented and used with the currently available technology.
What's next for Deep Scenario Simulator
We want to extend the use case scenarios and make it more generic in terms of the covered financial events and market data. We also want to investigate Generative Adversarial Networks, and other AI algos (e.g. RL A3C) to further improve the quality of generated data.Last but not least the UI and API needs to be further streamlined.










Log in or sign up for Devpost to join the conversation.