-
homepage
-
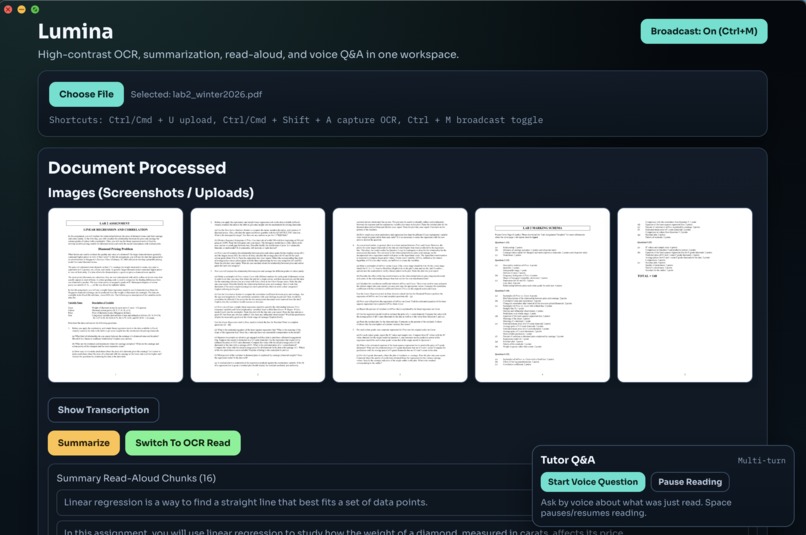
ocr
-
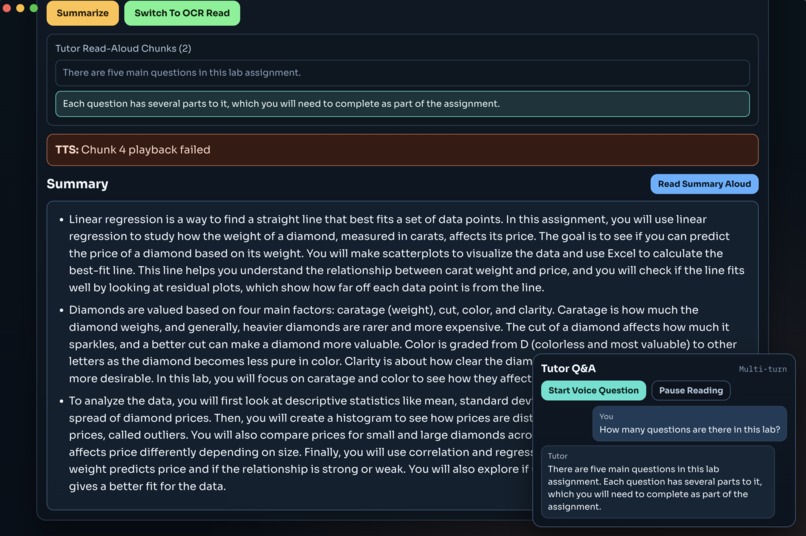
summary and tutor
Inspiration
We were inspired by a real accessibility gap: blind and low-vision students can access basic text, but often get blocked by scanned PDFs, formulas, code snippets, and complex academic layouts. When a screen reader says only “image,” learning stops. We wanted to build a system that restores independence in those high-pressure moments.
What it does
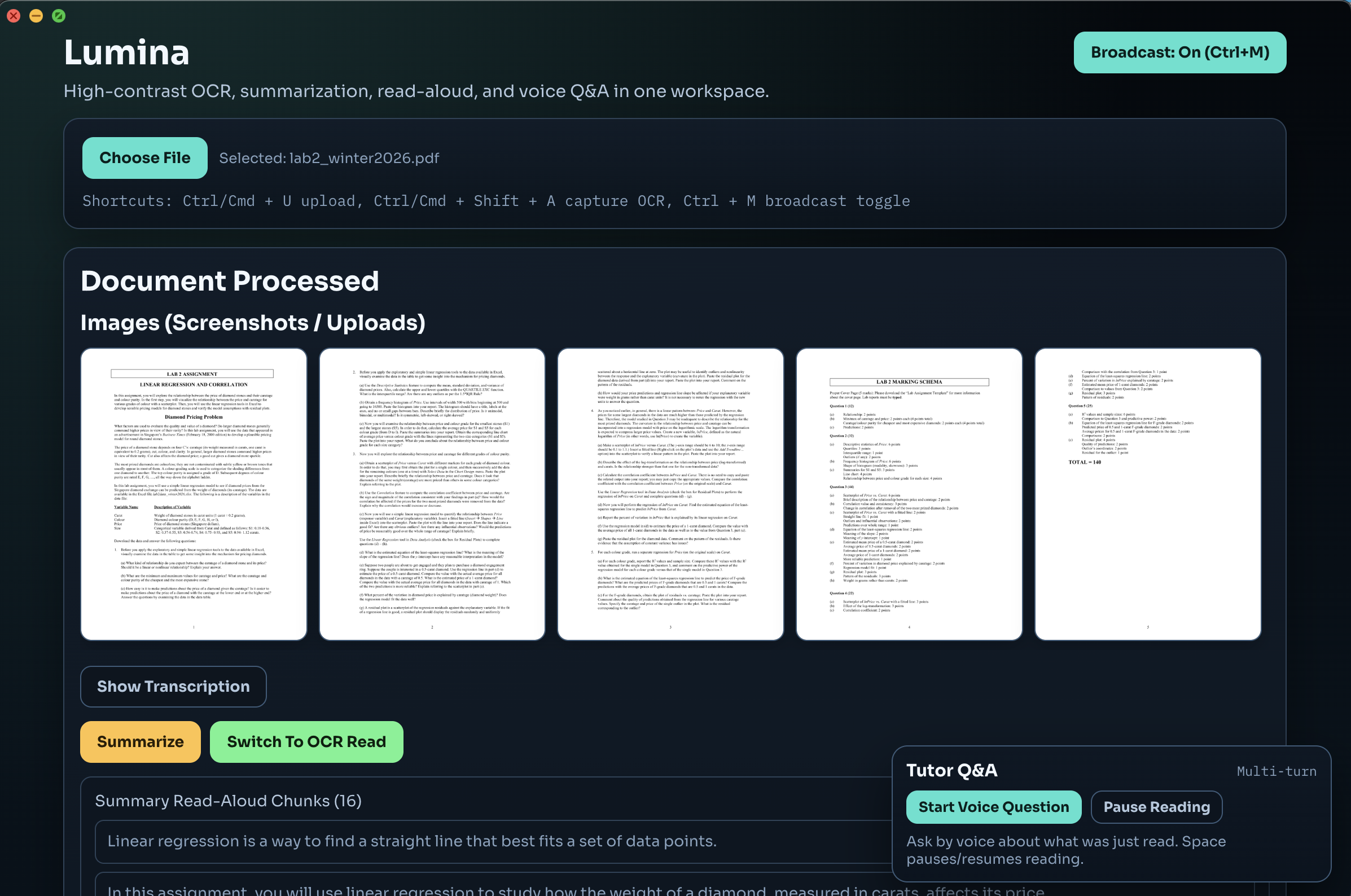
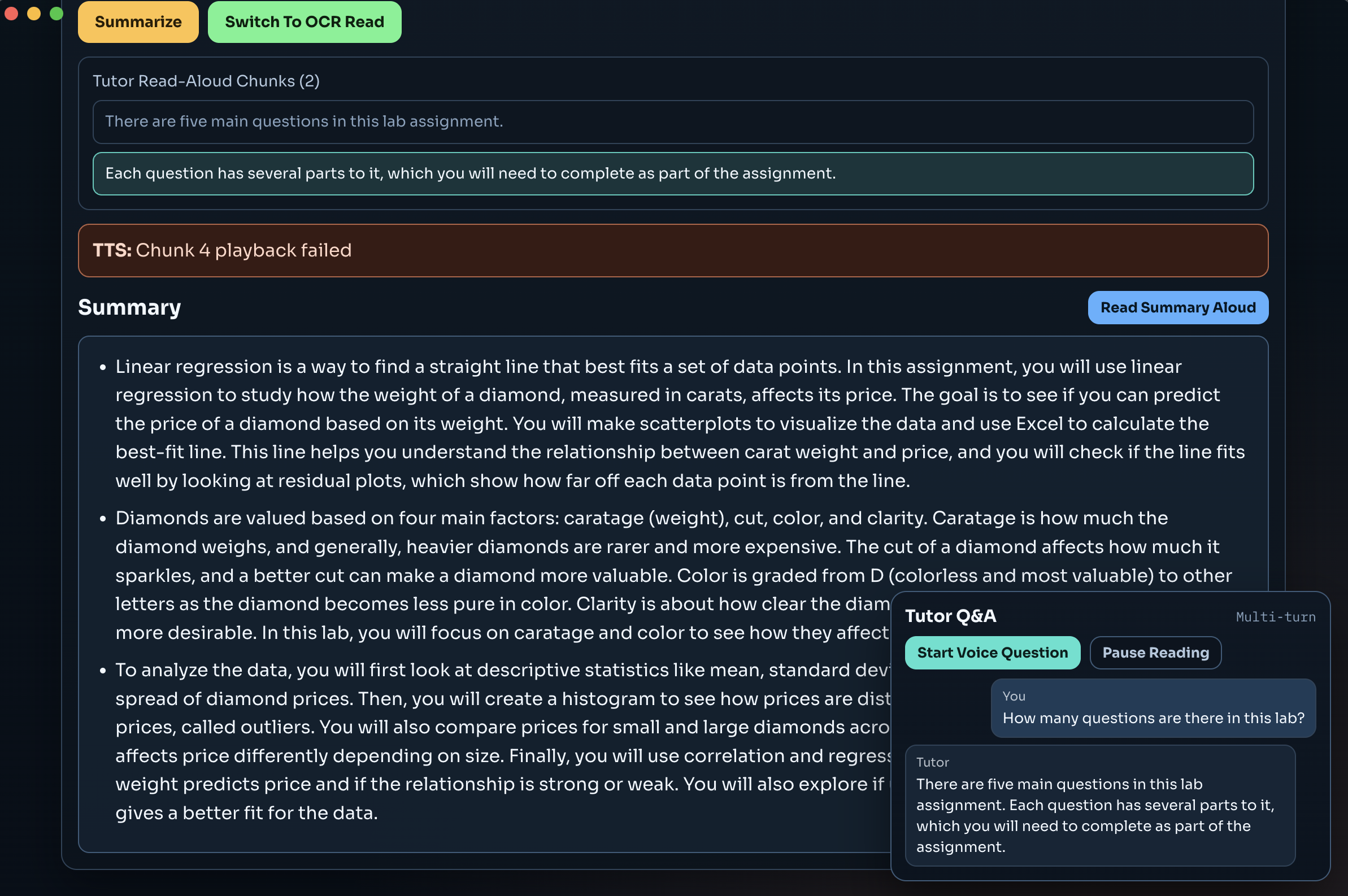
zypher_Lumina captures content from uploads or screenshots, reconstructs it into structured, readable format, summarizes key ideas in plain language, and reads it aloud with natural pacing. Users can interrupt at any time, ask a voice question, and receive a contextual answer before resuming the original reading flow.
How we built it
We built an end-to-end stack with Electron + React on the client and Node/Express APIs on the backend. Gemini Vision (via OpenRouter) handles OCR and structure extraction, GPT-4o powers summarization and semantic chunking, Kokoro provides local TTS, Whisper handles STT, and SSE streams chunked audio playback in real time.
Challenges we ran into
Our hardest problems were reliability and continuity: preserving reading order from noisy OCR, handling formulas/code cleanly, creating natural chunk boundaries, and keeping audio responsive without waiting for full synthesis.
Accomplishments that we're proud of
We shipped a full MVP loop: capture → structured OCR → summary → streamed TTS → interruptible tutor Q&A. We also added caching, concurrency control, retry logic, and robust error handling for demo stability.
What we learned
Accessibility is not just “reading text aloud.” True accessibility means comprehension, interaction, and control. System design and UX flow matter as much as model quality.
What's next for zypher_Lumina
Next, we will run real user testing with BVI students, measure task completion and comprehension gains, improve math/code explanation quality, and harden deployment for campus accessibility offices and broader educational adoption.




Log in or sign up for Devpost to join the conversation.