-
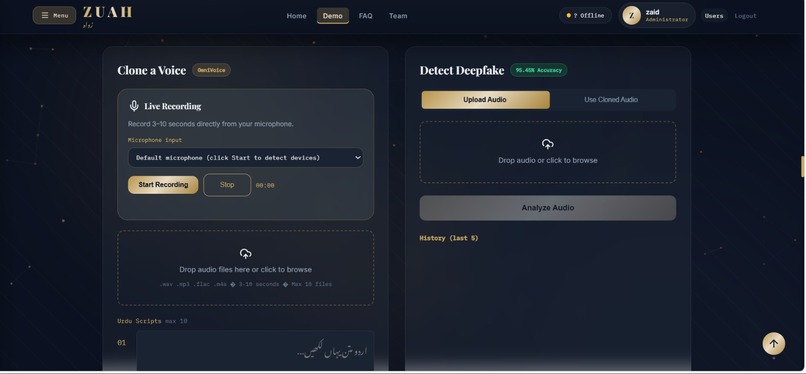
Dashboard
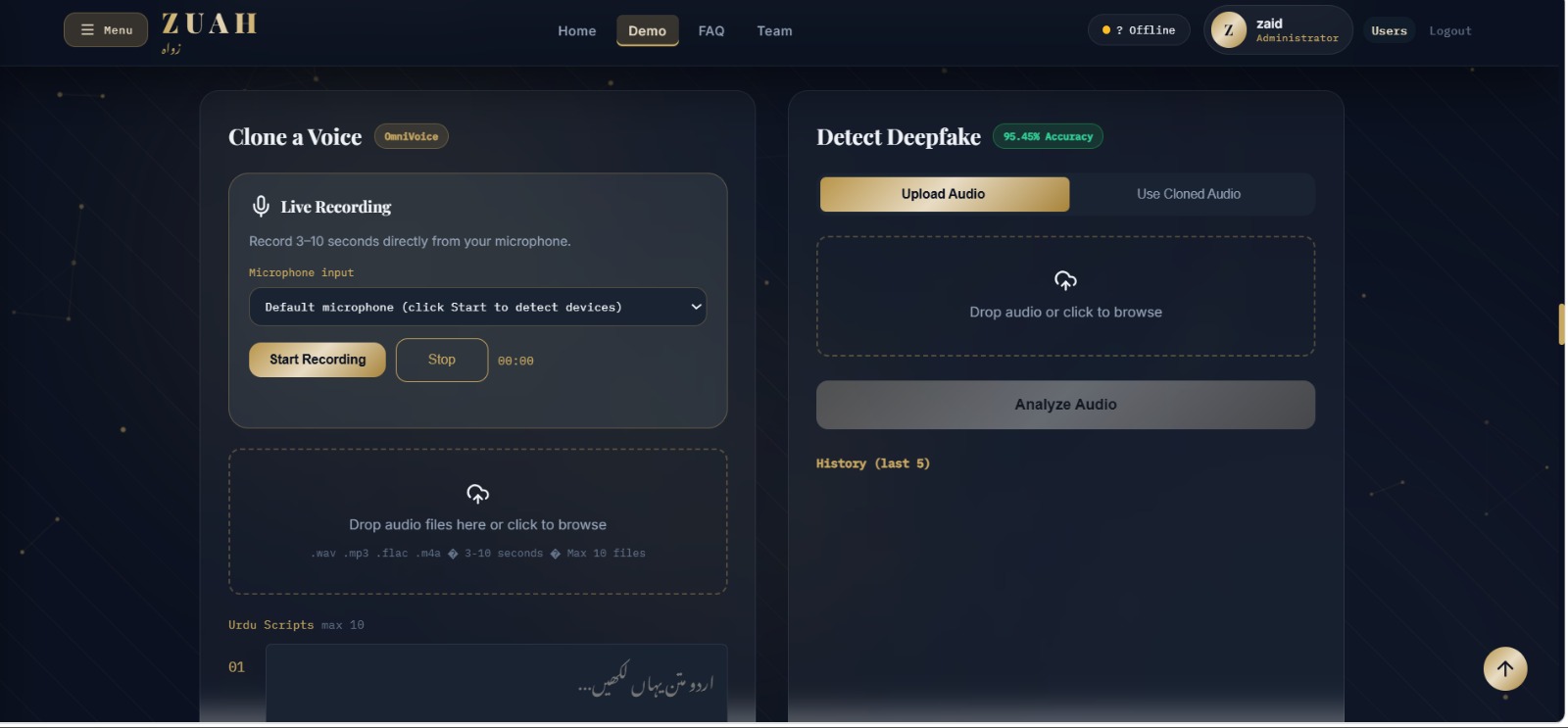
Inspiration
Urdu-speaking communities lack tools to detect AI-generated voice fraud. With deepfake audio becoming weaponized for scams and misinformation in Pakistan, we built Zuah — a platform that both demonstrates the threat through voice cloning and arms users with detection.
What it does
Zuah detects whether an audio clip is real or AI-generated with 95.45% accuracy, and clones any voice from a 3–10 second sample into fluent Urdu speech. Users get a full dashboard with usage tracking, billing tiers, an audio library, and an admin panel — all behind JWT-authenticated accounts.
How we built it
We fine-tuned a Wav2Vec2 + AASIST + Conformer ensemble on a custom Urdu deepfake dataset (2,400 clips across 48 speakers) plus ASVspoof 2019. For generation we integrated OmniVoice, a zero-shot diffusion-based TTS model with native Urdu support. The backend is Flask with SQLite, the frontend is vanilla JS with WaveSurfer.js for audio visualization, and inference runs on a GPU server tunneled via ngrok during demos.
Challenges we ran into
No existing Urdu deepfake audio dataset existed — we built one from scratch Wav2Vec2 alone under-detected Urdu-specific prosody artifacts; adding the Conformer branch pushed accuracy from ~87% to 95.45% XTTS-v2 did not support Urdu reliably; we evaluated multiple TTS models before settling on OmniVoice Colab's session limits made sustained demo hosting unreliable — we architected a split deployment (always-on web app + on-demand GPU container) to solve this
Accomplishments you are proud of
95.45% detection accuracy on Urdu speech with under 2.1 seconds inference time First publicly demonstrated Urdu-specific deepfake detection and generation platform Full production-grade platform: auth, billing plans, API keys, audit logs, PDF reports, and real-time analytics — not just a model demo
What have we learnt
Ensemble architectures (feature-level fusion of spectral + contextual representations) significantly outperform single-model approaches for low-resource languages Responsible AI framing matters as much as the model — consent workflows, usage limits, and explainability outputs made the platform credible beyond just accuracy numbers Hosting ML models in production requires fundamentally different architecture than a Colab notebook
What's next for Deepfake Generation and Detection
Real-time streaming detection via WebSocket (currently processes complete files only) Expanding the dataset to regional Urdu dialects (Punjabi-accented, Sindhi-accented Urdu) and other languages specifically English. Replacing ngrok with a permanent Azure GPU container for 24/7 inference Publishing the Zuah Urdu Voice Dataset openly for other researchers
Built With
- aasist
- asvspoof-2019-dataset
- azure
- azure-files
- bcrypt
- blob-storage)-databases:-sqlite-huggingface-hub
- conformer
- container-instance
- google-colab-(gpu-inference)
- html/css
- javascript
- librosa
- microsoft-azure-(app-service
- namecheap-(domain)
- ngrok-(tunnel)
- omnivoice
- pyjwt
- python
- pytorch
- reportlab
- sql-flask
- torchaudio
- transformers-(huggingface)
- wavesurfer.js

Log in or sign up for Devpost to join the conversation.