-
-

Introduction
-
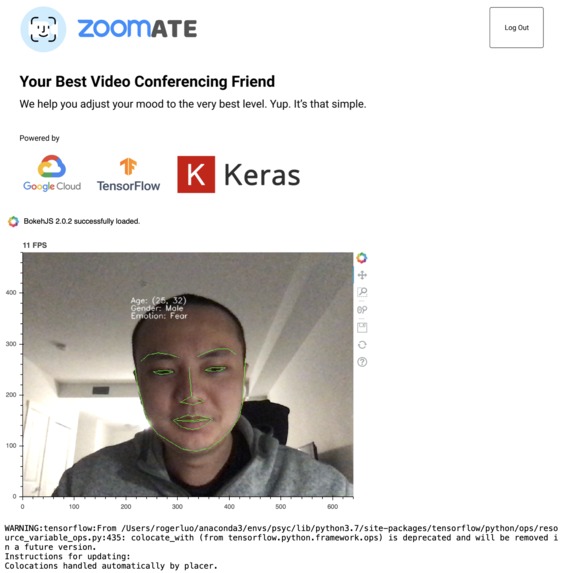
Streaming window showing the real-time facial expression analysis
-
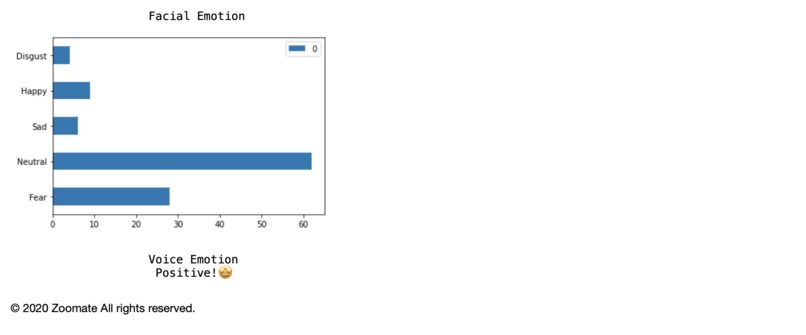
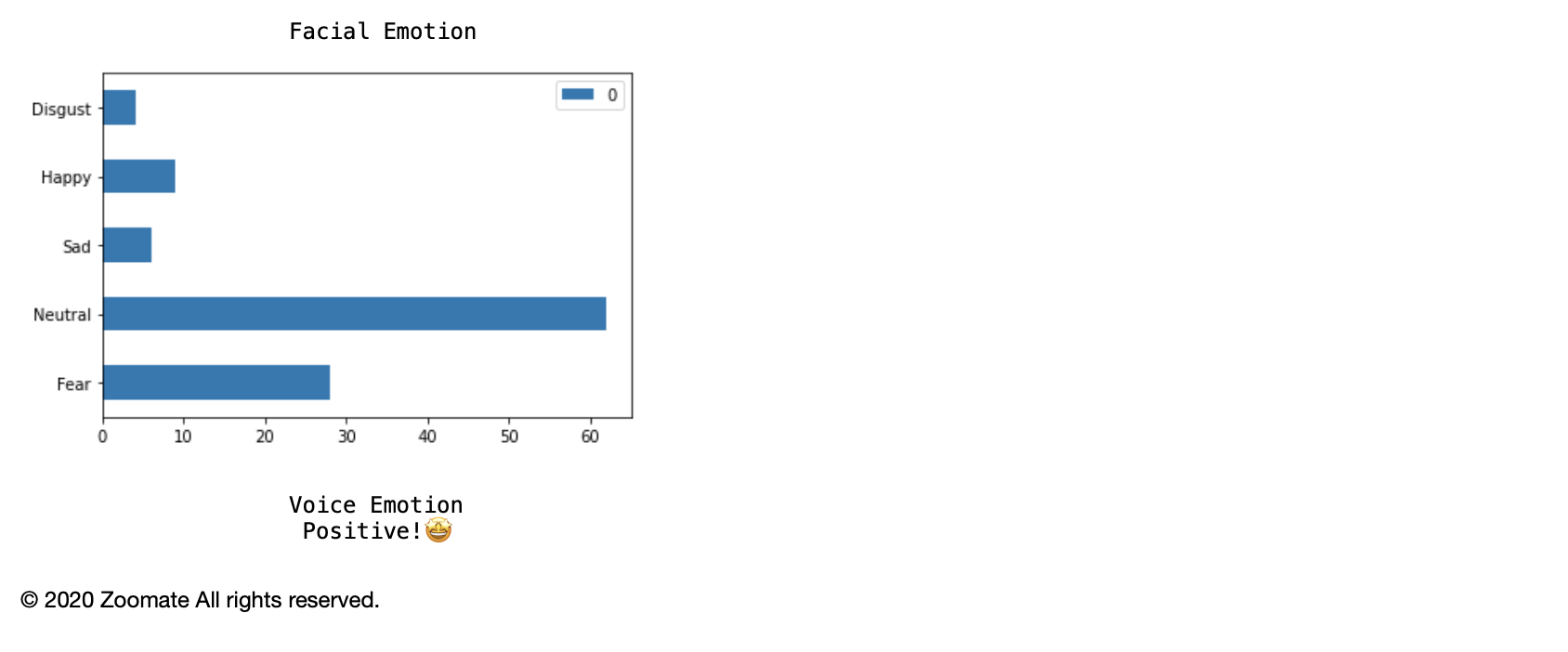
Results summary after the video chat session


Inspiration
During the pandemic, a lot of our work moved online. But not everybody is having a perfect experience with the video chat. A lot of times, the facial and voice expression delivers nuances in emotion that can transmitted to others. The experience would not be good if the emotions are negative.
What it does
Zoomate can analyze the user's facial and voice emotion in real time, and provide feedback to users. This will help users adjust their mood in their next video chat session.
How I built it
Voice recognition was done by google cloud speech to text service. From the result of google service, we input the text stream into a LSTM model trained by us during the competition. The facial recognition identifies user's emotion in realtime, and generate a histogram summarizing the frequency of different emotions captured during the chat session.
Challenges I ran into
- Setting up the google cloud speech to text services
- LSTM model training and tuning
- Project integration
- Multi-threading synchronization
- Streaming video from a web browser while with little latency - as there's also an inference running in the background
Accomplishments that I'm proud of
Finished the whole project in 24 hours is already very amazing for us. We have no experience in google services, and we spent significant amount of our time on this part. Besides, we had a lot of issues about package dependencies. At the end, we finished it, as well as created a nice video for it !!! Thanks my teammates !!!!
What I learned
Daniel: During this 24 hours, its my first time to try the google cloud service. We spent around 1 hour to set up the whole system to connect the text output to our LSTM model.
What's next for Zoomate
- We will try to retrain the model of LSTM to improve the analysis accuracy.
- Clean up the project, delete some unnecessary files or test scripts
- Add dash graph to show the analysis result visually (better looking)
Built With
- google-web-speech-api
- keras
- lstm
- python
- tensorflow



Log in or sign up for Devpost to join the conversation.