-
-

Web App Before User Submits
-

Web App When User Hits Submit
-

Email User Receives With The Zoom Statistics
-
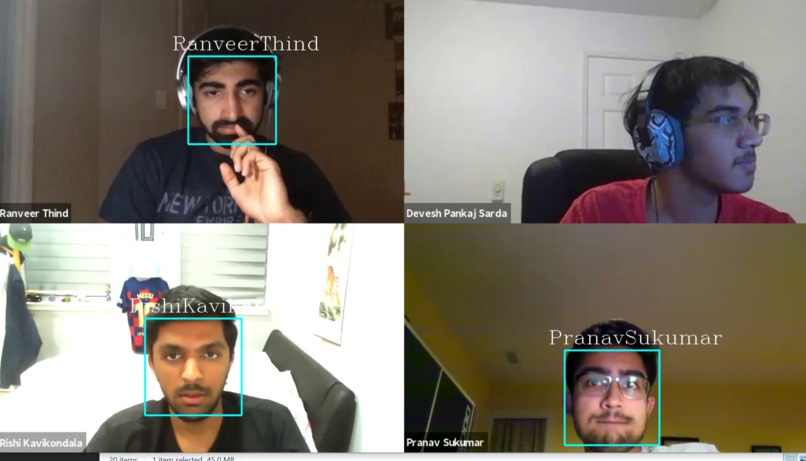
Computer Vision Algorithms Detecting Who Is Looking at Screen
-

Percentage of the Class Actively Looking at the Screen Over Time
-

Most Common Sentiments in the Zoom Audio Recording
-

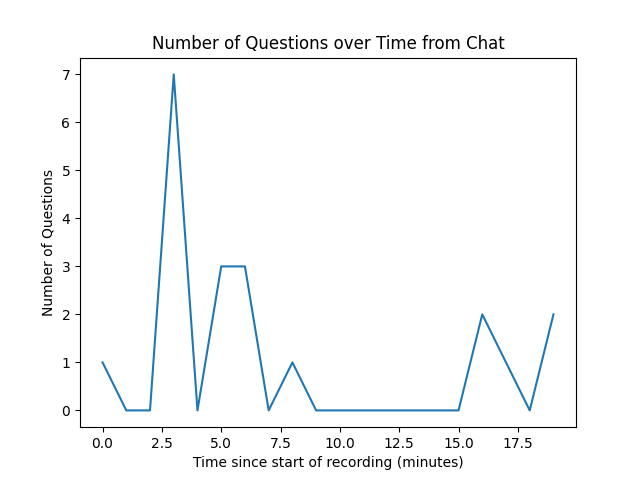
Number of Questions Asked in the Zoom Chat Over Time
-

Number of Questions Asked in the Zoom Audio Transcript Over Time







Inspiration
As college undergraduates who are used to going to live lectures and discussion sections, the transition to online learning was very difficult. Attending Zoom lectures and discussions does not provide the same incentive to actively listen and pay attention. As a result, we often have to rewatch entire lectures because we did not pay attention during the live lecture.
We also understand the plight of instructors, as some of the members of the team are TAs for classes. While leading discussion sections, we have realized that students do not pay as much attention, and answer questions less frequently.
We want to address these issues by creating a tool to give Professors and TAs automated feedback for their recorded Zoom meetings. A tool like this can also provide extra motivation for students to pay attention, since their instructors can see how engaged they are.
What it does
We implemented our solution as a Web-application. This application takes in the Zoom Video recording, Zoom chat transcript, and Zoom audio transcript, which can be generated from a recorded meeting. We use computer vision to analyze how often the students are looking at the computer screen and paying attention. We also use Natural Language Processing (NLP) to provide sentiment analysis and topic clustering for the questions posed in the audio transcript and chat box. We then email these charts and statistics to an email address passed in to the Web-application.
How we built it
Client Side:
We built the frontend for our Web App using HTML and CSS. We had input fields to allow the user to provide their email and upload a Zoom video recording, audio transcript, and chat transcript, which can be easily downloaded after a recorded meeting ends.
Server Side:
When the user presses “Send” on the Client Side, the files are uploaded to Google Cloud Storage. These files are then passed into a Cloud Function written in Python.
Our Python scripts were designed to perform various analysis. First, Python programs were written to parse the input transcripts into readable formats. There is a program to perform topic modeling and clustering on both the audio and chat transcripts using Latent Dirichlet Allocation (LDA) using the sklearn library. We read through all the text in the audio and chat transcripts and used Nltk’s Multinomial Naive Bayes library to classify whether a statement was a question or not. We also conducted sentiment analysis on the entire transcripts using the IBM Watson Speech API. Finally we performed face detection analysis on the video recording using OpenCV and a Siamese Neural Network to see if each face was facing the screen. We used Keras and TensorFlow to estimate the attentiveness of an individual by their facial movements and used it to take attendance from school id pictures.
With this data we generated graphs of the percentage of the class looking at their computer screen over time, the number of questions asked in the chat and verbally over time, and the most common emotions from the audio recording. We reported the topic clusters as .txt files.
Finally, we used the email library in Python to generate an email from our email address “online.class.analyser@gmail.com” to the specified recipient. This email contains the previously mentioned graphs and data as attachments.
Challenges we ran into
We were able to write the Python backend and run it locally fairly quickly. The largest challenges for us had to do with implementing the code as cloud functions on GCP. We initially had permission issues with GCP. We also ran into troubles reading stored files in subdirectories on GCP. Our codebase was also initially too large to be hosted on GCP, and we had to remove large video files. These issues with GCP were especially challenging for us to overcome because this was the first time using GCP for a lot of the team members.
Accomplishments that we're proud of
Despite these challenges, we were able to successfully build our Web App and host it on GCP! We are proud of the various technologies we used, and how we seamlessly integrated them to provide a helpful tool. Prior to this Hackathon we did not have any experience with NLP, but were able to learn it and integrate it with OpenCV and GCP to build a cohesive application.
We are most proud of the fact that we were able to create something that helps Professors, TAs, and students adapt to the challenges posed by the COVID-19 Pandemic.
What we learned
We learned how to brainstorm ideas effectively in a team, implement our idea collaboratively, and parallelize tasks for maximum efficiency. We learned about NLP techniques which we implemented into our design and solution process, carefully selecting analysis methods to evaluate candidate options before proceeding on a rigorously defined footing. We also learned how to deploy Python scripts to Google Cloud Functions and how to call those functions from a Node.js server.
What's next for Edify
We decided to develop our solution exclusively for Zoom because it is the primary mode of delivering lectures and discussion sections in academia. We want to expand our solution to different platforms like Microsoft Teams and Skype so that it can be used in a corporate setting as well. We also want to incorporate our application with school databases so that we can use real student ID's in our Computer Vision modeling. We would also like to gather and display analytics in real time so that a presenter can adapt their strategies to suit the audience at any particular moment.
Zoom learning is not perfect, and will never replace in person classes for many people, but we hope that our tool can help countless Professors, TAs, and students.





Log in or sign up for Devpost to join the conversation.