Inspiration
If there is anything real to the hype surrounding artificial intelligence, it is its ability to automate more repetitive yet complicated tasks and save time from it. Such tasks can be found in almost any industry of any level. Combating wildlife trafficking, where speed is key, also still requires some tasks to be manually done. This time-consuming manual task is a huge obstacle that conservation organizations face today. In fact, gathering data for a single case requires multiple articles on average. This involves a series of the process which consists of defining keywords, searching, clipping, reading, and extracting information which may take up hours only to provide information for a single wildlife case. To hasten this process, we choose to tackle the Global Problem Statement no. 10 on Broadening the net: targeted scanning of media to enrich counter wildlife trade intelligence efforts. We utilize artificial intelligence concepts to provide the profile of the wildlife trafficking cases such as what species, the trade volume, where it happened and so on, insofar, this kind of information has been provided by analysts through extracting the data from the news manually. We believe that the current state of artificial intelligence mainly machine learning can offer a solution to automate this. That way, an AI model can read the article and extract what the analyst might need with little hands-on from the analysts themselves, saving time and making faster decisions to combat wildlife trafficking.
What it does
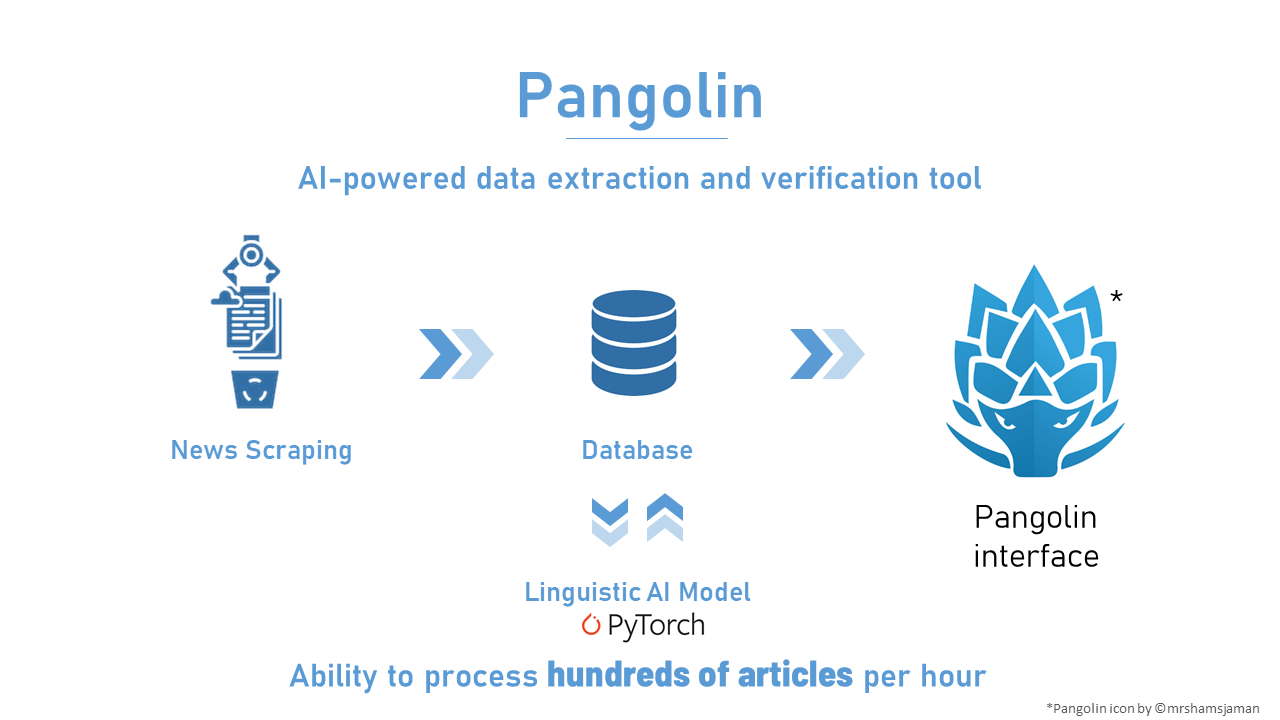
Navy Pangolin is a software tool with machine learning to automatically process online news articles and extract key information to shorten the time spent on manually reading these articles that would be typically done by analysts working on a certain case in counter wildlife trafficking efforts.
How we built it
We used PyTorch as our framework to develop out machine learning model as well as open-source repositories to visualize the output of the model (predicted words that are considered people, wildlife species, crime, etc). The purpose of the visualization is so that users can verify whether the machine learning model's predictions are correct. In addition, user corrected data can be reused as training data to make the machine learning model even more accurate over time through usage.
Challenges we ran into
The limited amount of annotated data forced us to manually label ourselves and made the model underfit. We believe with more exposure to expert annotations, this issue will disappear.
Pangolin is a large software project with multiple discreet parts that require more than 6 people to build to a full-fledge tool.
Accomplishments that we're proud of
We've demonstrated that Pangolin is able to discern raw text data and assist human in collecting information such as wildlife species, date of the cases, location and most importantly: crime type (i.e. smuggling, trading, poaching, etc)
What we learned
We've learned that there is great opportunity for conservationists and computer scientists to collaborate on solving today's hard problems. We learner that Pangolin can set an example to raise awareness on how analysts can save their time and how machine learning practitioners can help overcome these challenges.
What's next for Zoohackathon2019-Pangolin
As the next step, we wish to do the following:
- Approach various organizations that may be interested to use a production-level version of Pangolin;
- Build a dashboard to better visualize the data into interactive wildlife trafficking map and data summary of the number of trafficking cases and its volume;
- Extend Pangolin to become multilingual;
- Extend Pangolin beyond text and news articles to multimedia data such as photos, videos, and possibly audio; and
- Improve project branding.





Log in or sign up for Devpost to join the conversation.