-
-
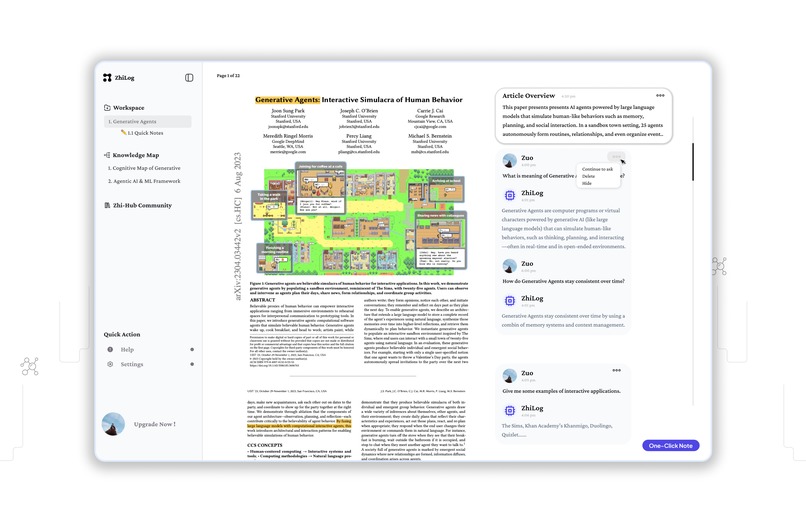
ZhiLog - AI Learning Agent Interface (Read–Ask–Note Flow)
-
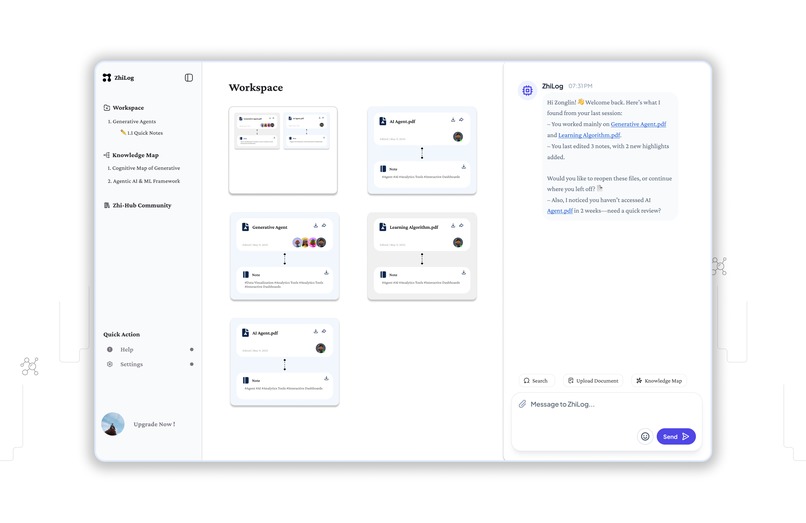
ZhiLog - Workspace

Inspiration
As graduate students, we constantly faced fragmented learning workflows — switching between ChatGPT, PDF viewers, note-taking apps, and cloud drives. We wanted a better way to learn deeply, not just quickly. That’s why we built ZhiLog: an AI-native learning agent that helps students complete the “read → ask → note → retain” cycle seamlessly.
What it does
ZhiLog allows users to:
- Upload PDFs or insert article links
- Ask contextual questions and get source-backed answers (via Perplexity Sonar)
- Auto-generate structured notes in Markdown
- Build a personal knowledge graph from interactions
- View and reuse their Q&A and notes in future sessions
How we built it
- Backend: Python, LangChain, Perplexity Sonar API
- Frontend: Flask(demo), Figma (UI design)
- Parsing: PyPDF2, BeautifulSoup
Challenges we ran into
- Maintaining context in multi-page document conversations
- Designing a simple but powerful UX that balances control and automation
- Managing LLM cost vs. accuracy during API integration
- Building a scalable knowledge graph backend within time limits
Accomplishments that we're proud of
- Built a functional prototype with full “read–ask–note” flow
- Integrated Perplexity API for trustworthy, real-time answers
- Designed an interface learners said they would use daily
What we learned
- Perplexity's Sonar API is ideal for fast and factual Q&A
- Learners value context and memory over flashy features
- Agent-native workflows reduce cognitive load and boost retention
- Great UX means one clear entry point, not a dozen scattered tools
What's next for ZhiLog
- Expand knowledge graph capabilities
- Integrate Google Drive and Canvas for dynamic material fetching
- Launch ZhiHub: a community for shared knowledge bundles
- Agent operation visualization: boost trust among users
- Continue iterating based on user testing and agent behavior feedback
- Prepare for MVP launch and seed round fundraising


Log in or sign up for Devpost to join the conversation.