-
-

We are ZetaGAN!
-
Home page
-
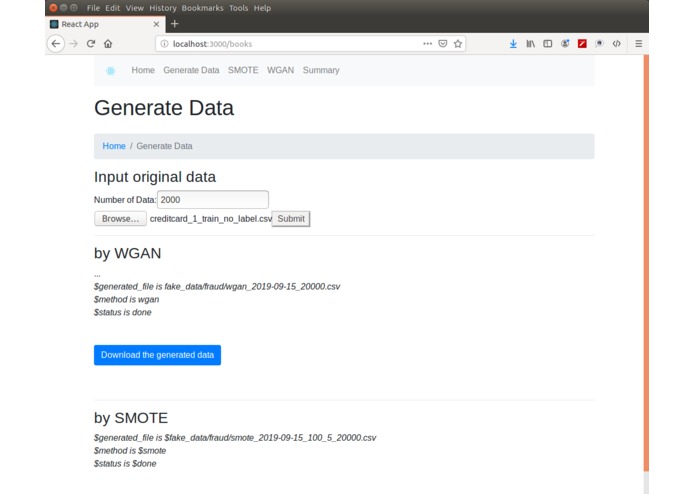
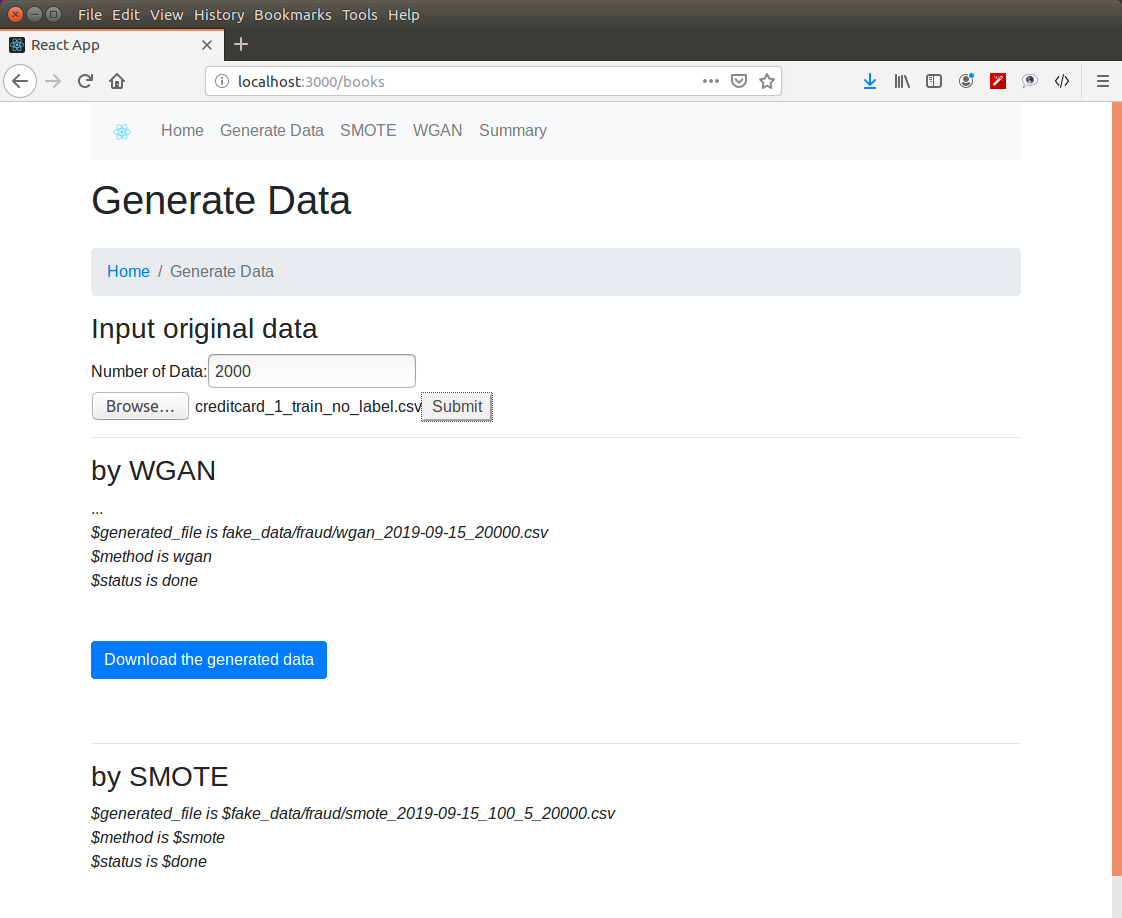
generators: WGAN and SMOTE
-
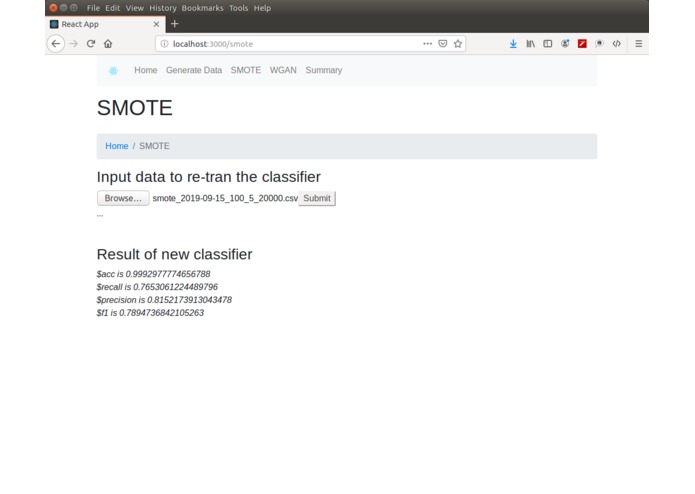
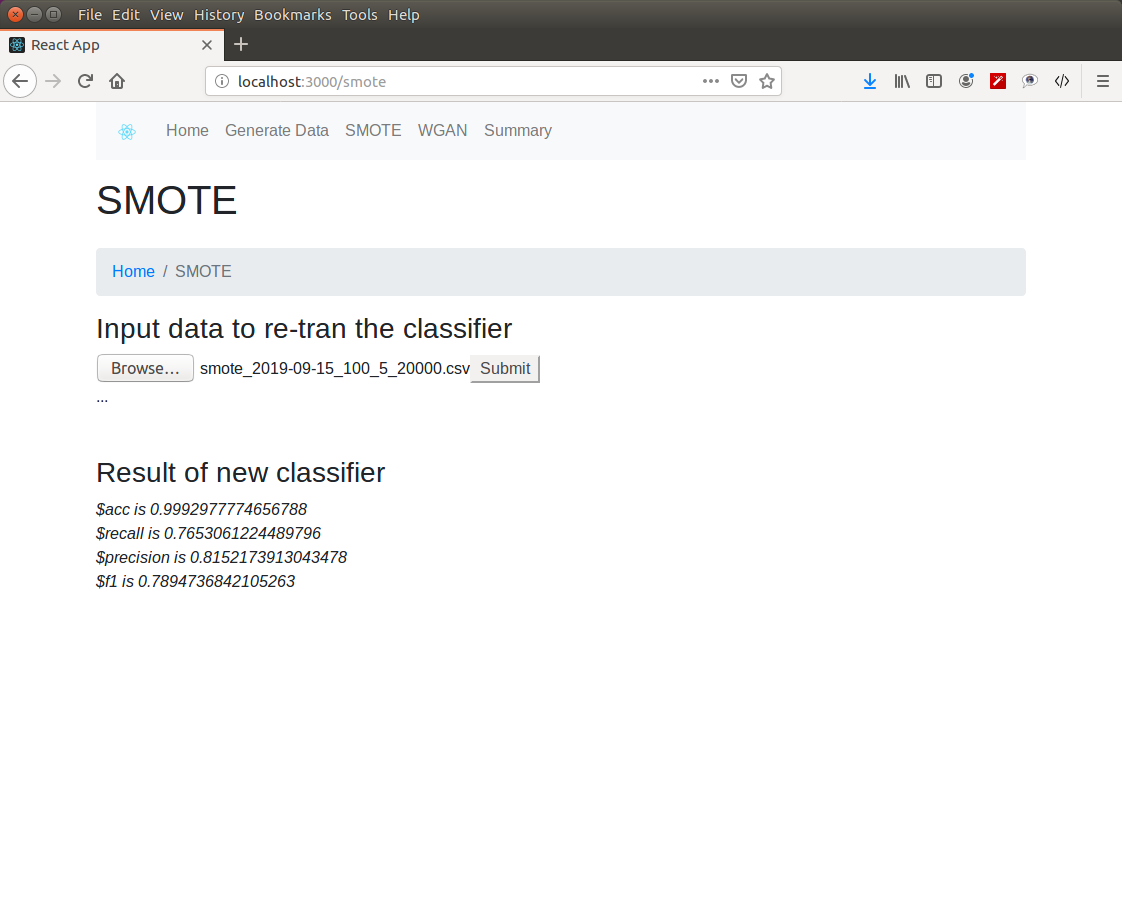
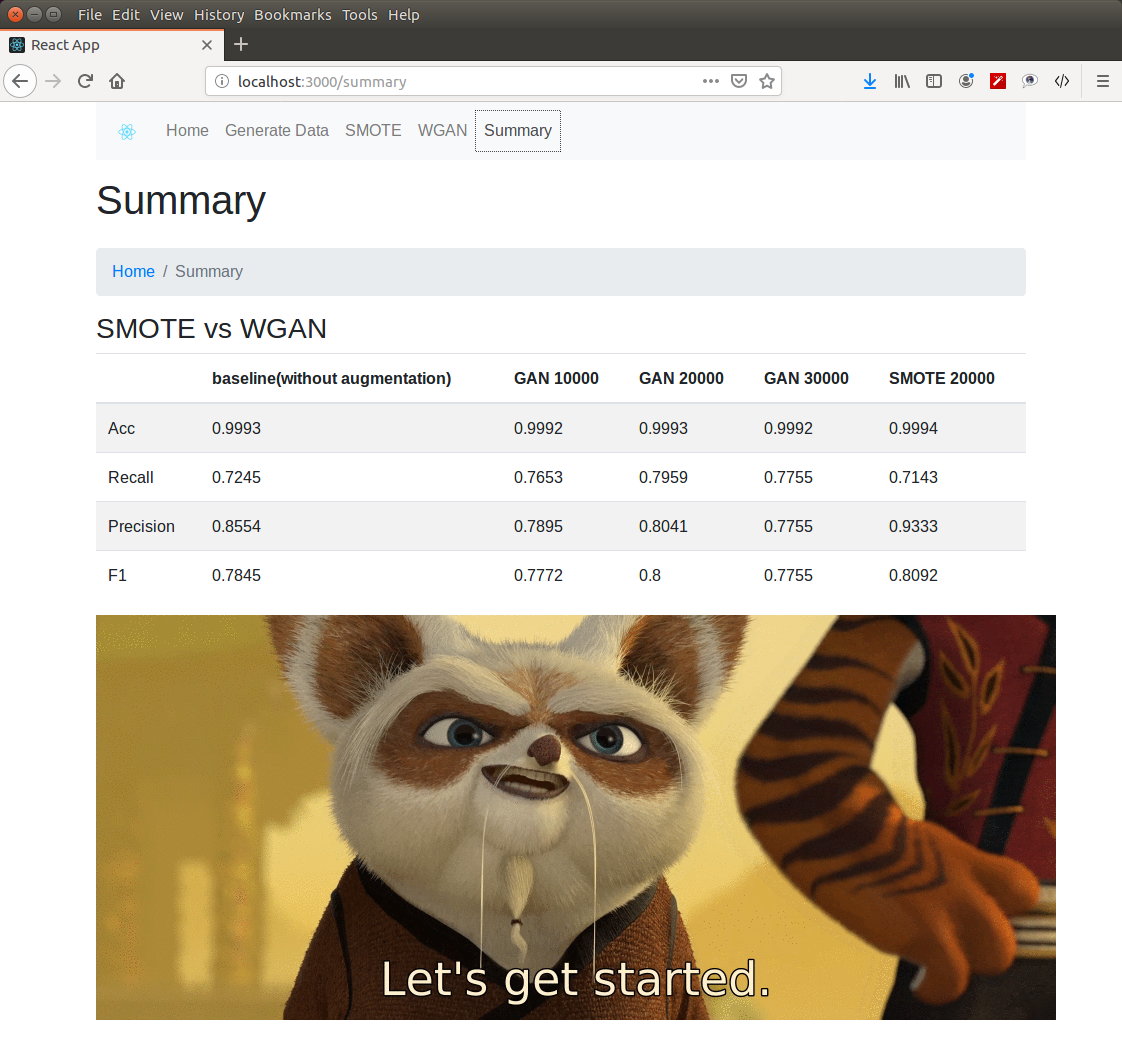
classification performance of SMOTE generated data
-
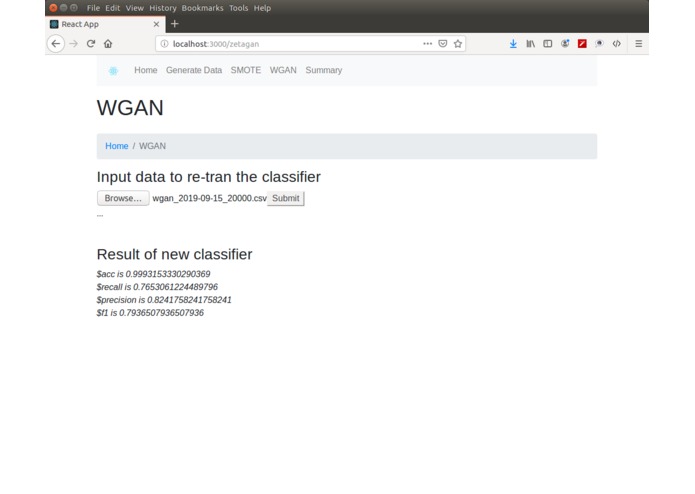
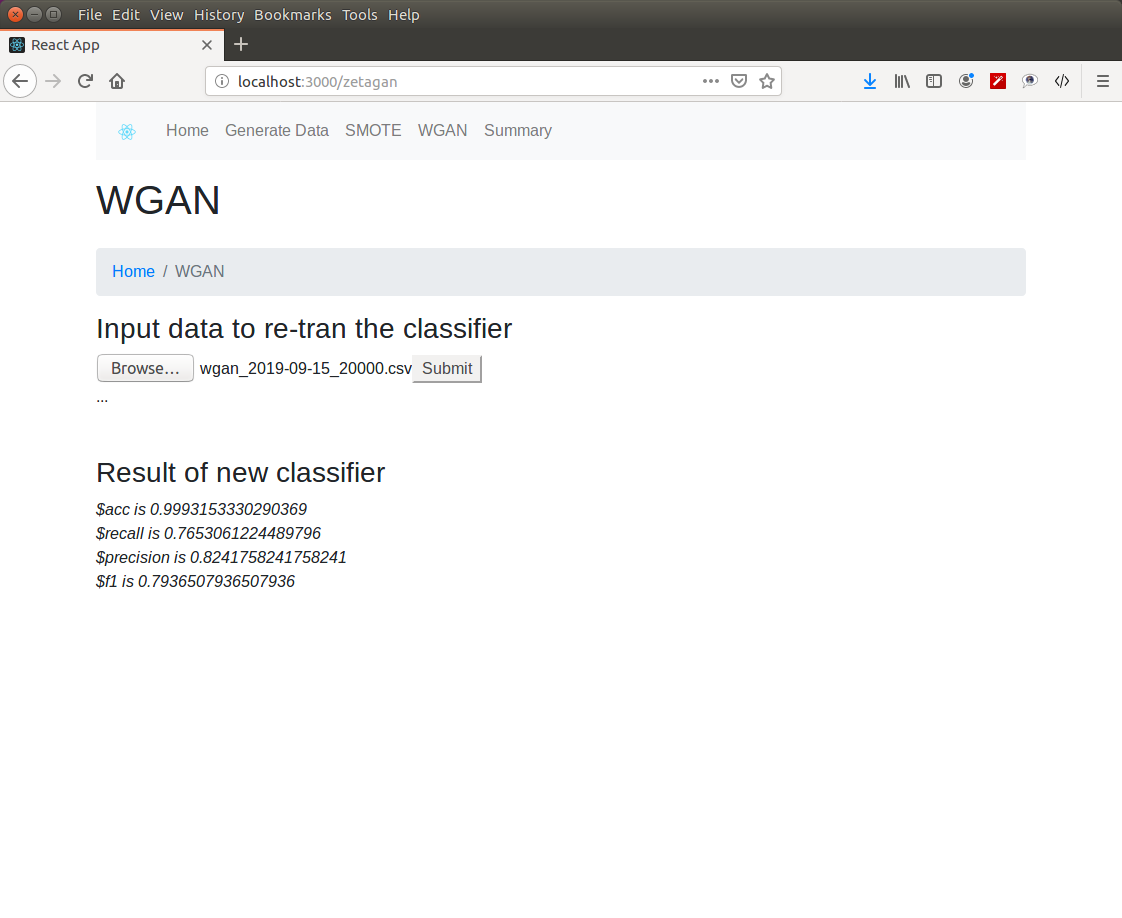
classification performance of WGAN generated data
-
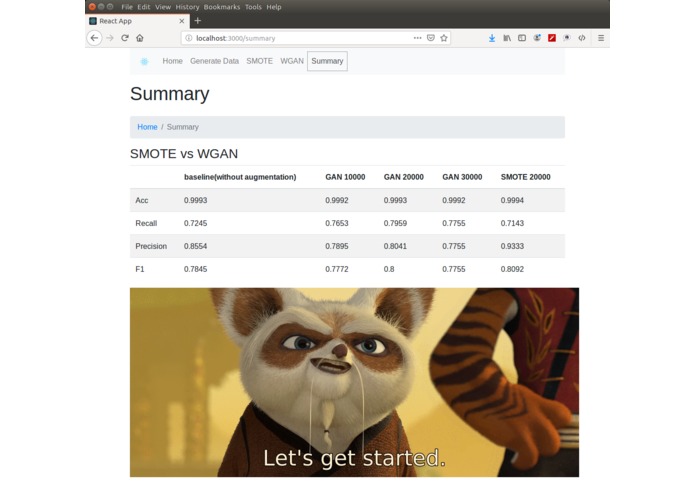
Summary page
-

The team


Inspiration
- Collecting data takes time: AI is powerful when there are numerous labelled data to train the model; however, data collection is time-consuming.
- Imbalanced data: Imbalance is common and expected in real world, e.g. Medical diagnosis, Spam filtering, and Fraud detection.
- Concern of data privacy: The concerns of data leak and privacy are increasing. It’s getting harder and harder to collect data due to new regulations and guidelines, e.g. GDPR.
What it does
- Generate Synthetic Samples, i.e. pseudo data, for structured/tabular data.
- The data’s schema, data distribution, and relationship between columns of the generated data are as close to real data as possible.
- The difference of statistical properties between synthetic and real data is slight.
- A Data Augmentation Platform to provide the data augmentation service with only small amount of data.
How we built it
- A Data Generation Model built with PyTorch to generate pseduo data for minority class.
- Train a single-hidden-layer MLP classifier built with PyTorch on pseudo data and part of real data. Testing dataset is the rest part of real data.
- Calculate the performance metric of testing dataset with PyTorch.
- Compare the performances between MLP classifiers trained on data with augmentation (by GANs and SMOTE respectively) and trained on data without augmentation
Structured datasets we used
- Credit Card Fraud Detection Dataset available on Kaggle:
- A target variable (0 or 1) with 0.172% are 1
- 30 independent variables: time, transaction amount, and 28 principal components
- Pima Indians Diabetes Database available on Kaggle:
- A target variable (0 or 1) with 34.896% are 1
- 8 independent variables: demographic attribute and vital signs
Challenges we ran into
- Among hundreds of GANs model, which one should we choose per the purpose of our project?
- How should we adjust the network’s parameters to encourage it to produce believable samples?
- Struggling with the integration of web platform given that we are unfamiliar with web backend and frontend techniques.
Accomplishments that we're proud of
Developing this project from consolidating idea to building a real web platform in a month! Every decision and every movement is made within quite short period of time, and we are really good at fast-learning!
What we learned
- GANs Models
- Over-sampling technique
- How to integrate the machine learning model with the web API into the web platform
What's next for Data Generation Service
- Modify the platform UI and add more features
- Try other algorithms for generating data, e.g. Condition GAN model
- Try to generate synthetic samples for unstructured data, e.g. image of license plate, text to speech
- Implement our methodology on different domains to help the world, e.g. Defect Inspection, rare disease diagnose
Built With
- flask
- gans
- python
- pytoch
- react
- scikit-learn
- smote





Log in or sign up for Devpost to join the conversation.