-
-
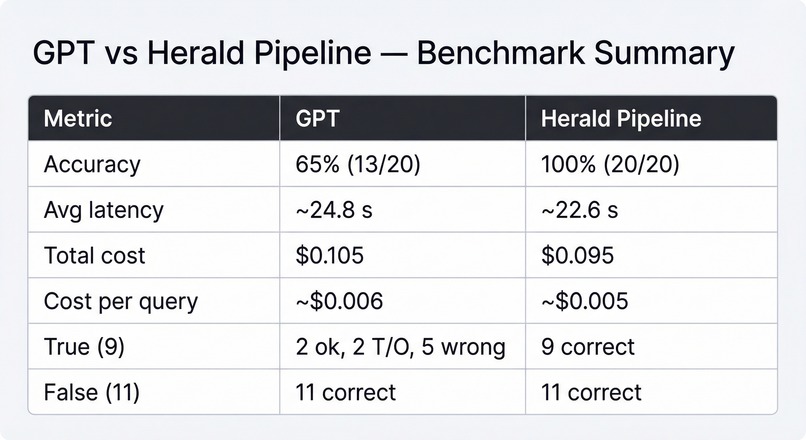
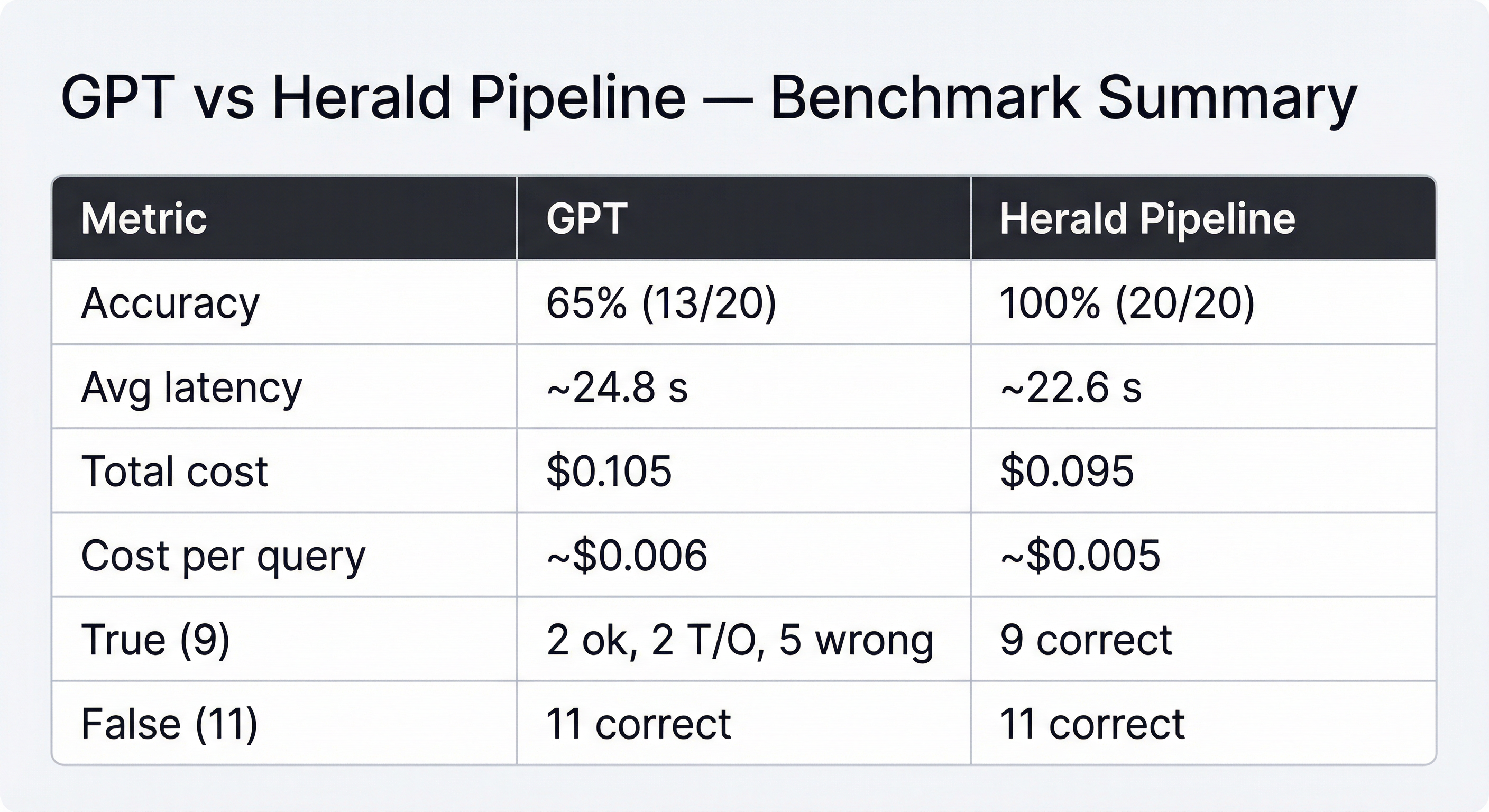
A comparison of an LLM call against our pipeline on a dataset of 20 relatively complex proofs in LaTeX
-
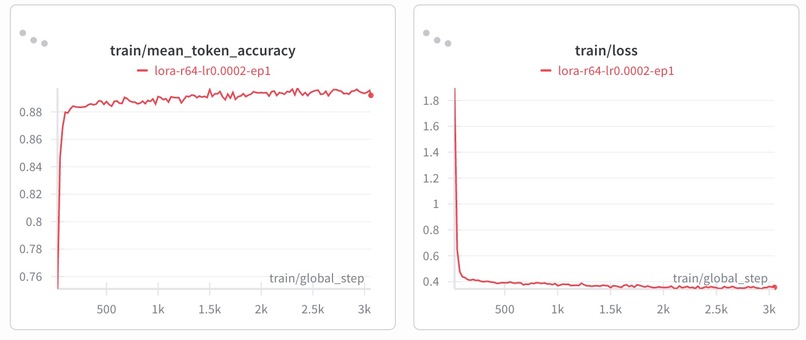
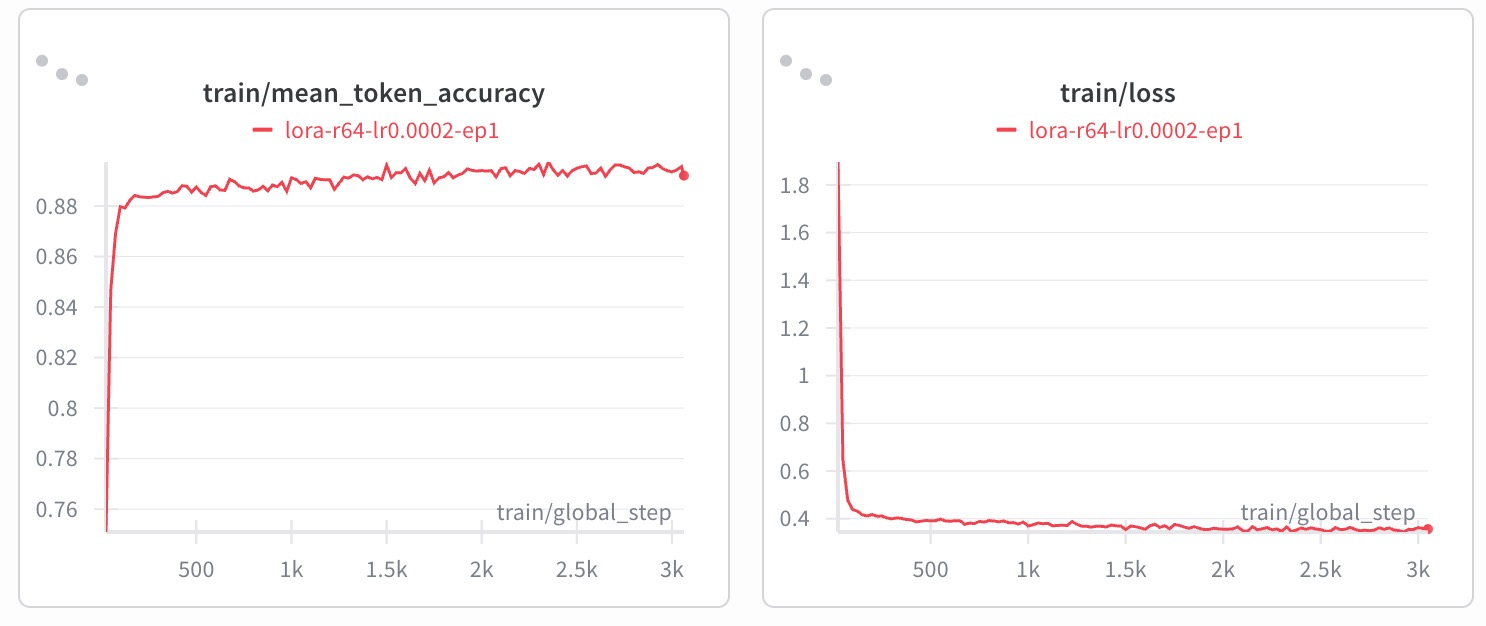
Finetuning the Herald_Translator with LoRA significantly improved the accuracy, reaching strong levels for a code task
-
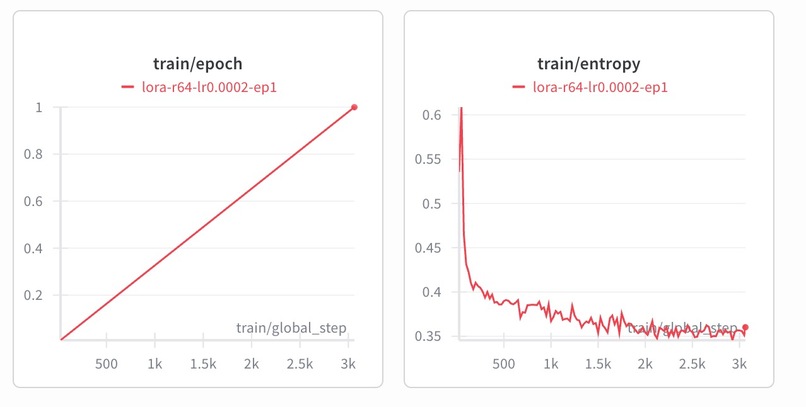
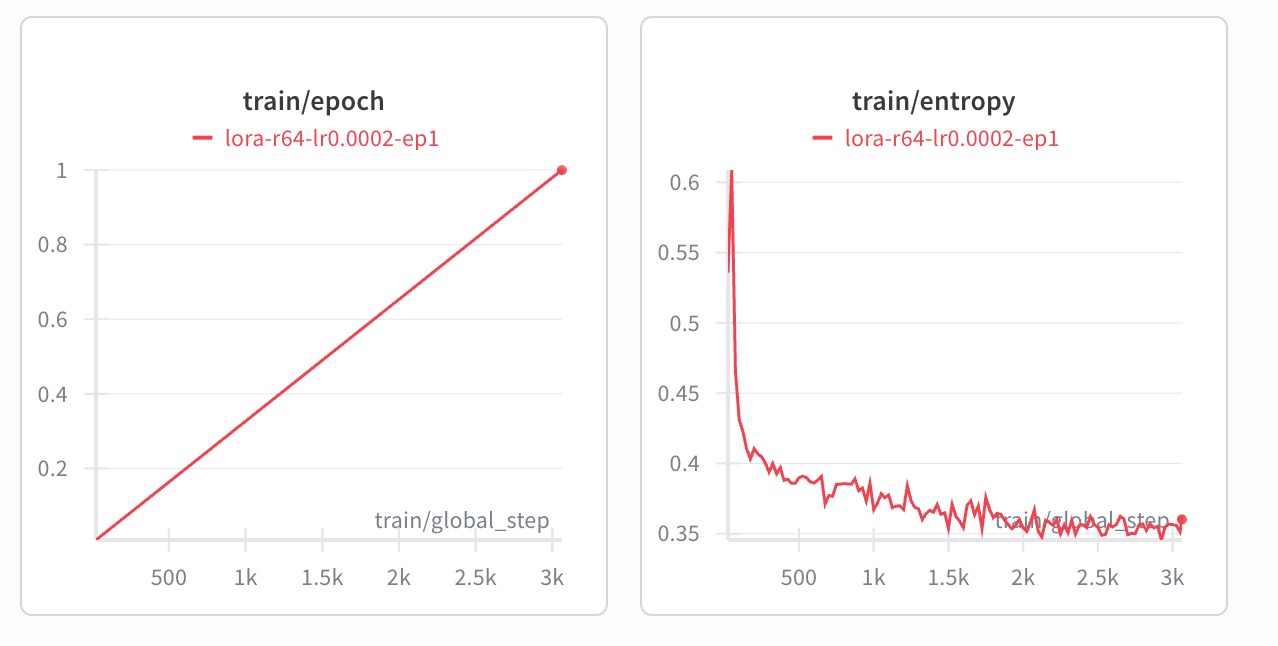
We finetuned with 3000 epochs, and as training progressed, the entropy of the model decreased as expected
Inspiration
As math and computer science majors, we’re often spending hours writing proofs in LaTeX, getting lost in paragraphs of LaTeX more times than we can count. Formal correctness is slow: you only find gaps when a TA grades it, often long after you’ve lost context. Instead, we wanted a Grammarly-like experience for proofs: immediate feedback as you write. Recent advances in neural theorem proving and informal-to-formal translation (Polu & Sutskever, 2020; Lewkowycz et al., 2022) indicate that it's possible to close the loop: highlight the exact step that’s wrong, explain why, and suggest a minimal fix in real time.
How it Works
Zeta is a Chrome extension for Overleaf that assists users with proof-writing, essentially acting as Grammarly for formal math. As users write, it intelligently chunks the document, translates each segment to Lean using a fine-tuned Herald_Translator model (Zhou et al., 2024), and compiles the result. Compilation errors are captured and passed to an LLM to generate precise, actionable feedback. In Thinking mode, Zeta adds an automated repair loop: Lean errors are iteratively fed back into the LLM until valid Lean code is produced or an iteration limit is reached. Once compilation succeeds, a final synthesis step generates structured feedback for the user based on the full repair trajectory.
Challenges we ran into
Robustness to semantic variation The translator’s performance degraded significantly under minor semantic perturbations in the LaTeX that didn’t affect the underlying proof logic. To address this, we fine-tuned Herald_Translator with LoRA on a dataset of systematically perturbed (accounting for how likely the typo was based on key positions), logically equivalent examples, improving invariance to typos.
Lean compilation errors Even when the LaTeX was correct, the generated Lean sometimes contained minor issues (e.g., type errors) that prevented compilation. We introduced a Thinking Mode with an automated repair loop: Lean compiler errors are fed back into the LLM, which iteratively patches the code until it compiles, stabilizes (no further changes), or reaches a preset iteration limit.
Axioms vs Theorems in Lean4 In Lean4, a theorem must be backed by a proof term that is fully verified by the kernel, but an axiom can just introduce a statement without proof and is accepted as true by assumption. In our project, translated Lean4 code would sometimes rely on undeclared assumptions. In some cases, introducing an axiom would allow compilation to succeed even when the formal proof was incomplete. As a result, we had to ensure that the translation and repair pipeline avoided introducing axioms as shortcuts to resolve proof failures. Instead, all results needed to compile strictly as theorems with explicit proof terms.
Accomplishments that we're proud of
We compared Zeta’s Herald-based pipeline against a ChatGPT-based baseline on a 20-problem benchmark (9 true, 11 false statements). The Herald pipeline achieved perfect correctness across both true and false cases while maintaining comparable latency and slightly lower cost. ChatGPT 4.1 struggled primarily on true proofs, where structural reasoning and proof-state consistency are required, highlighting the advantage of a specialized translation + repair pipeline over a single-pass LLM.
Fine-tuning Herald_Translator with LoRA (Hu et al., 2021) improved the accuracy on a perturbed evaluation set from 56% (base model) to 90% (LoRA fine-tuned), demonstrating significantly stronger invariance to semantically equivalent variations.
On the systems side, baseline inference latency on Modal was ~15–18 seconds per translation. Integrating vLLM (Kwon et al., 2023) reduced this to ~3 seconds per call across 100+ runs, making real-time Overleaf feedback feasible.
What we learned
We learned that translation from informal mathematics to formal language is highly sensitive to surface variation and implicit assumptions. We also saw how ambiguity in LaTeX conventions and library usage (e.g., implicit definitions, overloaded notation, unstated algebraic structures) creates failure modes during translation. Formal systems perform a lot better when provided with explicit structure, types, and hypotheses, and informal answers often omit those. Bridging that gap is the most difficult part of robust translation and feedback.
What's next for Zeta
While Zeta performs strongly, several clear avenues remain for improvement. First, the iterative repair model could be strengthened by training of a repair model on Lean error–correction trajectories and optimizing for convergence speed under structured compiler feedback. Second, both translation and repair should be conditioned on a richer representation of the Lean proof state. Instead of relying primarily on raw error messages, incorporating structured goal states and type information would allow the model to reason directly over formal constraints. Finally, we could train a dedicated model to map repair trajectories and compiler outputs into high-quality natural language guidance, using human responses (e.g., whether the feedback resolved confusion or improved the proof) as a post-training signal.
References
Hu et al. (2021). LoRA: Low-Rank Adaptation of Large Language Models.
Kwon et al. (2023). vLLM: Easy, Fast, and Cheap LLM Serving with PagedAttention.
Lewkowycz et al. (2022). Solving Quantitative Reasoning Problems with Language Models.
Polu & Sutskever (2020). Generative Language Modeling for Automated Theorem Proving.
Zhou, X., et al. (2024). Herald: Neural Translation from LaTeX to Lean for Formal Verification.
Built With
- amazon-web-services
- fastapi
- lean4
- lora
- modal
- peft
- pytorch
- vllm
- wandb




Log in or sign up for Devpost to join the conversation.