-
-
Plataforma
-
Motor
-
Dominios
-
Métrica
-

Empresas
-
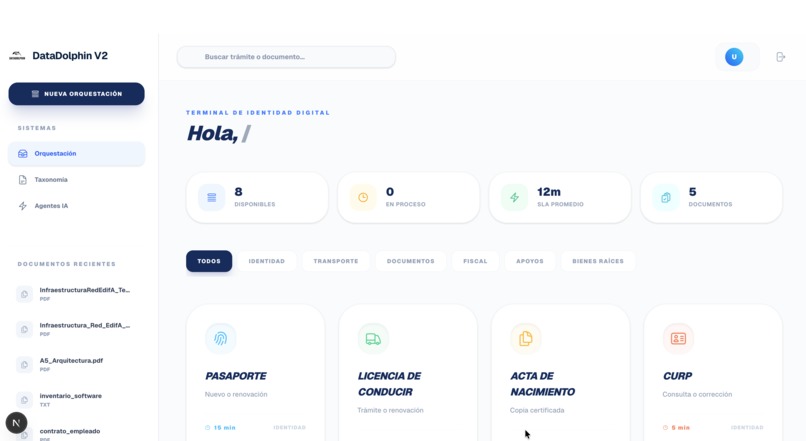
Dashboard
-
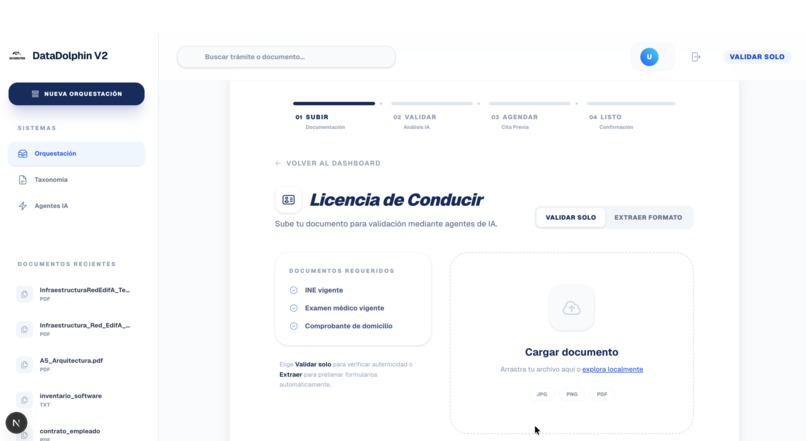
Procesos con IA
-
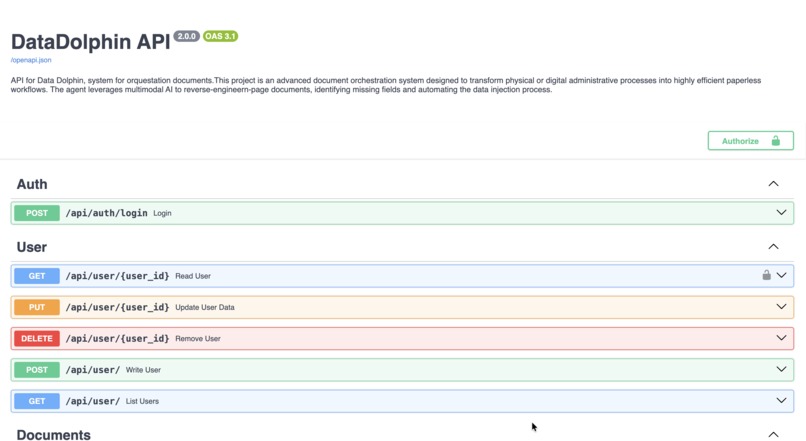
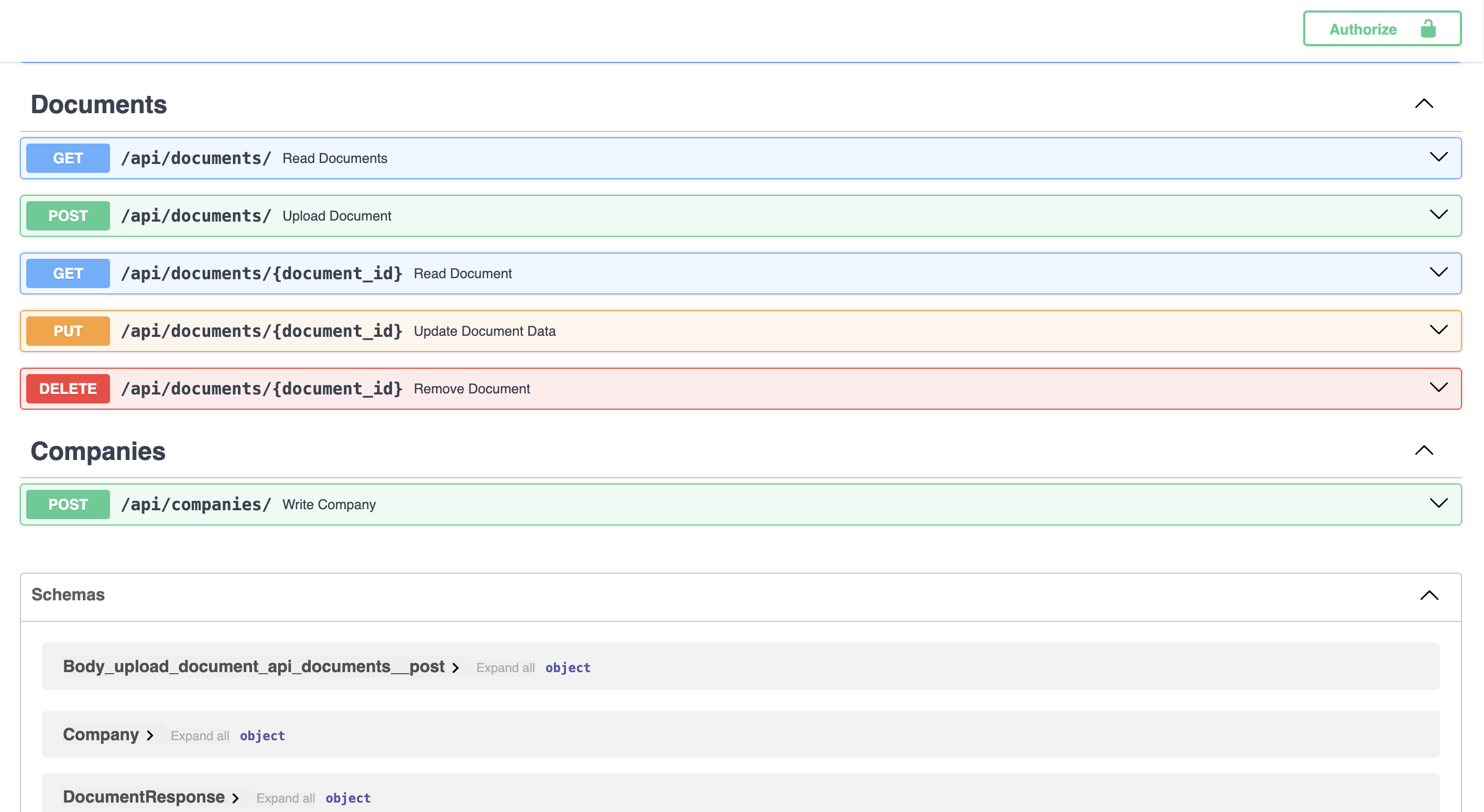
API
-
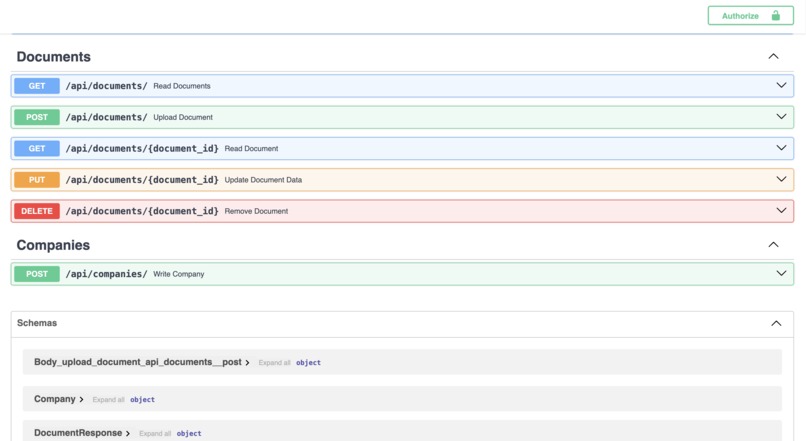
API
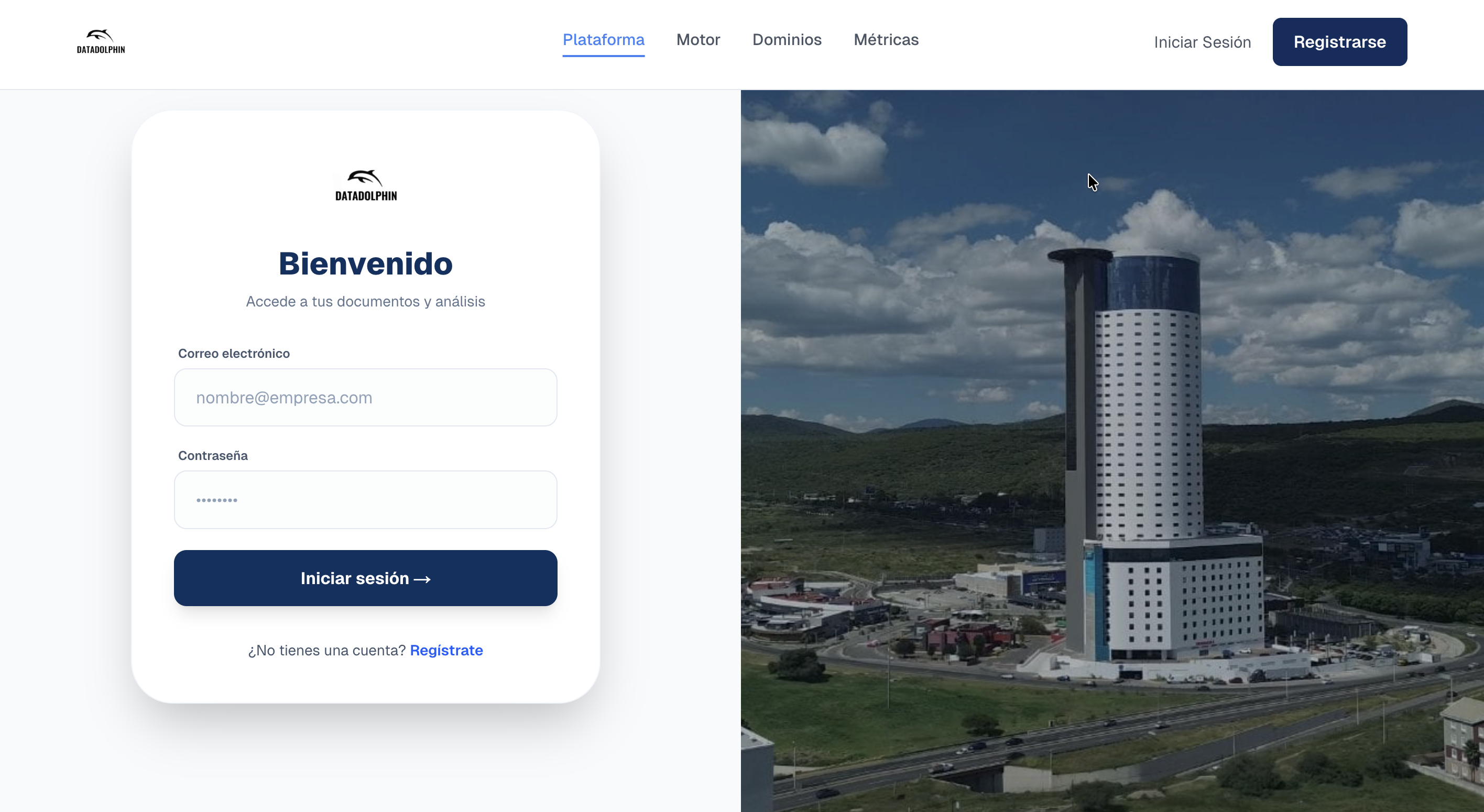
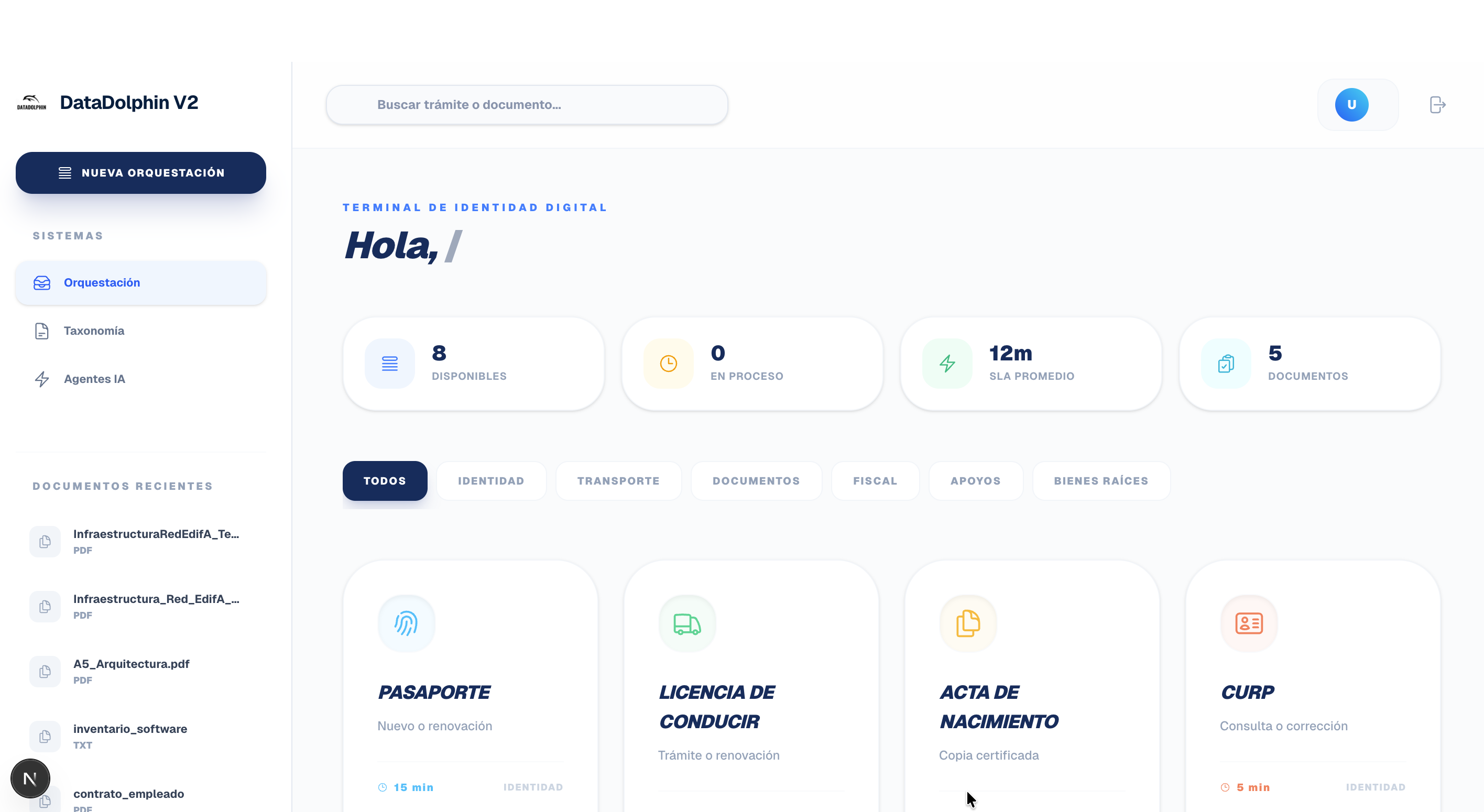
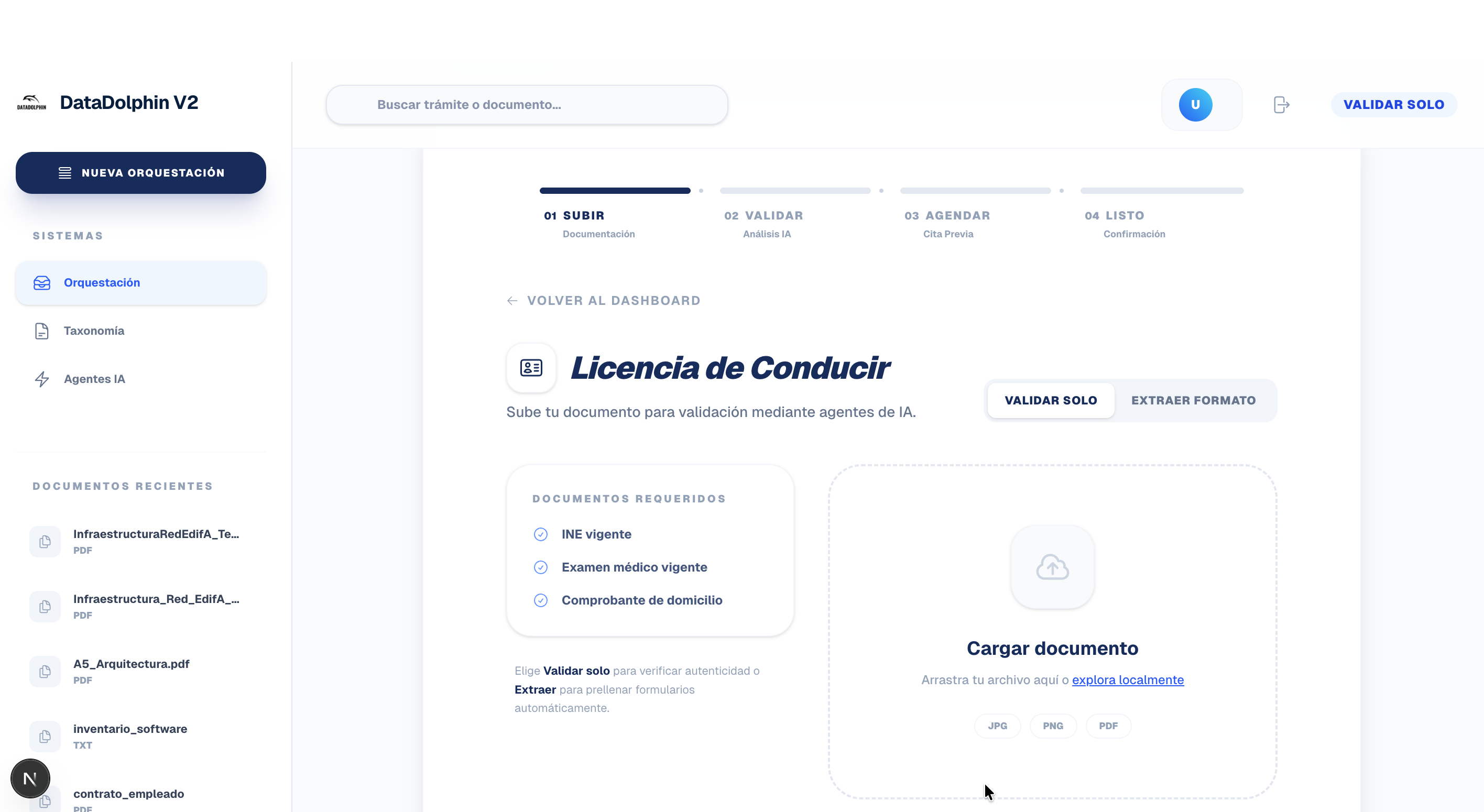
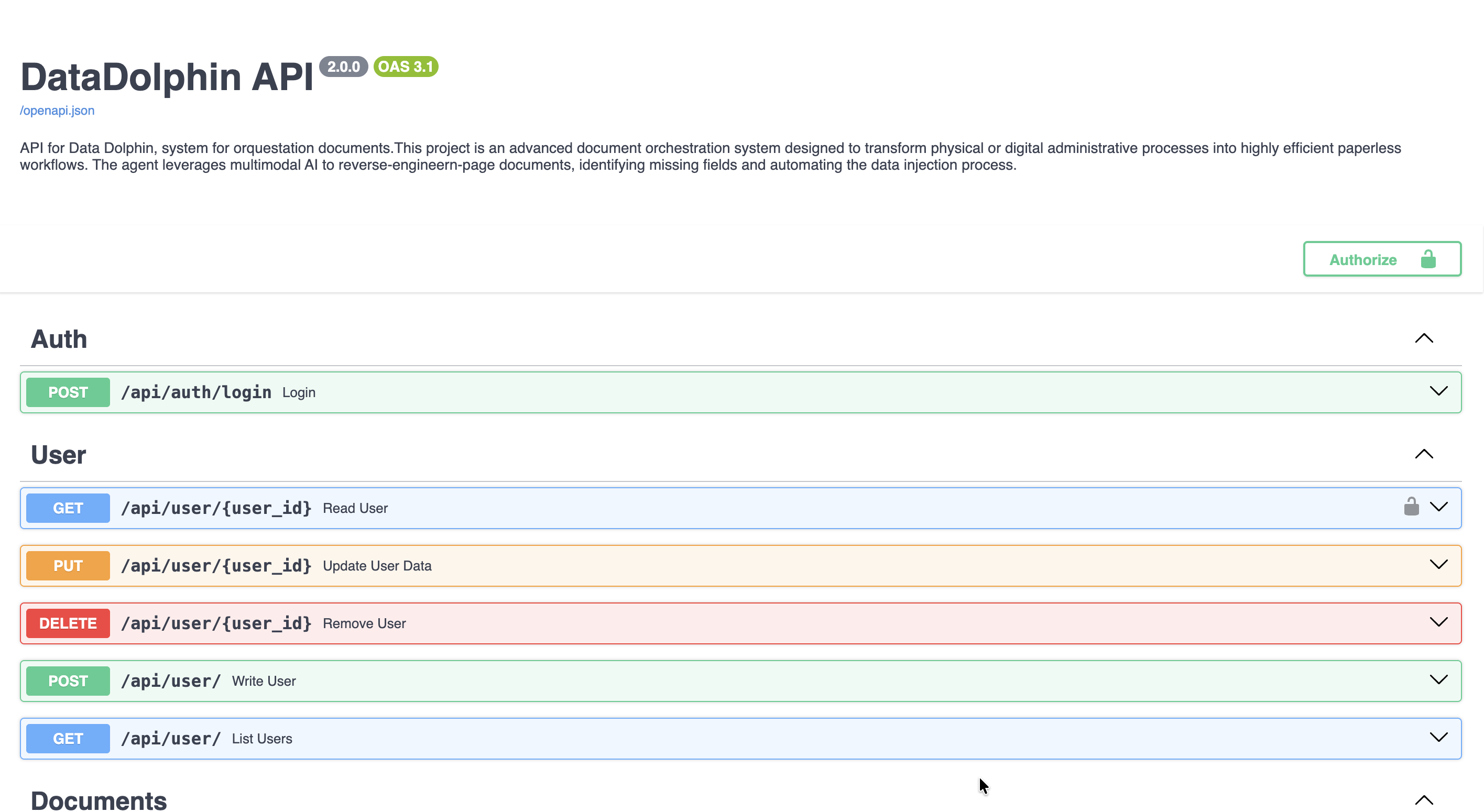
Inspiración
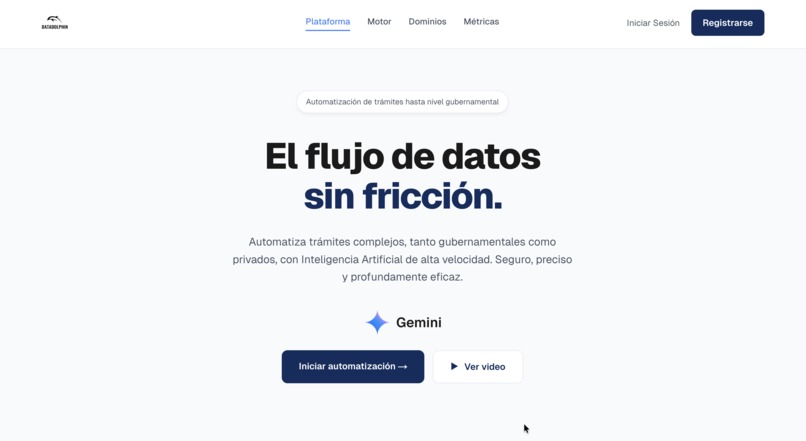
El verdadero reto no es recolectar datos, sino entenderlos. El propósito de DataDolphin V2 es realizar una ingeniería inversa de documentos para entender su estructura profunda, desde registros fiscales hasta normativas internacionales.
¿Qué hace?
DataDolphin V2 es una plataforma avanzada de orquestación y clasificación semántica que utiliza IA multimodal para automatizar trámites de nivel gubernamental y privado.
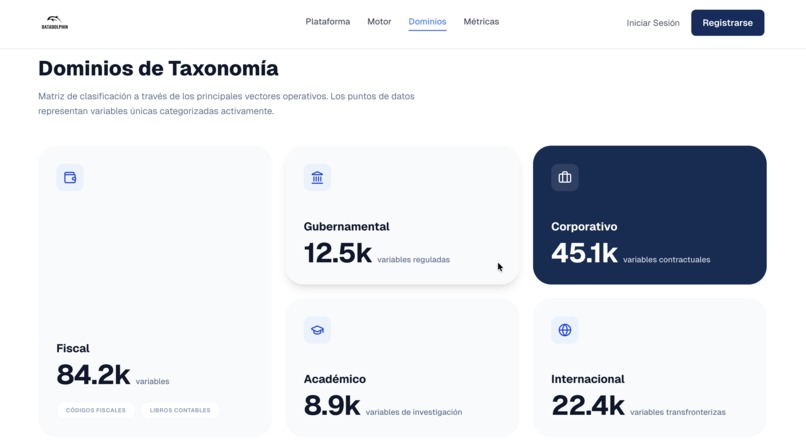
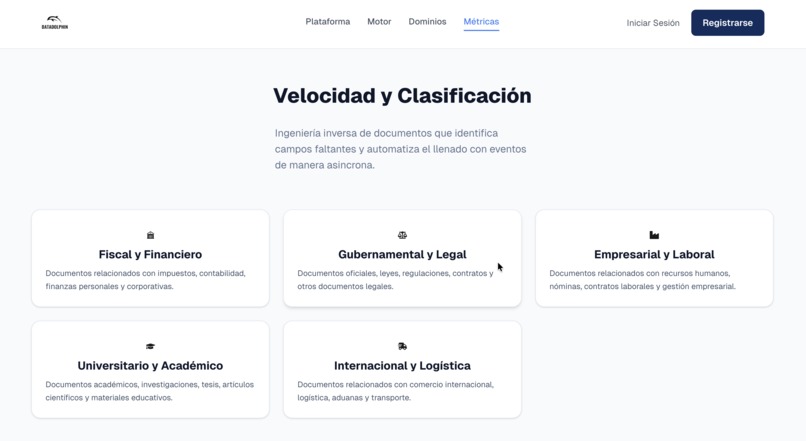
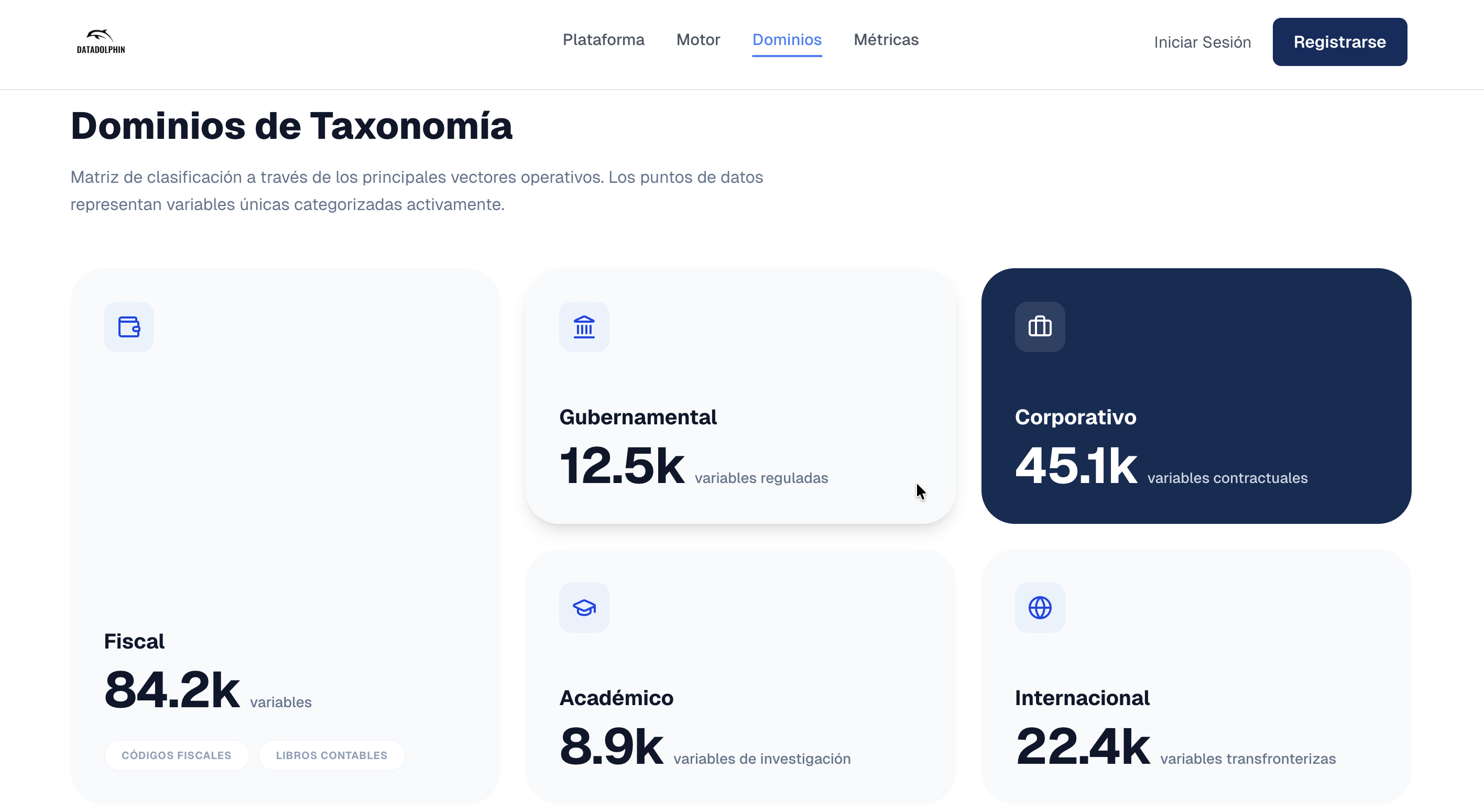
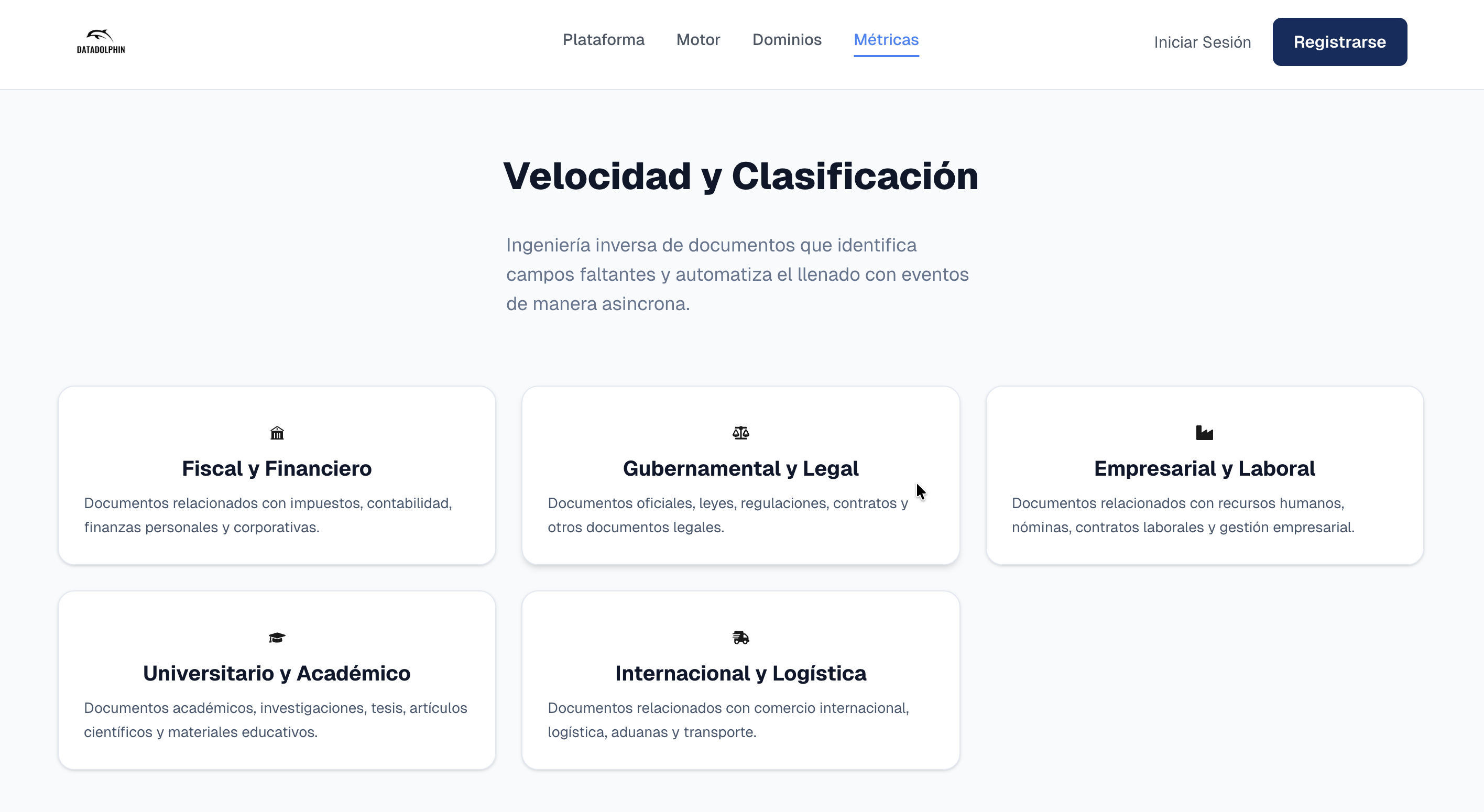
El sistema identifica campos faltantes y automatiza el llenado de procesos administrativos, clasificando variables a través de 5 vectores operativos principales:
- Fiscal: Manejo de códigos fiscales y libros contables.
- Gubernamental: Control de variables reguladas.
- Corporativo: Gestión de variables contractuales.
- Académico: Organización de datos de investigación.
- Internacional: Procesamiento de datos transfronterizos.
¿Cómo lo construimos?
La arquitectura de DataDolphin V2 se divide en tres capas técnicas fundamentales para garantizar el rendimiento y la precisión del agente:
Capa de Presentación (Frontend)
Interfaz desarrollada para la gestión y visualización de datos de alta densidad:
- Next.js: Framework de React para el manejo de rutas y renderizado optimizado.
- TypeScript: Implementación de tipado estricto para asegurar la escalabilidad del código.
- Tailwind CSS: Framework de diseño utilizado para la creación de componentes modulares y la matriz de taxonomía.
Capa de Inteligencia y Orquestación
Núcleo operativo basado en agentes autónomos supervisados:
- Lógica basada en habilidades: Comportamiento del agente definido mediante una matriz de competencias en SKILL.md y configuraciones dinámicas en agent.yaml.
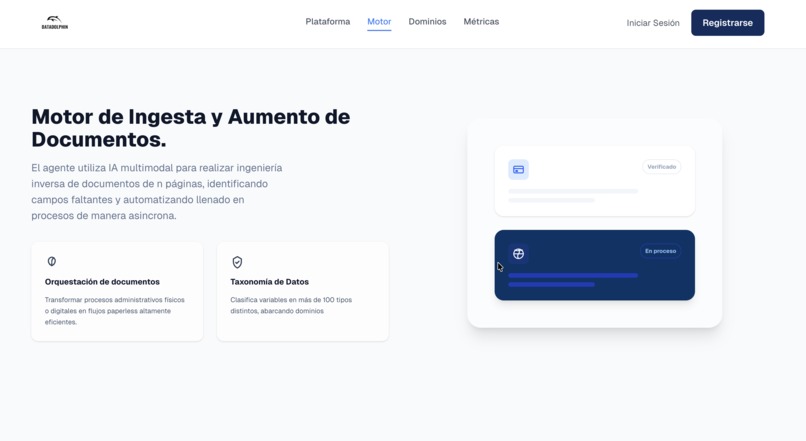
Capa de Procesamiento de Documentos
Módulo especializado en la extracción y análisis estructural de archivos:
- Python: Lenguaje principal para el procesamiento lógico y manejo de metadatos.
- PyMuPDF: Librería técnica utilizada para realizar ingeniería inversa en documentos, permitiendo la extracción precisa de coordenadas y contenido en archivos de múltiples páginas.
Requerimientos de Visión y Extracción (Percepción)
El agente no solo debe "leer", debe "ver" la estructura.
Detección de Geometrías (Bounding Boxes): La lógica debe identificar líneas continuas (____), rectángulos de formulario y espacios en blanco masivos.
Built With
- claude
- figma
- gemini
- git
- github
- next.js
- openrouteservice
- postgresql
- python
- react
- tailwind-css
- typescript
- vercel



Log in or sign up for Devpost to join the conversation.