-
-
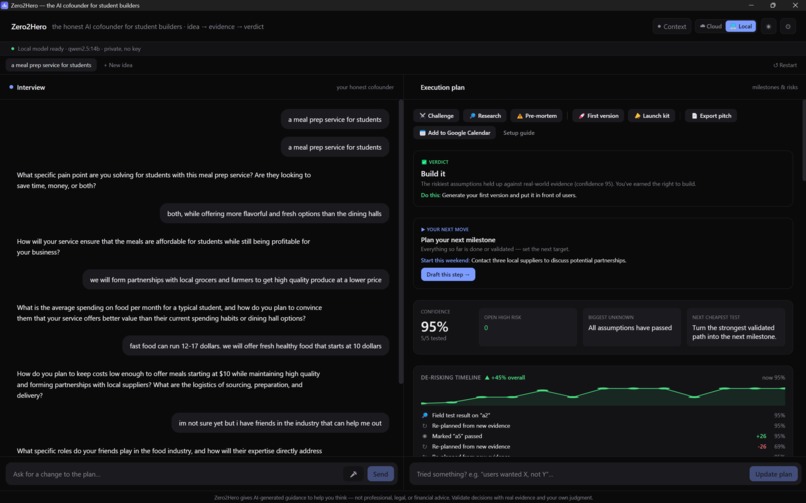
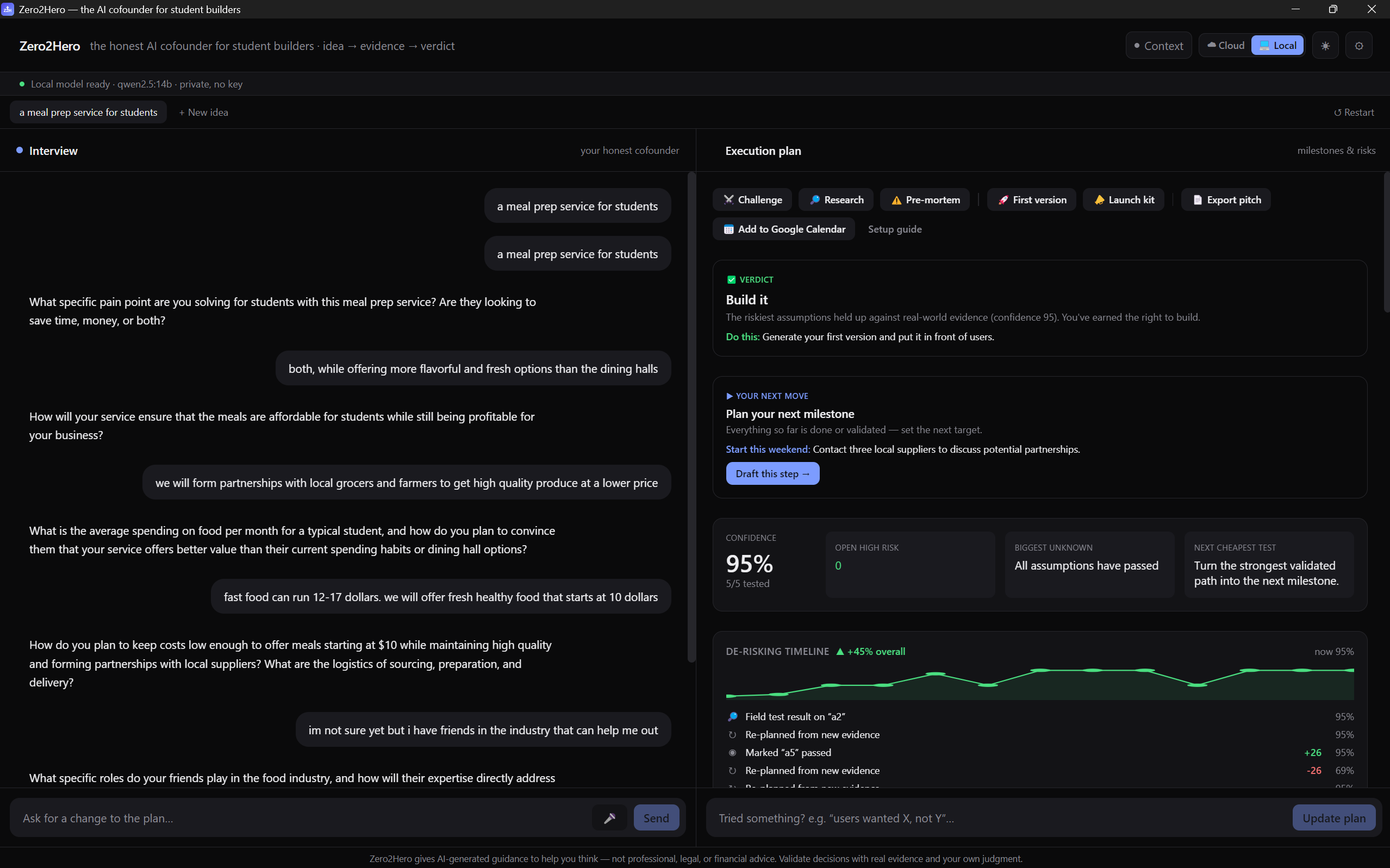
Zero2Hero home page with interview and execution plan pages
-
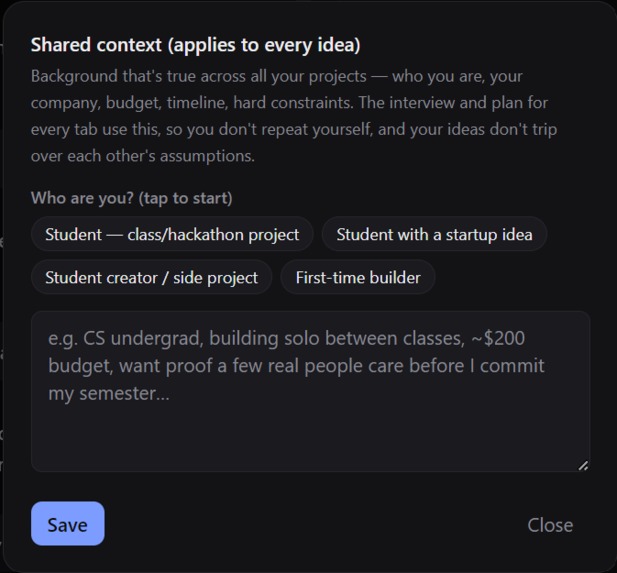
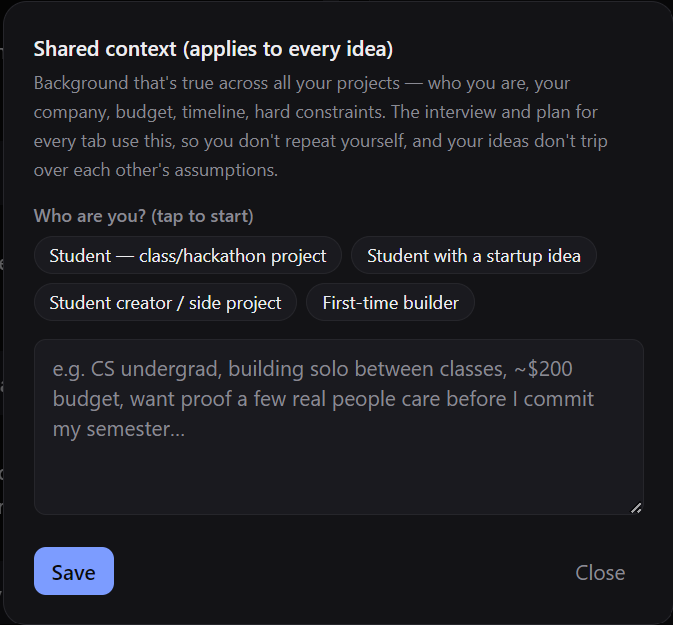
Context page to provide personal info such as budget, other commitments, etc.
-
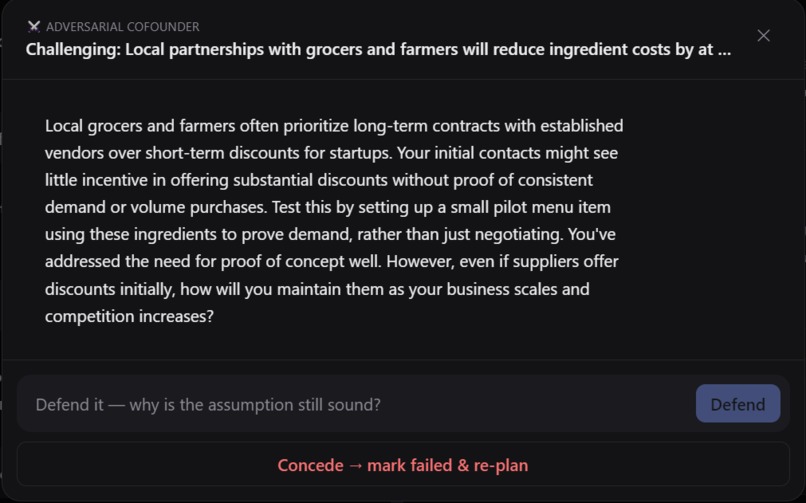
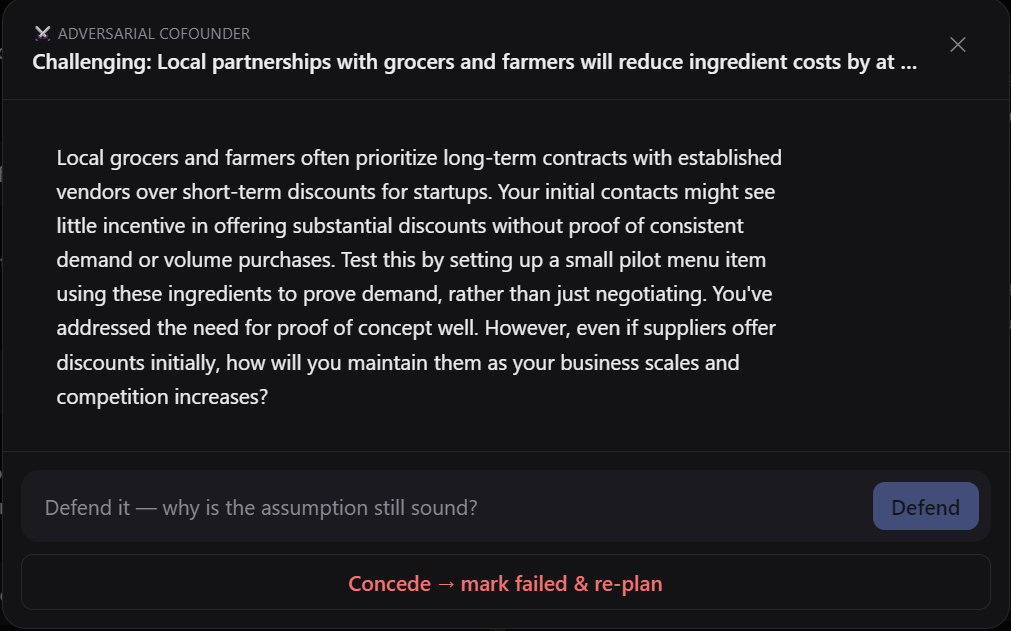
Adversarial Cofounder that challenges your assumptions and forces you to address core parts of you idea
-
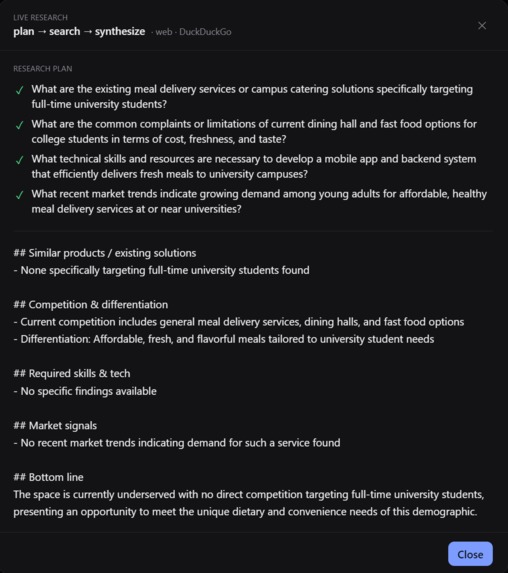
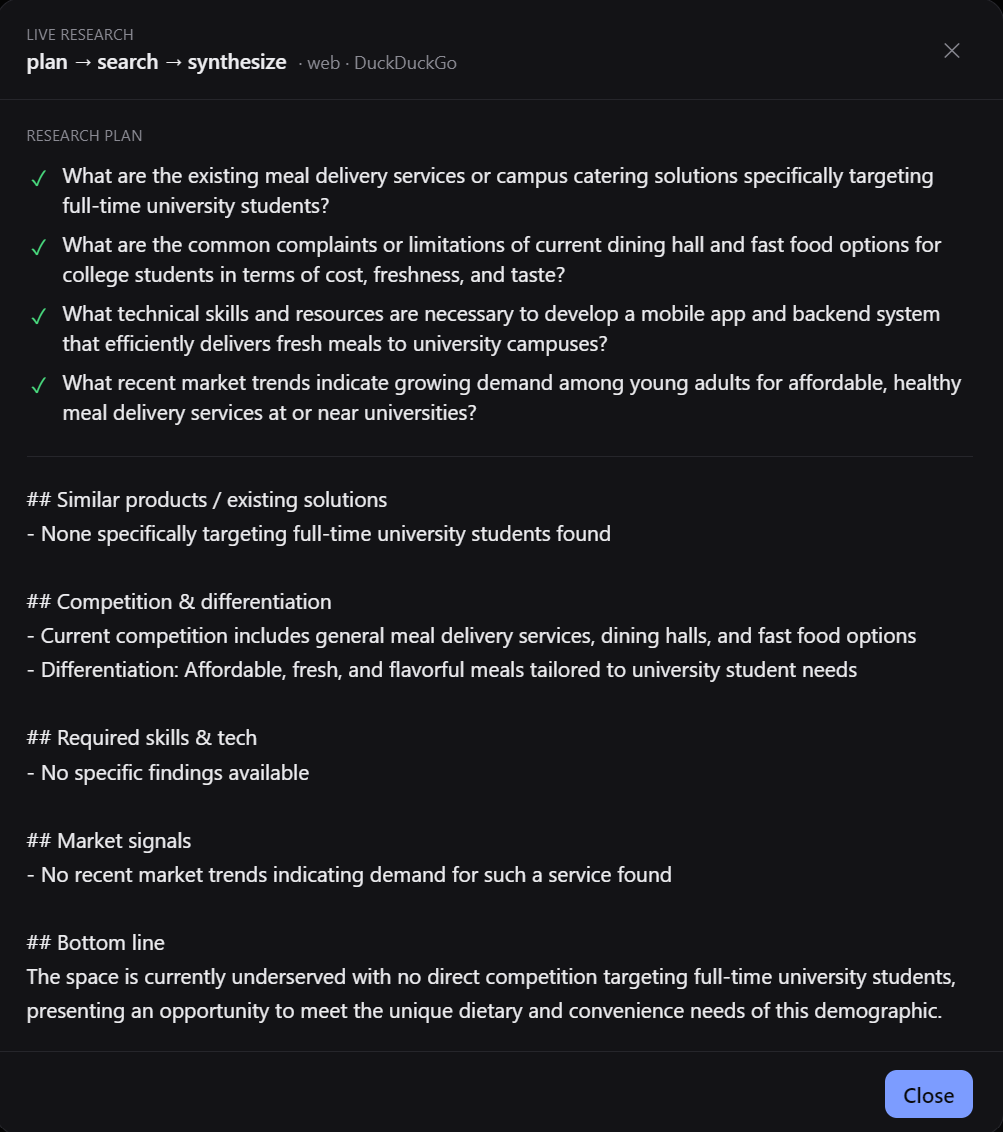
Research tab that finds relevant information to aid in the execution page
-
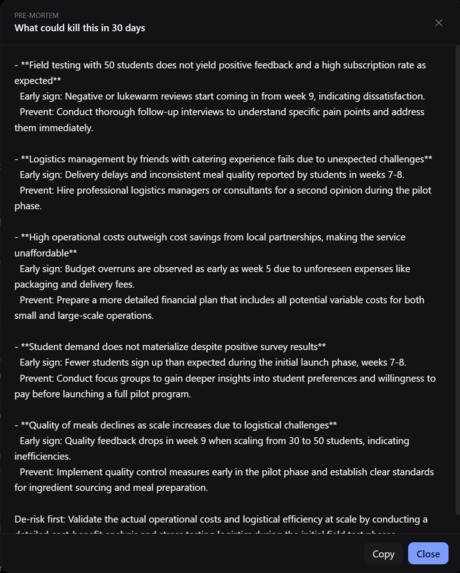
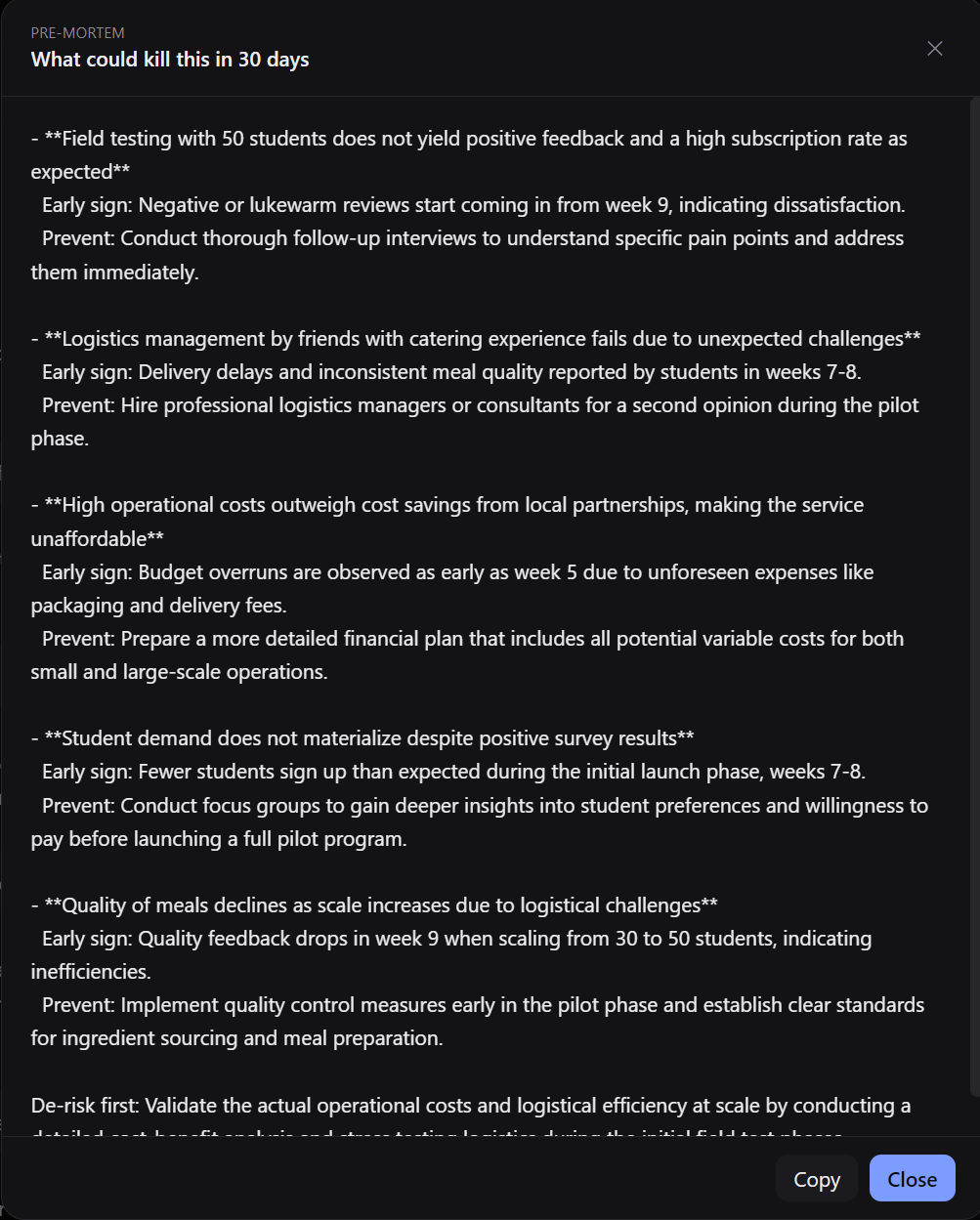
Pre-mortem that lets the founder know what to watch out for and the potential issues that could kill the project in the first 30 days
-
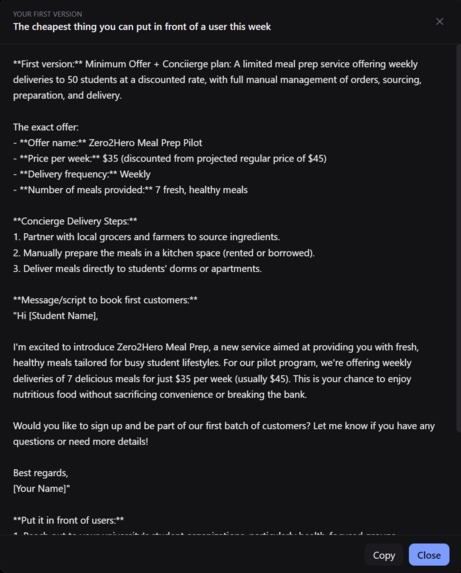
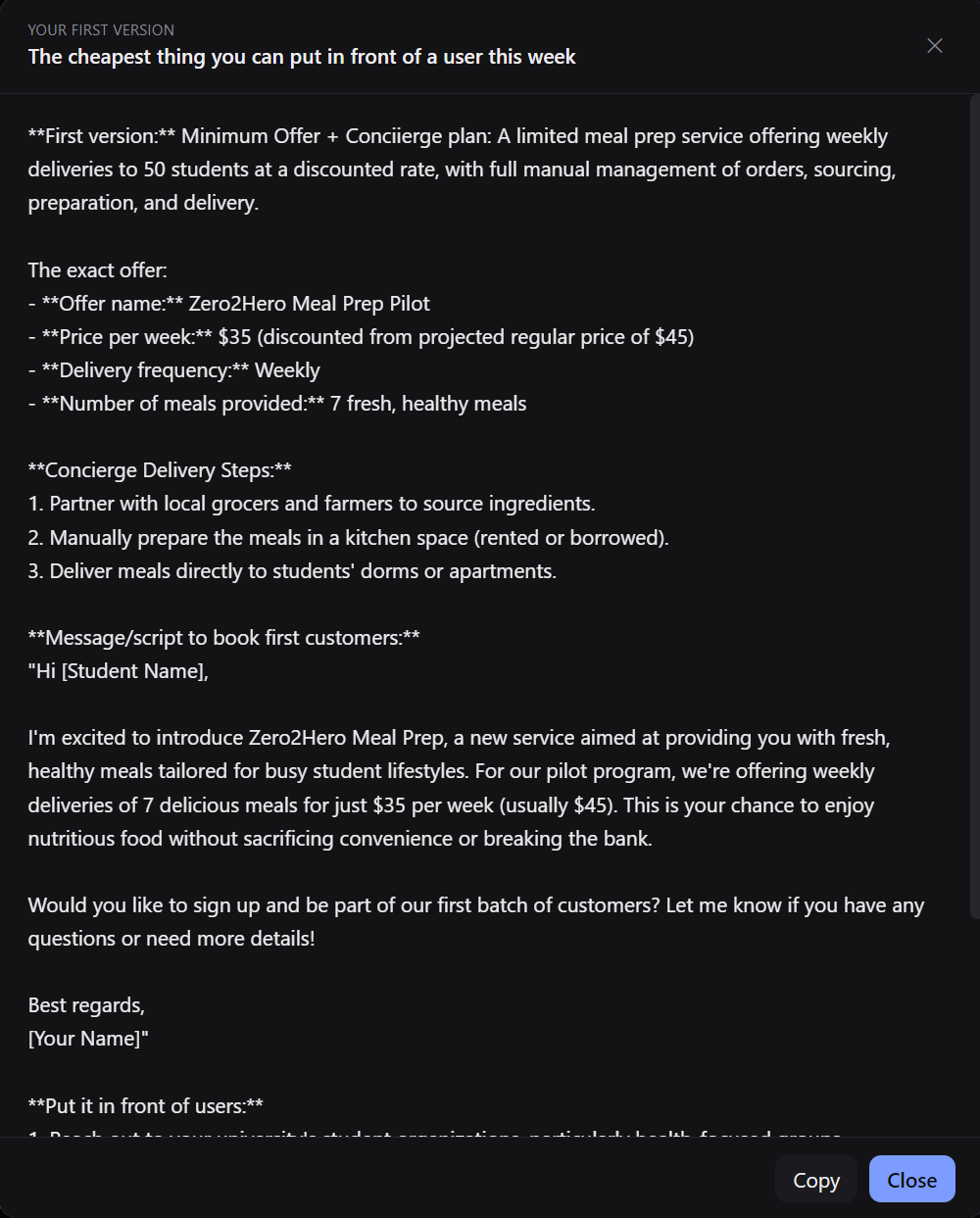
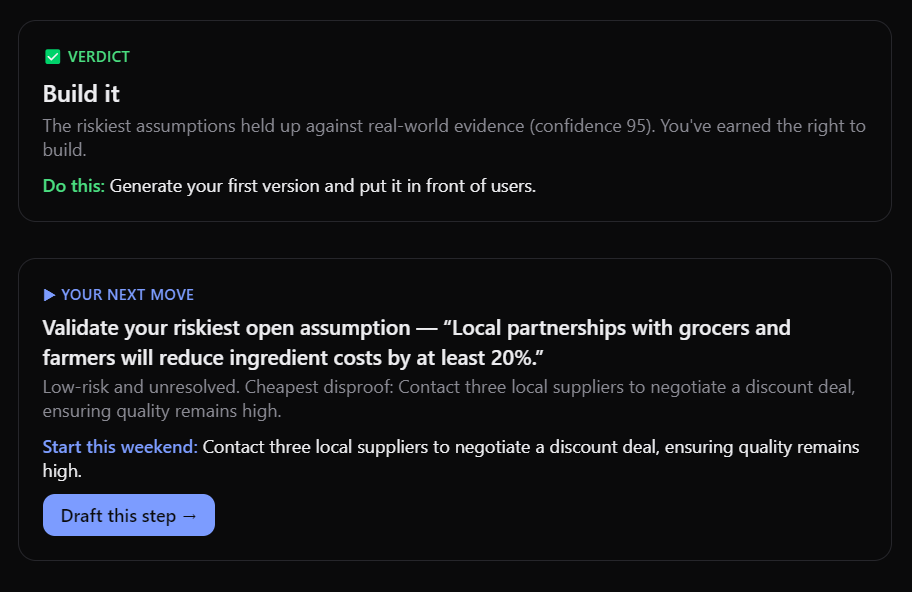
First Version tab that gives you the exact template for what you could serve in front of a user this week. Cheap and dirty execution
-
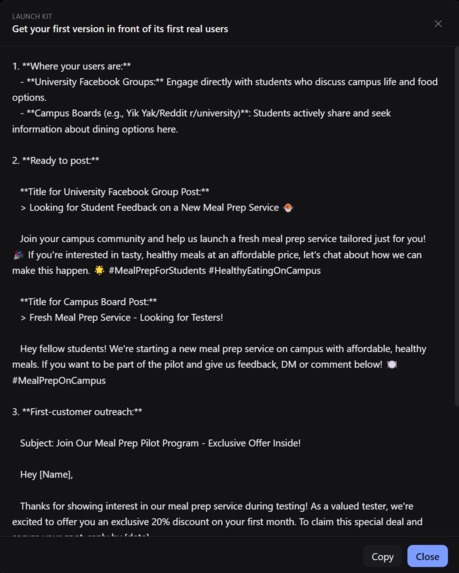
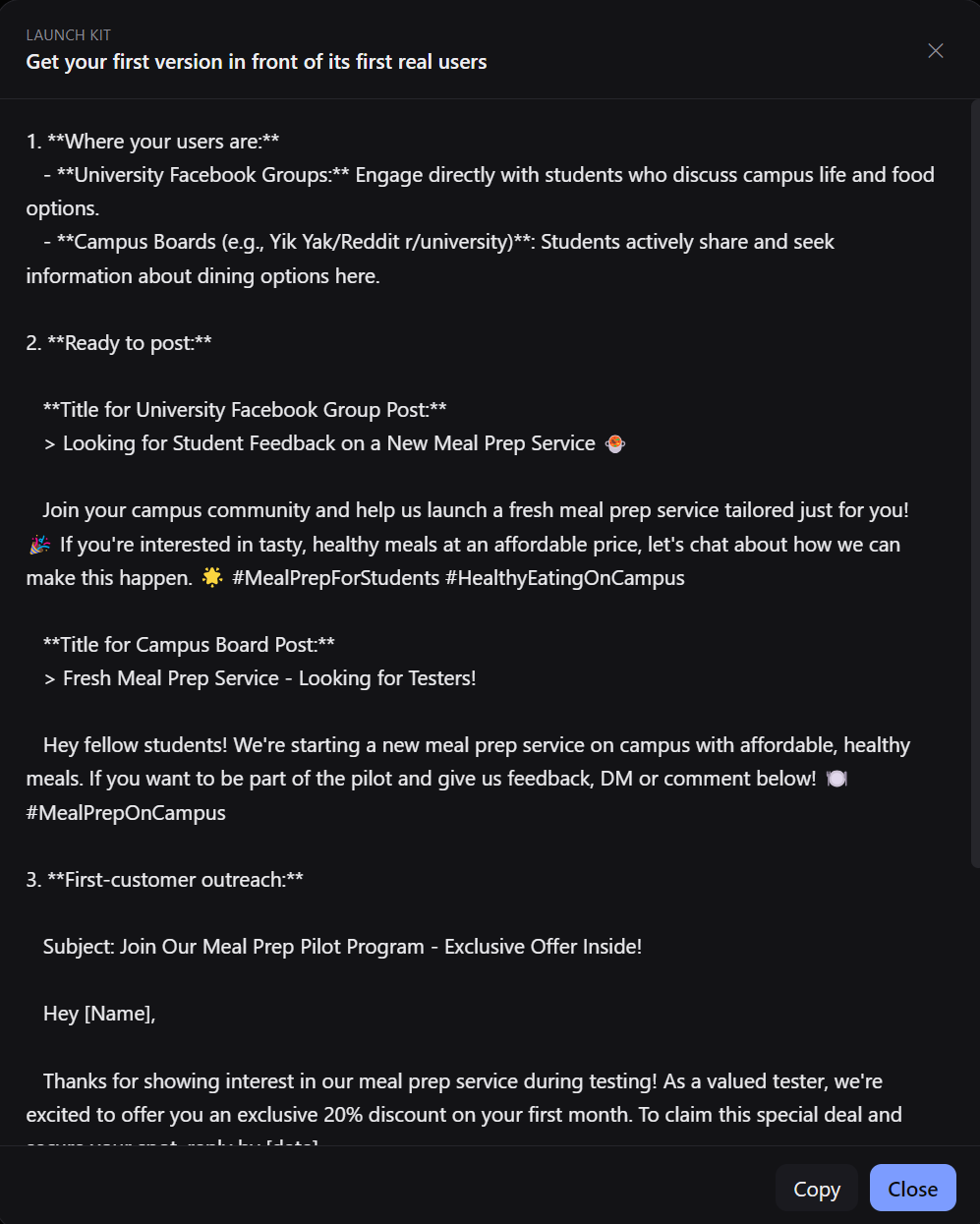
Launch Kit tab that helps you find exactly where your audience is likely to be located and a drafted launch post to drop in
-
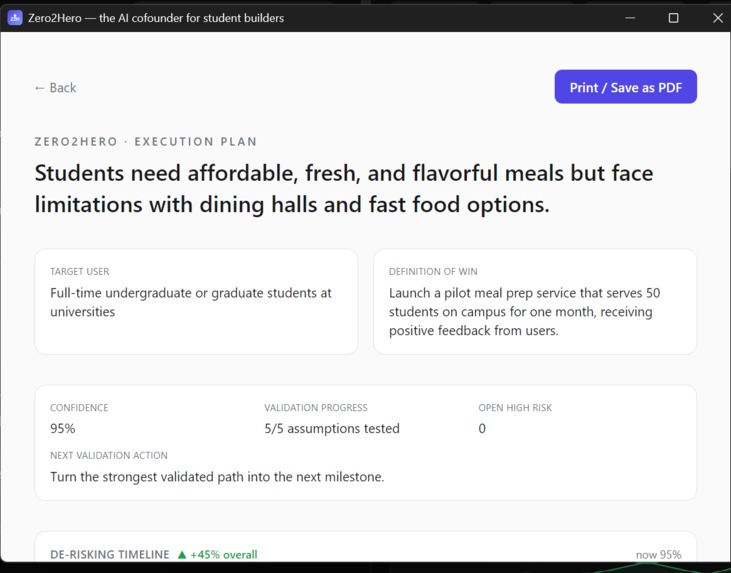
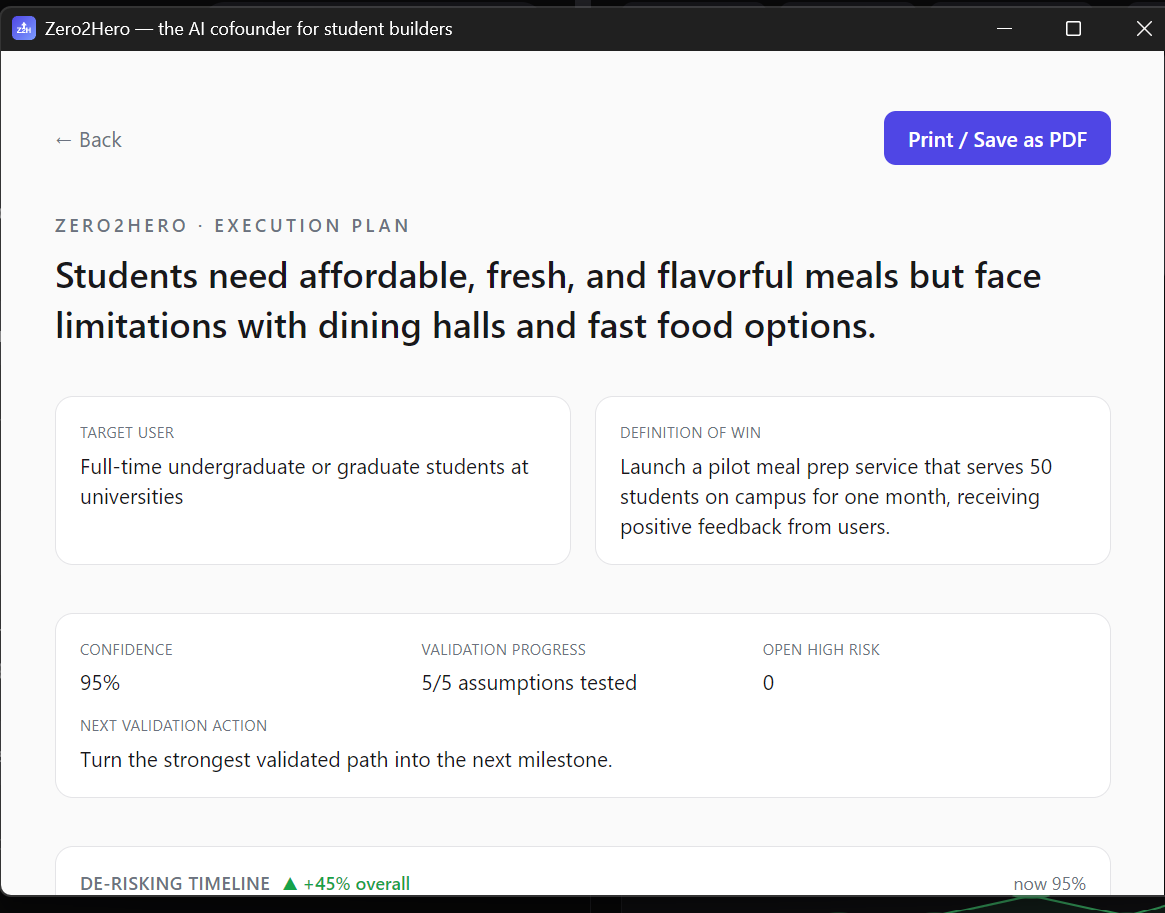
Export Pitch page that lets you export the execution plan at any time as a PDF
-
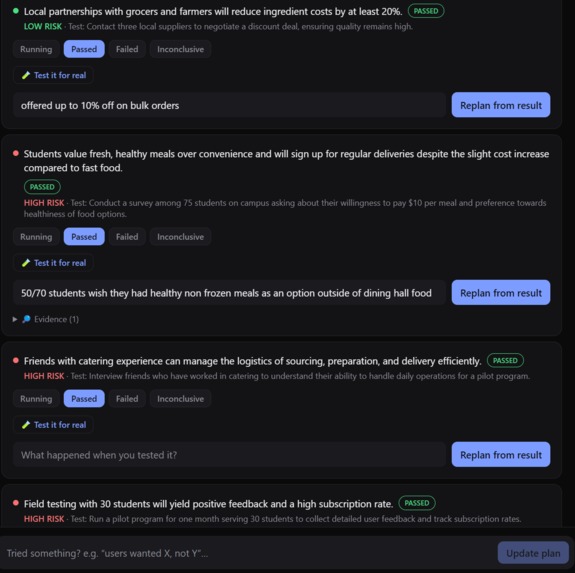
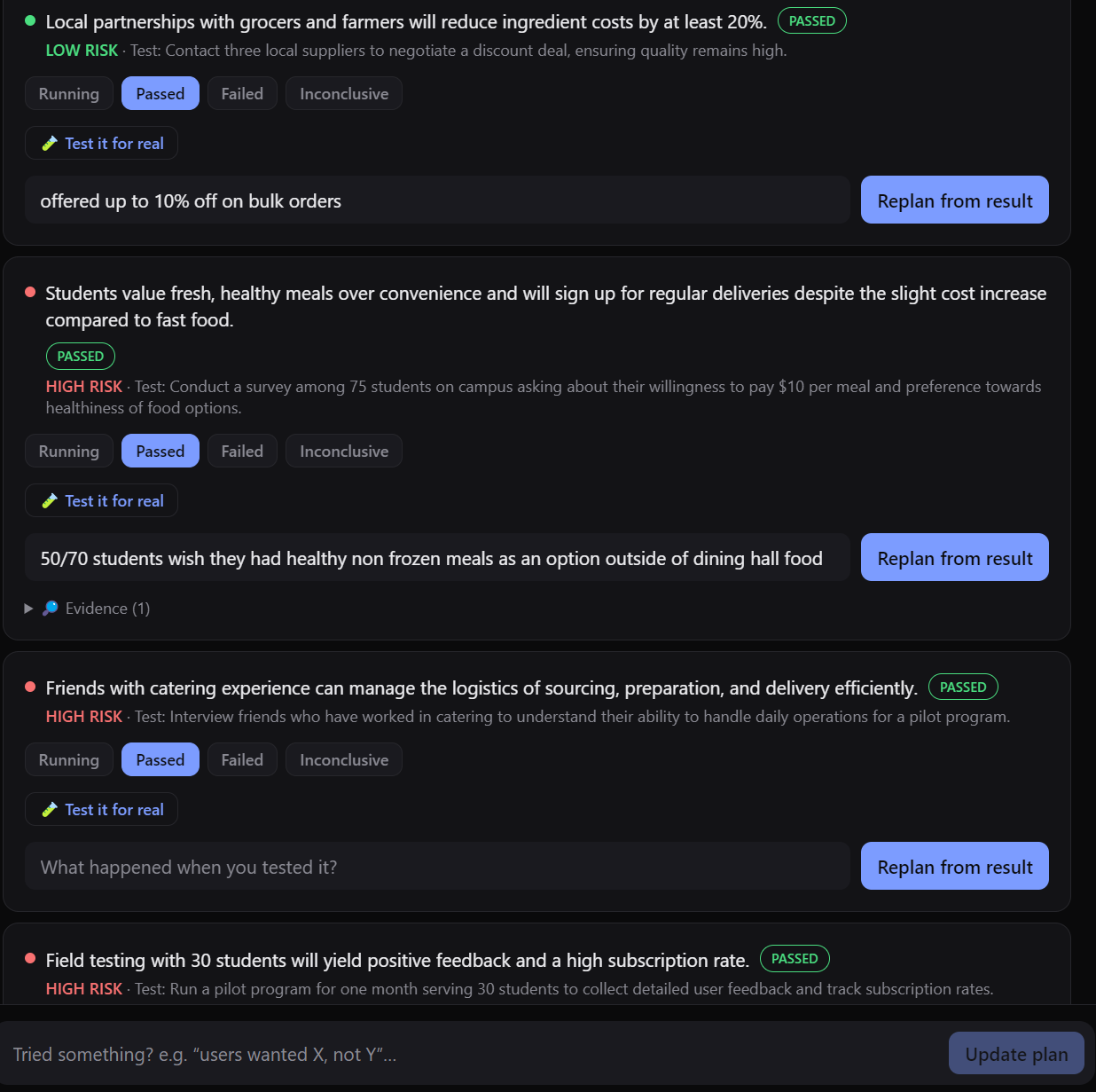
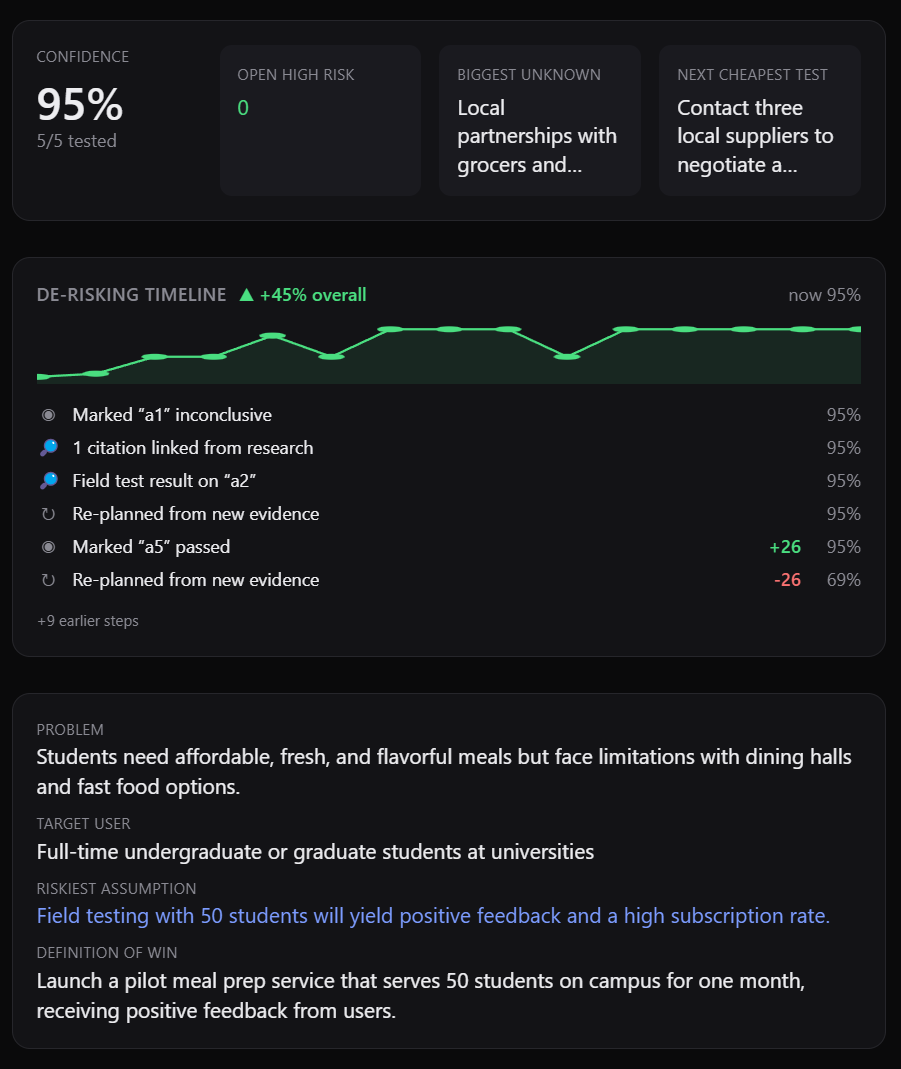
Assumption Tests are the tasks that the user would need to complete in order for the idea to be validated and the assumptions addressed.
-
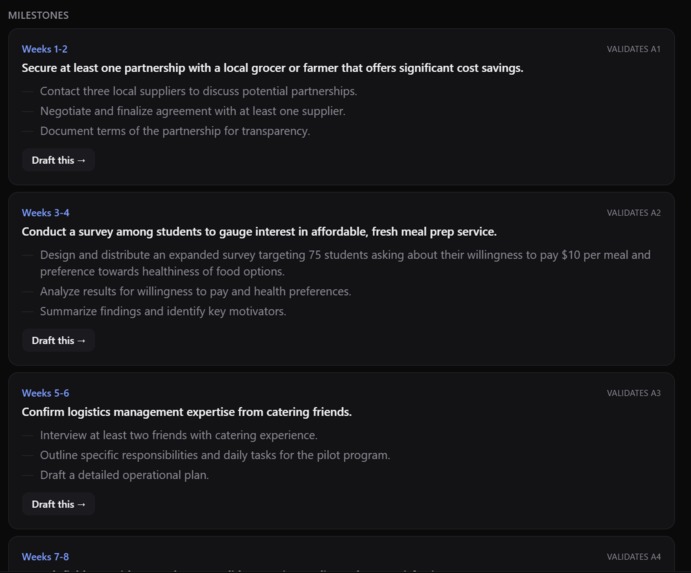
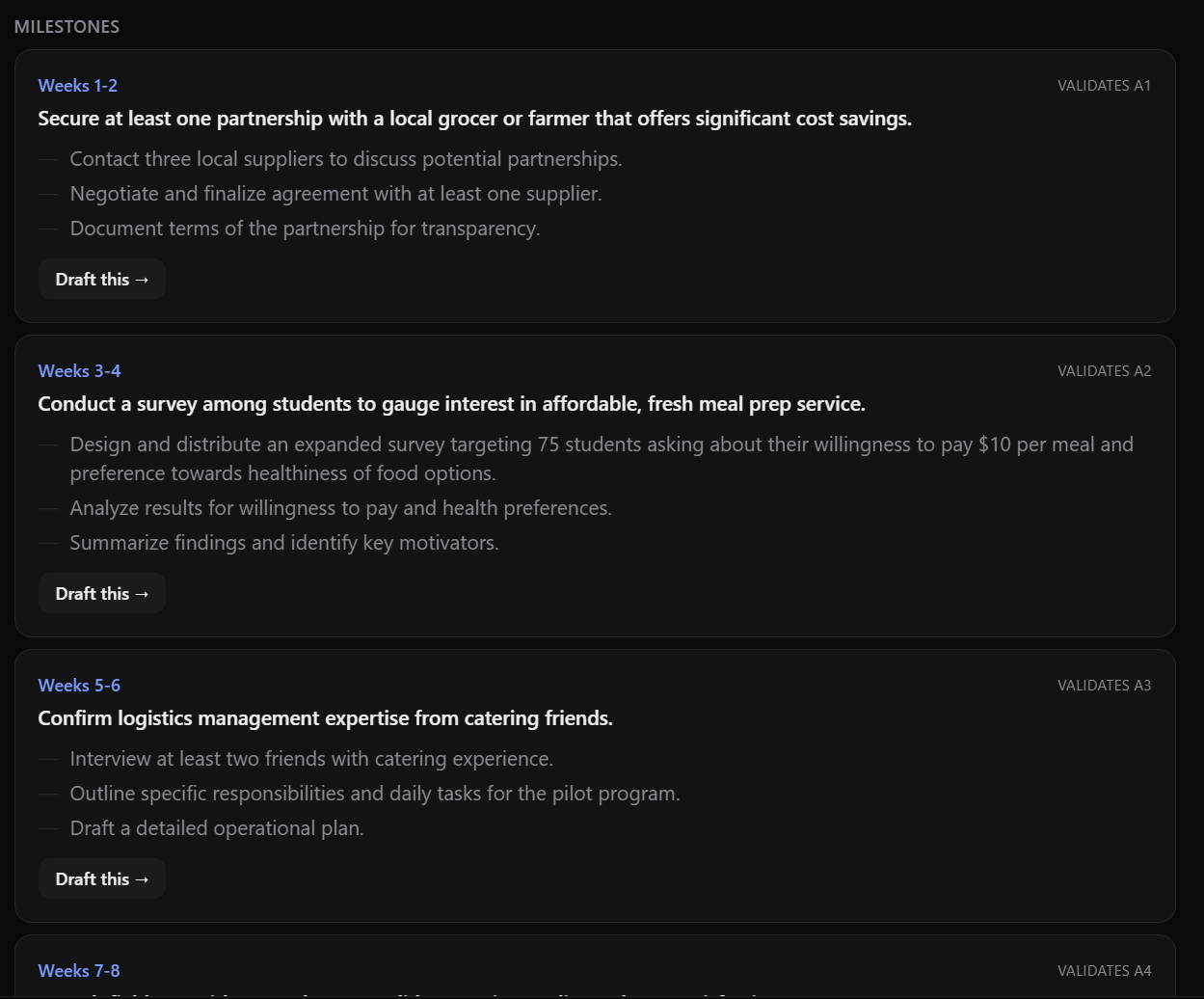
The milestones tab is the multi-week plan given to the user to help them tackle the assumptions and launch details in a structured manner
-
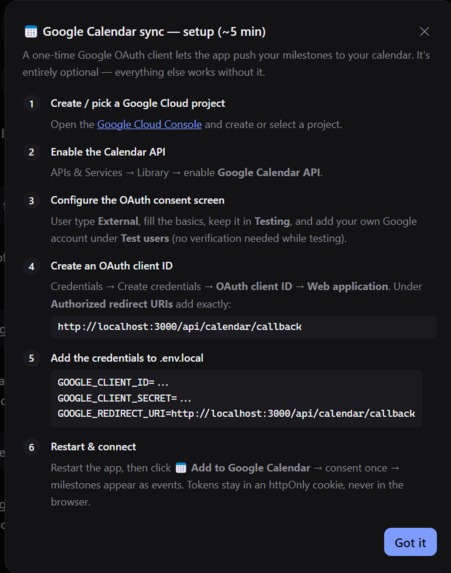
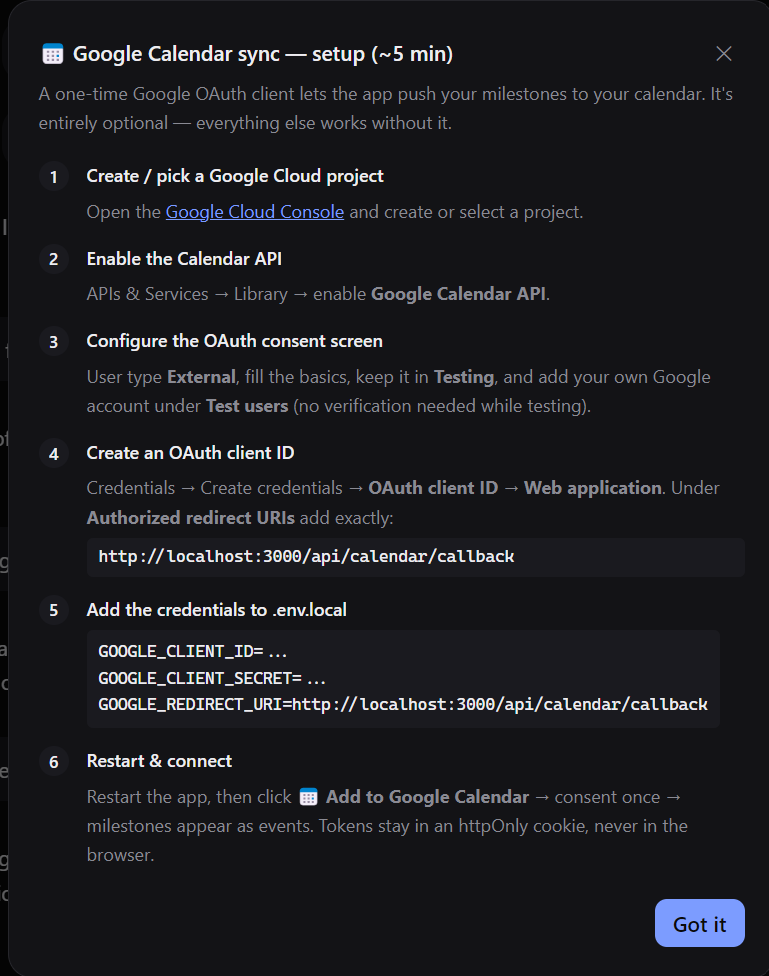
Google Calendar Integration to schedule milestones directly onto the user's calendar to help them track it effectively
-
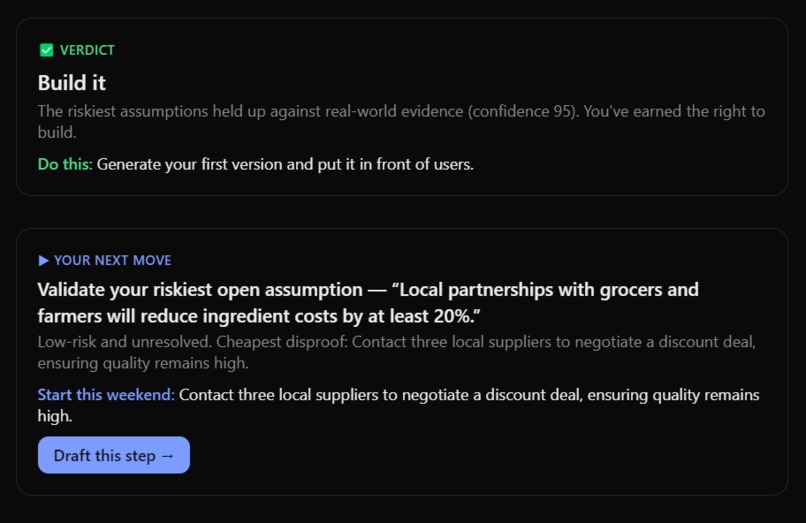
Verdict and next move. These tell the user whether they should tackle this idea or not and a clear actionable step to build or validate
-
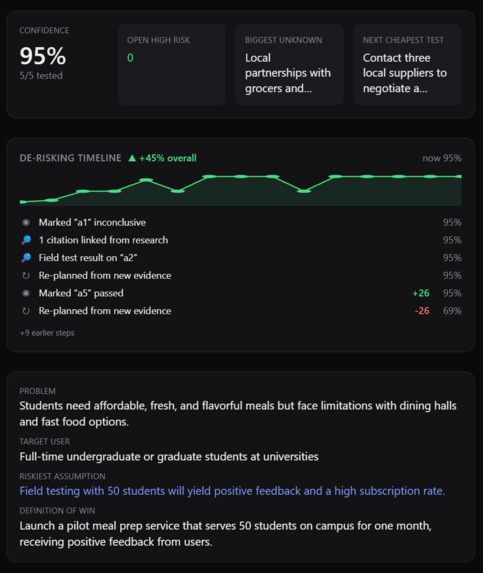
Confidence Percentage and Graph to show the changes in confidence as the user has completed tests and validated the idea
Inspiration
Most of us have a folder of ideas we never start. The reason usually isn't the work; it's the fear of finding out, six months in, that nobody wanted the thing. We've all done the same dance: get excited, ask a few friends, hear "that's awesome," and take that as a green light. It isn't one. Friends are being nice, mentors are busy, and AI assistants are the worst of the bunch, because if you ask one about your idea, it will almost always cheer you on.
So our first instinct was the obvious one: can't you just tell an AI to be brutally honest and tear your idea apart? We tried that, and it falls apart fast. You can talk it out of its own criticism. These models are trained to be agreeable, so "be harsh with me" is a thin coat of paint that wears off after a couple of replies. Push back once or twice, and it caves and starts agreeing with you again. And even when it does criticize, being critical isn't the same as being right. It's just generating objections that sound plausible, with nothing real behind them. A confident "this won't work" is as made-up as a confident "this is great." On top of that, a chat has no memory of the bar you set. It won't hold you to a threshold you agreed on before you ran a test, and it won't give you the same answer tomorrow.
We wanted the opposite of a yes-man, but we realized you can't get there with a clever prompt. You get there by building the honesty into the system, so it holds up even when the person using it really wants to hear a yes. That's what we set out to make.
What it does
Zero2Hero takes a vague idea and walks it to an evidence-backed go or no-go decision.
It starts by interviewing you, the way a sharp cofounder would, to pull out the assumption you didn't even realize you were making. From there, it builds a plan: your riskiest assumptions, ranked, each paired with the cheapest way to test it, plus the milestones that get you to a first version. Then it pushes back. It picks your weakest assumption and argues against it, and you either defend it or concede.
The part we care about most is what comes next. It designs the cheapest real-world test for that assumption, and it doesn't assume you're building software. For a lot of student ideas, the cheapest test is offline: a sign-up sheet, ten honest conversations, and a pre-order to see if anyone will actually pay. You go run it, you log what really happened, and that result becomes the evidence that moves the needle. From there, you get an honest verdict, build it, don't, or not yet, and if it's worth pursuing, a first version and a kit to get it in front of real people.
How we built it
It's a full-stack Next.js app with the UI and the API routes in one place, streaming responses so the interview feels live. Underneath is a provider-agnostic model layer: it runs fully local and private on Ollama with Qwen2.5 by default, or on Azure OpenAI in the cloud, and you can switch per request.
The thing that makes it a system rather than a chat wrapper is that every model output is structured and validated. The model returns JSON, we check it against a schema at the boundary, and anything malformed never reaches you. Research works out of the box with a keyless web search, with an optional self-hosted SearxNG for fully private search, and we drop any fabricated source on the server, so a made-up citation can never move your confidence.
The honesty lives in code, not in the prompt. The verdict is computed deterministically, and it simply cannot return "build it" unless a high-risk assumption has actually passed and has real evidence behind it. There's no wording you can use to get a yes out of it. The confidence score works the same way, adjusting from evidence on top of assumption status:
$$ \text{confidence} = \mathrm{clip}!\left(50 + \sum_{a} w(a)\,s(a) + \mathrm{clip}!\Big(\sum_{a} w(a)\,\mathrm{clip}(e_a,-2,2),\,-12,12\Big),\; 5,\; 95\right) $$
where w(a) is how risky an assumption is, s(a) is the shift from its status, and e_a is the net direction of its cited evidence. Because the verdict and the recommended next step are derived in code with no extra model calls, the advice is consistent, and you can trace exactly why you got it. We shipped it as a cross-platform desktop app built in CI for Mac, Windows, and Linux, with a 236-test suite that runs fully offline.
What we learned
The biggest lesson was that honesty has to be engineered, not prompted. A prompt can make an AI sound honest for a few messages. Only the architecture keeps it honest when there's pressure on it, and the most responsible version of this was the structural one: gate the yes on real evidence, make the AI argue back, and keep a human deciding every change.
We also learned how sensitive the judging is. Getting the AI to fairly call a real-world result took us three tries. With rules alone, it swung from too harsh to too generous, and only pinning it to thresholds we set before the test, plus one worked example, got it consistent. Honestly, that was the clearest proof that "just tell it to be critical" doesn't work. And we learned not to assume software, so every step adapts to the kind of idea instead of defaulting to a web app.
Challenges we faced
The hardest one was making the AI honest without making it useless. Our test judge first called a genuinely encouraging result a failure, then overcorrected and passed a result that missed its own bar. We fixed it by feeding it the thresholds we'd set up front and anchoring it with an example, and we verified it live across clear passes, fails, and the messy in-between.
The rest were the usual trenches. Keeping fabricated sources out so a fake citation can never sway the score. Making one model layer behave the same whether it's running locally on a laptop or on Azure. Packaging a web app into clean desktop installers in CI. And building a safety screen that refuses clearly harmful ideas before any model call, without tripping over legitimate ones like a Nerf gun marketplace or a malware-detection tool.
What's next
Shareable validated-plan links so you can hand a mentor the evidence, a willingness-to-pay test with a real payment link, and a follow-up loop that checks back in on the riskiest assumption you still haven't proven.
Built With
- azure-openai
- docker
- docker-compose
- electron
- github-actions
- google-calendar-api
- google-oauth
- javascript
- localstorage
- msw
- ndjson
- next.js
- node.js
- ollama
- playwright
- qwen2.5
- react
- searxng
- tailwindcss
- testing-library
- typescript
- vitest
- web-speech-api
- zod


Log in or sign up for Devpost to join the conversation.