What it does
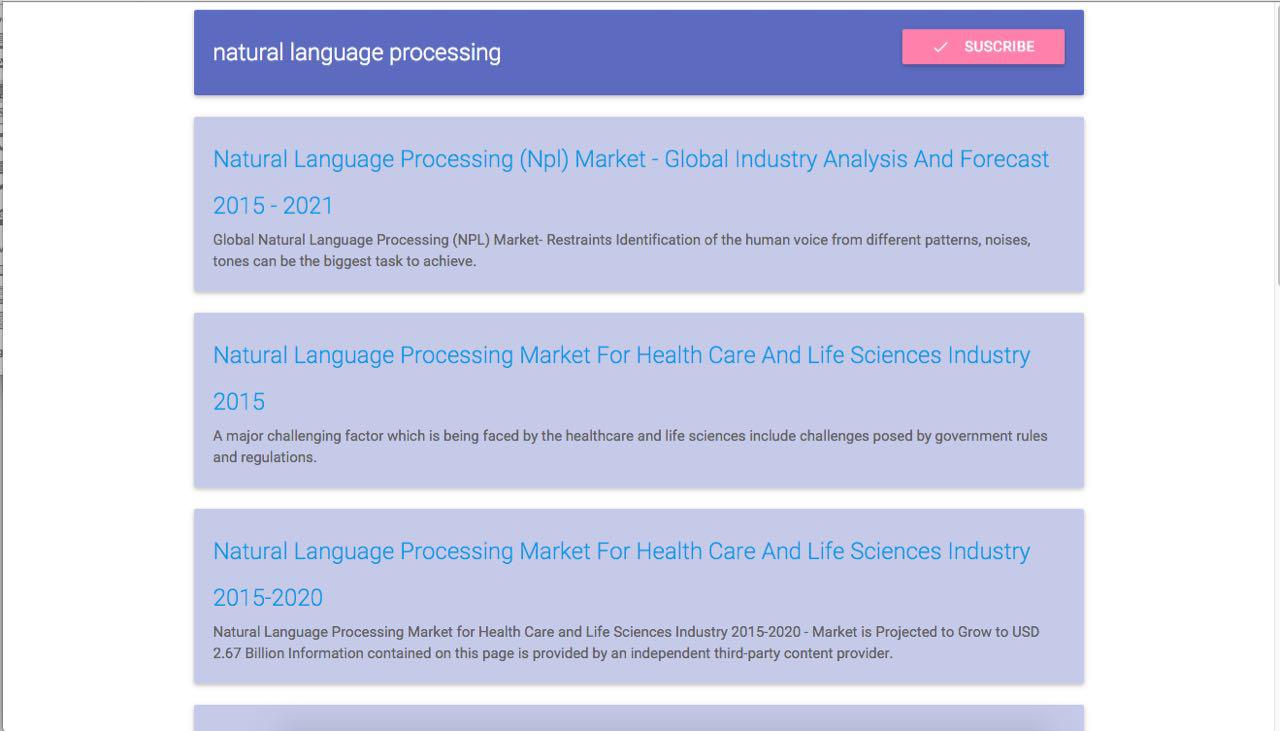
Our application uses user-submitted queries to find keywords and articles that the user might be interested in. Using the Bing Search API, we retrieve and aggregate related articles. We then apply our custom summarization algorithm to the article, allowing us to display the key sentences and sentiments for every article.
How We Built It
Our summarization algorithm uses an extractive method, identifying the top sentences that best summarize a given article. To do this, we compute a centrality and a relevancy score for every sentence in the file. The relevancy score is a weighted linear combination of various attributes that have been shown, across various studies, to be a good basis for the relevancy of articles. The attributes that we use include key-word frequency, title frequency, document position and sentence length as indicators of relevance.
We think that the most interesting of these attributes is the frequency score, in which we calculate the sentence-based feature selection score and the density-based feature selection score -- combining the scores to get a relevancy score.
To calculate the centrality score we create a vertex for every sentence in the article and draw edges between every vector (giving us a complete graph). The weights of the undirected edges are the cosine similarities of the tf-idf vectorizations of the sentences. Given this graph, represented as an adjacency matrix, we then applied Google's PageRank algorithm to the matrix, giving us a centrality ranking for every single sentence.
We then computed the overall score by taking the square root of the product of the centrality score and relevancy score for every sentence. However, getting our summarizing sentences wasn't as simple as just taking the topmost relevancy scores. What we did was apply a maximal marginal relevance selection algorithm, allowing us to ignore redundant sentences while still choosing relevant sentences.
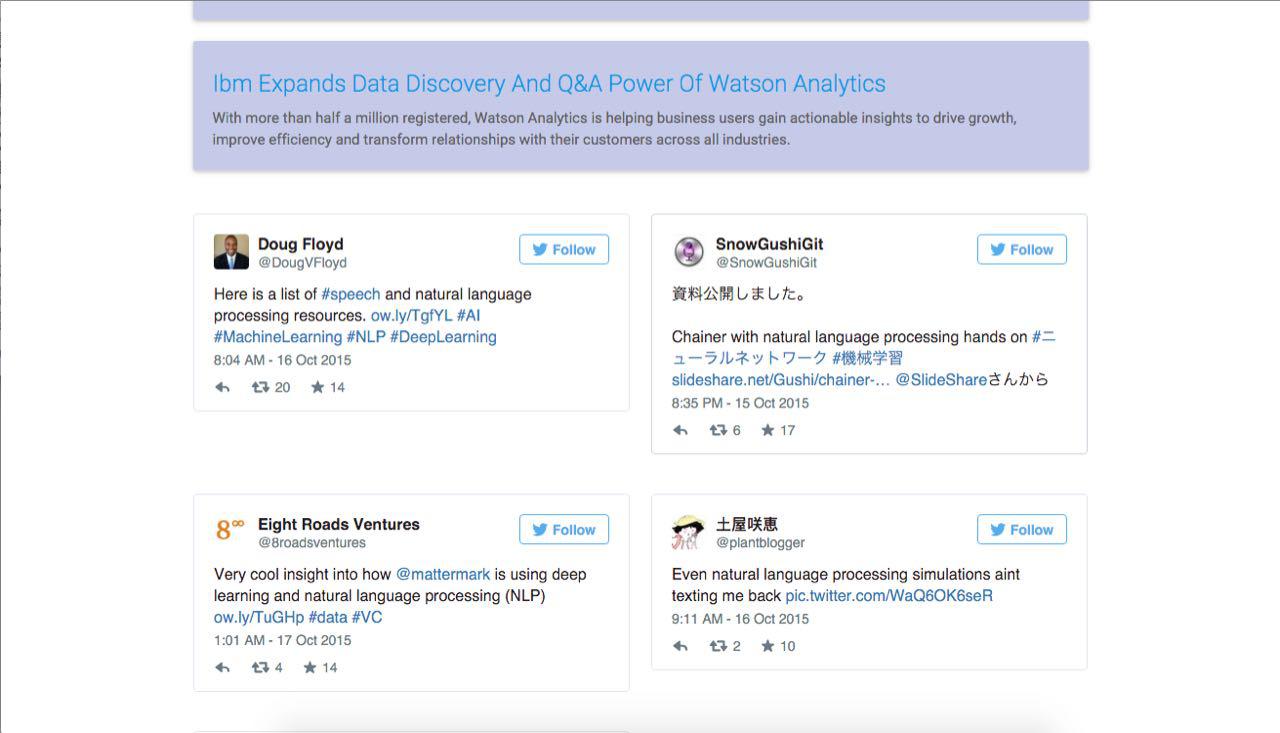
Our end result was a great number of relevant and interesting summaries. To add to our idea of letting people know what's going on with respect to their favourite topics, we also query relevant Twitter posts. This allows our users to get insight on what others are saying about their interests.
Challenges We Ran Into
One big challenge for us was finding an idf (inverse document frequency) score for words. As we don't have massive servers and a great amount of computational power, we needed a way to acquire idf scores efficiently.
Another problem that we encountered was the fact that the centrality scores (being the result of PageRank) weren't normalized between 0 and 1. This often meant that they were less spread out and had a lesser effect on the overall score than relevancy did. In order to resolve this problem, we needed to normalize the weights between 0 and 1 in such a way that preserves relationships between sentences.
Accomplishments That We're Proud Of
We're proud of building a clean, sharp web application that provides contextual and relevant summarizations of recent news articles. We personally designed and developed each one of our methods and had a lot of fun doing so!
What We Learned
We learned a lot about Natural Language Processing, Text Mining and solving difficult problems given unique constraints. We can honestly say that we're leaving this weekend a lot more knowledgeable than we went into it.
What's Next For Zero
Given that we're relying on Bing News Search to acquire our relevant articles, not everything is in our hands. We're definitely planning on building on this awesome creation and learning about additional options and ways we can find the absolute best articles for readers.
Built With
- bing-search-api
- cosine-similarities
- django
- lexrank
- numpy
- pagerank
- python
- scipy
- tf-idf-vectorization


Log in or sign up for Devpost to join the conversation.