-
-
-
-
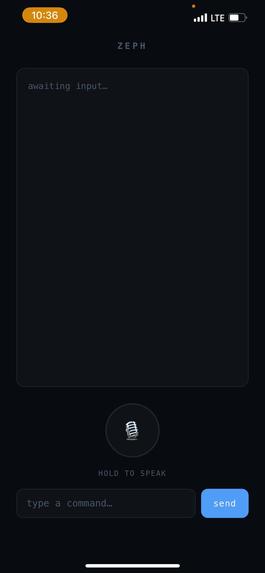
phone pwa
Inspiration
Enterprise IT is broken. Siri can't touch a Linux machine. Alexa sends everything to the cloud. IT teams waste hours on repetitive setup tasks — configuring workstations, pulling repos, managing processes — all things that should take a single sentence. We wanted to build the voice assistant that actually works in a real office.
What it does
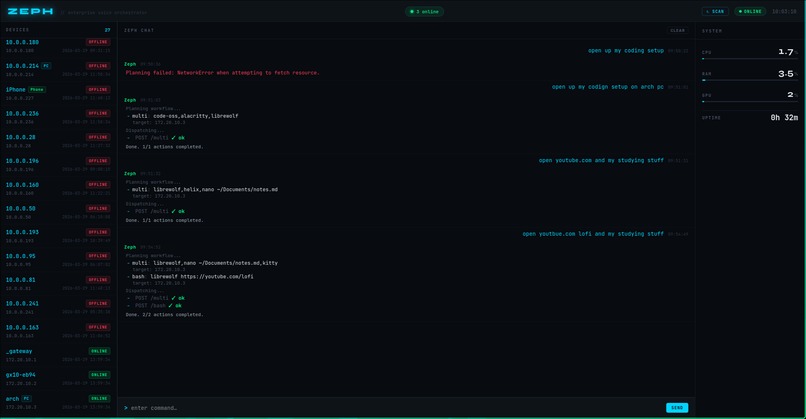
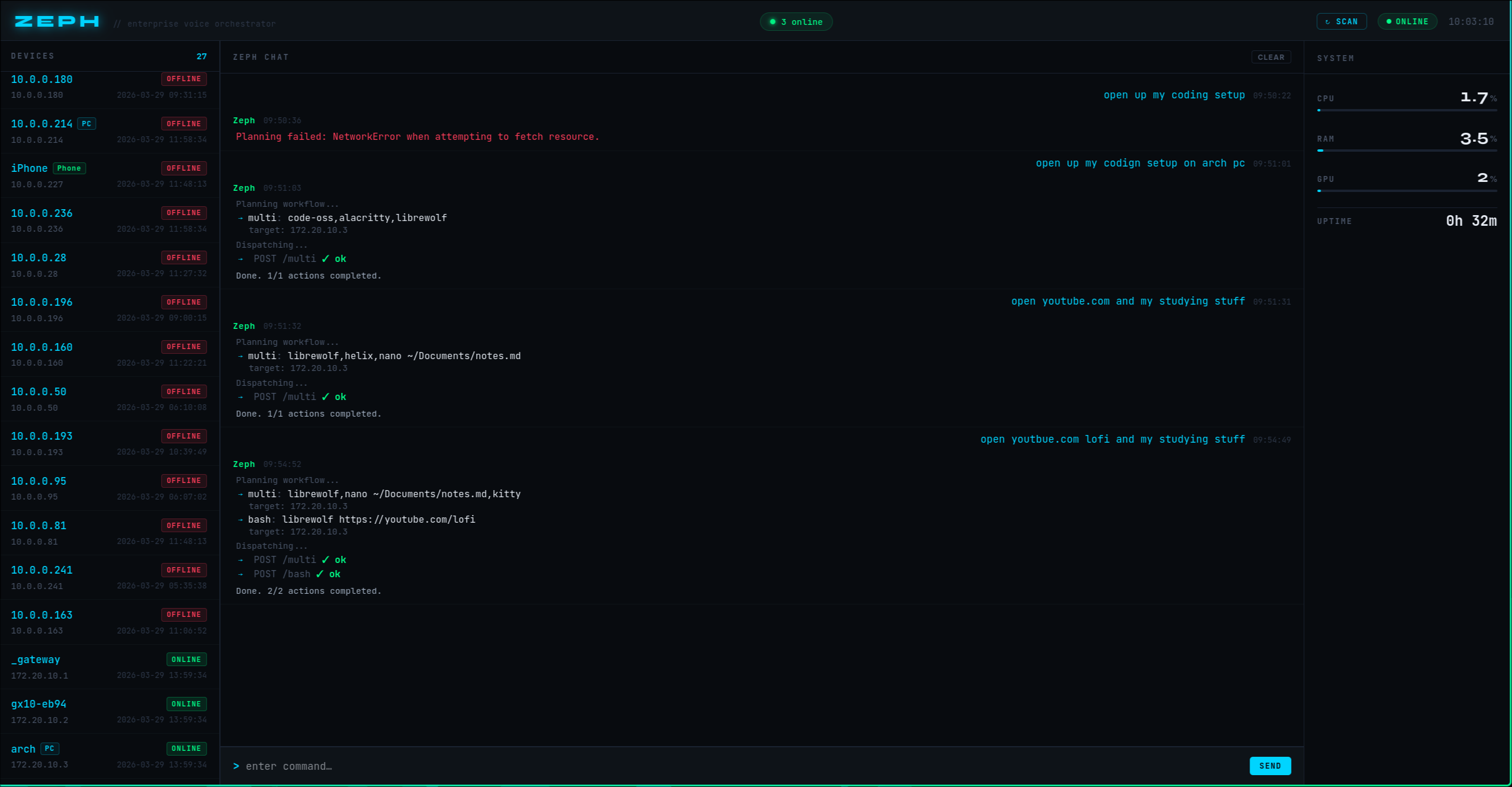
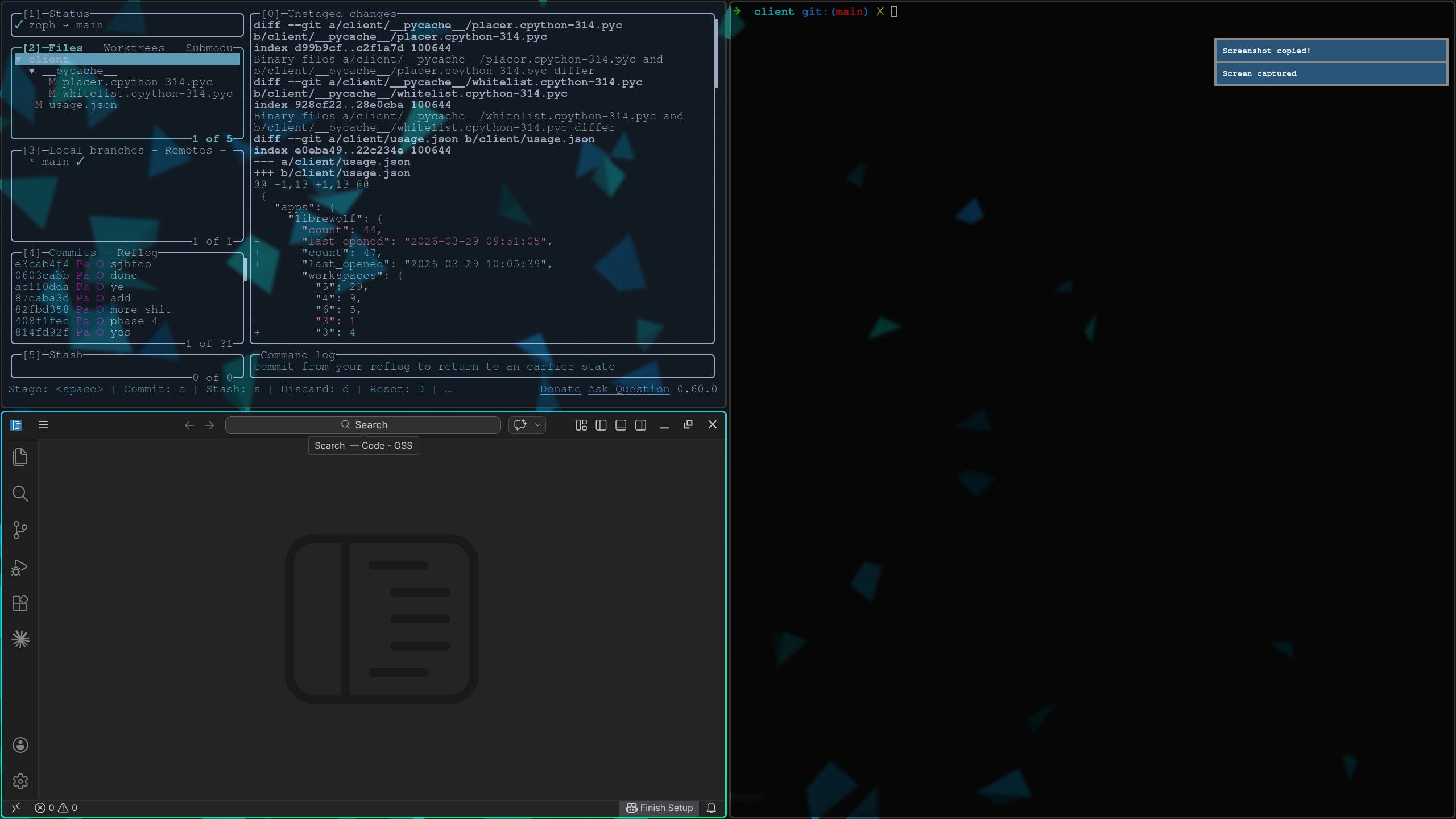
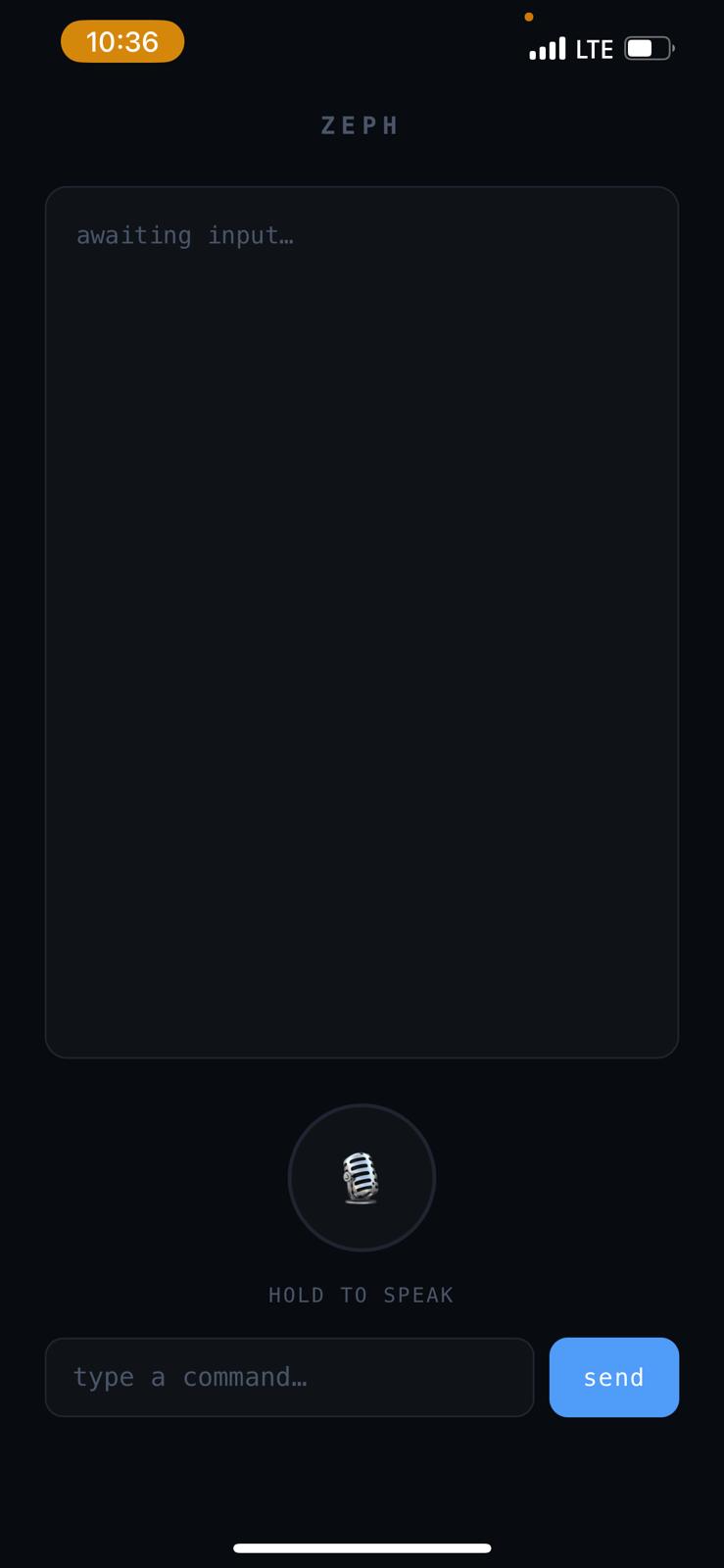
Zeph is an AI-powered enterprise voice assistant running on an ASUS Ascent GX10 supercomputer. You speak a natural language command — from your browser, or your iPhone — and Zeph's local LLM plans a full multi-step workflow and dispatches it across your entire network simultaneously.
- Voice or text input via iPhone PWA or dashboard
- Local LLM (Ollama + qwen3-coder:30b) plans structured workflows — fully offline, no data leaves the building
- LAN device discovery — automatically finds every machine on the network
- Multi-app workspace setup — "set up for dev" opens your editor, terminal, and git client tiled on a new workspace
- Preset + freestyle workflows — the LLM infers intent, not just pattern-matches
- Real-time dashboard — live device status, command log, CPU/RAM/GPU stats
How we built it
- GX10 server: FastAPI orchestrator, Ollama LLM, SQLite device registry, async LAN scanner, React dashboard, iPhone PWA
- Arch Linux client: Flask agent on each machine, hyprctl for desktop control, whitelist-validated bash execution
- LLM layer: Structured JSON workflow planning via qwen3-coder:30b running fully locally on the GX10
- Transport: Pure HTTP over LAN — no SSH, no cloud, no VPN
Challenges we ran into
- Getting the LLM to reliably output structured JSON workflows for complex multi-step commands required significant prompt engineering
- OpenDrop (AirDrop on Linux) relies on AWDL and OWL kernel drivers — too unstable for a hackathon demo, scrapped
- TUI apps like btop and lazygit attach to the current terminal instead of opening in a new window — solved by automatically wrapping them in alacritty
- Hyprland tiling layout requires careful sequencing and sleep timing between app launches
Accomplishments that we're proud of
- Fully offline AI agent — the LLM runs entirely on the GX10, zero cloud dependency
- Natural language to multi-machine workflow execution in under 2 seconds
- The LLM freestyle reasoning — "hackathon mode" or "focus mode" produces sensible app combos without explicit examples
- Built solo in 24 hours
What we learned
- Local LLMs are genuinely capable of structured reasoning when prompted correctly — the gap with cloud models is closing fast
- Enterprise voice control is a real unsolved problem — nothing on the market does what Zeph does for Linux environments
- Hardware orchestration at the network level is more accessible than expected with modern async Python tooling
What's next for Zeph
- Whisper STT on the GX10 — standalone mic input, no phone required
- Smart light control — GPIO and Govee/Tapo bulb API integration
- HTTPS + WSS — secure the PWA for production use
- Multi-machine fleet — broadcast commands to dozens of machines simultaneously
- OpenCode integration — voice-trigger AI coding sessions on any machine in the network


Log in or sign up for Devpost to join the conversation.