Inspiration
One in four students will experience a mental health crisis before they graduate.
Most will never tell anyone.
Not because they don't want help. Not because help doesn't exist. But because the moment they consider reaching out — the weight of being seen, judged, or labeled stops them cold. Psychologists call this anticipatory stigma. We call it the reason 70% of students suffering right now will suffer alone.
We looked at every existing solution. Woebot. Wysa. Replika. Talkspace. Each one asks the same thing of a student in their most vulnerable moment:
Type how you feel into a box.
That's it. A text box. In a world where those same students spend hours a day on video calls — where they laugh, cry, argue, and connect through faces and voices — mental health platforms ask them to reduce their pain to a chat message.
We refused to accept that.
If stigma dissolves when the interaction feels human — then the solution isn't better text. The solution is a face.
What it does
zeo.ai is the world's first emotion-aware 3D AI companion built specifically for student mental health at an institutional level.
It doesn't just respond to what you say. It sees what you feel.
The Experience
A student opens zeo.ai. No signup. No form. No barrier.
An AI avatar appears — like joining a Google Meet. It speaks. It listens. Its expression shifts when yours does. When you say "I'm nervous about tomorrow" and your face shows fear, it doesn't just read the words — it reads you.
"That kind of pressure before an exam is something so many students carry alone. You don't have to. Let's take one breath together first."
That's not a scripted response. That's a fused output from real-time facial emotion detection, vocal tone analysis, and a large language model — delivered through a warm voice and a face that is paying attention.
Core Features
| Feature | What it means for students |
|---|---|
| 🎭 3D Emotion-Aware Avatar | A face that reacts, adapts, and responds to how you actually feel |
| 🔓 Zero Authentication | No login = no barrier at the moment that matters most |
| 🧠 Persistent Memory | The AI remembers you across sessions — relationships, not transactions |
| 📅 Institutional Counselor Booking | Direct appointment scheduling with verified campus counselors |
| 🤝 Anonymous Peer Community | Students share, follow, and discover they are not alone |
| 🚨 Real-Time Crisis Detection | Distress threshold triggers immediate crisis resource surfacing |
| 🌐 Multilingual Support | Serves international student populations in their language |
| 🔒 Privacy-First Architecture | No raw video stored. Ever. |
End-to-end response time: under 2 seconds.
How we built it
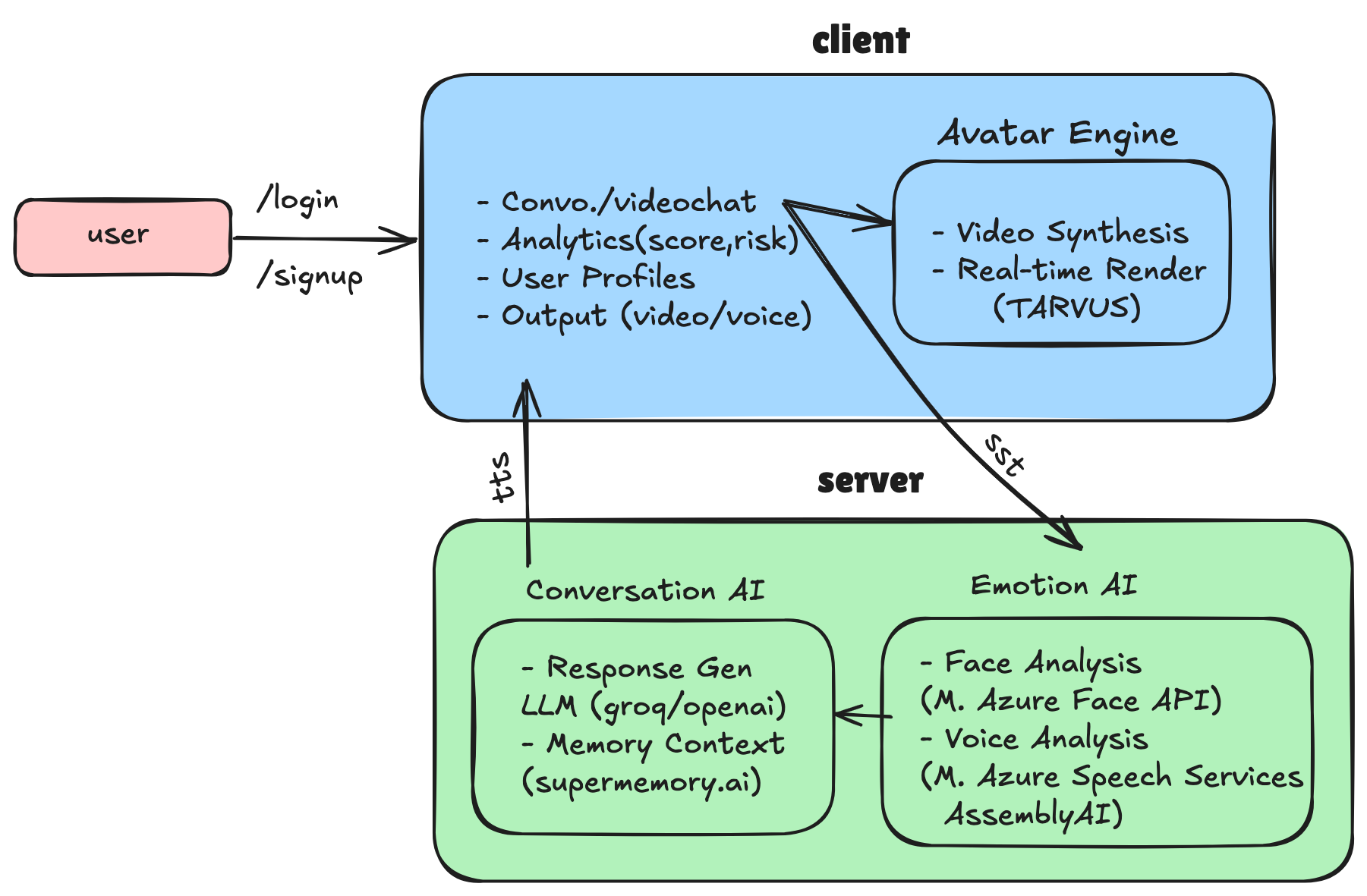
zeo.ai runs on a two-tier architecture — a React client hosting the avatar engine, and a Node.js server running two parallel AI subsystems.
Architecture Overview
┌─────────────────────────────────────────────┐
│ CLIENT │
│ │
│ React 18 + TypeScript + Vite │
│ Tailwind CSS + Framer Motion │
│ │
│ ┌──────────────────────────────────┐ │
│ │ AVATAR ENGINE │ │
│ │ TAVUS: Video Synthesis │ │
│ │ Real-time Render + Lip-sync │ │
│ └──────────────────────────────────┘ │
│ │
│ WebRTC stream capture │
│ Web Speech API (on-device STT) │
└──────────────┬──────────────────────────────┘
│ STT stream ↓ ↑ TTS audio
┌──────────────▼──────────────────────────────┐
│ SERVER │
│ │
│ ┌─────────────────┐ ┌──────────────────┐ │
│ │ EMOTION AI │ │ CONVERSATION AI │ │
│ │ │ │ │ │
│ │ Azure Face API │→ │ Groq / OpenAI │ │
│ │ Azure Speech │ │ LLaMA 3.1 70B │ │
│ │ AssemblyAI │ │ Supermemory.ai │ │
│ └─────────────────┘ └──────────────────┘ │
│ │
│ Node.js + Express │ MongoDB + PostgreSQL │
│ Eleven Labs TTS │ REST + WebSocket │
└─────────────────────────────────────────────┘
The Intelligence Pipeline
- Student's camera and microphone stream via WebRTC
- Azure Face API returns emotion probabilities across 8 categories every 500ms
- Azure Speech Services / AssemblyAI analyse vocal pitch, pace, and energy
- Both run in parallel — fused into a structured emotion context JSON
- Groq (LLaMA 3.1 70B) receives emotion context + session memory from Supermemory.ai + user message — generates a calibrated, empathetic response
- Eleven Labs TTS synthesises the response in a warm human voice
- Phoneme data streams to TAVUS for real-time lip-sync
- Avatar delivers response with matched facial expression — under 2 seconds total
Tech Stack
| Layer | Technologies |
|---|---|
| Frontend | React 18, TypeScript, Vite, Tailwind CSS, Framer Motion |
| Avatar Engine | TAVUS (video synthesis + real-time render + lip-sync) |
| Stream Capture | WebRTC, Web Speech API |
| Backend | Node.js, Express, REST + WebSocket |
| Emotion AI | Azure Face API, Azure Speech Services, AssemblyAI |
| Conversation AI | Groq (LLaMA 3.1 70B), OpenAI GPT-4o |
| Memory | Supermemory.ai |
| Voice | Eleven Labs TTS |
| Database | MongoDB, PostgreSQL |
Privacy by Design
- No raw video stored — ever
- Pseudonymised session tokens decouple identity from data
- Explicit informed consent required for all persistence
- On-device inference planned for next phase
Challenges we ran into
⚡ Breaking the 2-Second Wall
Every component — emotion detection, STT, LLM inference, TTS, avatar render — naturally wants to run sequentially. Sequential kills the experience. We rebuilt the entire pipeline to run emotion analysis and speech processing in parallel, shaving nearly 800ms off the critical path. Sub-2s on consumer hardware was the hardest engineering problem we solved.
🎭 Regulated Empathy
An avatar that mirrors distress too precisely can deepen it. A student crying shouldn't see an avatar that looks like it's about to cry too. We designed a regulated empathy model — the avatar signals understanding and attentiveness without adopting the user's emotional valence. It took 20+ iterations to feel right.
🚪 The Authentication Trap
Every step we added before the session — email verification, profile setup, consent screens — dropped engagement. The first barrier kills the first session. Shipping zero-auth felt risky. It was the most important design decision we made.
👤 Finding the Right Face
Photorealistic avatars triggered uncanny valley discomfort. Cartoonish avatars felt dismissive for serious emotional conversations. TAVUS gave us the render quality to find the narrow band where an avatar feels warm, present, and trustworthy.
🌍 The Fairness Problem We Didn't Ignore
Azure Face API's emotion detection accuracy varies across demographic groups — particularly South Asian and East Asian facial features. We documented it honestly as a known limitation rather than ignoring it, and built the fix into our roadmap.
Accomplishments that we're proud of
We built something that has never existed before.
Not a better chatbot. Not a prettier UI on top of the same text interface. Something structurally different — a platform where the modality itself is the therapeutic intervention.
- 🏗️ Sub-2-second end-to-end latency across 50 prototype sessions on standard consumer hardware — facial emotion, voice analysis, LLM response, TTS, and avatar render, fully parallelised
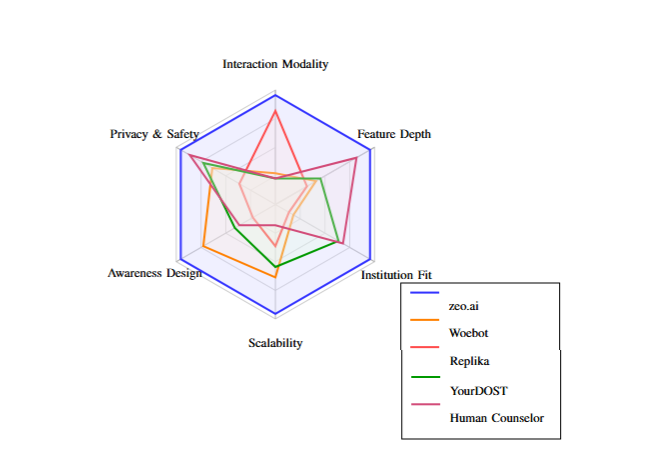
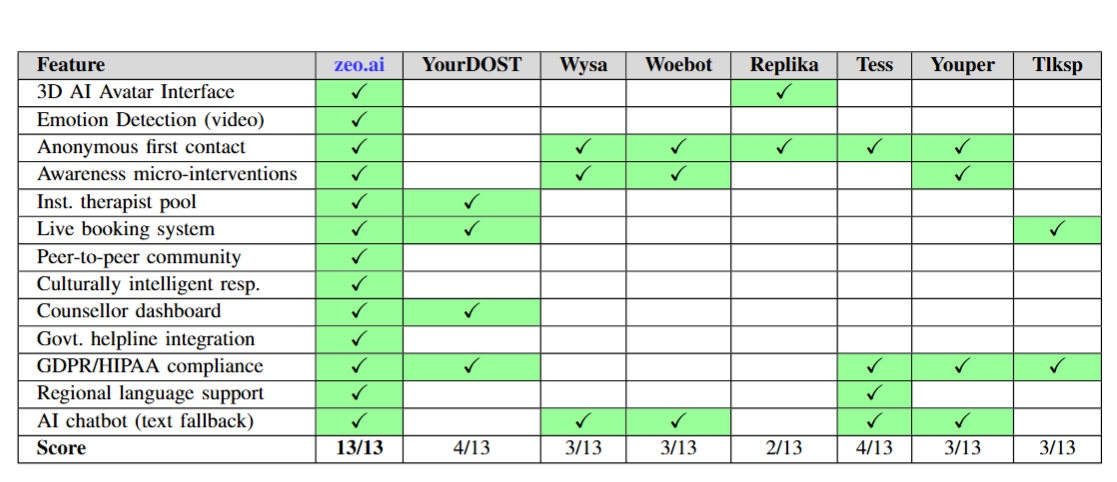
- 📊 13/13 feature dimensions covered — the only mental health platform simultaneously offering avatar modality, video emotion detection, institutional integration, anonymous access, peer community, crisis routing, counselor dashboard, and GDPR compliance. Every competitor benchmarked maxed out at 4/13.
- 📄 IEEE research paper formalising the Modality-Stigma Gap (MSG) model — empirical evidence for why text-only platforms structurally reproduce the stigma barrier they claim to solve
- 🏥 Working institutional infrastructure — counselor dashboard, live booking, appointment management, role-separated access — not mockups, working features
- ⏱️ 10 seconds from landing page to speaking with an AI face — zero data entered, zero friction, zero barrier
What we learned
The medium is the message — and the medicine. A text interface doesn't just deliver support differently — it is a different kind of support. One that discards 93% of the affective bandwidth of human communication. Changing the modality isn't a feature upgrade. It's a fundamentally different intervention.
Stigma lives in the first 10 seconds. The decision to seek help or close the tab happens before a single word is typed. Every friction point at first contact — login, consent walls, profile fields — compounds the anticipatory stigma already keeping students away. Designing against stigma means designing for the pre-decision moment.
Composing APIs is an art, not a shortcut. Using Azure, Groq, TAVUS, and Eleven Labs is not the innovation. The innovation is knowing which signals to fuse, at what latency, weighted how, to produce an interaction a student in distress experiences as human.
Honesty about limitations builds more trust than hiding them. We found demographic accuracy gaps in emotion detection. We documented them. We roadmapped the fix. Credibility is built on what you acknowledge, not just what you claim.
What's next for zeo.ai
The prototype is proof of concept. The roadmap is proof of commitment.
| Phase | Timeline | Deliverable | Success Metric |
|---|---|---|---|
| 1 | Q2 2026 | IRB-approved RCT: n=50, avatar vs. text, 8 weeks | Stigma score, disclosure depth, retention |
| 2 | Q3 2026 | On-device inference (TFLite/ONNX) | Zero raw video upload |
| 3 | Q4 2026 | Counselor Dashboard v2 + Awareness A/B testing | Adoption >60% |
| 4 | Q1 2027 | Fairness audit + multilingual emotion model | Equitable accuracy |
| 5 | Q2 2027 | Multi-centre RCT: n=500, waitlist-controlled | Peer-reviewed publication |
The primary lever for closing the student mental health treatment gap may not be new clinical content — but an overdue change in the modality through which that content is delivered.
We're not building a better chatbot. We're retiring the paradigm.
Built With
- api
- assemblyai
- azure
- azure-face-api
- azure-speech-services
- css
- eleven
- eleven-labs
- express.js
- face
- framer
- framer-motion
- groq
- labs
- llama
- mongodb
- motion
- node.js
- postgresql
- react
- rest-api
- services
- speech
- tailwind
- tailwindcss
- tavus
- typescript
- vite
- web-speech-api
- webrtc
- websocket

Log in or sign up for Devpost to join the conversation.