


Inspiration 💡
When was the last time you read a book? Not a required book, but one just for your personal enrichment? With more than a billion hours of Youtube Videos being streamed every day and more than 720,000 hours of content being uploaded daily, we are in the midst of a digital age where the way we learn has completely changed. Millions of daily Youtube Users are faced with an inexhaustible amount of content. Many are on YouTube for entertainment purposes, but according to a Pew Research Study, 50% of Americans use Youtube for educational purposes. This means, in the US alone, around 98.5 Million users need a way to learn more in a shorter period of time.
If you want to be in control of your life, if you hate wasting time and like concise, precise, and relevant information, and if you want to optimize how you learn so you can quickly use your knowledge in the real world, zone in on ZenTube.
Let's make that Happen! ✨
So what’s the app about? 🤔
ZenTube condenses the information within a YouTube Video so that you can learn, develop, and master skills more efficiently! By generating the video transcript, a concise video summary, and time-stamped key points, you don't need to watch the entire video to gain a good understanding of the subject matter. If you want to dive deeper, then you can directly ask specific questions and the application will answer the inquires based on the information inside the YouTube Video. We not only save your valuable time but also enable you to silence the noise by making the content inside videos digestible and searchable.
Stay calm and Study on! 🚀
Tech Stack 🏗
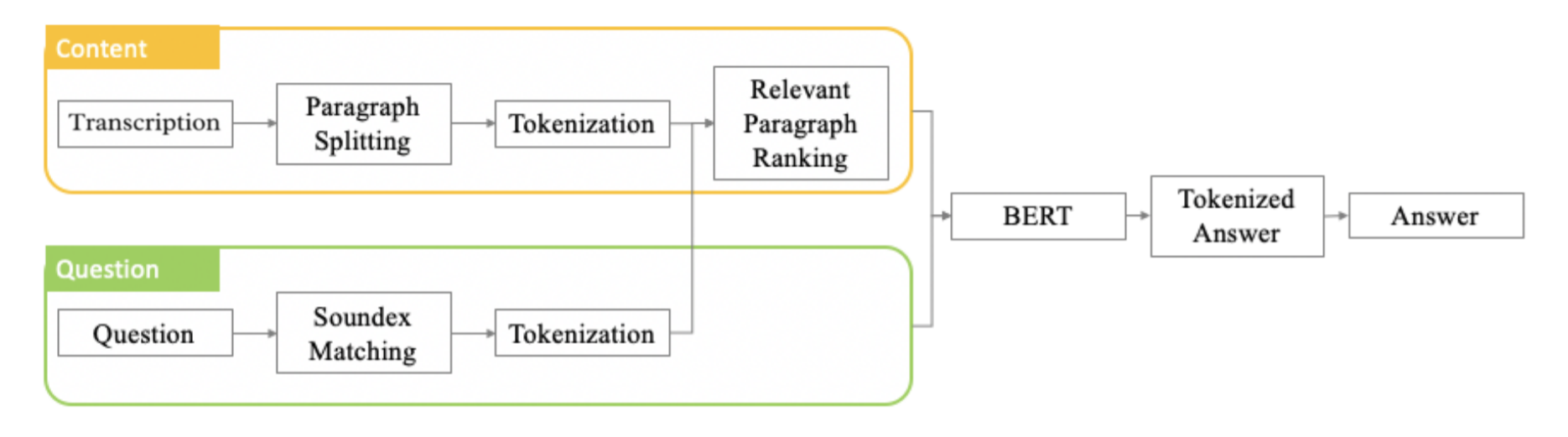
First and foremost, it is Crafted with 💙. For the front-end, we’ve used React.js & Tailwind as a CSS framework. The Authentication (OAuth) is done through Firebase & we also used Cloudstore database to store user logs. Using Python as the root language for creating the ML model, it was fed using a few different libraries such as Numpy, Pandas & Keras with Tensorflow. An image of the same model is deployed on Docker for Debugging purposes & hosted on glitch.me.
For the functionality, we wrote a custom, proxy middleware API to extract YouTube metadata and to convert YouTube videos to Mp3 (or MP4) format from the default .m4a format. From there, we pass the Mp3 file into Assembly-AI's API since it doesn't directly support .m4a format natively. Then, the API returns a JSON response which contains a list of features including Transcription, Automatic Transcript Highlights, Word Timings, Topic Detection, Profanity Filtering, along with recently added updates such as —
Auto Chapters that provide a "summary over time" by breaking audio/video files into "chapters" based on the topic of conversation & Sentiment Analysis processed by a Disfluency filter.
Finally, we use the Tensorflow(TF) BERT Model to analyze the transcript and answer all your questions.
The model is created using a pre-trained BERT model fine-tuned on SQuAD 1.1 (Stanford Question Answering Dataset) which is a new method of pre-training language representations that obtain state-of-the-art results on a wide array of Natural Language Processing (NLP) tasks.
The model takes a passage and a question as input and returns a segment of the passage that most likely answers the question. Everything happens client-side in the web browser, meaning privacy is protected and no text from the website is ever sent to a server for classification.
Challenges We ran into 🧱
There were lots of challenges on the way. First, because we were all online and separated by a 11 hour timezone difference, it was difficult for us to communicate during the Hackathon. We also spent a great deal of time brainstorming and discussing project ideas.
- File Incongruences - YouTube uses .M4A file formats while Assembly API only accepts .Mp3 or .Mp4 files.
- Run Time Error - TensorFlow BERT Model took too long to process longer videos along with high latencies. Under fit data & optimized the model & code.
- Output Error - Hierarchical Pyramidal filters were glitching so AI Model wasn't outputting anything while producing a suitable Answer.
- Language Barrier - Non-English Videos cannot be processed, so files had to be translated into English. So, middleware was creating additional latencies in the network layer.
- React Components - Transforming highly dynamic ideas created in Figma into React Components and Layouts.
- LocalStorage - LocalStorage method was not working. Had to fixed it manually.
- Integration of Modules - Connecting the Various APIs and the JSON data with front-end UI Components was challenging!
Design
We were heavily inspired by the revised version of Iterative design process that not only includes visual design but also a full-fledged research cycle where we discovered and defined problems before resolving issues & finally deploying the final product.
- Discover: a deep dive into the problem
- Define: synthesizing the information from the discovery phase into a problem definition.
- Develop: draft and analyze solutions to tackle the problem.
- Deliver: select the best solution and build that.
We went with a minimalist Material UI design. We utilized design tools like Figma, Photoshop & Illustrator to prototype our designs before doing any coding. Through this process, we are able to get iterative feedback so we could spend less time re-writing code.
Research 📚
Research bolsters our app's functionality to better serve users: we found our target group early on in the process, enabling us to focus on engineering the project. Here are a few of the resources that were helpful to us —
- A Comparative Study of Transformer-Based Language Models on Extractive Question Answering, (ArXiv — [cs.CL] 7 Oct 2021) : https://arxiv.org/pdf/2110.03142.pdf
- Hierarchical Ranking for Answer Selection (ArXiv — [cs.CL] 1 Feb 2021) : https://arxiv.org/pdf/2102.00677.pdf
- Understanding Indirect Answers (ArXiv — [cs.CL] 7 Oct 2020) : https://arxiv.org/pdf/2010.03450.pdf [Page 11 - 15]
- Answering Complex Open-domain Questions Through Iterative Query Generation (ArXiv — [cs.CL] 15 Oct 2019) : https://arxiv.org/pdf/1910.07000.pdf
- Question Answering with Pretrained Transformers (Pytorch Method) : https://bit.ly/3xisc6E
- Assembly-AI API docs : https://docs.assemblyai.com/overview/getting-started
♣ Articles :-
- 25 YouTube Statistics that May Surprise You : https://bit.ly/3DEBmg8
- How Much Time Do People Spend on Social Media in 2021? : https://bit.ly/3DJb8Js
- Study shows half of YouTube viewers are there for education : https://bit.ly/30Md6Ka
- YouTube user statistics 2021 : https://bit.ly/3DFss1Z
- Survey on how much a person spends time on YouTube Ads : https://bit.ly/3CG6J8K
CREDITS
- Design Resources : Freepik
- Icons : Icons8, fontawesome
- Font : Roboto / Raleway / Autowide / Lato / Montserrat
Takeaways
Accomplishments that we're proud of 🙌
A fully working prototype! This has been intense yet insightful journey. We are proud of the final product we designed and engineered within such a short timeframe. This is something we would recommend to our friends and family as we truly believe this is a quality application. The fluidity of the user's experience is something that we take pride in as we strive to return a sense of serenity to the oftentimes stressful and difficult process of studying and learning. This could not have been achieved without harmonizing front-end with back-end components to enhance the learning process.
What we learned 🙌
Staying hydrated was our motto for completing this impactful and complex project on time. We have learned how great things are accomplished through innovation and teamwork. Together we had a lot of fun participating in MetroHacks & these are the few things we learned —
- Creating and Customizing Mind Maps based on Data
- Deploying ML models on GCP
- New methods of optimizing data overfitting issues & critical block holds
- How To Leverage Tailwind CSS to quickly style React Components
- Improved UI/UX knowledge & Figma Designing
What's next for ZenTube 📃
We believe that our App has great potential. YouTube is a global, multilingual platform. Likewise, we plan to expand ZenTube's capabilities by incorporating other languages as right now, ZenTube can natively process English videos only. This improvement will not only permit a greater audience to transform their education but also facilitate the exchange of diverse information and technical expertise globally. Additionally, we intend to continue augmenting the accuracy and speed of our NLP Model. Finally, we want to implement a more dynamic MindMap Component that allows the user to better visualize key concepts and how they relate to one another at a glance.
Let's bring the Zen Mindset to people around the world who are hungry to learn more! ✨
Note ⚠️ — 18+ group category Hackathon Project. Also, API credentials have been revoked. If you want to run the same on your local, use your own credentials.







Log in or sign up for Devpost to join the conversation.