-
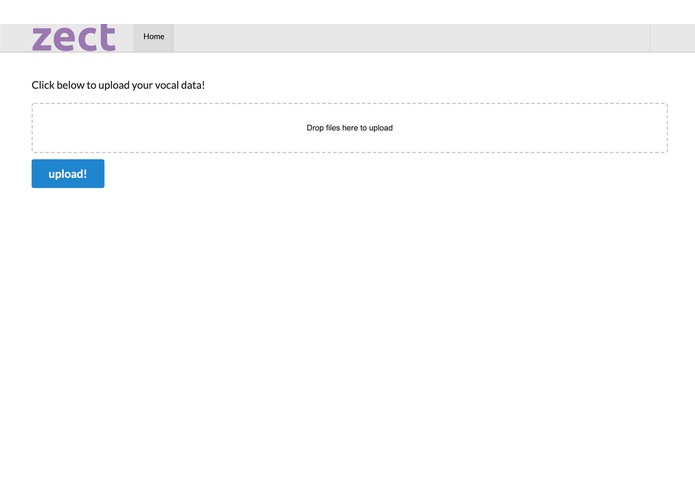
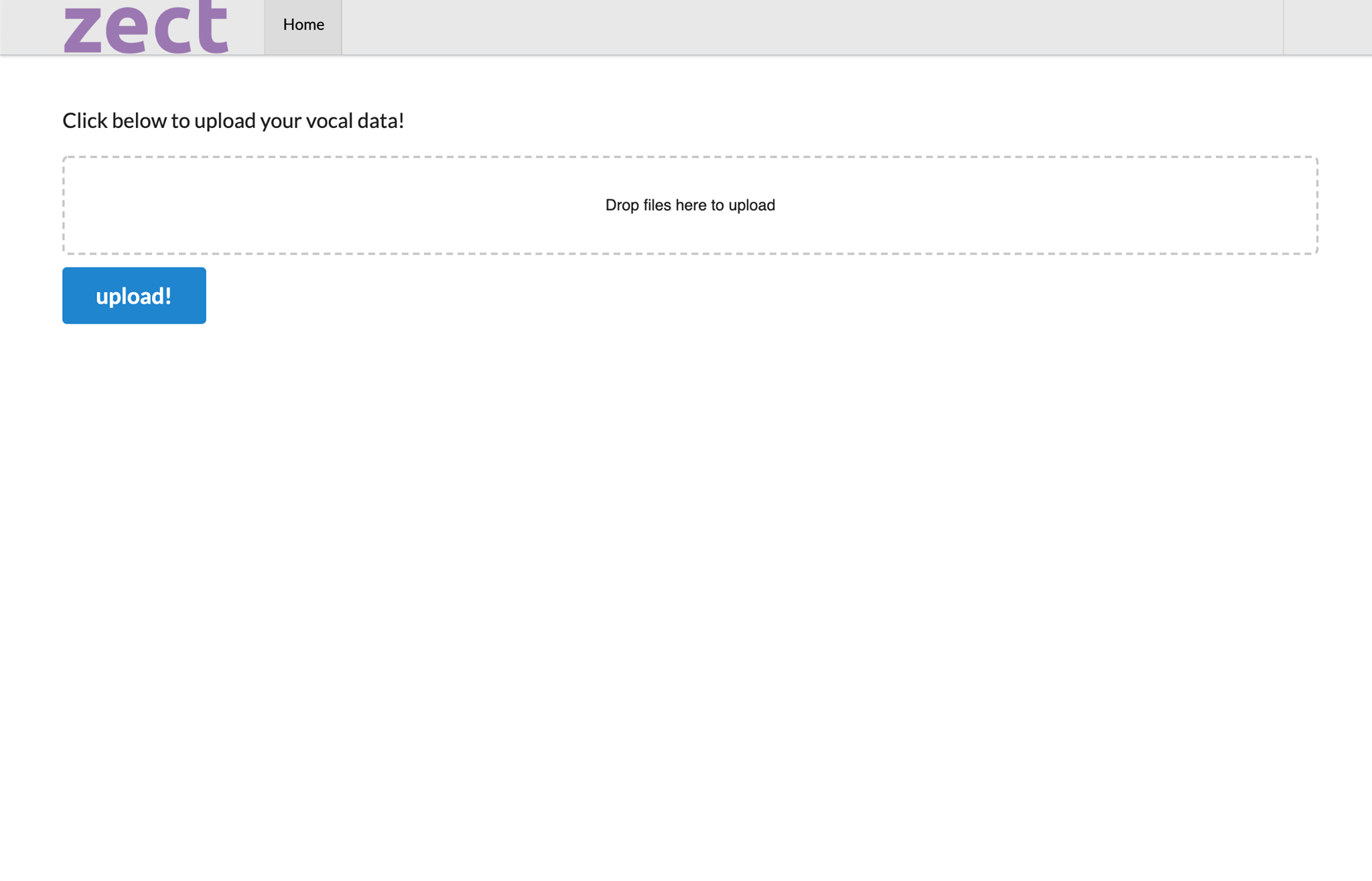
Vocal upload page
-

Report page
-
Zect Home

Inspiration
One of the members of our team, Clinton, suffers from a stutter. While discussing possible novel uses of speech APIs, he mentioned that people with stutters often have verbal blocks, which prevent them from speaking normally. People with stutters have to learn how to change their speech in order to avoid problematic phonetic structures (using a technique known as word substitution). We realized that it would be valuable to develop a system that helps people with stutters identify sources of verbal blocks as well as ways to improve their speaking.
What it does
Our product gives a profile on stress points and places for improvement when it comes to stuttering. Given an audio file, it detects stuttering and discovers the words or sounds that consistently cause issues.
Then, combining our stuttering analytics with the rich word data extracted from the Rev AI transcription, we produce a speech report that gives several helpful metrics:
- a graph of the types of phonemes that users have difficulty with (which is useful for voice training and speech therapy)
- the most problematic phonemes, ranked by stutter frequency
- word replacement recommendations, to help users develop their word substitution technique
How we built it
Using a machine learning algorithm, we built a system that identifies when a person stutters, as well as the phoneme that causes them to stutter. Then, using Rev's speech-to-text API, we can triangulate the precise word that a person stuttered on. The API allows us to index transcribed speech by speaker, time, and consonant/vowel sound, and so we can document which words and sounds are most problematic for our users.
Then, combining our stuttering analytics with the rich word data extracted from the Rev AI transcription, we collect useful metrics, which we have visualized in our presentation.
Challenges we ran into
Finding a rich corpus of audio data to train the SVC algorithm on was extremely difficult and laborious! As one might expect, training data of subjects demonstrating stuttered speech isn't easy to come by. To make matters more difficult, the data we found wasn't preprocessed, which meant we had to listen to and manually label every one-second instance in which we identified stuttering—prolongations and repetitions.
What we learned
Programming is hard.
More seriously, we became very familiar with the intricacies of planning and executing a larger-scale project. There are often non-trivial details that get overlooked until they become the biggest challenge of the entire project, and this experience improved our ability to foresee such issues and solve them.
Built With
- python
- rev-ai
- scikit-learn

Log in or sign up for Devpost to join the conversation.