-
-
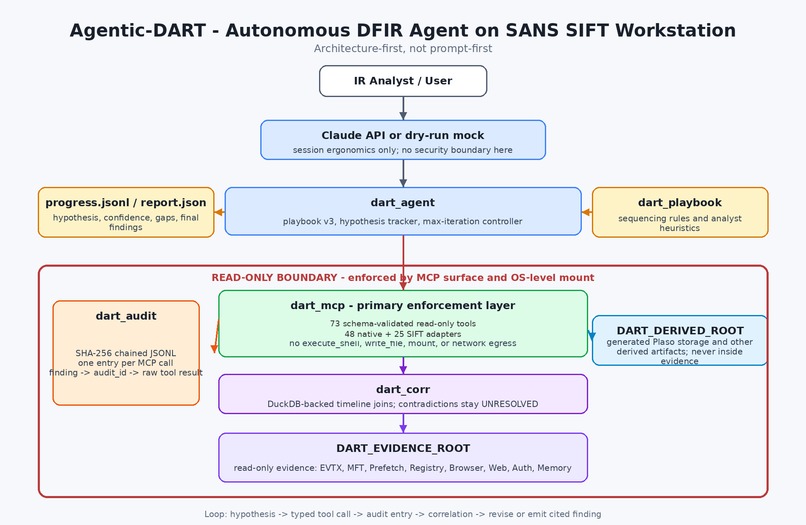
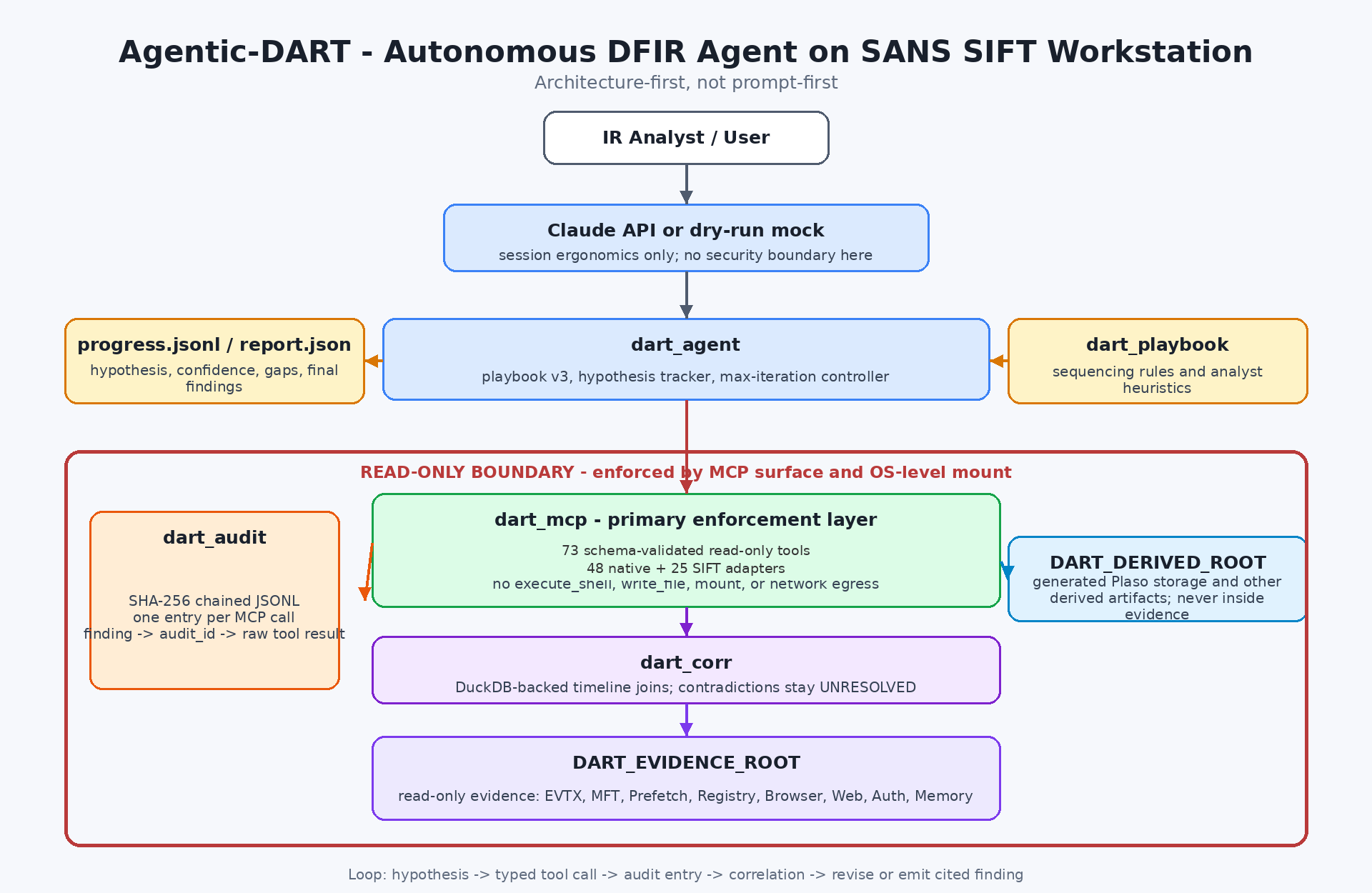
System architecture: 73 typed read-only MCP functions, 10-phase playbook, SHA-256 audit chain
-
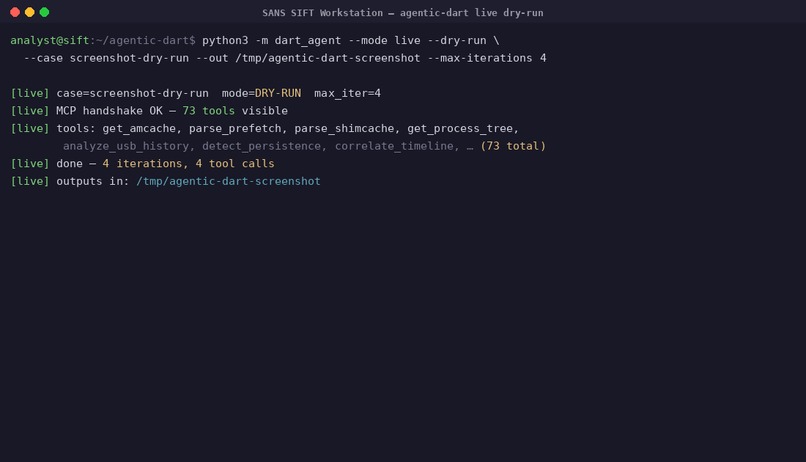
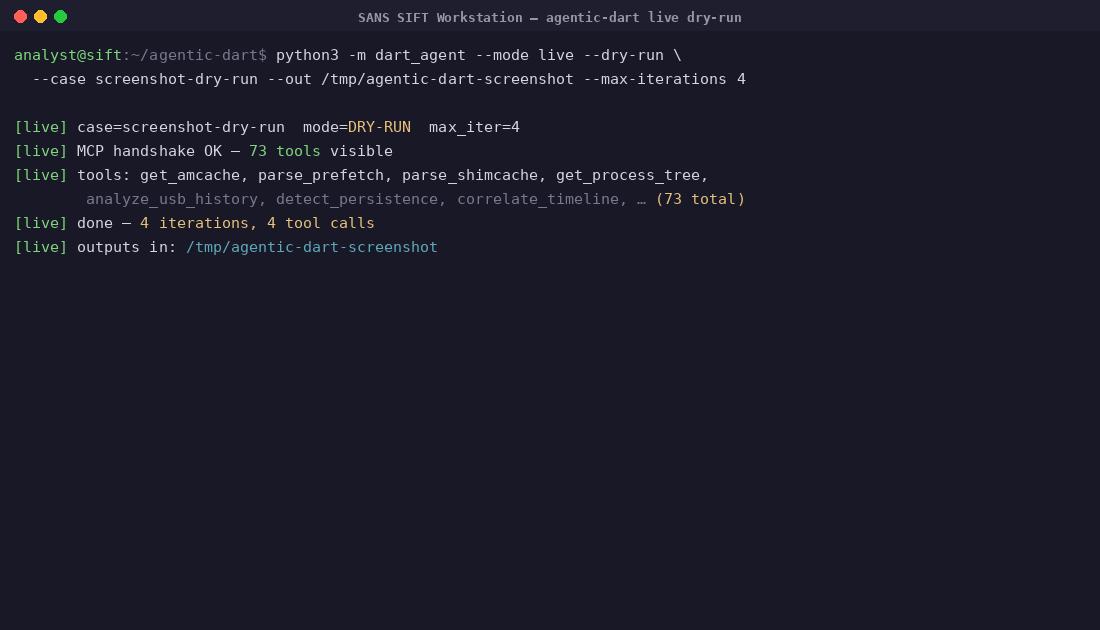
Run phase 1: autonomous triage initialization on a clean SIFT Workstation
-
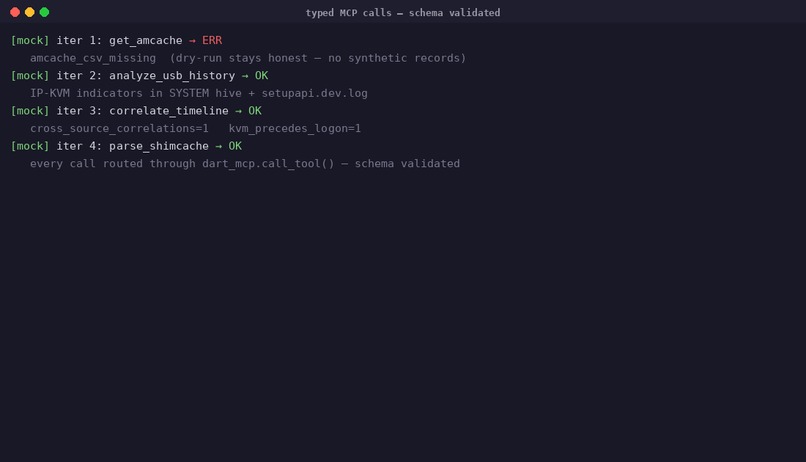
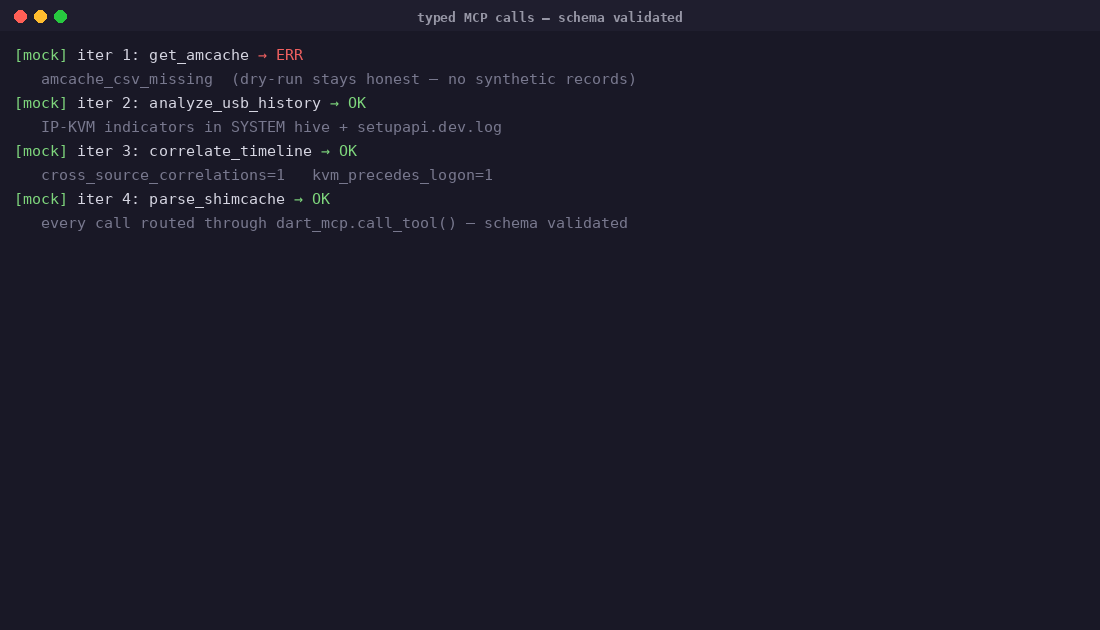
Investigation: the agent correlates artefacts and forms hypotheses
-
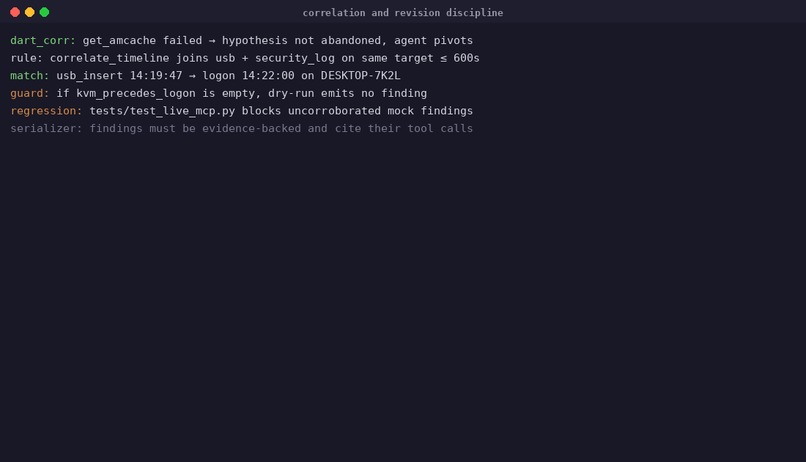
Self-correction: a contradiction forces the agent to retract and revise its hypothesis
-
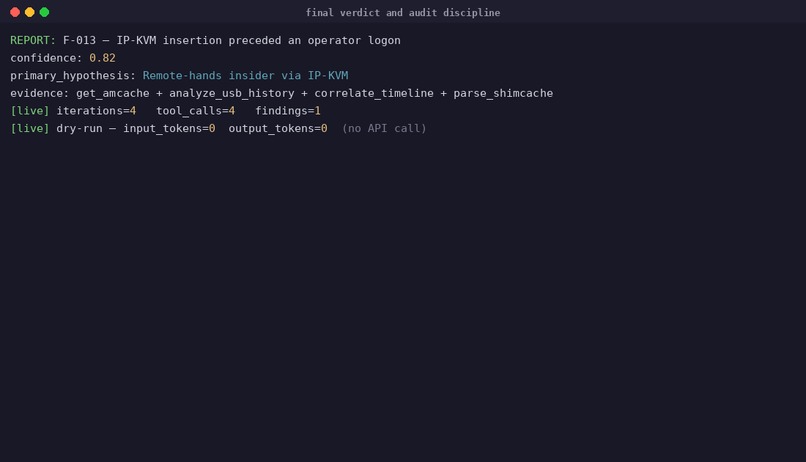
Final report: every finding traceable to a tool call via the audit chain
Inspiration
Most agentic DFIR demos prove that an LLM can hallucinate persuasively inside a Jupyter notebook. None of them answer the questions a senior analyst actually asks when handed an evidence drive:
- Did the agent trace its conclusions back to specific MCP calls?
- Did the agent retract an early hypothesis when later evidence contradicted it?
- Could the agent even attempt a destructive operation if the LLM decided to?
- Can a reviewer reproduce the same findings bit-for-bit six months from now, on a different host, with no access to the original context window?
Agentic-DART is built around those four questions. The design is architecture-first, not prompt-first: the LLM cannot misbehave because the wire it speaks on does not expose misbehaviour.
What it does
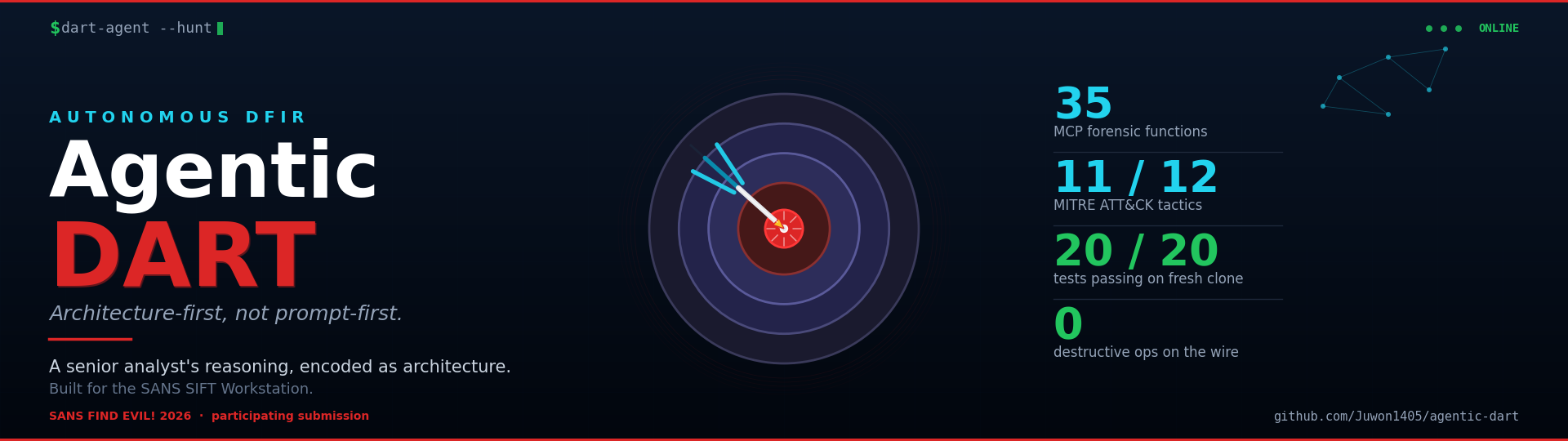
Agentic-DART is an autonomous DFIR (Digital Forensics and Incident Response) agent that runs on the SANS SIFT Workstation. It exposes 73 typed, read-only forensic functions to Claude via a custom MCP (Model Context Protocol) server, executes a structured 10-phase playbook, and emits — into out/<tier>/<case>/<timestamp>/:
findings.json— typed evidence findings with provenanceaudit.jsonl— tamper-evident SHA-256-chained record of every MCP call madereport.json+summary.json— the case report and run metadata, suitable for handing to a manager or an attorney
The agent runs end-to-end with no human intervention on a clean SIFT VM, and produces output a senior DFIR analyst would recognise as their own — because the playbook codifies how a senior analyst actually walks a case.
Machine speed, evidence-grade. A first manual pass over a single host costs an analyst days. Agentic-DART's measured end-to-end runtime is ~30 seconds on the bundled case and ~5-10 minutes against a 5 GB CFReDS image — minutes instead of days, with the full audit chain intact.
One command, real evidence. python3 analyze.py --case self-evaluation/case-01 runs the whole live senior-analyst loop; point it at your own case with --evidence <evidence_root>. And the evidence is real: the companion collector adapter (a separate repo — stdlib-only, no LLM, no API key) ingests either a Velociraptor offline collection ZIP or a raw forensic disk image (--source image, dead-disk via Velociraptor remapping) and normalises it to a SHA-256 manifest. Collection never reasons; the agent never collects — so the boundary between what was collected and what was concluded is explicit and auditable. This is a deployable two-machine IR pipeline, not a notebook demo.
How we built it
Phase 0 — Architectural guardrails (the foundation)
Before any detection logic was written, the MCP boundary was defined to be physically incapable of:
- executing shell commands
- writing files outside
evidence_root/ - mounting partitions
- evaluating arbitrary code
This is enforced not by a system prompt asking the LLM to behave, but by the fact that those functions do not exist on the wire. The test suite includes a bypass test pack that verifies the absence of these primitives is preserved across every release.
Phase 1 — The 10-phase playbook
P0 Scope & volatility assessment
P1 Initial access vector triage
P2 Timeline reconstruction
P3 Anomaly surfacing
P4 Hypothesis formation
P5 Kill-chain assembly
P6 Contradiction handling
P7 Attribution & Diamond Model
P8 Recovery & denial check
P9 Finding emission
Each phase emits typed findings into findings.json, and every MCP call is hashed into audit.jsonl. The playbook is YAML-defined (dart_playbook/senior-analyst-v3.yaml), so a customer can swap in their own playbook without modifying the agent code.
Phase 2 — 48 native MCP functions
Each function is typed, read-only, and emits structured findings the agent can correlate against later. Coverage spans:
- Windows artefacts (10 OS-specific functions plus shared cross-platform consumers): Amcache, Prefetch, ShimCache, Registry hives, Scheduled Tasks, Event Logs, USB history, ShellBags, MFT, USN journal. Many cross-platform functions (process tree, persistence, defense evasion, Kerberos events, credential access, lateral movement, etc.) also exercise the Windows surface.
- macOS artefacts (5 OS-specific functions): UnifiedLog, KnowledgeC, FSEvents, LaunchAgents/Daemons plist, LSQuarantineEvent (v0.6.1).
- Linux artefacts (6 OS-specific functions): auth.log/syslog through
parse_linux_text_log, journald, auditd, bash and shell history, cron (v0.6.1). - Cross-platform (26 functions): DuckDB scale-engine timeline correlation, process tree, lateral movement detection, ransomware behaviour, credential access, defense evasion, discovery, DNS tunneling (v0.6.1), MITRE ATT&CK mapping, browser history, exfiltration, supply-chain IoC scanning.
Phase 3 — SIFT Workstation adapter layer
For the heavy-lift artefact formats where reinventing the parser would be wasteful, dart-mcp wraps existing SIFT toolchain binaries: Volatility 3, MFTECmd, EvtxECmd, PECmd, RECmd, AmcacheParser, YARA, log2timeline, psort. Each wrapper preserves the read-only guarantee of the MCP boundary — the bypass tests cover the SIFT adapters identically.
Phase 4 — Collector-adapter (separate repository)
agentic-dart-collector-adapter is a stdlib-only Python layer that converts third-party collection output (Velociraptor offline-collector ZIP, raw disk images, and in v0.2 Falcon Forensics export) into the evidence_root/ layout dart_agent reads. This keeps the analysis engine decoupled from any single collection vendor.
Mapping to the official evaluation criteria
The six headings below use the official criterion names, in the official order. All criteria are equally weighted; Autonomous Execution Quality is the tiebreaker.
1. Autonomous Execution Quality
Criterion: can the agent reason about next steps, handle failures, and self-correct in real time?
The full 10-phase playbook runs end-to-end with no human in the loop:
# One command, no prompts, no human interaction
python3 analyze.py --case self-evaluation/case-01
Measured runtime on a clean SIFT VM: ~30 seconds on the bundled case, ~5-10 minutes on a 5 GB CFReDS image.
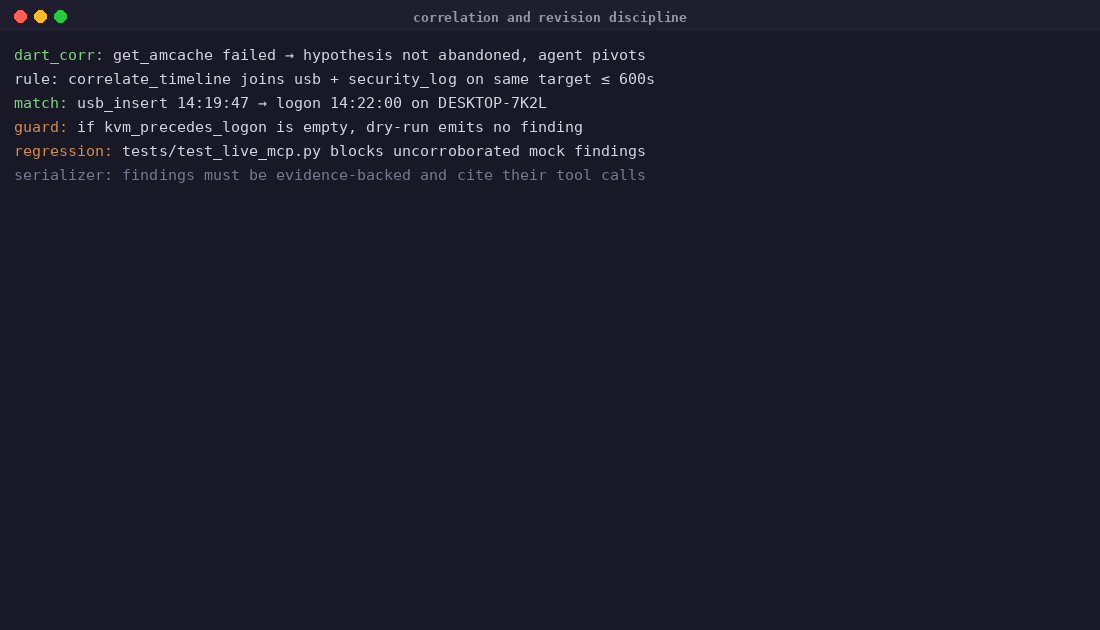
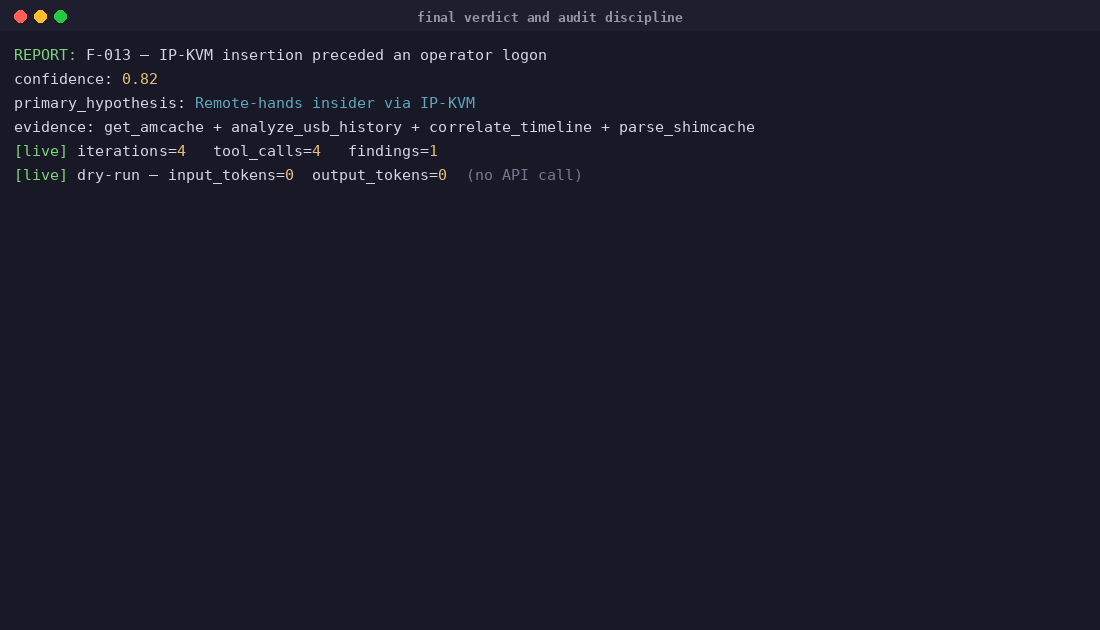
Self-correction is the headline behaviour — and it is graded, not anecdotal. case-04's ground truth encodes it as a finding of its own (F-PHISH-006, category self_correction): the agent forms an initial hypothesis ("OneDriveStartup persistence", confidence 0.62), runs parse_registry_hive, sees the path resolve to a legitimate Microsoft component, retracts the hypothesis, re-correlates, and lands on the actual persistence mechanism (HKCU\...\Run\WinUpdate) at confidence 0.91. The hypothesis revision is written to progress.jsonl after the iteration, and the MCP calls that forced it are SHA-256-chained in audit.jsonl — a reviewer can replay exactly why the agent changed its mind. scripts/eval/demo.py reports self_correction_observed: true on the bundled case-01, which exercises the same loop on a USB/logon contradiction: flagged UNRESOLVED, hypothesis replaced after the time window is widened.
Failure handling is structural, not hopeful. Every tool dispatch in the live loop is wrapped: a failing tool call comes back to the model as a structured {"error", "detail"} tool result instead of crashing the run, so the loop continues and the model routes around the failure — pivoting to the next artefact that can confirm or kill the current hypothesis. Oversized tool output is truncated before it reaches the model (heavy data is the tool's job; meaning is the LLM's job), and --max-iterations caps the loop.
2. IR Accuracy
Criterion: are hallucinations caught and flagged? Are confirmed findings distinguished from inferences?
The honest claim is not "we are perfect" — it is that every number is measured, every finding is traceable, and the limits are not hidden. Measured scores live in docs/accuracy-report.md and docs/benchmarks/SUMMARY.md, regenerated from live runs rather than transcribed here — recall varies by case difficulty and by model, and a figure pinned in prose only drifts out of sync with the harness. What holds regardless of the score:
- Hallucinations: 0 — by construction, not by luck. Any finding lacking an
audit_idreference to a chained MCP call is blocked at write time. A low recall means missed coverage; a fabricated finding cannot reach the report at all. - Evidence integrity preserved. SHA-256 of every input file is recorded before and after each run, and an anti-spoliation test asserts that no input is mutated and that any write attempted outside the evidence root resolves to zero.
- Recall is reported per-finding, per-case, per-model — never as a single headline number. The benchmarks show the current spread across Haiku / Sonnet / Opus.
Hallucination management is mechanical. Any finding lacking an audit_id reference to a chained MCP call is counted as a hallucination — no softer definition is used. The benchmark suite reports the count as a hard column in docs/benchmarks/SUMMARY.md.
Confirmed vs inferred is a typed field, not prose. Every finding carries status: confirmed | unresolved | false_positive plus a numeric confidence. When sources contradict, dart_corr emits the contradiction with status: UNRESOLVED — and unresolved records are never auto-resolved. The agent must surface them or revise its hypothesis; it cannot smooth them over.
Self-correction is observable in the logs, not merely asserted. Two kinds appear:
- Hypothesis revision (live). In the authentication + lateral-movement case, the agent raises explicit contradictions — an after-hours logon against a daytime execution window, a public-key SSH session against a claimed password vector, a domain controller against the actual lateral target — and revises its chain against the evidence instead of forcing the first theory through. In another run, the agent initially reads a freshly created local account as attacker-created, then retracts that finding once the profile registry confirms it is the host's own user — a false finding withdrawn rather than asserted.
- Parameter-adjusted re-run (deterministic, reproducible). In the bundled reference run
examples/out/find-evil-ref-01/audit.jsonl, the agent callsanalyze_usb_historyonce with a default window, identifies the gap, then re-runs the same tool with an explicit time window — a self-directed second pass that judges can reproduce byte-for-byte from the committed audit log, withprogress.jsonltracking the primary and alternative hypotheses per iteration.
Ground truth spans 11 case studies across two evidence tiers:
| Tier | Cases | Evidence | Total findings |
|---|---|---|---|
self-evaluation/ (synthetic) |
case-01 to case-08 | self-evaluation/case-01/evidence_root/ bundled; others are scenario specs |
69 |
external-evaluation/ (third-party, community-verified) |
case-01 to case-03 | NIST CFReDS / Ali Hadi / Digital Corpora M57 (downloaded on demand) | 30 |
External datasets are deliberately chosen across three independent authoring bodies (US NIST, Champlain College, Naval Postgraduate School) to avoid source bias. All three predate dart-mcp by 10-20 years — they cannot represent in-distribution training data.
Per-case ground truth exists for all bundled case studies, but benchmark summary rows are only written for cases actually executed by the harness. External-tier datasets are downloaded on demand. --download fetches the raw disk image only; adapt it into an evidence_root/ with the collector adapter (--source image), then re-run without --download to analyze:
python3 analyze.py --case external-evaluation/case-01 --download
3. Breadth and Depth of Analysis
Criterion: how much case data does the agent analyse? Depth on fewer artefact types beats shallow coverage of many.
The surface is broad — 73 typed read-only functions (48 native + 25 SIFT adapters) across Windows, macOS, and Linux artefact classes — but the evaluation is built to prove depth on real attack chains, not shallow coverage of many types:
- 99 ground-truth findings across 11 cases, scored per finding. A case is never just "passed"; each finding is individually recalled or missed, so partial depth is visible.
- Single cases chain many stages deep.
self-evaluation/case-08(12 findings) walks supply-chain compromise → ADCS ESC8 NTLM relay → DCSync → Golden Ticket;self-evaluation/case-07(13 findings) covers a full ransomware chain from initial access to impact. - Depth is enforced by correlation, not narration.
dart_corr(DuckDB) joins timelines across disk, memory, and network sources; findings that cannot survive the join are flagged, not kept. - Coverage claims are measured.
docs/accuracy-report.mddocuments 10 of the 12 in-scope Enterprise tactics actively covered by scoped detection rules, with 108 MITRE ATT&CK technique references across 69 unique techniques attached to ground truth. TA0009 (parsers present, scoped rules in Phase 2) and TA0011 (needs PCAP primitives) are tracked as roadmap, not claimed.
4. Constraint Implementation
Criterion: are the constraints architectural or prompt-based — and are they tested for bypass?
Architectural, not prompt-based. The read-only guarantee is not a rule the model is asked to follow: destructive primitives do not exist in the MCP registry, so there is nothing to jailbreak and nothing to "convince". The boundary is the set of function names on the wire.
It is tested for bypass on every CI push — tests/test_mcp_bypass.py holds 7 adversarial tests:
- Calling any of 9 destructive names (
execute_shell,write_file,mount,umount,network_egress,eval,exec_python,delete_file,system) raisesToolNotFoundat the dispatcher. - The registered surface is asserted as an exact set — a positive list and an 11-name negative list (the 9 above plus
spawn_process,kill_process) — so adding a tool can never silently widen the boundary. - Relative path traversal, absolute path escape, and null-byte truncation are each blocked by
_safe_resolvebefore any function body runs. - SQL-injection payloads against the DuckDB correlation engine are rejected by a character allowlist plus a forbidden-keyword block.
- A write probe confirms handlers cannot create files outside the evidence root.
The CI packaging job re-verifies that the installed package exposes no forbidden name (execute_shell, write_file, eval, mount, rm, system) after a clean install. The SIFT adapter layer is covered by the same tests — wrapping Volatility 3 or MFTECmd does not weaken the boundary.
5. Audit Trail Quality
Criterion: can any finding be traced back to the specific tool execution that produced it?
Yes — by ID, in one command: dart_audit trace F-NNN resolves any finding back to the exact MCP call that produced it.
Every MCP call is hashed into audit.jsonl with:
prev_hash— SHA-256 of the previous entryentry_hash— SHA-256 of this entry's canonical JSONtool_name,args,result_digest,timestamp
The chain is verified by dart_audit verify (and re-verified automatically in CI). The benchmark suite reports audit_chain_intact: true|false as a column.
6. Usability and Documentation
Criterion: can another practitioner deploy this and build on it?
Another practitioner deploys in four steps on a stock SIFT VM (or any Linux/macOS with Python 3.10+):
git clone https://github.com/Juwon1405/agentic-dart.git && cd agentic-dart
bash scripts/install.sh --os auto # installs into active interpreter; also installs the collector adapter
python3 scripts/healthcheck.py # API-free readiness check
python3 analyze.py --case self-evaluation/case-01
Building on it is the design intent: the playbook is YAML — swap in your own methodology without touching agent code; the MCP surface is typed and asserted as an exact set — adding a tool forces a test declaring it; the collector adapter keeps the evidence contract explicit, so any collection source that can produce evidence_root/ plugs in.
| Surface | Path |
|---|---|
| Top-level overview | README.md |
| Per-case walkthroughs | examples/case-studies/<tier>/case-NN/README.md (11 cases) |
| Per-case machine-readable ground truth | examples/case-studies/<tier>/case-NN/truth.json |
| Benchmark suite operator guide | scripts/eval/README.md |
| Accuracy report (self-evaluation) | docs/accuracy-report.md |
| Accuracy report (external) | docs/benchmarks/SUMMARY.md |
| Architecture | docs/architecture.md |
| Playbook | dart_playbook/senior-analyst-v3.yaml |
| Audit format | dart_audit/README.md |
| Collector adapter | https://github.com/Juwon1405/agentic-dart-collector-adapter |
| Demo video | https://www.youtube.com/watch?v=20zY7QoTAyU |
Challenges we ran into
The drift problem. Hardcoded counts (function counts, test counts, playbook step counts) had been duplicated across ~25 locations: README, CHANGELOG, wiki, profile README, GitHub Pages, CI workflow, install scripts, demo scripts. Every release that touched any of these required hand-editing all 25 places, and CI went red for 10 consecutive pushes during v0.6.0. Resolution: moved all counts to a single source of truth and used invariant assertions ("at least N") in CI rather than exact-equals checks.
The contradiction-handling problem. Early playbook versions would smooth over conflicts between data sources (e.g. USB insertion at 14:19:47 vs operator logon at 14:22). LLMs prefer coherent narratives. Resolution: added a hard architectural constraint that unresolved contradictions cannot be silently discarded — the agent must surface them or declare them unreachable. case-01 IP-KVM insider demonstrates this.
The provenance problem. Many "agentic" tools produce findings with no traceable backing — the LLM said it found something, and that's the end of the audit trail. Resolution: every finding carries an
audit_idthat links to a specific MCP call inaudit.jsonl. Findings without anaudit_idare counted as hallucinations.The collection-coupling problem. Early designs assumed Velociraptor as the only evidence collection layer. When a customer adopts Falcon Forensics or Tanium, the analysis engine should not need to change. Resolution: extracted a separate collector-adapter repo (stdlib-only Python) that normalises any input source into the same
evidence_root/layout. The analysis engine doesn't care which collector produced the data.
Accomplishments we're proud of
- Single-developer end-to-end platform — autonomous agent + MCP server + SIFT adapter + collector adapter (ZIP and dead-disk image) + one-command
analyzeCLI + OS-aware installer + benchmark suite + 11 case studies, shipped by one person in six weeks. - Minimal dependency surface in the core MCP layer. Only two third-party Python packages —
duckdbfor the cross-artifact timeline-correlation engine andpython-registryfor offline hive parsing (the audit trail itself is stdlib-only SHA-256-linked JSONL). The reasoning loop adds the officialanthropicSDK on top. Auditable in a single sitting. - Measured MITRE ATT&CK coverage. 10 of the 12 in-scope Enterprise tactics actively covered by scoped detection rules (per
docs/accuracy-report.md; TA0009 and TA0011 are tracked as Phase-2 roadmap, not claimed). 108 distinct technique references mapped to 99 ground-truth findings across the 11 case studies. - External-dataset honesty. External-tier evaluation against three independent third-party datasets that the project's author did not create or have influence over. Numbers are what they are.
What we learned
- Architecture wins over prompting. A system prompt asking the LLM to "please don't execute arbitrary code" is a marketing claim. A wire protocol that doesn't expose
execute_codeis a guarantee. - Self-correction is a measurable property. It is not enough for an agent to sometimes retract wrong claims; the retraction itself needs to be a first-class auditable event with its own hash.
- The right unit of accuracy is per-finding, not per-case. A single case can have 13 findings (case-07 ransomware) and the agent might get 10 right and 3 wrong. Reporting "case passed" or "case failed" hides that signal; reporting per-finding recall/precision exposes it.
- External benchmarks discipline internal claims. As long as the only evidence is bundled with the project, "Recall 1.000" is just a number we wrote. Once the same agent runs against NIST CFReDS (which existed before this project did), the number means something.
What's next for Agentic-DART
Post-submission roadmap, scheduled for after 2026-06-15:
- Falcon Forensics input adapter (v0.2 of collector-adapter). The agent already consumes Velociraptor and raw images; adding Falcon is one input-format module.
- EZTools sidecar generation. Auto-invoke PECmd / AmcacheParser / EvtxECmd / RECmd when their binaries are present on the local toolchain, merge parsed JSON into the manifest.
- macOS + Linux artefact parity with Windows. Unified log, KnowledgeC, FSEvents, auditd, journald, launchd — match the classification depth that the Windows surface currently has.
- CI url-reachability check. Detect dead external dataset URLs as drift, not as a benchmark failure.
- Live benchmark run on user host. The submission ships the benchmark infrastructure but the numerical results in
docs/benchmarks/SUMMARY.mdare produced from the maintainer's workstation rather than CI (the 13 GB external datasets are too large for a free runner). A separate machine in the post-submission period will host the rolling accuracy ledger.
How to run Agentic-DART yourself
Prerequisites
- SIFT Workstation (or any Linux/macOS with Python 3.10+)
- Anthropic API key (
ANTHROPIC_API_KEY) —analyze.pyis live mode only and fails fast without it. - ~16 GB disk space (only if running external benchmarks)
Install
git clone https://github.com/Juwon1405/agentic-dart.git
cd agentic-dart
bash scripts/install.sh --os ubuntu --skip-sift # add --install-sift --install-eztools for the full toolchain
python3 scripts/healthcheck.py # API-free readiness check
The installer is OS-aware (--os auto|ubuntu|centos|macos), installs into the current Python interpreter, clones and installs the collector adapter, and only stages SIFT (via cast) / Eric Zimmerman Tools (.NET 9) when asked — never pretending a tool is present when it is not.
Run an evaluation case
export ANTHROPIC_API_KEY='sk-...'
python3 analyze.py --case self-evaluation/case-01 # bundled evidence
python3 analyze.py --case external-evaluation/case-01 --download # fetch raw image (then adapt + analyze)
python3 analyze.py --list # discover all cases (no key needed)
Low-level offline demo (no API key)
bash examples/demo-run.sh
Run against your own evidence
Convert a Velociraptor collection or a raw disk image into an evidence_root/ with the collector adapter, drop it under a case folder, then run it:
python3 -m dart_collector_adapter --source image --input disk.E01 \
--output examples/case-studies/self-evaluation/case-01/evidence_root --case-id my-case
python3 analyze.py --case self-evaluation/case-01
Submission artefacts checklist
- [x] Source code: https://github.com/Juwon1405/agentic-dart
- [x] License: MIT (
LICENSEin repo root) - [x] README with architecture overview and reproduction commands
- [x] Demo video (submitted directly to Devpost form, not embedded in repo)
- [x] 11 documented case studies with machine-readable ground truth
- [x] Benchmark suite (
scripts/eval/) covering internal + external evidence - [x] CI green at submission (full pytest suite passing across dart_mcp, dart_agent, dart_audit, dart_corr)
- [x] Audit-chain verification utility (
dart_audit verify) - [x] Architectural guardrail test pack (
tests/test_mcp_bypass.py— 7 bypass tests) - [x] Single-source-of-truth count discipline (no hardcoded drift)
- [x] Companion collector-adapter repo: https://github.com/Juwon1405/agentic-dart-collector-adapter
Links
- Source code: https://github.com/Juwon1405/agentic-dart
- Collector adapter (companion repo): https://github.com/Juwon1405/agentic-dart-collector-adapter
- Quick start guide: https://github.com/Juwon1405/agentic-dart/blob/main/docs/QUICKSTART.md
- Architecture diagram: https://github.com/Juwon1405/agentic-dart/blob/main/docs/dart-architecture.png
- Dataset documentation: https://github.com/Juwon1405/agentic-dart/blob/main/docs/dataset.md
- Accuracy report: https://github.com/Juwon1405/agentic-dart/blob/main/docs/accuracy-report.md
- Agent execution logs (reproducible reference run): https://github.com/Juwon1405/agentic-dart/tree/main/examples/out/find-evil-ref-01
Built With
- anthropic-claude
- duckdb
- mcp
- mitre-attack
- model-context-protocol
- pytest
- python
- sift-workstation
- volatility3
- yara






{kind=link}
Log in or sign up for Devpost to join the conversation.